Sklearn用法
1.Sklearn通用学习模式
Sklearn中包含众多机器学习方法,但各种学习方法大致相同,我们在这里介绍Sklearn通用学习模式。
- 首先引入需要训练的数据,Sklearn自带部分数据集,也可以通过相应方法进行构造;
Sklearn datasets中我们会介绍如何构造数据。然后选择相应机器学习方法进行训练,训练过程中可以通过一些技巧调整参数,使得学习准确率更高;- 模型训练完成之后便可预测新数据,然后我们还可以通过
MatPlotLib等方法来直观的展示数据。 - 另外还可以将我们已训练好的Model进行保存,方便移动到其他平台,不必重新训练。
2.Sklearn数据预处理
数据集的标准化对于大部分机器学习算法来说都是一种常规要求,如果单个特征没有或多或少地接近于标准正态分布,那么它可能并不能在项目中表现出很好的性能。在实际情况中,我们经常忽略特征的分布形状,直接去均值来对某个特征进行中心化,再通过除以非常量特征(non-constant features)的标准差进行缩放。
例如, 许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差(比如径向基函数、支持向量机以及L1L2正则化项等)。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。例如我们可以通过Scale将数据缩放,达到标准化的目的。
标准化方法一、使用StandardScaler,fit(),transform();或者fit_transform()
为什么要进行归一化?
机器学习模型被互联网行业广泛应用,一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?维基百科给出的解释:
- 归一化后加快了梯度下降求最优解的速度;
如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
- 归一化有可能提高精度;
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
哪些机器学习算法不需要(需要)做归一化?
概率模型(树形模型)不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、SVM、LR、Knn、KMeans之类的最优化问题就需要归一化。
StandardScaler原理
作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。
标准差标准化(standardScale)使得经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
![]()
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
import numpy as np
from sklearn import linear_model
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
print("加载数据...\n")
data = np.loadtxt(r"C:\Users\admir\Desktop\机器学习\课程\第一节课\data.txt",delimiter=",",dtype=np.float64) #读取数据
X = np.array(data[:,0:-1],dtype=np.float64) # X对应0到倒数第2列
y = np.array(data[:,-1],dtype=np.float64) # y对应最后一列
plt.scatter(X[:,0],X[:,1])
# 标准化操作
scaler = StandardScaler()
scaler.fit(X)
x_train = scaler.transform(X)
x_test = scaler.transform(np.array([1650.0,3.0]).reshape(1,-1))
import numpy as np #矩阵标准差 x_np = np.array([[1.5, -1., 2.], [2., 0., 0.]]) mean = np.mean(x_np, axis=0) std = np.std(x_np, axis=0) print('矩阵初值为:{}'.format(x_np)) print('该矩阵的均值为:{}\n 该矩阵的标准差为:{}'.format(mean,std)) another_trans_data = x_np - mean another_trans_data = another_trans_data / std print('标准差标准化的矩阵为:{}'.format(another_trans_data))
#用sklearn
-
from sklearn.preprocessing import StandardScaler # 标准化工具
-
import numpy as np
-
-
x_np = np.array([[1.5, -1., 2.],
-
[2., 0., 0.]])
-
scaler = StandardScaler()
-
x_train = scaler.fit_transform(x_np)
-
print('矩阵初值为:{}'.format(x_np))
-
print('该矩阵的均值为:{}\n 该矩阵的标准差为:{}'.format(scaler.mean_,np.sqrt(scaler.var_)))
-
print('标准差标准化的矩阵为:{}'.format(x_train))
一般使用方法:
a) 先用fit
scaler = preprocessing.StandardScaler().fit(X)
这一步可以得到scaler,scaler里面存的有计算出来的均值和方差
b) 再用transform
scaler.transform(X)
这一步再用scaler中的均值和方差来转换X,使X标准化
c) 那么在预测的时候, 也要对数据做同样的标准化处理,即也要用上面的scaler中的均值和方差来对预测时候的特征进行标准化
注意:测试数据和预测数据的标准化的方式要和训练数据标准化的方式一样, 必须用同一个scaler来进行transform
方法二、使用preprocessing.scale()
from sklearn import preprocessing import numpy as np a=np.array([[10,2.7,3.6], [-100,5,-2], [120,20,40]],dtype=np.float64) print(a) print(preprocessing.scale(a))#将值的相差度减小 ''' [[ 10. 2.7 3.6] [-100. 5. -2. ] [ 120. 20. 40 [[ 0. -0.85170713 -0.55138018] [-1.22474487 -0.55187146 -0.852133 ] [ 1.22474487 1.40357859 1.40351318]]
###利用minmax方式对数据进行规范化### X=preprocessing.minmax_scale(X)#feature_range=(-1,1)可设置重置范围 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) clf=SVC() clf.fit(X_train,y_train) print(clf.score(X_test,y_test)) #0.933333333333 #没有规范化之前我们的训练分数为0.511111111111,规范化后为0.933333333333,准确度有很大提升
3.交叉验证
交叉验证的基本思想是将原始数据进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。还可以从有限的数据中获取尽可能多的有效信息。
机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集、验证集和测试集。 训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。不同的划分会得到不同的最终模型。
以前我们是直接将数据分割成70%的训练数据和测试数据,现在我们利用K折交叉验证分割数据,首先将数据分为5组,然后再从5组数据之中选择不同数据进行训练。
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier ###引入数据### iris=load_iris() X=iris.data y=iris.target ###训练数据### X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3) #引入交叉验证,数据分为5组进行训练 from sklearn.model_selection import cross_val_score knn=KNeighborsClassifier(n_neighbors=5)#选择邻近的5个点 scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')#评分方式为accuracy print(scores)#每组的评分结果 #[ 0.96666667 1. 0.93333333 0.96666667 1. ]5组数据 print(scores.mean())#平均评分结果 #0.973333333333
cross_val_score参数设置
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)
参数:
estimator: 需要使用交叉验证的算法
X: 输入样本数据
y: 样本标签
groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
scoring:
交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。具体可用哪些评价指标,官方已给出详细解释,链接:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
具体如下:
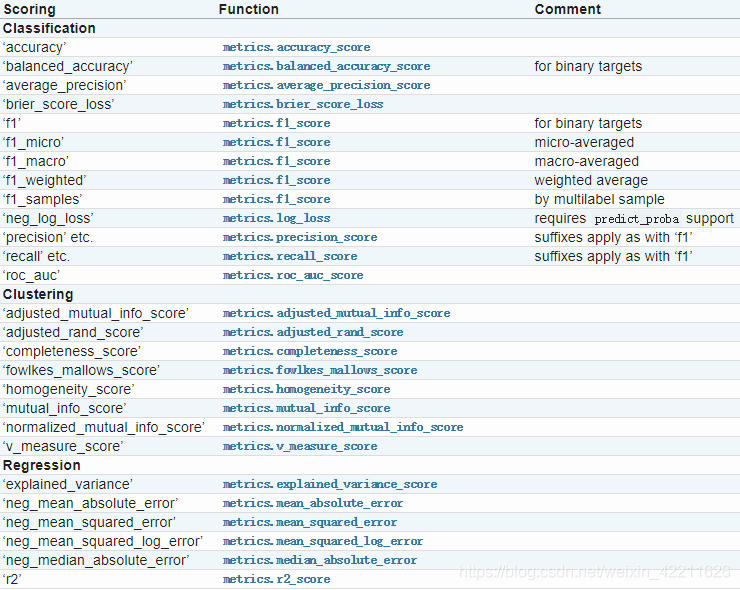
cv: 交叉验证折数或可迭代的次数
n_jobs: 同时工作的cpu个数(-1代表全部)
verbose: 详细程度
fit_params: 传递给估计器(验证算法)的拟合方法的参数
pre_dispatch: 控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是:
- 没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
- 一个int,给出所产生的总工作的确切数量
- 一个字符串,给出一个表达式作为n_jobs的函数,如’2 * n_jobs
error_score: 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
4.Sklearn Model的属性和功能
数据训练完成之后得到模型,我们可以根据不同模型得到相应的属性和功能,并将其输出得到直观结果。
###训练数据### model = linear_model.LinearRegression() model.fit(x_train, y) result = model.predict(x_test) ###属性和功能### print(model.coef_) # Coefficient of the features 决策函数中的特征系数 print(model.intercept_) # 又名bias偏置,若设置为False,则为0 print(result)
print(model.intercept_) #截距项。布尔型,默认为True,若参数值为True时,代表训练模型需要加一个截距项;若参数为False时,代表模型无需加截距项。
print(model.get_params())#得到模型的参数
print(model.score(x_train, y))#对训练情况进行打分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号