
k8s学习笔记-网络模型和网络插件
Linux网络名词解释:
1、网络的命名空间:
Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;docker利用这一特性,实现不容器间的网络隔离。
2、Veth设备对:
Veth设备对的引入是为了实现在不同网络命名空间的通信。
3、Iptables/Netfilter:
Netfilter负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核 模式中;
Iptables模式是在用户模式下运行的进程,负责协助维护内核中Netfilter的各种规则表;
通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
4、网桥:
网桥是一个二层网络设备,通过网桥可以将linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
5、路由:
Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里
在Kubernetes网络中存在两种IP(Pod IP和Service Cluster IP),Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,Service Cluster IP它是一个虚拟IP
是由kube-proxy使用Iptables/ipvs规则重新定向到其本地端口,再均衡到后端Pod的。
下面讲讲Kubernetes Pod网络设计模型:
kubernetes网络模型
1. 基础原则
每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中,不管是否运行在同一Node上都可以通过Pod的IP来访问。
k8s中Pod的IP是最小粒度IP。同一个Pod内所有的容器共享一个网络堆栈,该模型称为IP-per-Pod模型。
Pod由docker0实际分配的IP,Pod内部看到的IP地址和端口与外部保持一致。同一个Pod内的不同容器共享网络,可以通过localhost来访问对方的端口,类似同一个VM内的不同进程。
IP-per-Pod模型从端口分配、域名解析、服务发现、负载均衡、应用配置等角度看,Pod可以看作是一台独立的VM或物理机。
2. k8s对集群的网络要求
所有容器都可以不用NAT的方式同别的容器通信。
所有节点都可以在不同NAT的方式下同所有容器通信,反之亦然。
容器的地址和别人看到的地址是同一个地址。
这里我们回顾一下之前的docker 的网络基础,下图展示了Docker网络在整个Docker生态技术栈中的位置
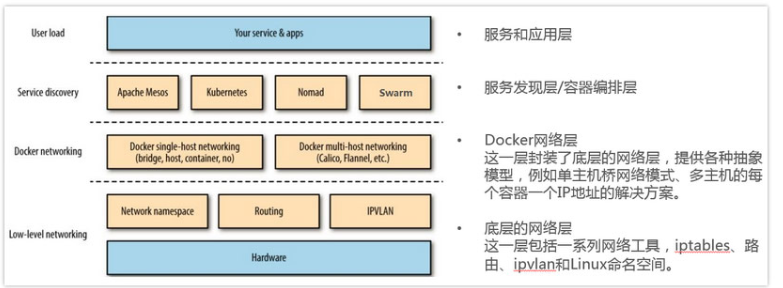
1、单机网络模式:Bridge 、Host、Container、None,这里具体就不赘述了。

参考文章:https://blog.csdn.net/wangguohe/article/details/81535942
2、多机网络模式:
一类是 Docker 在 1.9 版本中引入Libnetwork项目,对跨节点网络的原生支持;
一类是通过插件(plugin)方式引入的第三方实现方案,比如 Flannel,Calico 等等。
k8s网络通信:
1.容器内通信
同一个Pod的容器共享同一个网络命名空间,它们之间的访问可以用localhost地址 + 容器端口就可以访问

2.Pod 通信:Pod IP <---> Pod IP
a.同一Node中Pod的默认路由都是docker0的地址,由于它们关联在同一个docker0网桥上,地址网段相同,它们之间应当是能直接通信的。
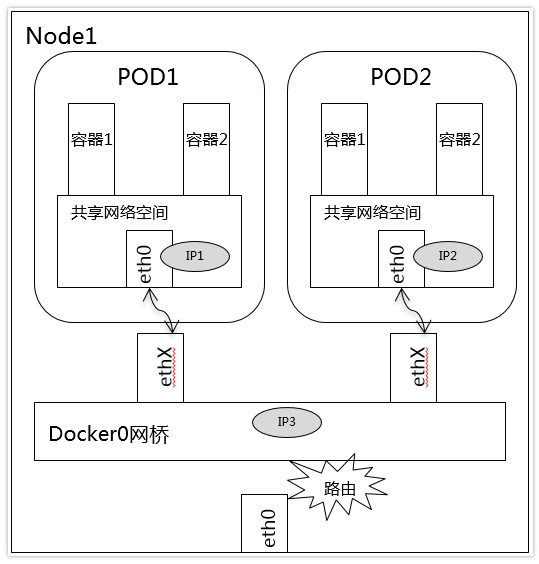
b.不同Node中Pod间通信要满足2个条件: Pod的IP不能冲突; 将Pod的IP和所在的Node的IP关联起来,通过这个关联让Pod可以互相访问, 通过第三方网络插件来创建覆盖网络,比如Flannel
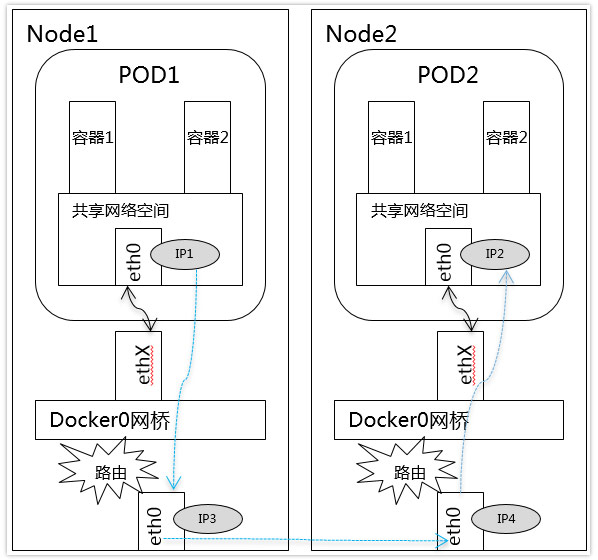
3.Pod与Service通信:Pod IP <---> cluster IP
Service是一组Pod的服务抽象,相当于一组Pod的LB,负责将请求分发给对应的
Pod;Service会为这个LB提供一个IP,一般称为ClusterIP。
4.Service 与集群外部客户端的通信:实现方式:Ingress、NodePort、Loadbalance
Kubernetes网络开源组件
1、技术术语:
IPAM:IP地址管理;这个IP地址管理并不是容器所特有的,传统的网络比如说DHCP其实也是一种IPAM,到了容器时代我们谈IPAM
主流的两种方法: 基于CIDR的IP地址段分配地或者精确为每一个容器分配IP。但总之一旦形成一个容器主机集群之后,上面的容器都要给它分配一个全局唯一的IP地址,这就涉及到IPAM的话题。
Overlay:在现有二层或三层网络之上再构建起来一个独立的网络,这个网络通常会有自己独立的IP地址空间、交换或者路由的实现。
IPSesc:一个点对点的一个加密通信协议,一般会用到Overlay网络的数据通道里。
vxLAN:由VMware、Cisco、RedHat等联合提出的这么一个解决方案,这个解决方案最主要是解决VLAN支持虚拟网络数量(4096)过少的问题。
因为在公有云上每一个租户都有不同的VPC,4096明显不够用。就有了vxLAN,它可以支持1600万个虚拟网络,基本上公有云是够用的。
网桥Bridge: 连接两个对等网络之间的网络设备,但在今天的语境里指的是Linux Bridge,就是大名鼎鼎的Docker0这个网桥。
BGP: 主干网自治网络的路由协议,今天有了互联网,互联网由很多小的自治网络构成的,自治网络之间的三层路由是由BGP实现的。
SDN、Openflow: 软件定义网络里面的一个术语,比如说我们经常听到的流表、控制平面,或者转发平面都是Openflow里的术语。
容器网络方案:
隧道方案( Overlay Networking )
隧道方案在IaaS层的网络中应用也比较多,大家共识是随着节点规模的增长复杂度会提升,而且出了网络问题跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点。
- Weave:UDP广播,本机建立新的BR,通过PCAP互通
- Open vSwitch(OVS):基于VxLan和GRE协议,但是性能方面损失比较严重
- Flannel:UDP广播,VxLan
- Racher:IPsec
路由方案
路由方案一般是从3层或者2层实现隔离和跨主机容器互通的,出了问题也很容易排查。
- Calico:基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
- Macvlan:从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
3、CNM & CNI阵营:
容器网络发展到现在,形成了两大阵营,就是Docker的CNM和Google、CoreOS、Kuberenetes主导的CNI。
首先明确一点:
CNM和CNI并不是网络实现,他们是网络规范和网络体系,从研发的角度他们就是一堆接口,你底层是用Flannel也好、用Calico也好,他们并不关心,CNM和CNI关心的是网络管理的问题。
CNM(Docker LibnetworkContainer Network Model):
Docker Libnetwork的优势就是原生,而且和Docker容器生命周期结合紧密;缺点也可以理解为是原生,被Docker“绑架”。
- Docker Swarm overlay
- Macvlan & IP networkdrivers
- Calico
- Contiv
- Weave
CNI(Container NetworkInterface):
CNI的优势是兼容其他容器技术(e.g. rkt)及上层编排系统(Kubernetes & Mesos),而且社区活跃势头迅猛,Kubernetes加上CoreOS主推;缺点是非Docker原生。
- Kubernetes
- Weave
- Macvlan
- Calico
- Flannel
- Contiv
- Mesos CNI
硬件交换:SR-IOV 单根IO虚拟化
这里我们用CNI
k8s加载CNI 的地方
kubelet /etc/cni/net.d/
cat /etc/cni/net.d/10-flannel.conflist

 浙公网安备 33010602011771号
浙公网安备 33010602011771号