神经网络
神经元模型的使用可以这样理解:
我们有一个数据,称之为样本。样本有四个属性,其中三个属性已知,一个属性未知。我们需要做的就是通过三个已知属性预测未知属性。
具体办法就是使用神经元的公式进行计算。三个已知属性的值是a1,a2,a3,未知属性的值是z。z可以通过公式计算出来。
这里,已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
由此可见,使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
1. 两层神经网络
结构
需要说明的是,至今为止,我们对神经网络的结构图的讨论中都没有提到偏置节点(bias unit)。事实上,这些节点是默认存在的。它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。正如线性回归模型与逻辑回归模型中的一样。
偏置单元与后一层的所有节点都有连接,我们设这些参数值为向量b,称之为偏置。如下图。
图23 两层神经网络(考虑偏置节点)
可以看出,偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)。有些神经网络的结构图中会把偏置节点明显画出来,有些不会。一般情况下,我们都不会明确画出偏置节点。
在考虑了偏置以后的一个神经网络的矩阵运算如下:
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
需要说明的是,在两层神经网络中,我们不再使用sgn函数作为函数g,而是使用平滑函数sigmoid作为函数g。我们把函数g也称作激活函数(active function)。
事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。初学者可能认为画神经网络的结构图是为了在程序中实现这些圆圈与线,但在一个神经网络的程序中,既没有“线”这个对象,也没有“单元”这个对象。实现一个神经网络最需要的是线性代数库。
效果
与单层神经网络不同。理论证明,两层神经网络可以无限逼近任意连续函数。
这是什么意思呢?也就是说,面对复杂的非线性分类任务,两层(带一个隐藏层)神经网络可以分类的很好。
下面就是一个例子(此两图来自colah的博客),红色的线与蓝色的线代表数据。而红色区域和蓝色区域代表由神经网络划开的区域,两者的分界线就是决策分界。
图24 两层神经网络(决策分界)
可以看到,这个两层神经网络的决策分界是非常平滑的曲线,而且分类的很好。有趣的是,前面已经学到过,单层网络只能做线性分类任务。而两层神经网络中的后一层也是线性分类层,应该只能做线性分类任务。为什么两个线性分类任务结合就可以做非线性分类任务?
我们可以把输出层的决策分界单独拿出来看一下。就是下图。
图25 两层神经网络(空间变换)
可以看到,输出层的决策分界仍然是直线。关键就是,从输入层到隐藏层时,数据发生了空间变换。也就是说,两层神经网络中,隐藏层对原始的数据进行了一个空间变换,使其可以被线性分类,然后输出层的决策分界划出了一个线性分类分界线,对其进行分类。
这样就导出了两层神经网络可以做非线性分类的关键--隐藏层。联想到我们一开始推导出的矩阵公式,我们知道,矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。因此,隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。
两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。
下面来讨论一下隐藏层的节点数设计。在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。因此,“自由”把握在设计者的手中。但是,节点数设置的多少,却会影响到整个模型的效果。如何决定这个自由层的节点数呢?目前业界没有完善的理论来指导这个决策。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择效果最好的值作为最终选择。这种方法又叫做Grid Search(网格搜索)。
了解了两层神经网络的结构以后,我们就可以看懂其它类似的结构图。例如EasyPR字符识别网络架构(下图)。
图26 EasyPR字符识别网络
训练
下面简单介绍一下两层神经网络的训练。
在Rosenblat提出的感知器模型中,模型中的参数可以被训练,但是使用的方法较为简单,并没有使用目前机器学习中通用的方法,这导致其扩展性与适用性非常有限。从两层神经网络开始,神经网络的研究人员开始使用机器学习相关的技术进行神经网络的训练。例如用大量的数据(1000-10000左右),使用算法进行优化等等,从而使得模型训练可以获得性能与数据利用上的双重优势。
机器学习模型训练的目的,就是使得参数尽可能的与真实的模型逼近。具体做法是这样的。首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。
loss = (yp - y)2
这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。
如果将先前的神经网络预测的矩阵公式带入到yp中(因为有z=yp),那么我们可以把损失写为关于参数(parameter)的函数,这个函数称之为损失函数(loss function)。下面的问题就是求:如何优化参数,能够让损失函数的值最小。
此时这个问题就被转化为一个优化问题。一个常用方法就是高等数学中的求导,但是这里的问题由于参数不止一个,求导后计算导数等于0的运算量很大,所以一般来说解决这个优化问题使用的是梯度下降算法。梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。
在神经网络模型中,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。反向传播算法是利用了神经网络的结构进行的计算。不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
反向传播算法可以直观的理解为下图。梯度的计算从后往前,一层层反向传播。前缀E代表着相对导数的意思。
图27 反向传播算法

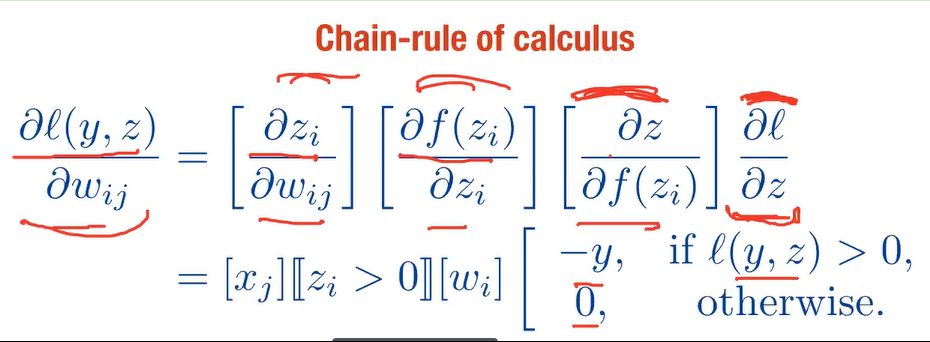
反向传播算法的启示是数学中的链式法则。在此需要说明的是,尽管早期神经网络的研究人员努力从生物学中得到启发,但从BP算法开始,研究者们更多地从数学上寻求问题的最优解。不再盲目模拟人脑网络是神经网络研究走向成熟的标志。正如科学家们可以从鸟类的飞行中得到启发,但没有必要一定要完全模拟鸟类的飞行方式,也能制造可以飞天的飞机。
优化问题只是训练中的一个部分。机器学习问题之所以称为学习问题,而不是优化问题,就是因为它不仅要求数据在训练集上求得一个较小的误差,在测试集上也要表现好。因为模型最终是要部署到没有见过训练数据的真实场景。提升模型在测试集上的预测效果的主题叫做泛化(generalization),相关方法被称作正则化(regularization)。神经网络中常用的泛化技术有权重衰减等。
2. 多层神经网络(深度学习)
结构
我们延续两层神经网络的方式来设计一个多层神经网络。
在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图。
图30 多层神经网络
依照这样的方式不断添加,我们可以得到更多层的多层神经网络。公式推导的话其实跟两层神经网络类似,使用矩阵运算的话就仅仅是加一个公式而已。
在已知输入a(1),参数W(1),W(2),W(3)的情况下,输出z的推导公式如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;
多层神经网络中,输出也是按照一层一层的方式来计算。从最外面的层开始,算出所有单元的值以后,再继续计算更深一层。只有当前层所有单元的值都计算完毕以后,才会算下一层。有点像计算向前不断推进的感觉。所以这个过程叫做“正向传播”。
下面讨论一下多层神经网络中的参数。
首先我们看第一张图,可以看出W(1)中有6个参数,W(2)中有4个参数,W(3)中有6个参数,所以整个神经网络中的参数有16个(这里我们不考虑偏置节点,下同)。
图31 多层神经网络(较少参数)
假设我们将中间层的节点数做一下调整。第一个中间层改为3个单元,第二个中间层改为4个单元。
经过调整以后,整个网络的参数变成了33个。
图32 多层神经网络(较多参数)
虽然层数保持不变,但是第二个神经网络的参数数量却是第一个神经网络的接近两倍之多,从而带来了更好的表示(represention)能力。表示能力是多层神经网络的一个重要性质,下面会做介绍。
在参数一致的情况下,我们也可以获得一个“更深”的网络。
图33 多层神经网络(更深的层次)
上图的网络中,虽然参数数量仍然是33,但却有4个中间层,是原来层数的接近两倍。这意味着一样的参数数量,可以用更深的层次去表达。
效果
与两层层神经网络不同。多层神经网络中的层数增加了很多。
增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
关于逐层特征学习的例子,可以参考下图。
图34 多层神经网络(特征学习)
更强的函数模拟能力是由于随着层数的增加,整个网络的参数就越多。而神经网络其实本质就是模拟特征与目标之间的真实关系函数的方法,更多的参数意味着其模拟的函数可以更加的复杂,可以有更多的容量(capcity)去拟合真正的关系。
通过研究发现,在参数数量一样的情况下,更深的网络往往具有比浅层的网络更好的识别效率。这点也在ImageNet的多次大赛中得到了证实。从2012年起,每年获得ImageNet冠军的深度神经网络的层数逐年增加,2015年最好的方法GoogleNet是一个多达22层的神经网络。
训练
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
1.影响
我们回顾一下神经网络发展的历程。神经网络的发展历史曲折荡漾,既有被人捧上天的时刻,也有摔落在街头无人问津的时段,中间经历了数次大起大落。
从单层神经网络(感知器)开始,到包含一个隐藏层的两层神经网络,再到多层的深度神经网络,一共有三次兴起过程。详见下图。
图36 三起三落的神经网络
上图中的顶点与谷底可以看作神经网络发展的高峰与低谷。图中的横轴是时间,以年为单位。纵轴是一个神经网络影响力的示意表示。如果把1949年Hebb模型提出到1958年的感知机诞生这个10年视为落下(没有兴起)的话,那么神经网络算是经历了“三起三落”这样一个过程,跟“小平”同志类似。俗话说,天将降大任于斯人也,必先苦其心志,劳其筋骨。经历过如此多波折的神经网络能够在现阶段取得成功也可以被看做是磨砺的积累吧。
历史最大的好处是可以给现在做参考。科学的研究呈现螺旋形上升的过程,不可能一帆风顺。同时,这也给现在过分热衷深度学习与人工智能的人敲响警钟,因为这不是第一次人们因为神经网络而疯狂了。1958年到1969年,以及1985年到1995,这两个十年间人们对于神经网络以及人工智能的期待并不现在低,可结果如何大家也能看的很清楚。
因此,冷静才是对待目前深度学习热潮的最好办法。如果因为深度学习火热,或者可以有“钱景”就一窝蜂的涌入,那么最终的受害人只能是自己。神经网络界已经两次有被人们捧上天了的境况,相信也对于捧得越高,摔得越惨这句话深有体会。因此,神经网络界的学者也必须给这股热潮浇上一盆水,不要让媒体以及投资家们过分的高看这门技术。很有可能,三十年河东,三十年河西,在几年后,神经网络就再次陷入谷底。根据上图的历史曲线图,这是很有可能的。
2.效果
下面说一下神经网络为什么能这么火热?简而言之,就是其学习效果的强大。随着神经网络的发展,其表示性能越来越强。
从单层神经网络,到两层神经网络,再到多层神经网络,下图说明了,随着网络层数的增加,以及激活函数的调整,神经网络所能拟合的决策分界平面的能力。
图37 表示能力不断增强
可以看出,随着层数增加,其非线性分界拟合能力不断增强。图中的分界线并不代表真实训练出的效果,更多的是示意效果。
神经网络的研究与应用之所以能够不断地火热发展下去,与其强大的函数拟合能力是分不开关系的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号