Hadoop-MapReduce
7.1.2MapReduce模型
Master/Slave架构:

Map函数:
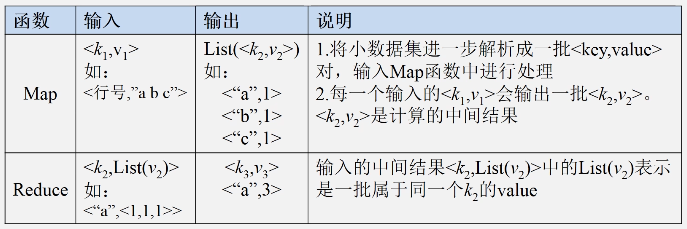
Reduce函数:

MapReduce的体系结构:
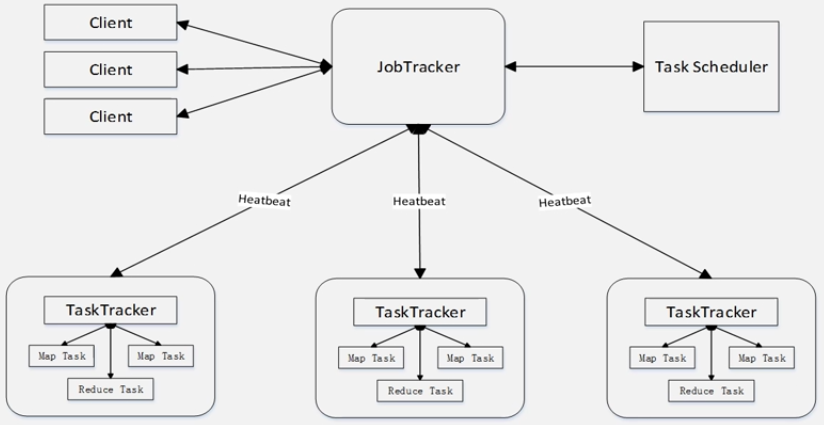
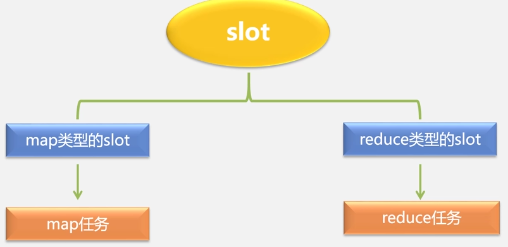
TaskTracker通过slot监控自己的资源使用情况(以slot为单位调度资源)
MapReduce的执行过程:
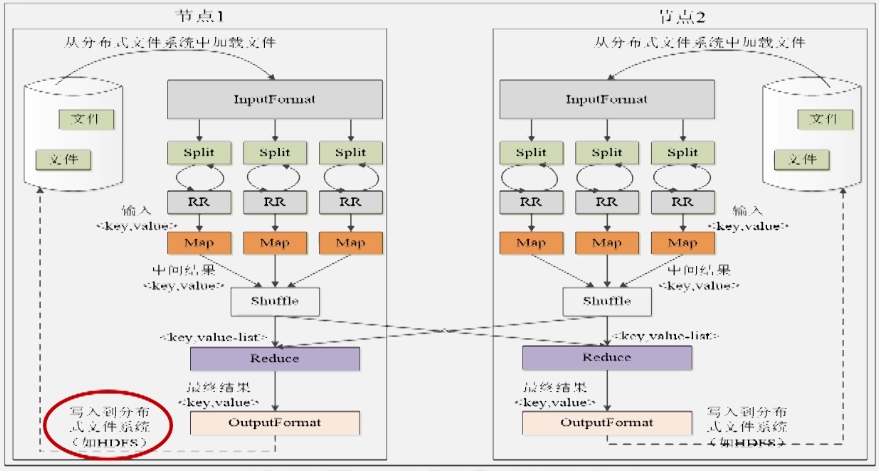
map的数量:最优情况下和分片的数量相同
reduce的数量:比slot的数量少一点(预留出一部分资源处理错误情况)[1.0版本]
shuffle的过程(包含map端的shuffle和reduce端的shuffle):
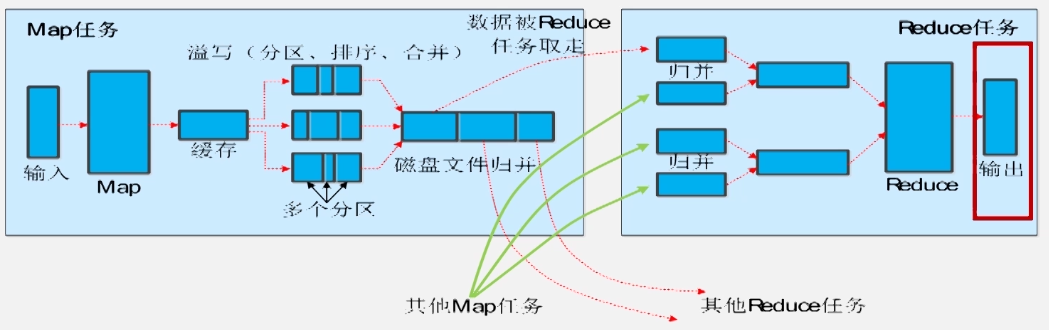
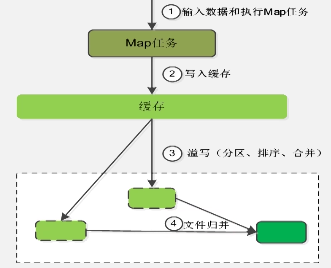
map端的shuffle(这里的合并:combine(key,totalvalue);归并:merge(key,value-list)):
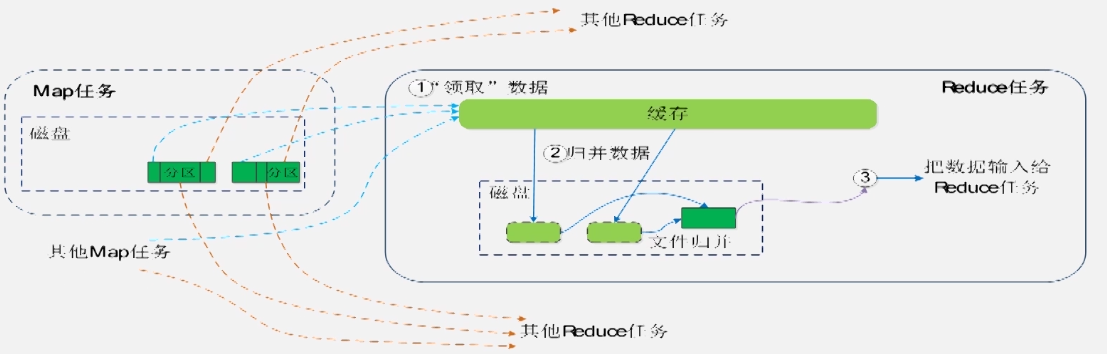
reduce端的shuffle:
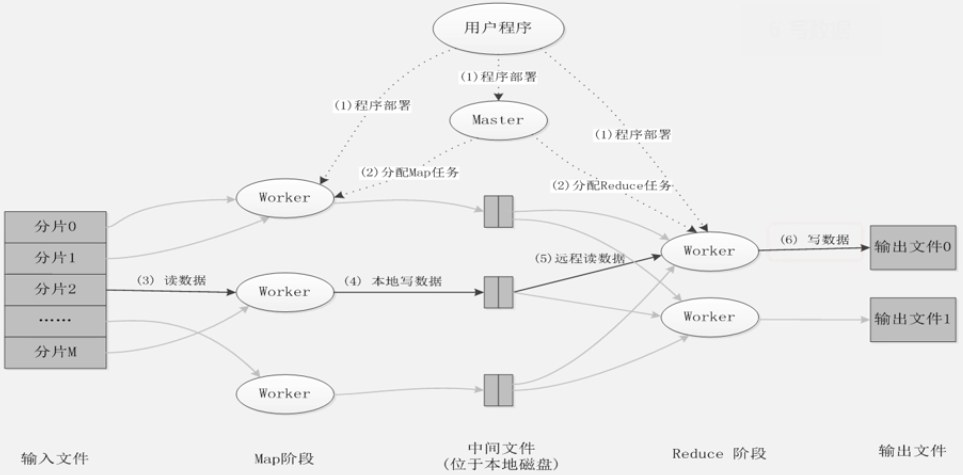
MapReduce应用程序的执行过程:
MapReduce能解决的问题:满足分而治之
MapReduce实例分析:

没有定义combine的结果:

定义combine后的结果:
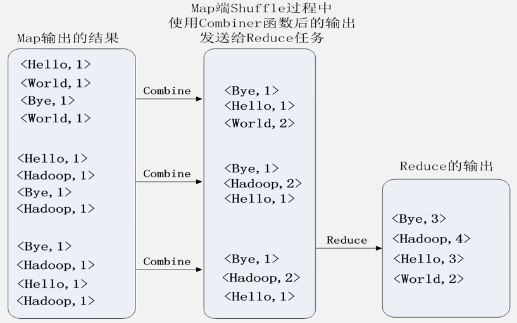
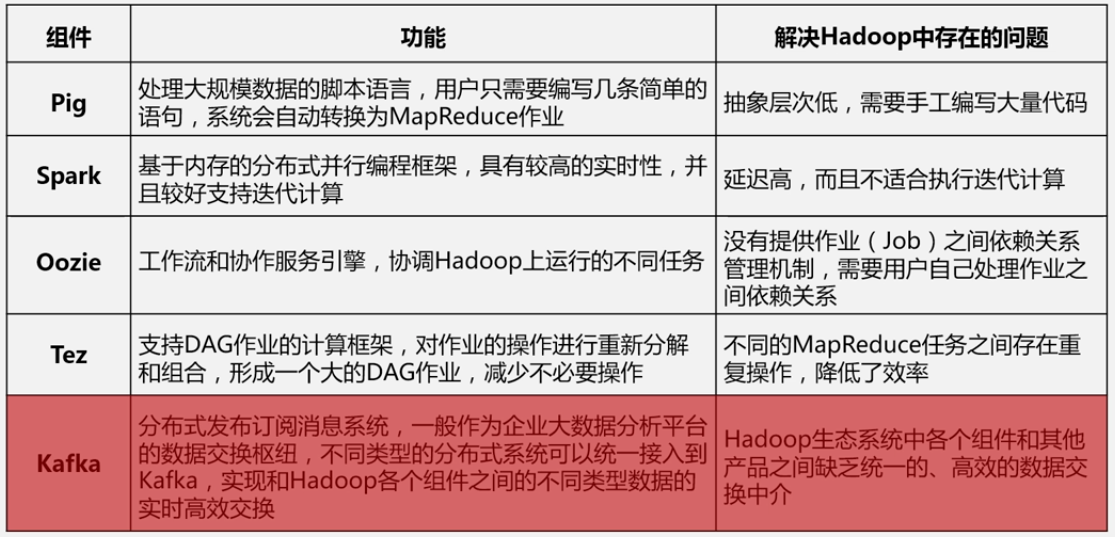
MapReduce的具体应用:
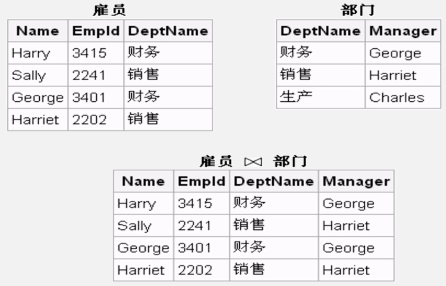
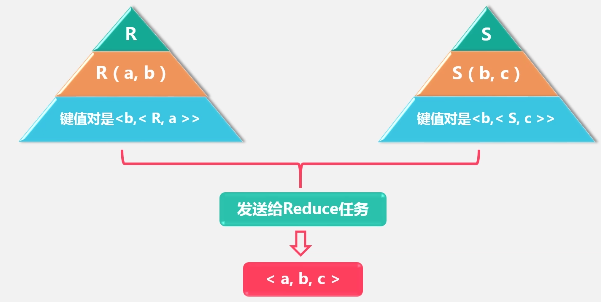
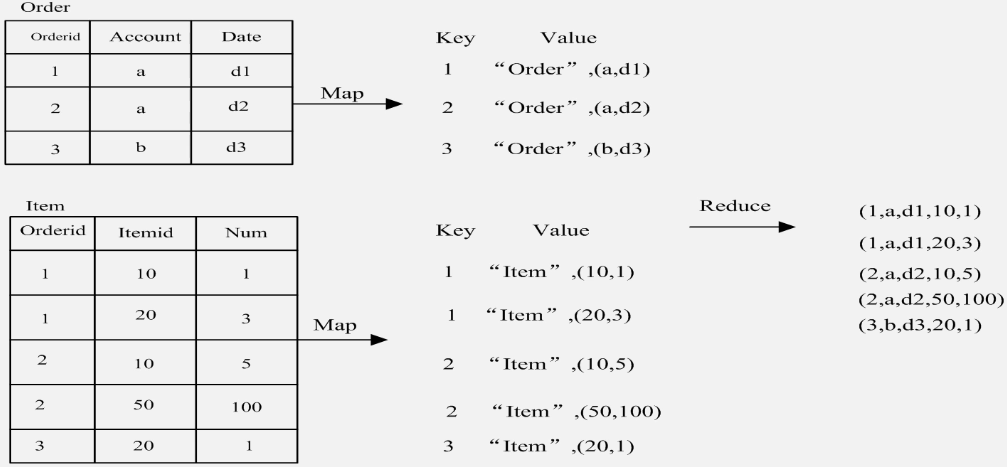
MapReduce自然连接实例分析:
9.1:不断完善的Hadoop生态系统
9.2:HDFS的高可用性

9.3:资源管理调度框架YARN
YARN的设计思路:
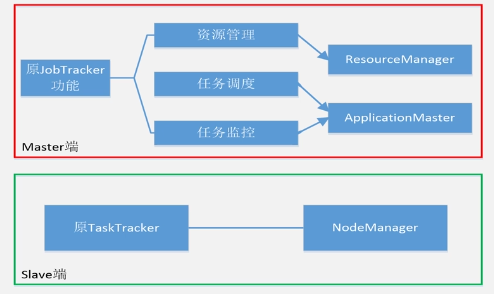
YARN的体系结构:
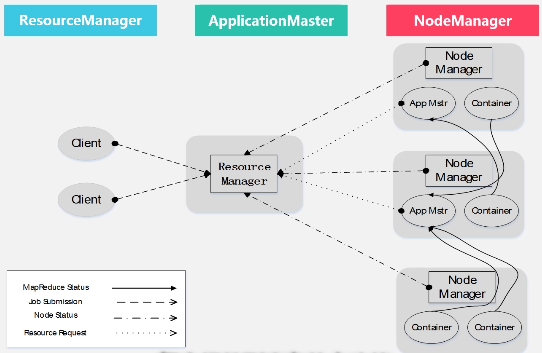
ResourceManager:
1.处理客户端请求
2.启动/监控ApplicationMaster
3.监控NoodeManager
4.资源分配与调度

调度器:



应用程序管理器:

ApplicationMaster:
1.为应用程序申请资源,并分配给内部任务
2.仍无调度、监控与容错

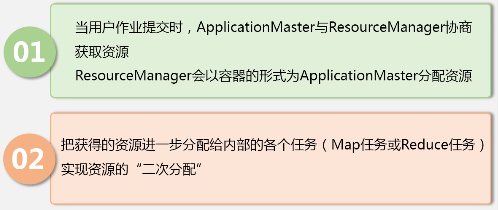



NodeManager:
1.单个节点上的资源管理
2.处理来自ResourceManager的命令
3.处理来自ApplicationMaster的命令
NodeManager是驻留在YARn集群中的每个节点上的代理:


9.3.4:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号