
模型压缩、量化总结
量化概述
量化方法的目的就是使用 8 位或 16 位的整型数来替代浮点数,这种方法试图利用定点点积来替代浮点点积,这很大程度上降低了神经网络在无硬浮点设备上的运算开销。
深度神经网络的量化技术主要可以分为两类:完成训练后量化和训练时量化。与训练后量化类的技术相比,训练时进行量化类的技术可量化权重、激活值和梯度,以获得体积相对更小且计算更简洁的网络,但也需要完整的数据样本以训练和量化深度神经网络。权重、激活值和梯度对量化的敏感度依次递增,其中梯度可以量化至4bits而不明显影响网络的精度,全网络的所有参数都被量化为8bits时网络几乎不会有明显的精度损失。

参考:
小改进大用途——量化方法在神经网络中的应https://zhuanlan.zhihu.com/p/38328685
神经网络量化简介https://jackwish.net/neural-network-quantization-introduction-chn.html
神经网络模型量化论文小结https://blog.csdn.net/u012101561/article/details/80868352
ICLR 2019论文解读:量化神经网络https://cloud.tencent.com/developer/article/1449043
模型压缩概述
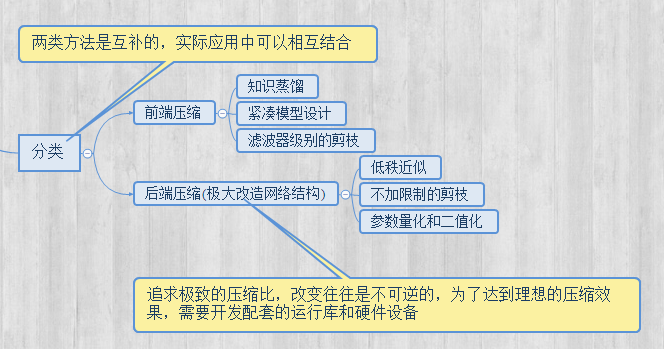
对于模型压缩这一块的方法大致可以分为:低秩近似(low-rank Approximation),网络剪枝(network pruning),网络量化(network quantization),知识蒸馏(knowledge distillation)和紧凑网络设计(compact Network design)。
前三种方法都是致力于将权重矩阵变得更稀疏,以此来减小计算和存储的开销。后两种方法往往是需要对网络结构有较大的改动,也需要对神经网络的更深层原理有一定的认识才能进行更好的压缩。
(1)Low-Rank低秩分解:通过SVD奇异值分解等矩阵分析方法可以有效减少矩阵运算的计算量
(2)网络剪枝(network pruning):将权重矩阵中相对“不重要”的权值剔除,然后再重新fine tune 网络进行微调。
使用pytorch进行网络修剪https://www.lizenghai.com/archives/27828.html
(3)网络量化(Network Quantization):最为典型就是二值网络、XNOR网络等。其主要原理就是采用1bit对网络的输入、权重、响应进行编码。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。
(4)知识蒸馏(knowledge distillation):采用的是迁移学习,通过采用预先训练好的复杂模型(Teacher model)的输出作为监督信号去训练另外一个简单的网络。
(5)紧致网络设计:直接设计又小又快又好的网络
参考:
深度神经网络加速和压缩新进展年度报http://www.sohu.com/a/232047203_473283
模型压缩总览https://www.jianshu.com/p/e73851f32c9f
Pytorch模型压缩
1.Distiller
Distiller 官方文档:https://nervanasystems.github.io/distiller/index.html
用 Distiller 压缩 PyTorch 模型:https://www.pytorchtutorial.com/distiller-compress-pytorch-model/
-
量化(Experimental)
官方文档:https://pytorch.org/docs/master/quantization.html#
训练后动态量化(post-training dynamic quantization)、训练后静态量化(static post training quantization)、训练中量化(quantization aware training)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号