Hive 的企业优化
优化
数据优化
一、从大表拆分成小表(更快地检索)
eg2:常用于分表
create table if not exists default.cenzhongman_2
AS select ip,date from default.cenzhongman;
二、使用外部表(多部门共用,指定存储目录,删表不删数据),分区表(按月按XXX分区)
#创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS table_name();
#创建分区表
create table emp_partition(ID int, name string, job string, mrg int, hiredate string, sal double, comm double, deptno int) partitioned by (mouth string);
三、使用 ORC | parquet 数据存储格式
#官网例子
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
四、使用 snappy 压缩格式
如上例
五、FetchTask 抓取任务转换 > more
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only (Select * 、筛选分区、limit 限制显示行数 这三种行为不会经过 mapreduce)
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)(相对nimimal 增加了时间戳,虚拟列,还有所有的选择)
</description>
</property>
优化 SQL 语句
join 优化
common/shuffle/reduce join :join 发生在 reduce 阶段
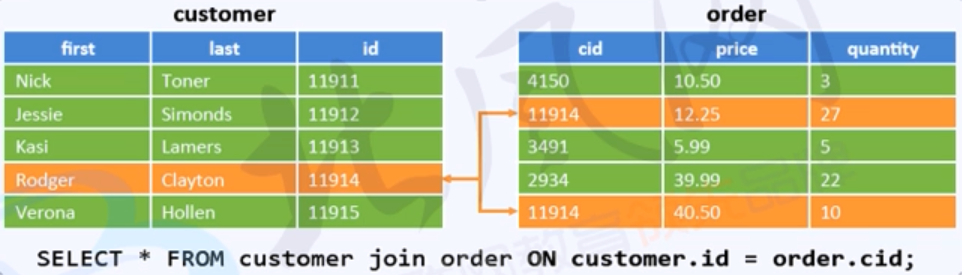

大表对大表,每个表的数据都从文件中读取(发生在Reduce shuffle 的分组Group过程(相同的key的value放在一起))
Map join :join 发生在 Map 阶段

小表对大表,大表的数据从文件中读取,小表的数据在内存中,通过 DistributedCache 类进行缓存
SMB join :Sort-Merge-Bucket join
SMB 的设置

注:Bucket CLUSTERED 按照 num_buckets 对数据进行分区并排序
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]


面对大表对大表处理时候的优化,Merge > sort > join
根据两个表的相同字段进行 按 num_buckets 分组(Merge) 并 在组内 排序(Sort)
execution plan 执行计划
官方文档
查看执行计划
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query
eg:explain select * from emp;
能够看到的信息
- The Abstract Syntax Tree for the query 语法树
- The dependencies between the different stages of the plan 依赖关系
- The description of each of the stages 每个阶段的描述
其他高级优化
1.设置任务并行执行
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.parallel | false | 默认为 false |
| hive.exec.parallel.thread.number | 8 | 建议10 ~ 20 之间 |
2.合理设置 reduce 任务的数量
| 参数 | 值 | 备注 |
|---|---|---|
| mapreduce.job.reduces | 1 | 测试出真知 |
3.推测执行 speculative
在 mapReduce 运行过程中,当 ApplicationMaster 检测到任务执行时间差异明显比正常时间长时,会多运行一个任务,结果取决于最先结束运行的任务。
在 Hive 执行过程中出现长时间任务为正常现象,为了防止系统创建重复任务占用过多的资源,应该关闭该功能
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.reduce.tasks.speculative.execution | true | 当用 Hive 时候推荐为 false |
| mapreduce.map.speculative | true | 当用 Hive 时候推荐为 false |
| mapreduce.reduce.speculative | true | 当用 Hive 时候推荐为 false |
4.合理设置 Map 值
一般来说,根据文件大小就是很合理的了。
5.动态分区调整
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.dynamic.partition | true | 是否开启动态分区属性 |
| hive.exec.dynamic.partition.mode | strict | strict mode, 用户必须指定至少一个静态分区以防用户意外地覆盖了所有的分区。nonstrict mode 所有的分区都是动态的 |
6.查询模式设置
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.mode nonstrict | nostrict | strict/nostrict |
设置严格模式将禁止三种类型查询
- 1)对于分区表,不加分区字段过滤条件,不能执行:分区表中,where 子句中不加分区过滤
Error eg:select * from emp_partition where name = 'cenzhongman';
Right eg:select * from emp_partition where name = 'cenzhongman', month = '201707'; - 2)对于 oder by 语句,必须使用 limit 语句
- 3)限制笛卡尔积的查询(Join 的时候不适用 on 而使用 where 的)
岑忠满的博客新站点
http://cenzm.xyz
