结对编程-stage_2
| 教学班 | 罗杰、任建班周五3、4节 |
|---|---|
| gitlab项目地址 | Here it is. |
| 成员 | 周远航(3004) 李辰洋(3477) |
结对编程体验
经过了上一阶段的磨合,第二阶段我们的配合更加流畅,也熟悉了对方的编程习惯,因此编程的效率有所提高。
和stage_1不同的感受是,stage_2我们讨论的时间明显减少,项目的基本框架已经成型,因此无需像第一阶段一样对大型设计架构进行讨论,只需要关注一些细节功能的实现方式即可。另外,本阶段代码规模明显增大,为了保证代码的可读性和优雅程度,我们花了更多时间在代码美观上,包括对一些冗长的方法进行了重写,提取更多工具性方法和工具类等。
在开始动笔前,我们还是首先进行了面对面讨论,更深入地挖掘了linux文件系统的原理,并对各个新增功能的实现方式进行敲定,并在第一阶段的讨论结束后开始动手。

由于和队友的课程时间不一致,能面对面编程的时间宝贵且有限,考虑到本次作业usersystem和filesystem的独立性较大,我们进行了一定的分工,并在仓库的alpha分支进行协作,将稳定版本merge到master分支触发评测,以节约评测资源。
截至目前,我们二人已在两分支进行了共186次commit。
然后,现实是残酷的,在动手一天后,主笔usersystem部分书写的L同学已经顺利完成了所有功能的实现和test的书写。然而主笔filesystem部分的Z同学陷入了啃不动指导书的绝境。于是乎在一个月黑风高的晚上,我们又一次进行了面对面现场合作。
在后期测试阶段,我们通过书写单元测试发现了一系列问题,延续了第一阶段的测试导向编程方法,即将test编写好后传递给对方,对方修改代码后通过测试。
设计思路
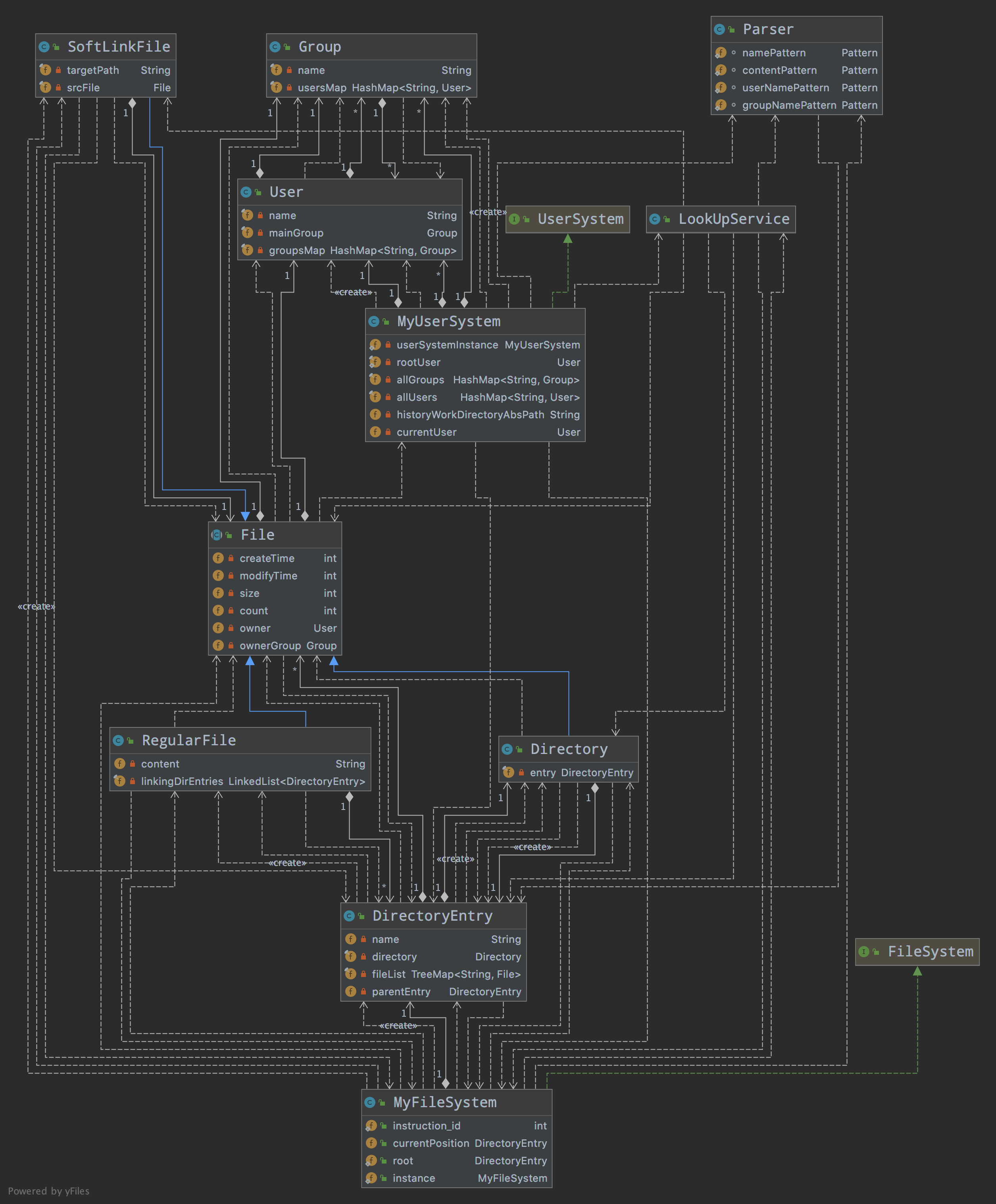
在第一阶段文件系统的基础上,本次迭代要求实现HardLink、SoftLink以及mv、cp、readline等指令,以及新增了用户系统及一系列功能,本阶段程序设计框架如下UML图所示:
-
MyFileSystem
文件系统核心类,继承官方接口FileSystem。用于记录root和currentPosition两个目录入口,并且维护指令流计数器。
-
DirectoryEntry
目录入口类。用于管理目录下的所有文件(包括目录文件、普通文件)以及文件树的上下级关系。
-
File
抽象类,所有文件类型对象的父类,定义了文件类型对象的公共属性和方法。
-
RegularFile
普通文件,继承File抽象类。
-
Directory
目录文件,继承File抽象类。
-
SoftLinkFile
软链接文件,继承File抽象类。保存了指向文件或目录的绝对路径。
-
MyUserSystem
用户系统核心类,继承官方接口UserSystem。用于管理系统所有用户和用户组信息,记录当前系统活跃用户信息。
-
User
用户类。保存用户名、用户主组及其所属用户组等信息。
-
Group
用户组类。保存用户组名及其包含的用户信息。
-
Parser
路径分析及格式检查工具类。
-
LookUpService
文件查询工具类。
实现过程
在本次任务中,我们继续使用TDD(测试驱动开发)的开发流程,尽量做到在编写代码之前做好测试单元的设计和编写,然而由于本次功能涉及的条件和特殊情况判断多且复杂,也让测试单元的编写举步维艰。
在代码编写过程中,出现了不少需要纠结具体细节实现的地方,出于对性能的考量,本次任务中使用JProfiler对极限数据进行了测试。
代码复审和测试阶段,我们发现,在对深度极大的文件树进行操作时,可能出现性能上的瓶颈,于是构造了大量超深目录创建和文件写入的测试数据,发现出现了爆栈、爆堆区空间等情况。对于爆栈的情况,我们将部分递归进行的函数去递归化,采用循环的方式进行处理。而对于爆堆区空间的问题,有些一筹莫展,于是我们使用JProfiler监测运行程序的内存占用状况,发现仅仅一次深度递归的mkdir,就产生了大量的内存占用:
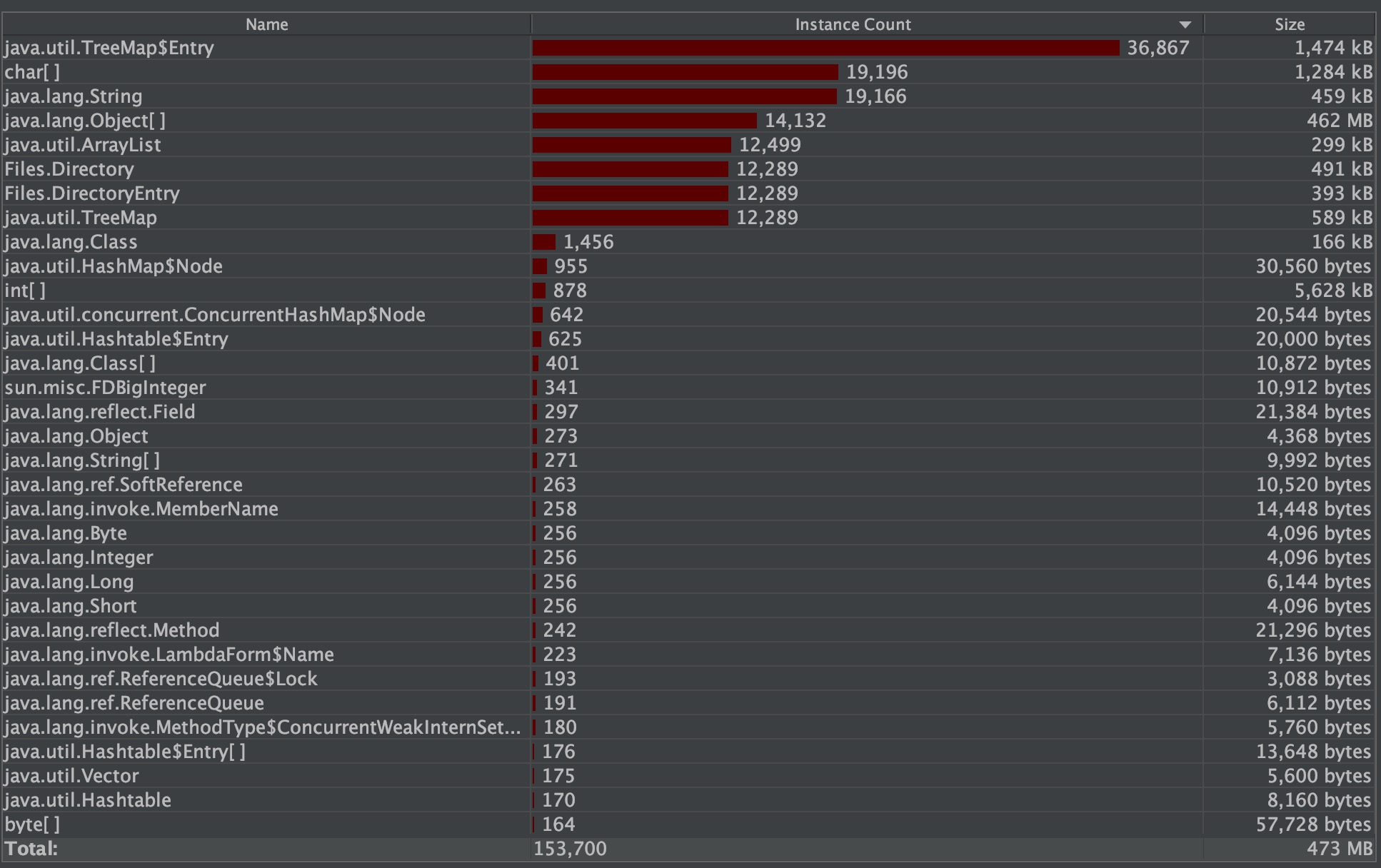
右图中可以发现,Object[]的size达到了462MB,这让我们想到,为了让绝对路径不进行重复计算,我们对每个目录都使用ArrayList对路径中节点进行保存,但缓存机制除了占据巨大的内存,还有另一个缺点,速度:
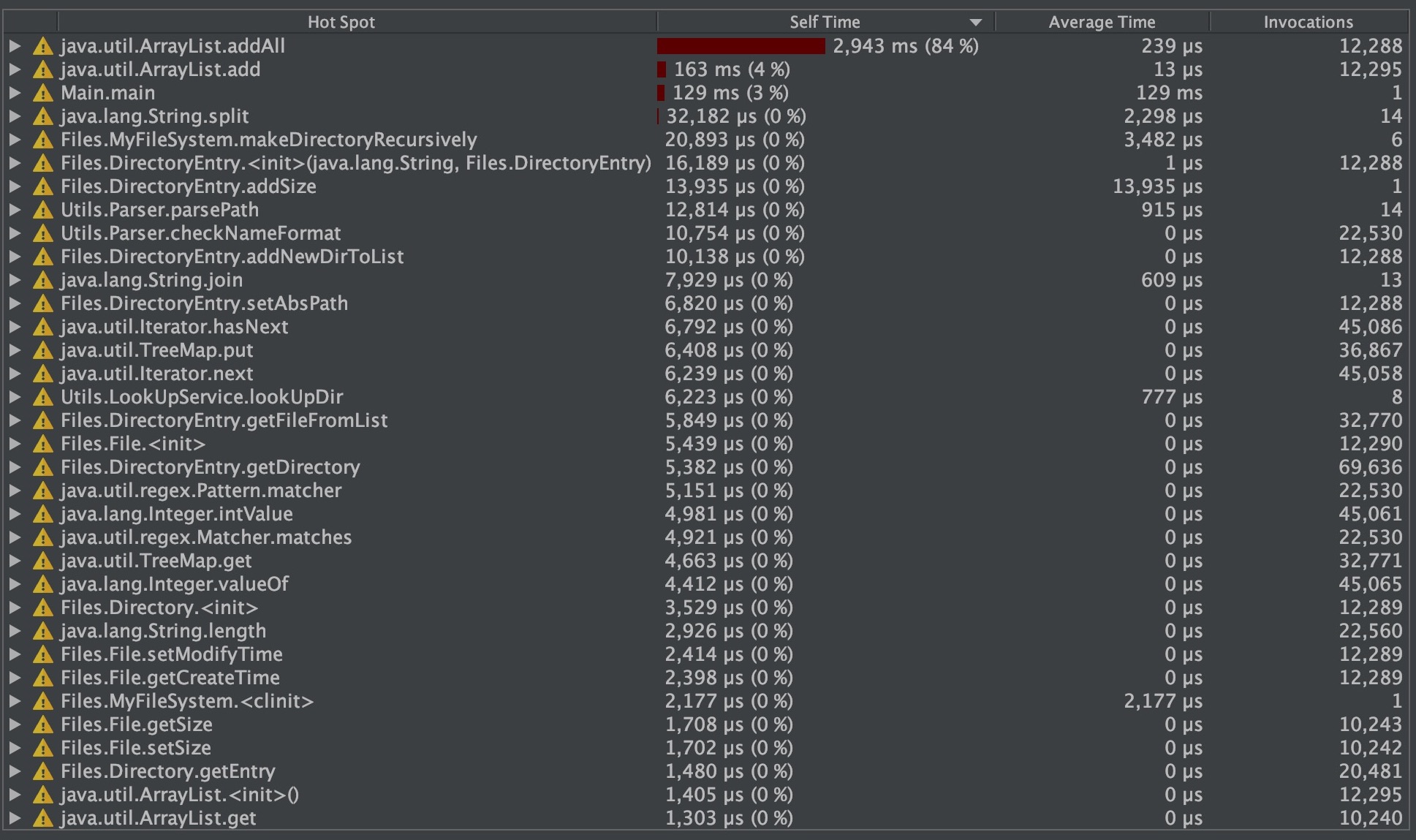
可以看到,对当前目录ArrayList的计算中,需要使用addAll方法将父节点的路径列表加入当前节点,这不仅占用了大量内存,也在计算的速度中,并不讨好,因此,我们计划使用StringBuilder保存,虽然在速度上有所进步,但内存空间上的消耗大了将近1/3:
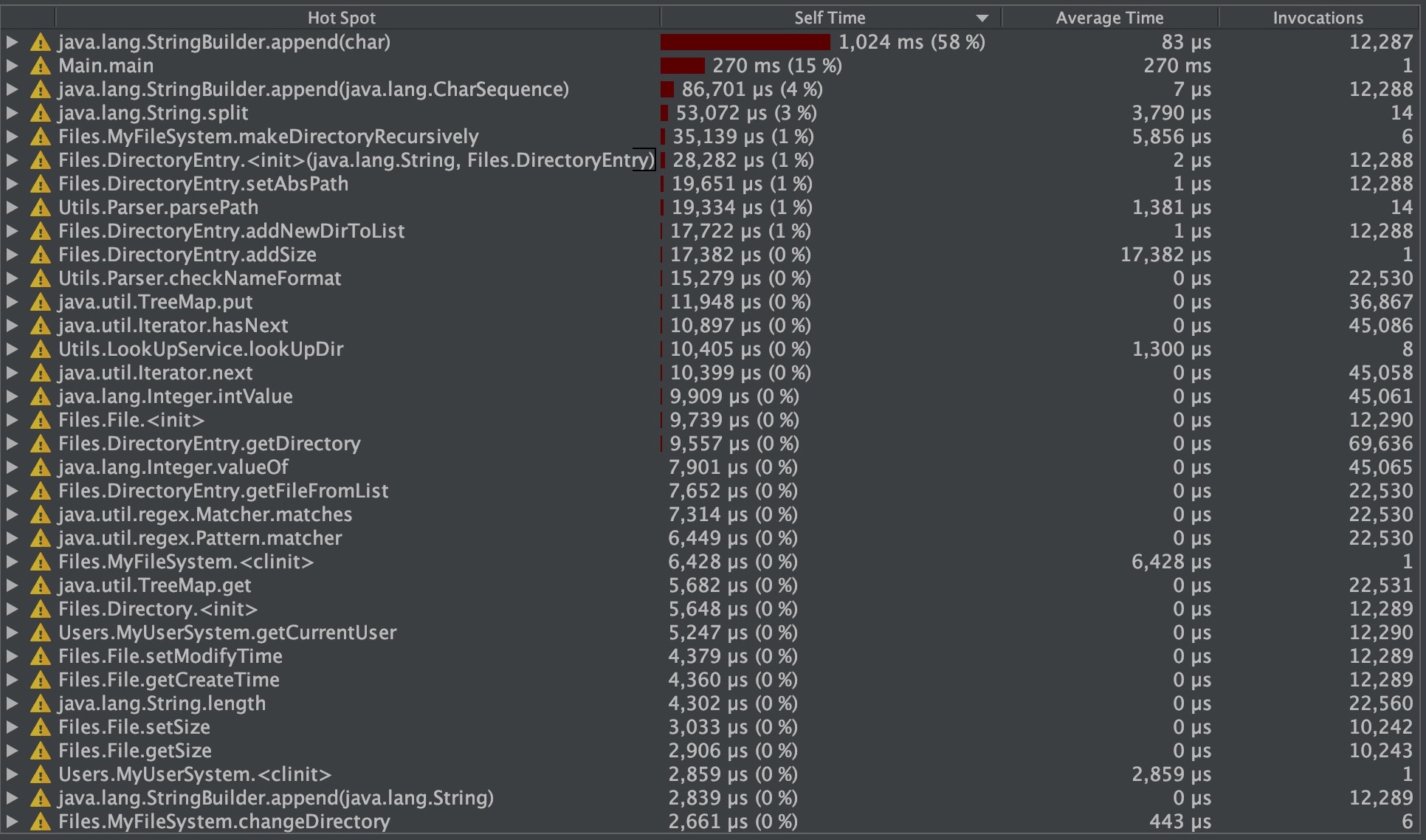
最后,我们分析,这种缓存虽然在计算上不需要过多时间,但如果存在大量的新增、移动、复制等命令,将大大降低运行效率,并且内存的使用量永远是一个隐患,因此,我们最终放弃缓存机制,对绝对路径的计算,仅采用即时计算的方式:
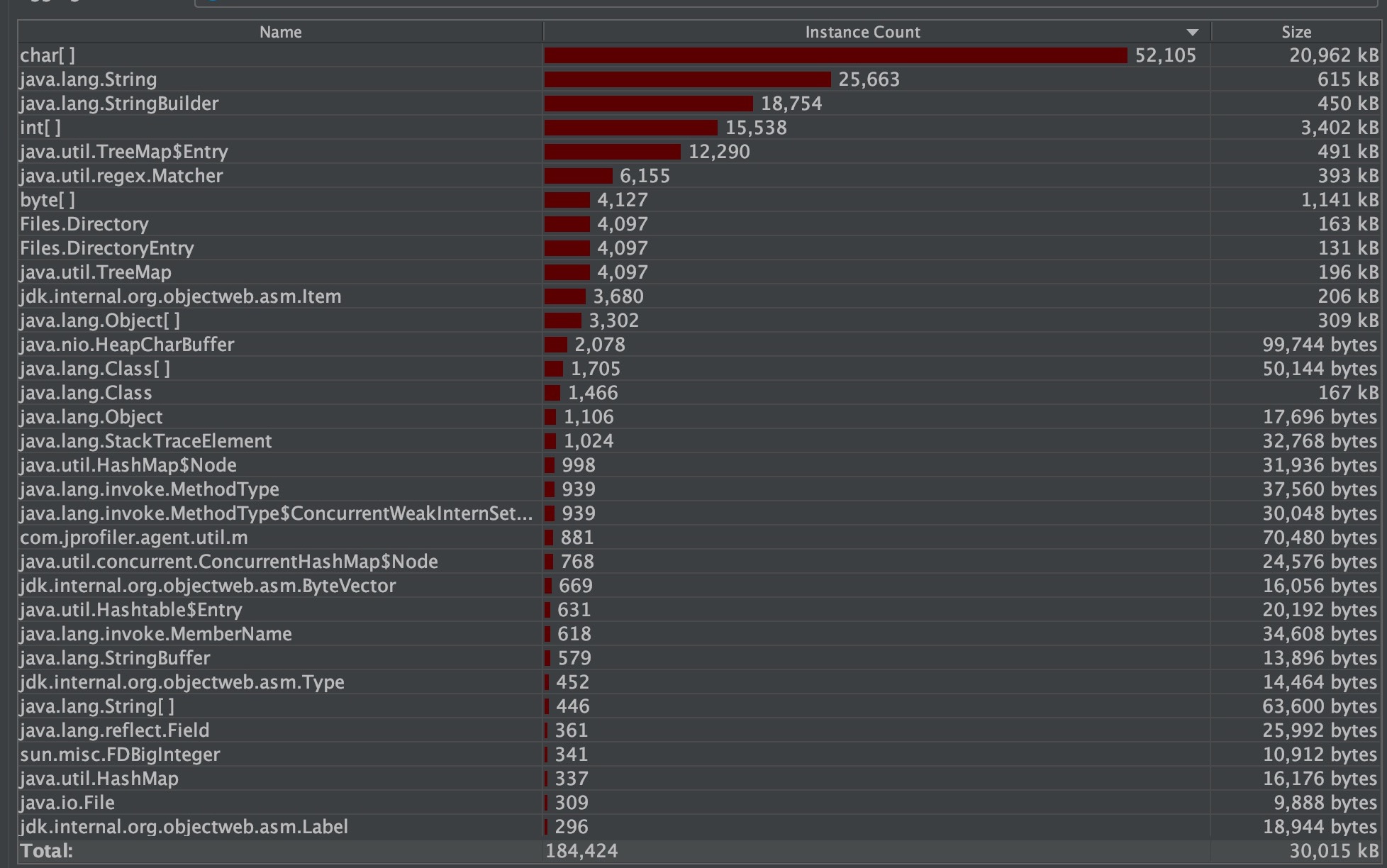
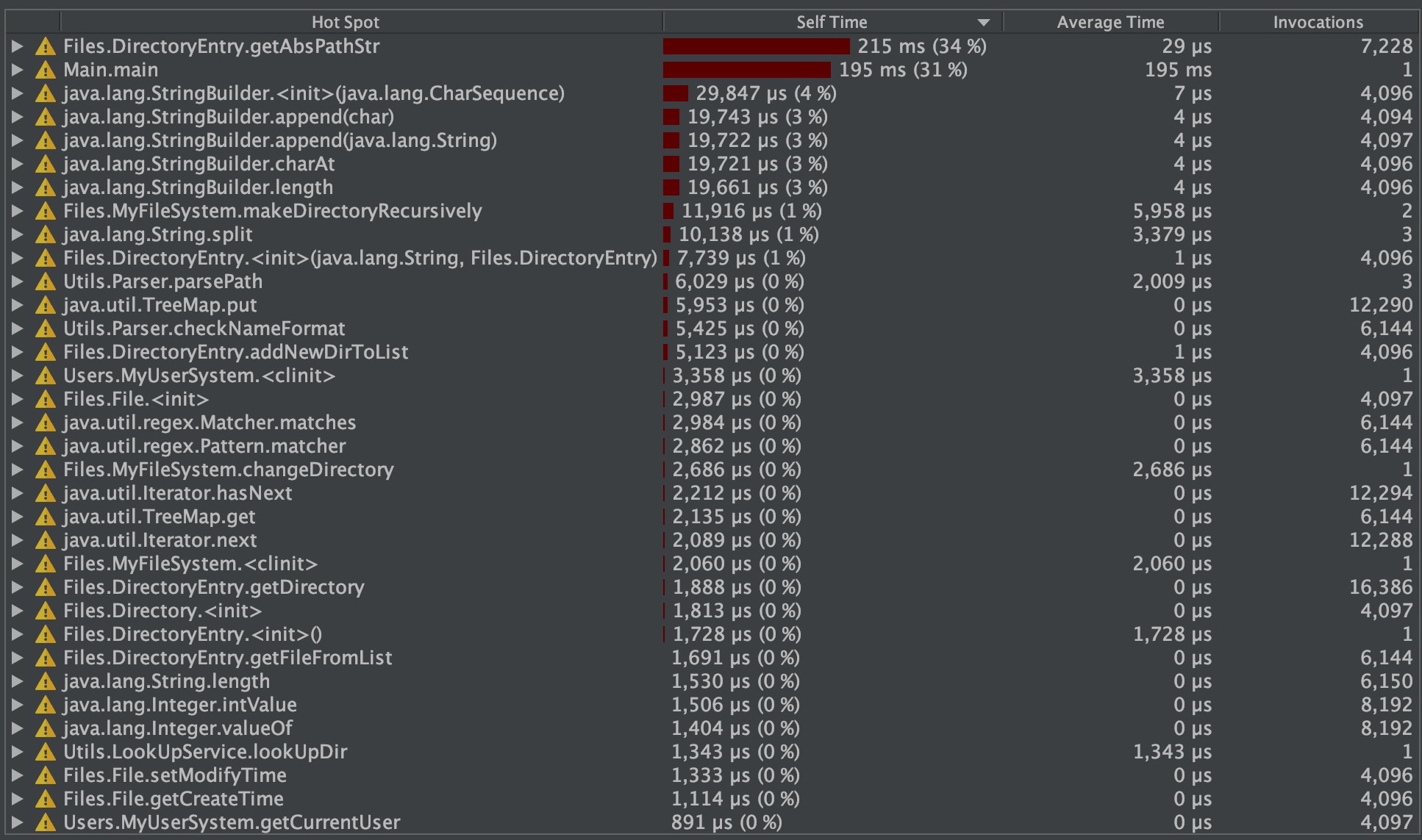
最终发现,在这种情况下,内存的使用量和速度都达到较好的水平,但在大量的getAbsPath方法调用中,可能依旧存在速度问题。鱼和熊掌不可兼得。
时间规划
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟 |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 555 | 815 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 15 | 15 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 120 | 150 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 270 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 636 | 895 |
整体来看,设计和主要代码的编写过程依然比较顺利,但代码复审、研读指导书细节、修改细节实现、测试复杂情况花费了比预计多了不止一倍的时间。而且,这些时间并不是集中的,而是遍布了作业进行期间的每一天。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号