
Tomcat组件梳理—Digester的使用
Tomcat组件梳理—Digester的使用
再吐槽一下,本来以为可以不用再开一个篇章来梳理Digester了,但是发现在研究Service的创建时,还是对Digester的很多接口或者机制不熟悉,简直搞不懂。想想还是算了,再回头一下,把这个也给梳理了。所以此文主要做两件事情,
1.梳理Digester的设计思想和常用接口。
2.梳理Digester对server.xml文件的解析。这么看也算是理论和实际相结合吧。
1.XML文件解析的两种方案。
Java解析XML文件有两个主要的思想,分别是:
1.1.预加载DOM树
该方法的思路是:将整个XML文件读取到内存中,在内容中构造一个DOM树,也叫对象模型集合,然后java代码只需要操作这个树就可以。
该方法的主要实现为DOM解析,在此基础上有两个扩展:JDOM解析,DOM4J解析。这两种方法的思路都是一样的,只不过一个是官方出的,一个是社区出的,好不好用的问题。Java很奇怪,都是社区出的更好用,即DOM4J。
该思想有优点和缺点:
- 优点:使用DOM时,XML文档的结构在内存中很清晰,元素与元素之间的关系保留了下来。即能记录文档的所有信息。
- 缺点:如果XML文档非常大,把整个XML文档装在进内存容易造成内容溢出,无法加载了。
1.2.事件机制的SAX
该方法的思路是:一行一行的读取XML文件,没遇到一个节点,就看看有没有监听该事件的监听器,如果有就触发。当XML文件读取结束后,内存里不会保存任何数据,整个XML的解析就结束了。所以,这里面最重要的是对感兴趣的节点进行监听和处理。
该思想仍然有优点和缺点:
- 优点:使用SAX不会占用大量内存来保存XML文档数据,效率高。
- 缺点:当解析一个元素时,上一个元素的信息已经丢弃,也就是说没有保存元素与元素之间的结构关系。
2.Digester的设计思想
2.1.主要解决的问题
Digester是对SAX的封装和抽象,解决在SAX中特别不好用的地方,那么Digester主要解决了哪些问题呢?
-
1.XML的内容是变化的,那么不同的内容如何采用不同的方法去处理呢?用多个if进行判断?显然不是。
Digester解决该问题的方法是,抽象出两个东西,一个是XML里面的内容,即XML中的节点,该内容可以使用正则进行书写。另一个是方法,找到该节点时需要调用的处理方法。处理方法统一继承Rule接口。
这样当在读取XML文件时,发现新的节点,就可以去找对应的正则,如果匹配,就可以调用对应的处理方法了。
-
2.解析一个XML上的节点时,该如何解析?
Digester解决该方法时,是将XML节点解析的生命周期进行抽象,不同生成周期做不同的事情,不同的处理方法只需要重写生命周期对应的方法就行。
-
3.如何确保XML上不同的节点有依赖关系呢?
Digester在内部自己维护了一个栈的结构,每遇到一个新的节点时,把这个对象把它压入栈(push),节点解析结束时,可以再从栈中弹出(pop),栈里面最顶部的对象永远都是现在正在解析的对象,第二个是它的父节点,提供API调用父节点的方法把引用当前对象,这样就解决了依赖的问题。
2.2.源码主要结构
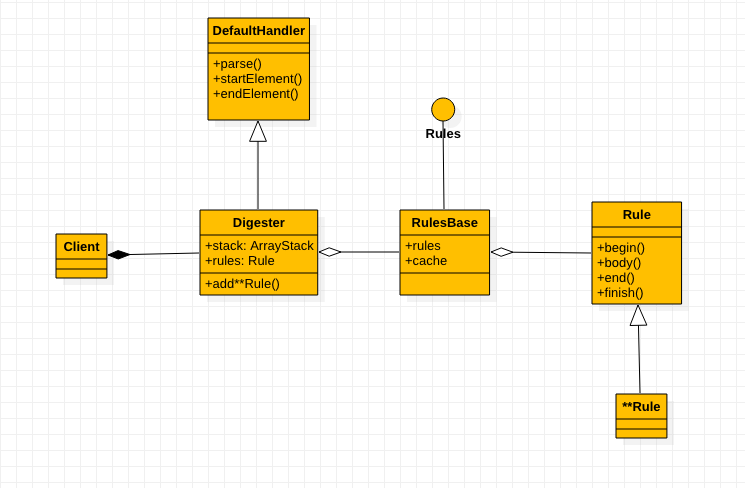
先对架构进行解释一下,
-
最上面的
DefaultHandler来自SAX,Digester集成该类,足以说明Digester底层用的是SAX了。 -
Client表示调用Digester的Java代码。 -
Digester是真个Digester组件的核心类和入口类,Client需要实例化该类,设置改类,并调用里面的参数。 -
Rules是一个保存XML的节点和规则的映射关系的接口,默认实现类是RulesBase -
RuesBase是Rules的默认实现类。当有一个XML节点开始解析时,会在这里面找是否有对应的节点,并根据节点查找对应的处理规则。 -
Rule对节点的处理方法的接口,内置的或者自定义的规则都是集成该接口。 -
**Rule是接口Rule的很多实现,根据具体的实现不同而不同。
使用Digester解析XML文档的流程:
- 1.首先,Client需要创建一个Digester对象。
- 2.然后,Client必须根据自己的XML格式来添加所有的Rule。
- 3.添加完Rule后,Client调用Digester的parse操作来解析XML文件。
- 4.Digester实现了SAX的接口,解析时遇到具体的XML对象时会调用startElement等接口函数。
- 5.在这些SAX接口函数中,会扫描规则链(RulesBase),找到匹配规则,规则匹配一般都是根据具体的元素名称来进行匹配。
- 6.找到对应的rule后,依次执行rule,这里的startElement对应的是begin操作,endElement对应的是end操作,具体要做的事情都在每个rule的begin,body,end函数中。
- 7.文档结束后,会执行所有rule的finish函数。
Digester的巧妙设计:
1.XML格式变化:Digester把这个变化抛给具体用户去解决,用户在使用Digester之前必须自己根据自己的XML文件格式来构造规则链,Digester只提供构造规则链的手段,体现了有所为有所不为的设计思想。
2.处理方式变化的问题,Digester将处理方式抽象为规则Rule,一个规则对应一个处理方式,Digester提供了通用的缺省的Rule,如果觉得提供的规则不满足自己的要求,可以自己另外定制。
Digester在代码中的使用流程
//3.用digester解析server.xml文件,把配置文件中的配置解析成java对象
//3.1.准备好用来解析server.xml文件需要用的digester。
Digester digester = createStartDigester();
//3.2.server.xml文件作为一个输入流传入
File file = configFile();
InputStream inputStream = new FileInputStream(file);
//3.3.使用inputStream构造一个sax的inputSource
InputSource inputSource = new InputSource(file.toURI().toURL().toString());
inputSource.setByteStream(inputStream);
//3.4.把当前类压入到digester的栈顶,用来作为digester解析出来的对象的一种引用
digester.push(this);
//3.5.调用digester的parse()方法进行解析。
digester.parse(inputSource);
- 3.1.准备好用来解析server.xml文件需要用的digester。
- 3.2.读取server.xml文件作为一个输入流。
- 3.3.使用inputStream构造一个sax的inputSource,因为digester底层用的是sax去解析的。
- 3.4.把当前类压入到digester的栈顶,用来作为digester解析出来的对象的一种引用,digester自带一个栈的结构。
- 3.5.调用digester的parse()方法进行解析。前面几步都是在准备环境,这里才是正真的去解析了。
2.3.内部维护的栈结构
Digester用栈来维护每个正在解析的对象,注意,这个栈里面存放的是正在解析的,即开始解析时就放入栈,解析玩就弹出栈。
这个栈是Digester自己写的一个,用ArrayList来实现的,但是方法都一样,在Digester类中进行维护,代码为:
//org.apache.tomcat.util.digester.Digester
/**
* The object stack being constructed.
*/
protected ArrayStack<Object> stack = new ArrayStack<>();
该栈的主要方法有:
clear():清楚栈内的所有元素。peek():返回栈顶对象的引用,而不进行删除。pop():弹出栈顶的元素。push():压入一个元素到栈顶。
3.Digester的常用接口
3.1.解析XML节点时的生命周期
在解析XML节点时,有一整个生命周期在里面,解析一个节点时,会有一下生命周期,1.遇到匹配的节点的开始部分时开始解析,2.解析文本内容,3.遇到匹配的节点的结束部分时结束解析,4.最后处理资源。
-
begin():当读取到匹配节点的开始部分时调用,会将该节点的所有属性作为从参数传入。 -
body():当读取到匹配节点的内容时调用,注意指的不是子节点,而是嵌入内容为普通文本。 -
end():当读取到匹配节点的结束部分时调用,如果存在子节点,只有当子节点处理完毕后该方法才会被调用。 -
finish():当整个parse()方法完成时调用,多用于清楚临时数据和缓存数据。
3.2.内置的规则接口
Digester内置了一些规则,可以调用接口直接使用,还有一些其他的API可调用:
ObjectCreateRule: 当begin()方法调用时,该规则会将指定的Java类实例化,并将其放入对象栈。具体的Java类可由该规则在构造方法出啊如,也可以通过当前处理XML节点的某个属性指定,属性名称通过构造方法传入。当end()方法调用时,该规则创建的对象将从栈中取出。FactoryCreateRule:ObJectCreateRule规则的一个变体,用于处理Java类无默认构造方法的情况,或者需要在Digester处理该对象之前执行某些操作的情况。SetPropertiesRule:当begin()方法调用时,Digester使用标准的Java Bean属性操作方法(setter)将当前XML节点的属性值设置到对象栈顶部的对象中。SetPropertyRule:当begin()方法调用时,Digester会设置栈顶部对象指定属性的值,其中属性名和属性值分别通过XML节点的两个属性指定。SetNextRule:当end()方法调用时,Digester会找到位于栈顶部对象的下一个对象,并调用其指定的方法,同时将栈顶部对象作为参数传入,用于设置父对象的子对象,以便在栈对象之间建立父子关系,从而形成对象树,方便引用。SetTopRule:与setNextRule对象,当end()方法调用时,Digester会找到位于站顶部的对象,调用其指定方法,同时将位于顶部下一个对象作为参数传入,用于设置当前对象的父对象。CallMethRule:该规则用于在end()方法调用时执行栈顶对象的某个方法,参数值由CallParamRule获取。CallParamRule:该规则与CallMethodRule配合使用,作为其子节点的处理规则创建方法参数,参数值可取自某个特殊属性,也可以取自节点的内容。NodeCreateRule:用于将XML文档树的一部分转换为DOM节点,并放入栈。
3.3.自定义规则
如果需要自定义规则,只需要创建一个类继承Rule接口,并重写里面的生命周期方法,可以选择只重写部分。
例如:
public class ConnectorCreateRule extends Rule {
@Override
public void begin(String namespace, String name, Attributes attributes){
//do something
}
@Override
public void begin(String namespace, String name, Attributes attributes){
//do something
}
}
最后在使用自定义的规则时,方法如下:
digester.addRule("Server/Service/Connector",new ConnectorCreateRule());
此时即可。
3.4.addRuleSet方法
很多时候针对同一个节点,我们会执行很多规则,比如:创建一个对象,设置属性,调用方法。至少三个。每次都写三个是比较麻烦的,那么有没有比较方便的方法呢?
有。使用addRuleSet()方法,传入需要匹配的节点名称,然后对该节点使用多个规则。此方法方便重用。
案例:
首先自定义一个规则:
public class MyRuleSet
extends RuleSetBase {
public MyRuleSet()
{
this("");
}
public MyRuleSet(String prefix)
{
super();
this.prefix = prefix;
this.namespaceURI = "http://www.mycompany.com/MyNamespace";
}
protected String prefix = null;
public void addRuleInstances(Digester digester)
{
digester.addObjectCreate( prefix + "foo/bar",
"com.mycompany.MyFoo" );
digester.addSetProperties( prefix + "foo/bar" );
}
}
然后可以直接调用:
Digester digester = new Digester();
... configure Digester properties ...
digester.addRuleSet( new MyRuleSet( "baz/" ) );
4.Digester解析Server.xml的案例分析
上面说了这么多,终于可以开始梳理Tomcat中Digester对server.xml文件的解析了。
4.1.总的步骤
使用Digester的方法在上面有说过,再展示一下:
//3.用digester解析server.xml文件,把配置文件中的配置解析成java对象
//3.1.准备好用来解析server.xml文件需要用的digester。
Digester digester = createStartDigester();
//3.2.server.xml文件作为一个输入流传入
File file = configFile();
InputStream inputStream = new FileInputStream(file);
//3.3.使用inputStream构造一个sax的inputSource
InputSource inputSource = new InputSource(file.toURI().toURL().toString());
inputSource.setByteStream(inputStream);
//3.4.把当前类压入到digester的栈顶,用来作为digester解析出来的对象的一种引用
digester.push(this);
//3.5.调用digester的parse()方法进行解析。
digester.parse(inputSource);
解释一下:
- 3.1.准备好用来解析server.xml文件需要用的digester。
- 3.2.读取server.xml文件作为一个输入流。
- 3.3.使用inputStream构造一个sax的inputSource,因为digester底层用的是sax去解析的。
- 3.4.把当前类压入到digester的栈顶,用来作为digester解析出来的对象的一种引用,digester自带一个栈的结构。
- 3.5.调用digester的parse()方法进行解析。前面几步都是在准备环境,这里才是正真的去解析了。
在第1个步骤中,需要先构造一个套规则,存放在digester实例中。构造代码比较多,我拆开说
4.2.节点绑定规则
以下均为createStartDigester()方法的内容
4.2.1.设置giester的参数:
// 创建一个digester实例
Digester digester = new Digester();
//是否对xml文档进行类似XSD等类型的校验,默认为fasle。
digester.setValidating(false);
//是否进行节点设置规则校验,如果xml中相应节点没有设置解析规则会在控制台显示提示信息。
digester.setRulesValidation(true);
//将XML节点中的className作为假属性,不必调用默认的setter方法
//(一般的节点属性在解析时会以属性作为入参调用该节点相应对象的setter方法,而className属性的作用
// 提示解析器使用该属性的值作来实例化对象)
Map<Class<?>, List<String>> fakeAttributes = new HashMap<>();
List<String> objectAttrs = new ArrayList<>();
objectAttrs.add("className");
fakeAttributes.put(Object.class, objectAttrs);
// Ignore attribute added by Eclipse for its internal tracking
List<String> contextAttrs = new ArrayList<>();
contextAttrs.add("source");
fakeAttributes.put(StandardContext.class, contextAttrs);
digester.setFakeAttributes(fakeAttributes);
//使用当前线程的上下文类加载器,主要加载FactoryCreateRule和ObjectCreateRule
digester.setUseContextClassLoader(true);
4.2.2.Server的解析
1.创建Server实例
digester.addObjectCreate("Server","org.apache.catalina.core.StandardServer","className");
digester.addSetProperties("Server");
digester.addSetNext("Server","setServer","org.apache.catalina.Server");
创建对象,设置属性,调用方法添加到Catalina类中。
2.为Server添加全局J2EE企业命名上下文
digester.addObjectCreate("Server/GlobalNamingResources",
"org.apache.catalina.deploy.NamingResourcesImpl");
digester.addSetProperties("Server/GlobalNamingResources");
digester.addSetNext("Server/GlobalNamingResources",
"setGlobalNamingResources",
"org.apache.catalina.deploy.NamingResourcesImpl");
创建对象,设置属性,添加到Server中。
3.为Server添加生命周期监听器
digester.addObjectCreate("Server/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Listener");
digester.addSetNext("Server/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
给Server添加监听器,Server一共添加了5个监听器,xml文件中显示如下:
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<!-- Security listener. Documentation at /docs/config/listeners.html
<Listener className="org.apache.catalina.security.SecurityListener" />
-->
<!--APR library loader. Documentation at /docs/apr.html -->
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<!-- Prevent memory leaks due to use of particular java/javax APIs-->
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
这5个监听器的作用分别是:
VersionLoggerListener:在Server初始化之前打印操作系统,JVM以及服务器的版本信息。AprLifecycleListener:在Server初始化之前加载APR库,并于Server停止之后销毁。JreMemoryLeakPreventionListener:在Server初始化之前调用,以解决单例对象创建导致的JVM内存泄漏问题以及锁文件问题。GlobalResourcesLifecycleListener:在Server启动时,将JNDI资源注册为MBean进行管理。ThreadLocalLeakPreventionListener:用于在Context停止时重建Exceutor池中的线程,避免导致内存泄漏。
4.给Server添加Service实例
digester.addObjectCreate("Server/Service",
"org.apache.catalina.core.StandardService",
"className");
digester.addSetProperties("Server/Service");
digester.addSetNext("Server/Service",
"addService",
"org.apache.catalina.Service");
创建Service对象,设置参数,添加到Server中。
5.给Service添加生命周期监听器
digester.addObjectCreate("Server/Service/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Listener");
digester.addSetNext("Server/Service/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
具体的监听器由className属性指定,默认情况下,Catalina未指定Service监听器。
6.为Service添加Executor
digester.addObjectCreate("Server/Service/Executor",
"org.apache.catalina.core.StandardThreadExecutor",
"className");
digester.addSetProperties("Server/Service/Executor");
digester.addSetNext("Server/Service/Executor",
"addExecutor",
"org.apache.catalina.Executor");
通过该配置我们可以知道,Catalina共享Excetor的级别为Service,Catalina默认情况下未配置Executor,即不共享。
7.为Service添加Connector
digester.addRule("Server/Service/Connector",
new ConnectorCreateRule());
digester.addRule("Server/Service/Connector",
new SetAllPropertiesRule(new String[]{"executor", "sslImplementationName"}));
digester.addSetNext("Server/Service/Connector",
"addConnector",
"org.apache.catalina.connector.Connector");
设置相关属性时,将executor和sslImplementationName属性排除,因为在Connector创建时,会判断当前是否指定了executor属性,如果是,则从Service中查找该名称的executor并设置到Connector中。同样,Connector创建时,也会判断是否添加了sslIlplementationName属性,如果是,则将属性值设置到使用的协议中,为其指定一个SSL实现。
8.Connector添加虚拟主机SSL配置
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig",
"org.apache.tomcat.util.net.SSLHostConfig");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig");
digester.addSetNext("Server/Service/Connector/SSLHostConfig",
"addSslHostConfig",
"org.apache.tomcat.util.net.SSLHostConfig");
digester.addRule("Server/Service/Connector/SSLHostConfig/Certificate",
new CertificateCreateRule());
digester.addRule("Server/Service/Connector/SSLHostConfig/Certificate",
new SetAllPropertiesRule(new String[]{"type"}));
digester.addSetNext("Server/Service/Connector/SSLHostConfig/Certificate",
"addCertificate",
"org.apache.tomcat.util.net.SSLHostConfigCertificate");
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig/OpenSSLConf",
"org.apache.tomcat.util.net.openssl.OpenSSLConf");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig/OpenSSLConf");
digester.addSetNext("Server/Service/Connector/SSLHostConfig/OpenSSLConf",
"setOpenSslConf",
"org.apache.tomcat.util.net.openssl.OpenSSLConf");
digester.addObjectCreate("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd",
"org.apache.tomcat.util.net.openssl.OpenSSLConfCmd");
digester.addSetProperties("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd");
digester.addSetNext("Server/Service/Connector/SSLHostConfig/OpenSSLConf/OpenSSLConfCmd",
"addCmd",
"org.apache.tomcat.util.net.openssl.OpenSSLConfCmd");
8.5版本新加内容
9.为Connector添加生命周期监听器
digester.addObjectCreate("Server/Service/Connector/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Connector/Listener");
digester.addSetNext("Server/Service/Connector/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
具体监听器类由className属性指定。默认情况下,Catalina未指定Connector监听器。
10.为Connector添加升级协议
digester.addObjectCreate("Server/Service/Connector/UpgradeProtocol",
null, // MUST be specified in the element
"className");
digester.addSetProperties("Server/Service/Connector/UpgradeProtocol");
digester.addSetNext("Server/Service/Connector/UpgradeProtocol",
"addUpgradeProtocol",
"org.apache.coyote.UpgradeProtocol");
用于支持HTTP/2,8.5新增。
11.添加子元素解析规则
digester.addRuleSet(new NamingRuleSet("Server/GlobalNamingResources/"));
digester.addRuleSet(new EngineRuleSet("Server/Service/"));
digester.addRuleSet(new HostRuleSet("Server/Service/Engine/"));
digester.addRuleSet(new ContextRuleSet("Server/Service/Engine/Host/"));
addClusterRuleSet(digester, "Server/Service/Engine/Host/Cluster/");
digester.addRuleSet(new NamingRuleSet("Server/Service/Engine/Host/Context/"));
// When the 'engine' is found, set the parentClassLoader.
digester.addRule("Server/Service/Engine",
new SetParentClassLoaderRule(parentClassLoader));
addClusterRuleSet(digester, "Server/Service/Engine/Cluster/");
此部分指定了Servlet容器相关的各级嵌套子节点的解析规则,而且没类嵌套子节点的解析规则封装为一个RuleSet,包括GlobalNamingResources,Engine,Host,Context以及Cluster解析。
4.2.3.Engine的解析
Engine的解析是放在digester.addRuleSet(new EngineRuleSet("Server/Service/"));方法里面的。
具体如下
1.创建Engine实例
digester.addObjectCreate(prefix + "Engine",
"org.apache.catalina.core.StandardEngine",
"className");
digester.addSetProperties(prefix + "Engine");
digester.addRule(prefix + "Engine",
new LifecycleListenerRule
("org.apache.catalina.startup.EngineConfig",
"engineConfigClass"));
digester.addSetNext(prefix + "Engine",
"setContainer",
"org.apache.catalina.Engine");
创建实例,并通过setContainer添加Service中。同时,还为Engine添加了一个生命周期的监听器,代码里写死,不是通过server.xml配置的。用于打印Engine启动和停止日志。
2.为Engine添加集群配置
digester.addObjectCreate(prefix + "Engine/Cluster",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Cluster");
digester.addSetNext(prefix + "Engine/Cluster",
"setCluster",
"org.apache.catalina.Cluster");
具体集群实现类由className属性指定。
3.为Engine添加生命周期监听器
digester.addObjectCreate(prefix + "Engine/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Listener");
digester.addSetNext(prefix + "Engine/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
由server.xml配置,默认情况下,未指定Engine监听器。
4.为Engine添加安全配置
digester.addObjectCreate(prefix + "Engine/Valve",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Engine/Valve");
digester.addSetNext(prefix + "Engine/Valve",
"addValve",
"org.apache.catalina.Valve");
为Engine添加安全配置以及拦截器Valve,具体的拦截器由className属性指定。
4.2.4.Host的解析
Host的解析位于HostRuleSet类,digester.addRuleSet(new HostRuleSet("Server/Service/Engine/"));
1.创建Host实例
digester.addObjectCreate(prefix + "Host",
"org.apache.catalina.core.StandardHost",
"className");
digester.addSetProperties(prefix + "Host");
digester.addRule(prefix + "Host",
new CopyParentClassLoaderRule());
digester.addRule(prefix + "Host",
new LifecycleListenerRule
("org.apache.catalina.startup.HostConfig",
"hostConfigClass"));
digester.addSetNext(prefix + "Host",
"addChild",
"org.apache.catalina.Container");
digester.addCallMethod(prefix + "Host/Alias",
"addAlias", 0);
创建Host实例,通过addChild()方法添加到Engine上。同时还为Host添加了一个生命周期监听器HostConfig,同样,该监听器由Catalina默认添加,而不是server.xml配置。
2.为Host添加集群
digester.addObjectCreate(prefix + "Host/Cluster",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Host/Cluster");
digester.addSetNext(prefix + "Host/Cluster",
"setCluster",
"org.apache.catalina.Cluster");
配置集群,集群的配置即可以在Engine级别,也可以在Host级别。
3.为Host添加生命周期管理
digester.addObjectCreate(prefix + "Host/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Host/Listener");
digester.addSetNext(prefix + "Host/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
此部分监听器由server.xml配置。默认情况下,Catalina未指定Host监听器。
4.为Host添加安全配置
digester.addObjectCreate(prefix + "Host/Valve",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Host/Valve");
digester.addSetNext(prefix + "Host/Valve",
"addValve",
"org.apache.catalina.Valve");
为Host添加安全配置以及拦截器Valve,具体拦截器类由className属性指定。Catalina为Host默认添加的拦截器为AccessLogValve,即用于记录访问日志。
4.2.5.Context的解析
Context的解析,位于ContextRuleSet类,digester.addRuleSet(new ContextRuleSet("Server/Service/Engine/Host/"));。
多数情况下,我们并不需要在server.xml中配置Context,而是由HostConfig自动扫描部署目录,以context.xml文件为基础进行解析创建。
1.创建Context实例
if (create) {
digester.addObjectCreate(prefix + "Context",
"org.apache.catalina.core.StandardContext", "className");
digester.addSetProperties(prefix + "Context");
} else {
digester.addRule(prefix + "Context", new SetContextPropertiesRule());
}
if (create) {
digester.addRule(prefix + "Context",
new LifecycleListenerRule
("org.apache.catalina.startup.ContextConfig",
"configClass"));
digester.addSetNext(prefix + "Context",
"addChild",
"org.apache.catalina.Container");
}
Context的解析会根据create属性的不同而有所区别,这主要是由于Context来源于多处。通过server.xml配置Context时,create是true,因此需要创建Context实例;而通过HostConfig自动创建Context时,create为false,此时仅需要解析节点即可。
2.为Context添加生命周期监听器
digester.addObjectCreate(prefix + "Context/Listener",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Listener");
digester.addSetNext(prefix + "Context/Listener",
"addLifecycleListener",
"org.apache.catalina.LifecycleListener");
具体监听器类由属性className指定。
3.为Context指定类加载器
digester.addObjectCreate(prefix + "Context/Loader",
"org.apache.catalina.loader.WebappLoader",
"className");
digester.addSetProperties(prefix + "Context/Loader");
digester.addSetNext(prefix + "Context/Loader",
"setLoader",
"org.apache.catalina.Loader");
默认为org.apache.catalina.loader.WebappLoader,通过className属性可以指定自己的实现类。
4.为Context添加会话管理器
digester.addObjectCreate(prefix + "Context/Manager",
"org.apache.catalina.session.StandardManager",
"className");
digester.addSetProperties(prefix + "Context/Manager");
digester.addSetNext(prefix + "Context/Manager",
"setManager",
"org.apache.catalina.Manager");
digester.addObjectCreate(prefix + "Context/Manager/Store",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Manager/Store");
digester.addSetNext(prefix + "Context/Manager/Store",
"setStore",
"org.apache.catalina.Store");
digester.addObjectCreate(prefix + "Context/Manager/SessionIdGenerator",
"org.apache.catalina.util.StandardSessionIdGenerator",
"className");
digester.addSetProperties(prefix + "Context/Manager/SessionIdGenerator");
digester.addSetNext(prefix + "Context/Manager/SessionIdGenerator",
"setSessionIdGenerator",
"org.apache.catalina.SessionIdGenerator");
默认实现为StandardManager,同时为管理器指定会话存储方式和会话标识生成器。Context提供了多种会话管理方式。
5.为Context添加初始化参数
digester.addObjectCreate(prefix + "Context/Parameter",
"org.apache.tomcat.util.descriptor.web.ApplicationParameter");
digester.addSetProperties(prefix + "Context/Parameter");
digester.addSetNext(prefix + "Context/Parameter",
"addApplicationParameter",
"org.apache.tomcat.util.descriptor.web.ApplicationParameter");
通过该配置,为Context添加初始化参数。
6.为Context添加安全配置以及web资源配置
digester.addRuleSet(new RealmRuleSet(prefix + "Context/"));
digester.addObjectCreate(prefix + "Context/Resources",
"org.apache.catalina.webresources.StandardRoot",
"className");
digester.addSetProperties(prefix + "Context/Resources");
digester.addSetNext(prefix + "Context/Resources",
"setResources",
"org.apache.catalina.WebResourceRoot");
digester.addObjectCreate(prefix + "Context/Resources/PreResources",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Resources/PreResources");
digester.addSetNext(prefix + "Context/Resources/PreResources",
"addPreResources",
"org.apache.catalina.WebResourceSet");
digester.addObjectCreate(prefix + "Context/Resources/JarResources",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Resources/JarResources");
digester.addSetNext(prefix + "Context/Resources/JarResources",
"addJarResources",
"org.apache.catalina.WebResourceSet");
digester.addObjectCreate(prefix + "Context/Resources/PostResources",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Resources/PostResources");
digester.addSetNext(prefix + "Context/Resources/PostResources",
"addPostResources",
"org.apache.catalina.WebResourceSet");
7.为Context添加资源连接
digester.addObjectCreate(prefix + "Context/ResourceLink",
"org.apache.tomcat.util.descriptor.web.ContextResourceLink");
digester.addSetProperties(prefix + "Context/ResourceLink");
digester.addRule(prefix + "Context/ResourceLink",
new SetNextNamingRule("addResourceLink",
"org.apache.tomcat.util.descriptor.web.ContextResourceLink"));
为Context添加资源链接ContextResourceLink,用于J2EE命名服务。
8.为Context添加Valve
digester.addObjectCreate(prefix + "Context/Valve",
null, // MUST be specified in the element
"className");
digester.addSetProperties(prefix + "Context/Valve");
digester.addSetNext(prefix + "Context/Valve",
"addValve",
"org.apache.catalina.Valve");
为Context添加拦截器Valve。
9.为Context添加守护资源配置
digester.addCallMethod(prefix + "Context/WatchedResource",
"addWatchedResource", 0);
digester.addCallMethod(prefix + "Context/WrapperLifecycle",
"addWrapperLifecycle", 0);
digester.addCallMethod(prefix + "Context/WrapperListener",
"addWrapperListener", 0);
digester.addObjectCreate(prefix + "Context/JarScanner",
"org.apache.tomcat.util.scan.StandardJarScanner",
"className");
digester.addSetProperties(prefix + "Context/JarScanner");
digester.addSetNext(prefix + "Context/JarScanner",
"setJarScanner",
"org.apache.tomcat.JarScanner");
digester.addObjectCreate(prefix + "Context/JarScanner/JarScanFilter",
"org.apache.tomcat.util.scan.StandardJarScanFilter",
"className");
digester.addSetProperties(prefix + "Context/JarScanner/JarScanFilter");
digester.addSetNext(prefix + "Context/JarScanner/JarScanFilter",
"setJarScanFilter",
"org.apache.tomcat.JarScanFilter");
WatchedResource标签用于为Context添加监视资源,当这些资源发生变更时,Web应用将会被重新加载,默认为WEB-INF/web.xml
WrapperLifecycle标签用于为Context添加一个生命周期监听类,此类的实例并非添加到Context上,而是添加到Context包含的Wrapper上。
WrapperListener标签用于为Context添加一个容器监听类,此类同样添加到Wrapper上。
JarScanner标签用于为Context添加一个Jar扫描器。JarScanner扫描Web应用和类加载层级的Jar包。
10.为Context添加Cookie处理器
digester.addObjectCreate(prefix + "Context/CookieProcessor",
"org.apache.tomcat.util.http.Rfc6265CookieProcessor",
"className");
digester.addSetProperties(prefix + "Context/CookieProcessor");
digester.addSetNext(prefix + "Context/CookieProcessor",
"setCookieProcessor",
"org.apache.tomcat.util.http.CookieProcessor");
5.总结
本以为Digester就是对server.xml解析,能有多大的问题,不想梳理的,迫于不懂,梳理之后发现它这个设计模式还是挺棒的,用户只需要配置节点名,规则就行。通过栈获取元素。其他的都写好了,只需要用就行。很棒的设计模式,应该用的是策略模式的思想,非常棒。也是有不小收获的。
参考:
- 《xml解析技术及JDOM和DOM4J的比较》https://blog.csdn.net/weixin_41547486/article/details/80906700
- 《Digester:一个通用xml引擎的设计剖析》https://blog.csdn.net/iteye_1315/article/details/81691465
- 《官方文档》https://commons.apache.org/proper/commons-digester/guide/core.html
- 《Tomcat架构解析》—作者:刘光瑞
|
作者:岑宇 出处:http://www.cnblogs.com/cenyu/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
>
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号