大数据笔记-基于mapreduce的并行算法
7.1 mapreduce


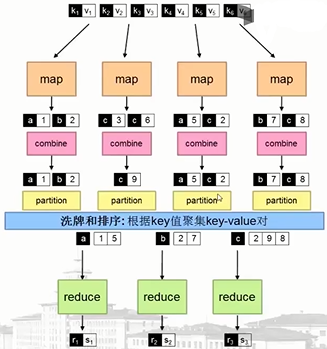
mapreduce编程:


同步工具:

实现时需要注意的地方:

本地聚合的重要性:

字数统计:

map进化1:引入数组H(仍然需要combiner)

map进化2:把数组H变为全局变量,map结束后再将H输出

(in-mapper的实现)本地聚合的设计模式:
将combiner的功能集成到mapper中(速度更快,in-mapper是内存上的操作->需要内存管理)

计算平均数:
combiner的设计:

example:
map version1:(此时reducer不能代替combiner)

version 2:(存在的问题:mapper的输出不是reducer的输入->影响了程序的正确性)

version 3:正确版本

in-mapper版本:(此时不需要combiner,可以减少通信量)

单词共现矩阵的计算:



方法1:词对法

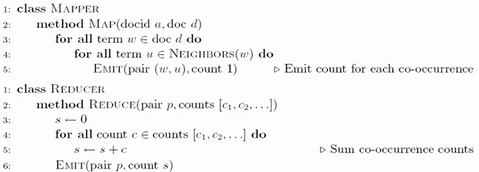
存在的问题:

估计相对频率:


同步的实现:将同步变成一个排序问题

方法2:条纹法


存在的问题:

估计相对频率:

同步的实现:构造数据结构使部分结果聚集到一起

再现概括总结:同步工具

tradeoff:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号