hbase系列之:初识hbase
一、概述
在hadoop生态圈里,hbase可谓是鼎鼎大名。江湖传言,hbase可以实现数十亿行X数百万列的实时查询,可横向扩展存储空间。如果传言为真,那得好好了解了解hbase。本文从概念上介绍hbase,稍微有点抽象,但这是学习hbase必须要了解的基础理论;如果想直接了解hbase的实操内容,可跳过本博文。
二、hbase介绍
先看看hbase官方的介绍:hbase是hadoop数据库,是一个分布式的,可扩展的大数据存储库;当需要对大数据进行随机,实时读/写访问时,可以使用hbase数据库;hbase的目标是在商业硬件集群上托管非常大的表-数十亿行X百万列;hbase是一个开源的、分布式的、版本化的非关系型数据库,模仿Google的bigtable;正如bigtable利用Google文件系统提供分布式数据存储一样,hbase在hadoop和hdfs上提供类似的功能。
通俗来说:
1、Hbase是一个在HDFS(也可以是普通文件系统)上开发的面向列的分布式数据库,如果需要实时地随机访问超大规模数据集,可以使用HBASE。
2、Hbase能够简单的通过增加节点来达到现行扩展。
3、Hbase不是关系型数据库,不支持SQL。
三、hbase的基本概念
1、Hbase表中的单元格(cell)有版本号,默认情况下自动分配版本号,为数据插入Hbase表单元格的时间戳,单元格的内容是未经解释的字节数组。
2、Hbase中的行是根据键(row key)进行排序的。
3、Hbase中只允许主键建立索引,可以通过几种策略来优化其他字段的查询性能。
4、建表时必须先指定列族,表建好之后列族不可增加,列族中的列可以根据实际需要增加。
5、物理上,所有列族成员都在一起存储,由于调优都是居于列族的,所以所有列族成员都应该有相同的访问模式和大小特征。
6、区域:
①、hbase自动把表水平划分成区域,每个区域由它所属的表、所包含的第一行和最后一行(不包括)三个属性来表示;
②、区域是在hbase集群上分布数据的最小单位;
③、一个太大的而无法放在单台服务器上的表会被放到服务器集群上,其中每个节点都负责管理表所有区域的一个
7、加锁:无论设计多少列,hbase对行的更新都是“原子的”。
四、hbase的作用
1、海量数据存储:能够存储百亿行数据和百万列数据。
2、准实时查询:能够在百毫秒内返回查询数据。
五、hbase的特点
1、容量大:Hbase单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数量级都非常具有弹性。(一般关系型数据库行在500万以下,列在30列一下。)
2、面向列:Hbase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。(实时动态增加列;单独对某一列做一些操作)
3、多版本:Hbase每一列的数据存储有多个Version。
4、稀疏性:为空的列并不占用存储空间,表可以设计得非常稀疏。
5、扩展性:底层依赖于hdfs。如果磁盘空间不够时,增加datanode节点或增加datanode节点的存储即可。
6、高可靠性:WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重问题时,数据不会发生丢失或损坏。而且Hbase底层使用hdfs,hdfs本身也有备份机制。
7、高性能:底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得Hbase有非常高的写入性能。region切分、主键索引和缓存机制使得Hbase在海量数据下具备一定的随机读取性,该性能针对Rowkey的查询可以达到毫秒级别。
六、hbase与关系型数据库的简要比较

七、hbase架构
hbase架构图如下图所示:
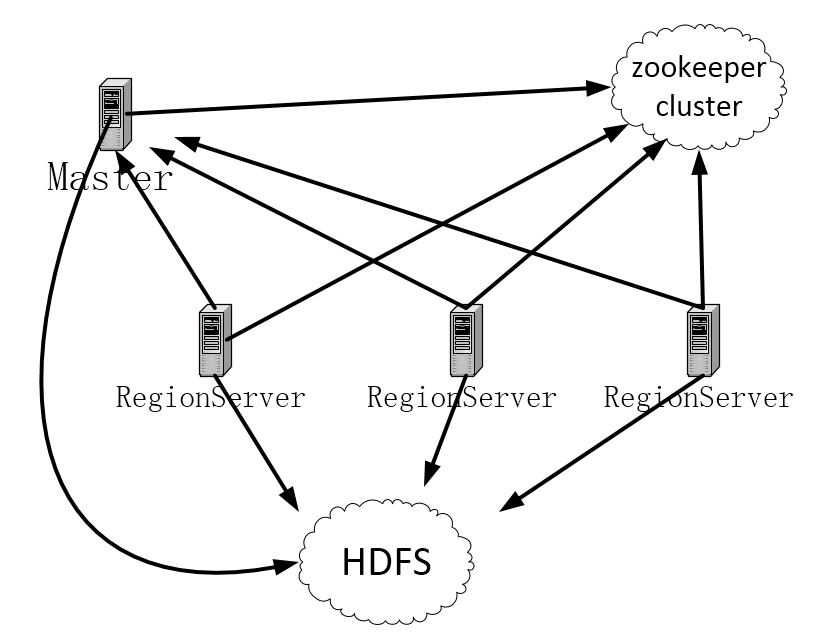
- Master
Master负责监视集群中的所有RegionServer实例、转移故障RegionServer、划分区域,并且是所有元数据更改的接口。在分布式集群中,Master通常运行在NameNode上运行。集群中可以存在多个Master(multi-Master),但是只有一个Master处于活跃状态(active),其他Master处于备份状态(Backup),如果活跃Master宕机或者发生异常,将从备份Master中选举出新的活跃Master来接管集群。
- hdfs
通常,Hbase使用hdfs来持久化数据。默认情况下,hbase是把数据存储在本地文件系统中,但是,如果要使用Hbase集群,就需要把Hbase的存储位置指向hdfs集群。
- zookeeper
Hbase依赖zookeeper来实现分布式协调。zookeeper管理hbase:meta目录表的位置以及当前集群的主机地址等信息;当客户端要连接到Hbase集群时,需要通过zookeeper来连接hbase集群。
- RegionServer
RegionServer负责服务和管理区域(region),还负责区域的划分并通知Hbase Master有了新的子区域;RegionServer包含多个region,是直接存储数据的地方,在分布式集群中,RegionServer在DataNode上运行。
八、hbase应用场景
hbase可以用在交通、金融、电商、移动等超大规模数据的领域。
九、总结
hbase为亿级数据秒级响应而生,从底层架构到存储模式,专为超大规模数据的存储而设计,但是查询条件不能多样化。在选择hbase作为数据库时,应考虑其利弊,适应用场景慎重选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号