python学习笔记二
用python获取数据:

抓取:
Requests库

解析:
BeautifulSoup:一个可以从HTML或XML文件中提取数据的Python库。
官网:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
生成BeautifulSoup的对象soup后,可使用soup.tag得到标签内容
tag中最重要的属性:name、attributes
获取tag名字的方法:

获取tag属性的方法:

获取tag中非属性的字符串:

寻找所有的某个标签的内容:

find_all方法+属性:
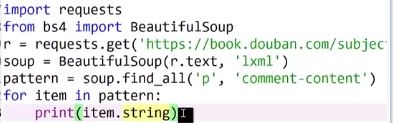
寻找第一个标签的内容:
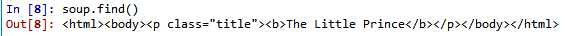
补充: 推荐博客https://www.cnblogs.com/hanmk/p/8724162.html
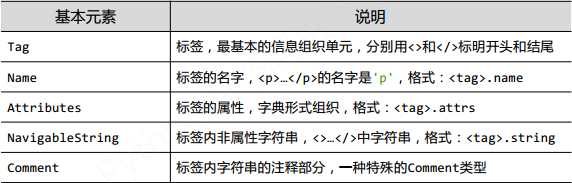
上课的示例代码:
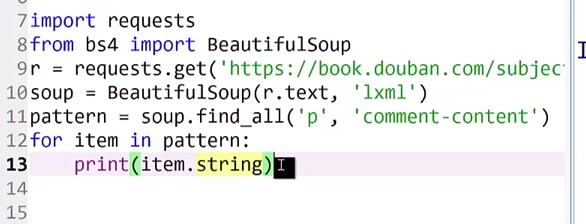
发现老师上课用的代码运行不出结果,原来是打印string时不能跨越多个标签,只能从最里层的标签开始打印,目前我也不知道为什么。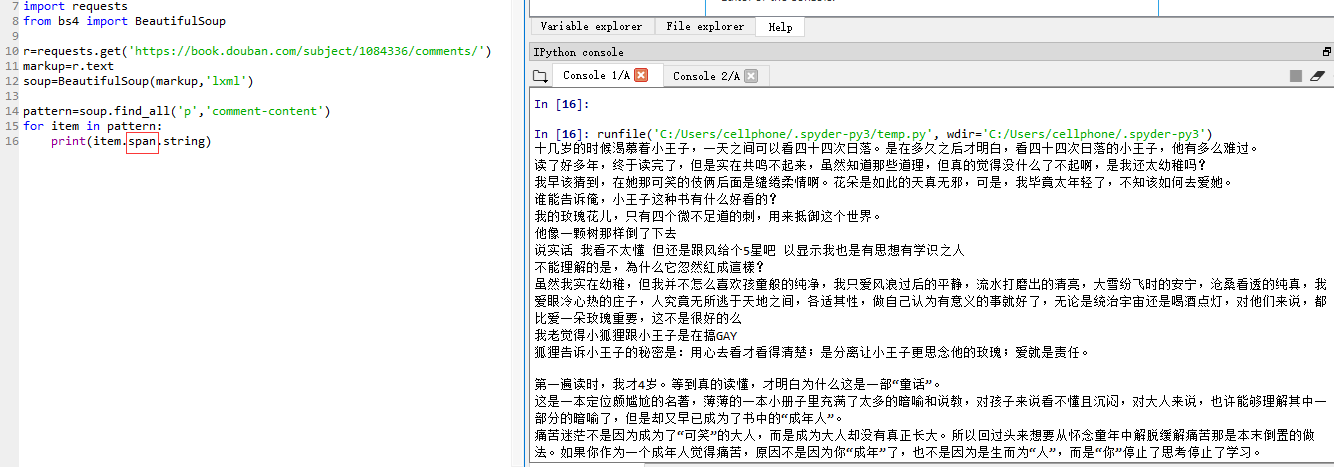
Regex:进行各类正则表达式处理
参考网站:
https://docs.python.org/3.5/library/re.html
python中的序列:
包括 字符串、列表、元组
序列元素的访问:

序列的操作类型:

标准类型运算符:

序列类型运算符:

类型转换内建函数:
list():将一个字符串转化为列表
tuple():将一个字符串转化为元组
str():将一个列表或者元组转化为字符串
序列类型可用内建函数:

python中的字符串:
三引号可以使字符串保持原貌:

r可以简化文件路径:

双引号使得单引号使用方便:
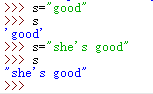
字符串与输出形式:
![]()
类型说明符:


字符串(s)默认的对齐方式为左对齐,整数的默认方式为右对齐
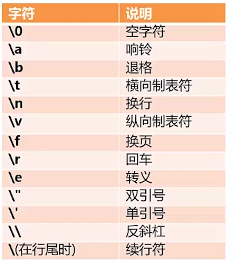
python中的转义字符:
python中的列表:
列表是可变数据类型,字符串是不可变数据类型
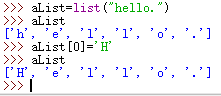
可以更改列表中的元素:
列表中可以包含不同类型的对象:


在列表中加入元素:
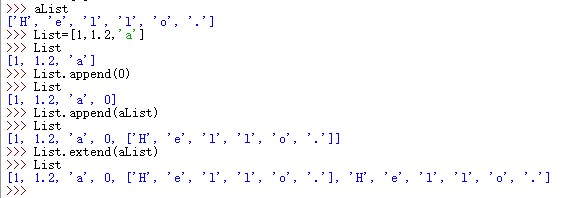
在列表中减去元素:
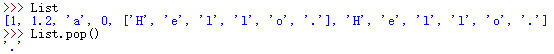

sort函数和sorted函数的区别:
>>> a=[1,3,5,2,9,4,7,8,6,0] >>> a.sort() >>> a [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a=[1,3,5,2,9,4,7,8,6,0] >>> sorted(a) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> a [1, 3, 5, 2, 9, 4, 7, 8, 6, 0]
sort函数的进一步用法:
>>> List=[3,4,5,2,1] >>> List.sort(reverse=True) >>> List [5, 4, 3, 2, 1] >>> strList=['abab','aa','b','ccccccc'] >>> strList.sort(key=len) >>> strList ['b', 'aa', 'abab', 'ccccccc']
reverse函数和reversed函数的区别:
>>> List1=[1,3,5,7,9] >>> List1.reverse() >>> List1 [9, 7, 5, 3, 1]
>>> List2=[2,4,6,8,10] >>> List3=reversed(List2) >>> List2 [2, 4, 6, 8, 10] >>> List3 <list_reverseiterator object at 0x00315F30>
reversed函数返回的是一个reverse 的迭代器
列表解析:


生成器表达式:


python中的元组:
元组是不可变数据类型,其一般使用与列表类似。
创造具有一个元素的元组:
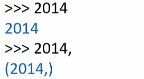
元组和列表的区别:
由于元组不可变,故对于那些会改变元组本身的方法不能使用,如sort()函数,对于列表可用;对于元组,使用时会报错。sorted()函数没有真正改变元组的内容,故可以使用
元组的作用:
1.在映射类型中当作键使用
2.函数的特殊类型参数
3.作为函数
元组作为函数的特殊类型参数:可变长位置参数
>>> def foo(arg1,*arg2): print(arg1) print(arg2) >>> foo("hello","good","morning","!") hello ('good', 'morning', '!')
元组作为函数的特殊返回类型:
>>>def foo(): return 1,2,3 >>>foo() (1,2,3)

python中的字典:
key(不可变数据类型)->value
创建字典:
1.直接创建

2.利用dict函数


将所有的key设置一个默认值:


将两个列表的元素组成字典:

从列表中构造字典:
如:


字典的使用:增删(del)改查(in/直接用键值查找)
dict2 = dict1 ->将dict2和dict1关联对应到同一个字典,执行例如dict1['score'] = 99的操作后,dict2中的内容也会受影响
字典的内建函数:dict(),len(),hash()
hash() ->判断某个对象是不是可哈希的->是不是不可变的
若一个对象是可哈希的(不可变的),则会出现哈希值;否则,会出现异常
单独输出字典的key or value:

更新 新旧的两个字典:

查找字典较为明智的方法:

清空字典:clear()



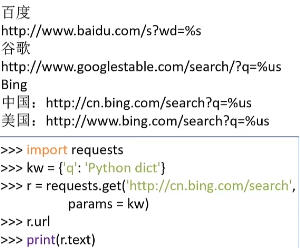
搜索引擎关键词查询中字典的使用:
字典充当可变长关键字参数;元组充当可变长位置参数

python中的集合:


集合的比较:


补充:
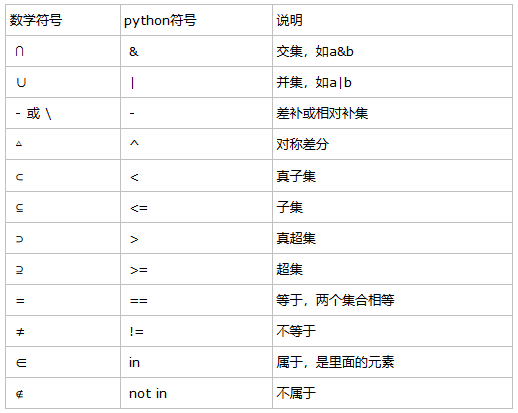
集合中的内建函数:
1.面向所有集合:

union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)
2.面向可变类型的集合:
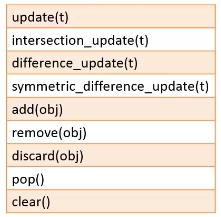
其中,add和update的区别如下:

python中的扩展库 SciPy:
SciPy中的数据结构:
-ndarray(N维数组)
-Series(变长字典)
-DataFrame(数据框)
SciPy中的NumPy:

创建数组:

代数运算计算行列式:

python中的数组:

用ndarray表示的数组:

ndarray的属性:

如一个二维数组:
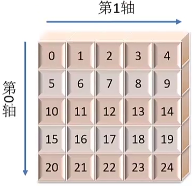
ndarray的创建:


ndarray的操作:


ndarray的运算:

注意:这里的矩阵乘法和线代中的矩阵乘法不一样

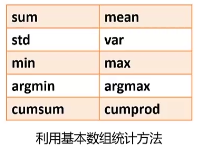
var->方差;std->标准差
ndarray在线代中的应用:


nadarray的ufunc函数:

python中的变长字典Series:
SciPy中的Matplotlib:

SciPy中的pandas:

Series中的键值是相互独立的(与字典的区别)
Series是一个有序定长的字典,类似一堆数组的对象,由数据和索引组成,对应一维序列
Series的创建:

自定义的创建方式:
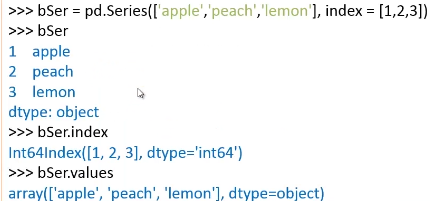
Series的基本运算:
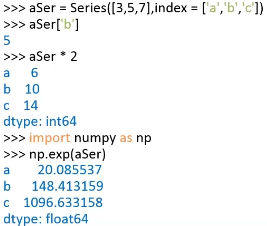
exp(N)->计算自然对数的N次方
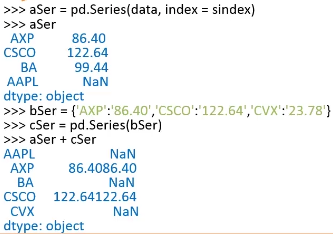
Series的数据对齐:

用Series自动对齐不同索引的数据:
Series的name属性:

DataFrame:
对应二维表结构,表格型的数据结构->相当于共享同一个index的Series的集合:

创建一个DataFrame:
1.

2.

DataFrame的基本操作:

iloc->某个区域
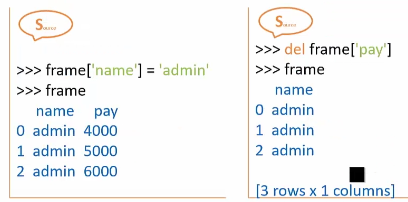
DataFrame对象的修改和删除:
DataFrame的统计功能:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号