
dl笔记
激活函数
https://blog.csdn.net/tyhj_sf/article/details/79932893
Xavier初始化方法 https://blog.csdn.net/shuzfan/article/details/51338178
应用中如何选择合适的激活函数?
1)深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
3)最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
输入层、卷积层、激活函数、池化层、全连接层
https://blog.csdn.net/qq_40957196/article/details/86039082
召回率、精确率
召回率 (Recall):该类样本有多少被找出来了(召回了多少)。
精确率 (Precision):你认为的该类样本,有多少猜对了(猜的精确性如何)。
准确率(accuracy):预测对的/所有
TP: 将正类预测为正类数
FN: 将正类预测为负类数
FP: 将负类预测为正类数
TN: 将负类预测为负类数
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN)

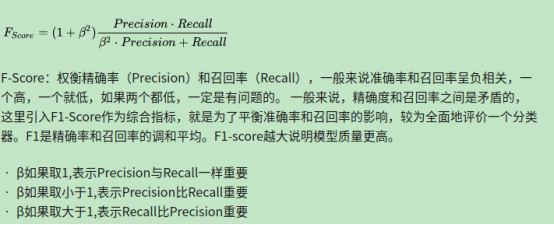
F-Score
Batch Normalization

https://www.zhihu.com/question/38102762
https://www.jianshu.com/p/b4d186cca6be
深度学习归一化:BN、GN与FRN https://www.cnblogs.com/dengshunge/p/12513712.html
BN层是现在大部分网络的标配,但其若batch size较小时,性能会表现较差;GN层就是为了解决batch size较小时,依然能使网络具有较好的性能,但是在大batch size时,性能依然比不上BN层;FRN层同时解决了mini-batch size的问题,同时又保证性能比BN层好。
阈值逻辑单元(Threshold Logic Unit, TLU) https://hyper.ai/wiki/3660
dropout层
https://blog.csdn.net/qq_33908388/article/details/96318452
动量梯度下降法(Momentum)
深度学习的优化算法主要有GD,SGD,Momentum,RMSProp和Adam算法,还有诸如Adagrad算法. https://www.cnblogs.com/callyblog/p/8299074.html
Momentum :https://www.jianshu.com/p/192c8bb5f1a1
DP模式 DDP模式
分布式训练DP、DDP原理 https://zhuanlan.zhihu.com/p/366253646
pytorch分布式训练
https://blog.csdn.net/m0_37400316/category_10179847.html
通俗理解torch.distributed.barrier()工作原理
https://blog.csdn.net/weixin_41041772/article/details/109820870
超参数优化
https://baijiahao.baidu.com/s?id=1665683313439416501&wfr=spider&for=pc
yolov5选择合适自己的超参数
https://blog.csdn.net/ayiya_Oese/article/details/115369068
EMA
指数移动平均(EMA)的原理及PyTorch实现
https://www.jianshu.com/p/f99f982ad370
学习率
warmup 预热学习率:https://www.cnblogs.com/shona/p/12252940.html
损失函数LOSS
目标检测回归损失函数——IOU、GIOU、DIOU、CIOU
https://blog.csdn.net/neil3611244/article/details/113355025
三大视觉任务的loss
https://blog.csdn.net/qq_35054151/article/details/116453530
Focal Loss 论文理解及公式推导
https://cloud.tencent.com/developer/article/1396320
https://www.cnblogs.com/yymn/articles/13668578.html
https://zhuanlan.zhihu.com/p/122542747
非极大值抑制(nms)算法
https://blog.csdn.net/lz867422770/article/details/100019587
图像增强
先验框
睿智的目标检测10——先验框详解及其代码实现
https://blog.csdn.net/weixin_44791964/article/details/103169623
k-means
----
感受野
关于感受野的总结 https://developer.aliyun.com/article/617954
感受野 https://blog.csdn.net/baidu_27643275/article/details/88711329

 浙公网安备 33010602011771号
浙公网安备 33010602011771号