基于spark分析海量用户日志预测用户流失
Table of Contents
背景知识
何为LCV?
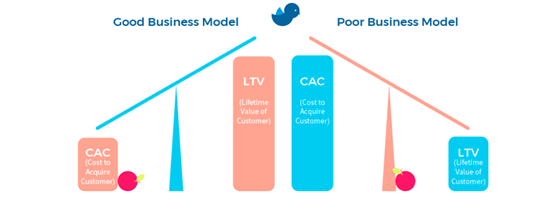
在市场营销中,客户生命周期价值(CLV 或通常是 CLTV)、终身客户价值(LCV)或终身价值(LTV)是对整个未来与客户关系的净利润的预测。客户终身价值是一个重要的概念,因为它鼓励企业将重点从季度利润转移到客户关系的长期健康,利用顾客生命周期价值衡量过去,展望未来。
(Avg Monthly Revenue per Customer * Gross Margin per Customer) ÷ Monthly Churn Rate
(注:这是一个概念模型,实际不同行业运用会有差异)
Clv 将现值的概念应用于属于客户关系的现金流。 因为任何未来现金流的现值都是用来衡量未来现金流今天的一次总付价值的,所以 CLV 将代表客户关系今天的一次总付价值。 更简单地说,CLV 是客户关系对公司的货币价值。 通过衡量CLV可以进行客户细分,促使公司精细运营挖掘客户最大价值,提升企业盈利能力。这也是公司愿意为获得客户关系而支付的价格上限,从而控制市场部门应该花多少钱来获得每个顾客,特别是在直接响应营销中。
Clv运用需要注意以下问题:
客户关系价值通常不能简单通过现有指标数据获取,过度依赖单一模型,可能导致客户细分不准确。
客户关系现金流取决于多维度价值评分,要考虑到客户给产品、企业带来的附加价值。
以牺牲潜在客户为代价,高估现有客户。
Clv 是一个动态概念,而不是一个静态模型。
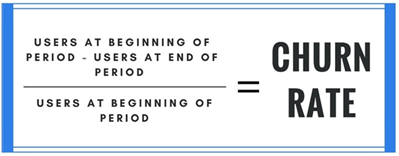
何为用户流失率
在客户生命周期价值理论中,客户流失率是决定客户关系价值的关键因素。从较高的层次上讲,流失率是在设定的时间段内离开的客户数量的度量。 它用于衡量您因取消客户而损失了多少收入。 它还可用于衡量停止使用您的产品或服务的用户或帐户的数量。 无论哪种情况,流失率都是客户群的流失率。
此为通用模型,具体模型会有不同
为什么流失率很重要?

获得新客户的费用比保留一个新客户的费用高5-25倍
将客户流失率降低仅5%即可将获利能力提高75%
与收购相比,提高保留率对增长的影响要高2-4倍
出售给现有客户的可能性为60-70%,但潜在客户只有5-20%
常用的流失率统计
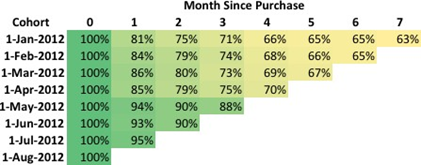
客户流失的影响因素有多方面,有一点需要整体把握的是,流失取决于客户生命周期中的不同阶段。 通常,发现客户在订阅开始时的流失率要比几个月前高。这可能是由于多种原因而发生的,例如销售过程中的期望设定不佳,优先级突然改变,入门计划不佳, 随着客户的成熟,他们的客户流失率将会稳定。 因此,计算新客户和老客户之间的客户流失率很重要,不能高估稳定的客户流失率,也不要低估早期客户流失率。
如何分析用户流失?

流失跟用户的生命周期有关。用户在产品中的生命周期可以分为,体验期、新手期、探索期、成熟期和疲惫期。用户在不同的生命周期阶段,流失的原因不同。可以从以下方面探究客户流失的原因:
用户主动型流失分析:用户主动选择不再接受服务。这么做的原因可能有很多,从客户公司业务方向的改变,到喜欢上其他公司的同类产品,或者到客户一直用不明白或不满意产品等等这些都有可能。
用户满意型流失分析:客户对产品的服务体验很满意但还是不再续费。一般来讲这些用户之所以使用某个产品,都是因为他们有些专门需求,可以保持关注,有需要会再考虑。
用户被动型流失分析:客户未及时更新他们的信用卡信息导致续费失败。只要用点心给他们做一个付费提醒就可以了,可以按客户的选择来给他们发邮件或短信提醒,或者请客户直接提供更便捷保险的付款方式即可。
用户垂直型流失分析:“流失的客户分别属于哪种类型?”“我们在哪些类型上的客户流失情况很好哪些不好?”显然,对用户流失做垂直型分析主要适合于B2B业务,尤其当公司的服务本身就是针对某些具体领域的。
用户集群型流失分析:“客户流失最多的月份是哪个?”“上季度的价格调整对客户流失有何影响?”主要关注大的市场环境、政策、活动等影响。
如何应对用户流失?
企业都会存在客户流失,这是一个常规指标,通过研究客户流失率,企业可以采取积极行动,进一步改善产品和服务,调整市场策略,或者针对具体客户的分析进行激励或挽留,以降低客户流失率。
建立预警模型的目的是提前识别潜在流失用户,为挽留用户赢得时间。
常见的流失预警模型有如下五种。
• 基于用户属性的流失预警模型
• 基于关键事件的流失预警模型
• 基于负体验的流失预警模型
• 基于业务粘性的流失预警模型
• 基于用户活跃度的流失预警模型
建立防止用户流失的运营策略
- 防堵流失漏洞。
• 性能优化。比如:优化卡顿、加载速度、降低耗电等。
• 功能优化。比如:补充竞品的优势功能,做到人有我也有。
• 体验优化。比如:缩短流程、优化交互、视觉体验等。 - 建立流失壁垒。
• 沉淀资产。比如:我的阅读偏好、收藏文章、下载文件、好友关系、聊天记录等。
• 增加转移难度。比如:特定的专属功能,播放视频独特格式。
• 福利刺激。增加福利体系,类似奖金机制。
开展流失用户召回活动
- 流失用户召回是一系列手段,不要指望一个手段召回所有流失。
- 根据流失原因的不同,对症下药,做针对性召回。
- 有效的触达方式。比如:通知栏push、短信、好友关系链召回等等。
spark分析案例简介
基于客户生命周期价值理论,为了实现用户价值最大化,降低用户流失率一直是众多企业关心的问题。本项目基于sparkify音乐APP的海量真实用户日志文件进行分析。旨在通过多维度特征的用户画像分析,构造模型,对流失用户进行预测。由于文件量级较大,scikit-learn 等很难高效处理。基于分布式技术的Spark可以很好解决该问题,并通过pyspark.ml库实现用户流失预测模型。
数据来源:
数据来源于Sparkify音乐APP的用户日志文件,格式为JOSON,迷你集128M,亚马逊AWS集群数据高达12G。日志包含18个字段,描述用户各个时间戳的相关操作日志。
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: long (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
需要安装的包:
pyspark,主要应用pyspark.ml,pyspark.sql.建议数据集较大在Amazon AWS云平台进行模型训练。
定义问题:
通过日志文件提取用户的各项特征,并用具体指标实现,基于这些指标构造模型,预测用户是否会流失。这是一个二分类的预测问题。
spark分析案例详细解
导入需要的库
# import libraries
from pyspark.sql import SparkSession, Window
from pyspark.ml.feature import RegexTokenizer, VectorAssembler, Normalizer, StandardScaler
from pyspark.sql.functions import avg, col, concat, desc, explode, lit, min, max, count, split, udf, isnull, weekofyear
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression,DecisionTreeClassifier,\
LogisticRegressionModel, RandomForestClassifier,RandomForestClassificationModel
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.mllib.evaluation import MulticlassMetrics
from pyspark.ml.feature import CountVectorizer, IDF, Normalizer, \
PCA, RegexTokenizer, Tokenizer, StandardScaler, StopWordsRemover, \
StringIndexer, VectorAssembler, MaxAbsScaler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.clustering import KMeans
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
from pyspark.sql.types import IntegerType, FloatType
from pyspark.sql.functions import desc
from pyspark.sql.functions import asc
from pyspark.sql.functions import sum as Fsum
from time import time
import re
import numpy as np
import scipy
import pandas as pd
import datetime
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
import seaborn as sns
import random
%matplotlib inline
spark = SparkSession.builder \
.master("local") \
.appName("Music App") \
.getOrCreate()
stack_overflow_data = 'mini_sparkify_event_data.json'
df = spark.read.json(stack_overflow_data)
数据洞察和清洗
数据概览
df.head()
Row(artist='Martha Tilston', auth='Logged In', firstName='Colin', gender='M', itemInSession=50, lastName='Freeman', length=277.89016, level='paid', location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Rockpools', status=200, ts=1538352117000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30')
df.count()
286500
df.select("userId").dropDuplicates().count()
226
df.printSchema() #充分理解数据各个字段的含义,数据类型,大致分布,才可以进一步探索数据
root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: long (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
过滤掉未注册用户
df = df.filter(col('userId') != '')
转换时间字段
#转换时间格式
get_time = udf(lambda x: datetime.datetime.fromtimestamp(x / 1000.0).strftime(
"%Y-%m-%d %H:%M:%S"))
df = df.withColumn("time", get_time(df.ts))
#便于查看小时、周几、几号的流失、非流失听歌频率的分布
get_hour = udf(lambda x: datetime.datetime.fromtimestamp(x / 1000.0).hour)
df = df.withColumn("hour", get_hour(df.ts))
get_weekday = udf(
lambda x: datetime.datetime.fromtimestamp(x / 1000.0).strftime("%w"))
df = df.withColumn("weekday", get_weekday(df.ts))
get_day = udf(lambda x: datetime.datetime.fromtimestamp(x / 1000.0).day)
df = df.withColumn("day", get_day(df.ts))
df.take(5)
[Row(artist='Martha Tilston', auth='Logged In', firstName='Colin', gender='M', itemInSession=50, lastName='Freeman', length=277.89016, level='paid', location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Rockpools', status=200, ts=1538352117000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:01:57', hour='0', weekday='1', day='1'),
Row(artist='Five Iron Frenzy', auth='Logged In', firstName='Micah', gender='M', itemInSession=79, lastName='Long', length=236.09424, level='free', location='Boston-Cambridge-Newton, MA-NH', method='PUT', page='NextSong', registration=1538331630000, sessionId=8, song='Canada', status=200, ts=1538352180000, userAgent='"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.103 Safari/537.36"', userId='9', time='2018-10-01 00:03:00', hour='0', weekday='1', day='1'),
Row(artist='Adam Lambert', auth='Logged In', firstName='Colin', gender='M', itemInSession=51, lastName='Freeman', length=282.8273, level='paid', location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Time For Miracles', status=200, ts=1538352394000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:06:34', hour='0', weekday='1', day='1'),
Row(artist='Enigma', auth='Logged In', firstName='Micah', gender='M', itemInSession=80, lastName='Long', length=262.71302, level='free', location='Boston-Cambridge-Newton, MA-NH', method='PUT', page='NextSong', registration=1538331630000, sessionId=8, song='Knocking On Forbidden Doors', status=200, ts=1538352416000, userAgent='"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.103 Safari/537.36"', userId='9', time='2018-10-01 00:06:56', hour='0', weekday='1', day='1'),
Row(artist='Daft Punk', auth='Logged In', firstName='Colin', gender='M', itemInSession=52, lastName='Freeman', length=223.60771, level='paid', location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Harder Better Faster Stronger', status=200, ts=1538352676000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:11:16', hour='0', weekday='1', day='1')]
转换性别、级别为数值
tran_gender = udf(lambda x: 1 if x == "M" else 0, IntegerType())
df = df.withColumn("gender", tran_gender("gender"))
tran_level = udf(lambda x: 1 if x == "paid" else 0, IntegerType())
df = df.withColumn("level", tran_level("level"))
数据探索
定义流失客户
churn_users = df.filter(
df.page == "Cancellation Confirmation").select("userId").dropDuplicates()
churn_users_list = [(row['userId']) for row in churn_users.collect()]
# 创建Churn列,用来标记后期证实流失的客户
flag_CancellationConfirmation_event = udf(
lambda x: 1 if x in churn_users_list else 0, IntegerType())
df = df.withColumn("Churn", flag_CancellationConfirmation_event("userId"))
df.take(5)
[Row(artist='Martha Tilston', auth='Logged In', firstName='Colin', gender=1, itemInSession=50, lastName='Freeman', length=277.89016, level=1, location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Rockpools', status=200, ts=1538352117000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:01:57', hour='0', weekday='1', day='1', Churn=0),
Row(artist='Five Iron Frenzy', auth='Logged In', firstName='Micah', gender=1, itemInSession=79, lastName='Long', length=236.09424, level=0, location='Boston-Cambridge-Newton, MA-NH', method='PUT', page='NextSong', registration=1538331630000, sessionId=8, song='Canada', status=200, ts=1538352180000, userAgent='"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.103 Safari/537.36"', userId='9', time='2018-10-01 00:03:00', hour='0', weekday='1', day='1', Churn=0),
Row(artist='Adam Lambert', auth='Logged In', firstName='Colin', gender=1, itemInSession=51, lastName='Freeman', length=282.8273, level=1, location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Time For Miracles', status=200, ts=1538352394000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:06:34', hour='0', weekday='1', day='1', Churn=0),
Row(artist='Enigma', auth='Logged In', firstName='Micah', gender=1, itemInSession=80, lastName='Long', length=262.71302, level=0, location='Boston-Cambridge-Newton, MA-NH', method='PUT', page='NextSong', registration=1538331630000, sessionId=8, song='Knocking On Forbidden Doors', status=200, ts=1538352416000, userAgent='"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.103 Safari/537.36"', userId='9', time='2018-10-01 00:06:56', hour='0', weekday='1', day='1', Churn=0),
Row(artist='Daft Punk', auth='Logged In', firstName='Colin', gender=1, itemInSession=52, lastName='Freeman', length=223.60771, level=1, location='Bakersfield, CA', method='PUT', page='NextSong', registration=1538173362000, sessionId=29, song='Harder Better Faster Stronger', status=200, ts=1538352676000, userAgent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0', userId='30', time='2018-10-01 00:11:16', hour='0', weekday='1', day='1', Churn=0)]
df.groupby("Churn").count().show()
+-----+------+
|Churn| count|
+-----+------+
| 1| 44864|
| 0|233290|
+-----+------+
查看用户关键行为:升级、降级
观察用户使用最多的页面
df.groupBy('Page').count().sort("count", ascending=False).show()
+--------------------+------+
| Page| count|
+--------------------+------+
| NextSong|228108|
| Thumbs Up| 12551|
| Home| 10082|
| Add to Playlist| 6526|
| Add Friend| 4277|
| Roll Advert| 3933|
| Logout| 3226|
| Thumbs Down| 2546|
| Downgrade| 2055|
| Settings| 1514|
| Help| 1454|
| Upgrade| 499|
| About| 495|
| Save Settings| 310|
| Error| 252|
| Submit Upgrade| 159|
| Submit Downgrade| 63|
| Cancel| 52|
|Cancellation Conf...| 52|
+--------------------+------+
用户流失在不同性别的分布
df_pd = df.dropDuplicates(["userId", "gender"
]).groupby(["Churn", "gender"
]).count().sort("Churn").toPandas()
sns.barplot(x='Churn', y='count', hue='gender', data=df_pd)
#1 male,paid 1,Churn 1
<matplotlib.axes._subplots.AxesSubplot at 0x7fd1d58f2710>
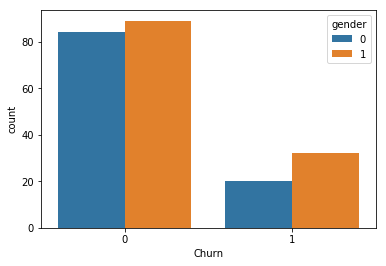
用户流失在不同会员等级的分布
df_pd = df.dropDuplicates(["userId", "level"
]).groupby(["Churn", "level"
]).count().sort("Churn").toPandas()
sns.barplot(x='Churn', y='count', hue='level', data=df_pd)
<matplotlib.axes._subplots.AxesSubplot at 0x7fd1d58add68>
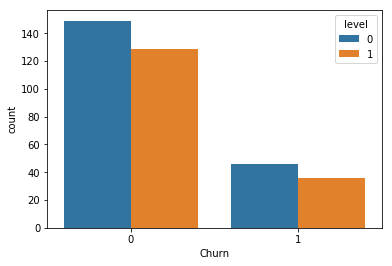
查看用户在不同端口的分布
df.groupBy(['churn', 'userAgent']).count().where(df['churn'] == 0).sort(
col('count').desc()).show(5)
df.groupBy(['churn', 'userAgent']).count().where(df['churn'] == 1).sort(
col('count').desc()).show(5)
用户流失最多的地区
df.select("userId", "Churn", "location").dropDuplicates().groupby(
["location", "Churn"]).count().sort(["Churn", "count"],
ascending=False).show(10)
+--------------------+-----+-----+
| location|Churn|count|
+--------------------+-----+-----+
|New York-Newark-J...| 1| 5|
|Los Angeles-Long ...| 1| 3|
|Philadelphia-Camd...| 1| 2|
|Phoenix-Mesa-Scot...| 1| 2|
|Spokane-Spokane V...| 1| 2|
|Miami-Fort Lauder...| 1| 2|
| Flint, MI| 1| 2|
| Jackson, MS| 1| 2|
|Greenville-Anders...| 1| 1|
|Indianapolis-Carm...| 1| 1|
+--------------------+-----+-----+
only showing top 10 rows
流失用户的每次登陆页面操作数
df.groupBy([
'userId', 'churn'
]).avg('itemInSession').groupBy('churn').avg('avg(itemInSession)').show()
+-----+-----------------------+
|churn|avg(avg(itemInSession))|
+-----+-----------------------+
| 1| 72.39591226205863|
| 0| 89.13463393625388|
+-----+-----------------------+
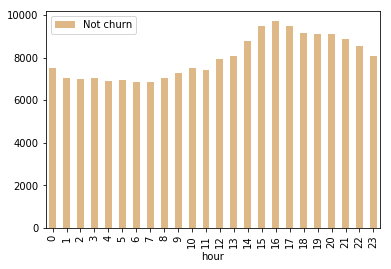
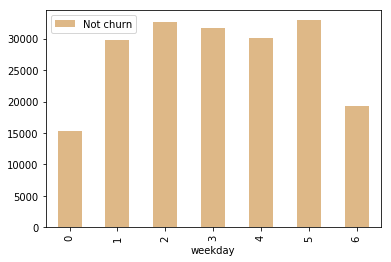
用户在线时段观察
def plot_cnt_by_churn(time):
"""
此函数用来绘制频率分布的直方图
"""
df_pd = df.filter(df.page == "NextSong").groupby(
"churn", time).count().orderBy(df[time].cast("float")).toPandas()
df_pd[time] = pd.to_numeric(df_pd[time])
df_pd[df_pd.churn == 0].plot.bar(x=time,
y='count',
color='burlywood',
label='Not churn')
df_pd[df_pd.churn == 1].plot.bar(x=time,
y='count',
color='lightseagreen',
label='Churn')
plot_cnt_by_churn("hour")
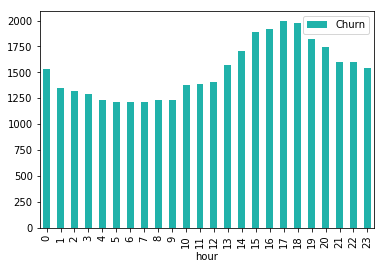
plot_cnt_by_churn("weekday")
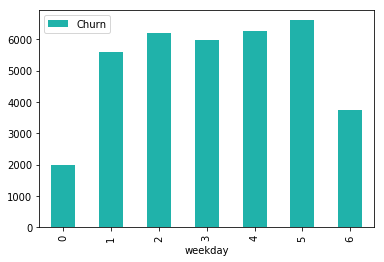
plot_cnt_by_churn("day")
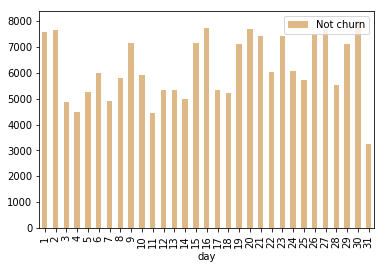
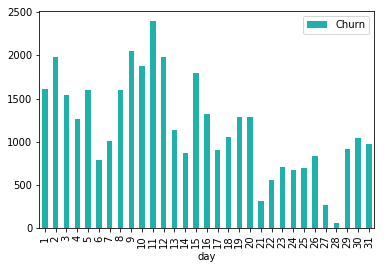
特征工程
每个用户相关关键页面操作累计和
用户累计参与度
每个SessionId的统计指标
用户听歌曲的丰富度
用户付费周期的特征分布(付费天数、免费天数)
用户平均每日登陆次数
user_session_count = df.select(
"userId", "sessionId").dropDuplicates().groupby("userId").count()
user_session_count = user_session_count.withColumnRenamed(
"count", "sessionCount")
user_session_count = user_session_count.join(
user_reg_days, user_session_count.userId == user_reg_days.userId).select(
user_session_count["userId"],
(user_reg_days["regDay"] /
user_session_count["sessionCount"]).alias("SessionOfday"))
user_session_count.show()
+------+------------------+
|userId| SessionOfday|
+------+------------------+
|100010| 7.949093915343916|
|200002|11.679104938271605|
| 125| 71.31688657407408|
| 124| 4.536410839719029|
| 51|1.9455844907407407|
| 7|10.396883267195767|
| 15|3.7675717592592592|
| 54|2.9932889139139136|
| 155| 3.926003086419753|
|100014| 14.18056712962963|
| 132| 4.180569299768519|
| 154| 7.957345679012345|
| 101| 5.39659375|
| 11| 7.779890769675926|
| 138| 4.441779320987654|
|300017|1.1802939447383893|
|100021|12.947773148148148|
| 29|1.7677662037037036|
| 69| 7.93604938271605|
| 112| 8.746262731481481|
+------+------------------+
only showing top 20 rows
目前的level
沉默时间
final_time_df = df.select(max(df.ts))
final_time_df.collect()
[Row(max(ts)=1543799476000)]
user_login.createOrReplaceTempView("user_login_view")
user_silence = spark.sql(
"SELECT userID, 1543622466000-finalTime AS user_silence FROM user_login_view "
)
user_silence.show()
+------+------------+
|userID|user_silence|
+------+------------+
| 10| 990678000|
| 100| 35117000|
|100001| 5124261000|
|100002| -177010000|
|100003| 4347685000|
|100004| 163401000|
|100005| 3650641000|
|100006| 4869396000|
|100007| 130557000|
|100008| 287247000|
|100009| 3011362000|
|100010| 798514000|
|100011| 5205381000|
|100012| 2521566000|
|100013| 2437650000|
|100014| 881817000|
|100015| 548713000|
|100016| 286819000|
|100017| 3559619000|
|100018| 244106000|
+------+------------+
only showing top 20 rows
构造训练数据集
df_final = df.select("userId", "gender",
"Churn").dropDuplicates().sort("userId")
df_final.show()
+------+------+-----+
|userId|gender|Churn|
+------+------+-----+
| 10| 1| 0|
| 100| 1| 0|
|100001| 0| 1|
|100002| 0| 0|
|100003| 0| 1|
|100004| 0| 0|
|100005| 1| 1|
|100006| 0| 1|
|100007| 0| 1|
|100008| 0| 0|
|100009| 1| 1|
|100010| 0| 0|
|100011| 1| 1|
|100012| 1| 1|
|100013| 0| 1|
|100014| 1| 1|
|100015| 0| 1|
|100016| 1| 0|
|100017| 1| 1|
|100018| 1| 0|
+------+------+-----+
only showing top 20 rows
df_final.count()
225
final_data = df_final.join(df_Help, 'userId','left').join(df_Error, 'userId','left').join(df_Upgrade, 'userId','left')\
.join(df_SubmitUpgrade, 'userId','left').join(df_Downgrade, 'userId','left').join(df_SubmitDowngrade, 'userId','left')
final_data = final_data.join(df_Add_to_Playlist, 'userId',
'left').join(df_Add_Friend, 'userId', 'left')
final_data = final_data.join(user_session_time_stat, 'userId','left').join(user_session_song_stat, 'userId','left')\
.join(user_session_Thumbs_Up_stat, 'userId','left').join(user_session_Thumbs_Down_stat, 'userId','left')\
.join(user_session_Roll_Advert_stat, 'userId','left')
final_data = final_data.join(user_song_count, 'userId',
'left').join(user_artist_count, 'userId', 'left')
final_data = final_data.join(user_reg_days, 'userId',
'left').join(user_paied_day, 'userId', 'left')
final_data = final_data.join(user_session_count, 'userId','left').join(user_recent_level, 'userId','left')\
.join(user_silence, 'userId','left')
final_data = final_data.fillna(0)
final_data.show(20)
final_data.printSchema()
+------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
|userId|gender|Churn|num_Help|num_Error|num_Upgrade|num_SubmitUpgrade|num_Downgrade|SubmitDowngrade|num_Add_to_Playlist|num_Add_Friend| avgSessionTime| minSessionTime| maxSessionTime| avgSessionSong|avgSessionThumbs_Up|avgSessionThumbs_Down|avgSessionRoll_Advert|userSongCount|userArtistCount| regDay| user_paied| SessionOfday|level|user_silence|
+------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
|100004| 0| 0| 6| 2| 8| 3| 10| 2| 23| 19|185.98650793650793| 0.0| 940.2166666666667| 47.1| 2.6923076923076925| 1.5714285714285714| 6.615384615384615| 881| 733|172.44008101851853|0.44497991967871486| 8.211432429453263| 1| 163401000|
| 104| 0| 0| 15| 1| 3| 1| 24| 0| 43| 23| 281.0339743589744| 25.783333333333335| 993.65| 68.5| 3.8181818181818183| 1.4166666666666667| 2.3| 1571| 1214|125.58270833333333| 0.8363039399624765| 4.830104166666667| 1| 273696000|
| 60| 1| 0| 7| 2| 1| 1| 21| 0| 58| 27|380.71481481481476| 7.716666666666667| 992.2333333333333| 91.33333333333333| 5.25| 1.2857142857142858| 1.0| 1477| 1137| 71.48456018518519| 0.982051282051282|3.9713644547325107| 1| 431789000|
| 68| 0| 0| 0| 0| 1| 0| 0| 0| 0| 7| 63.74166666666667| 33.53333333333333| 93.95| 14.5| 1.0| 0.0| 2.0| 29| 29| 100.0112962962963| 0.0| 50.00564814814815| 0| 621492000|
| 90| 1| 0| 2| 0| 0| 0| 0| 0| 0| 0| 29.70666666666667| 0.0| 74.38333333333334| 9.25| 0.0| 0.0| 1.5| 37| 37|101.98753472222222| 0.0|20.397506944444444| 0| 815529000|
| 126| 1| 0| 15| 2| 3| 1| 22| 0| 72| 33| 357.505| 0.0| 1533.75| 88.86206896551724| 6.136363636363637| 1.9090909090909092| 2.6923076923076925| 2229| 1643| 62.09569444444445| 0.8588007736943907|2.0698564814814815| 1| 29990000|
| 131| 1| 0| 13| 4| 1| 1| 15| 2| 51| 26|340.22456140350874| 0.0| 855.6666666666666| 92.0| 4.5| 1.6666666666666667| 1.6666666666666667| 1403| 1100|120.89991898148148| 0.9447128287707998| 6.363153630604288| 0| 74383000|
| 140| 0| 0| 34| 7| 10| 4| 50| 3| 148| 143|328.06525821596244| 0.0| 2230.266666666667| 84.53731343283582| 5.12962962962963| 2.027027027027027| 3.0| 4426| 2819| 80.60512731481481| 0.8229651162790698| 1.135283483307251| 1| 16074000|
| 17| 0| 1| 5| 0| 4| 1| 12| 0| 30| 12| 601.25| 9.933333333333334|1546.4333333333334|132.42857142857142| 8.0| 3.25| 4.0| 875| 741|13.099016203703703| 0.9437386569872959|1.8712880291005292| 1| 4156882000|
| 103| 0| 1| 7| 0| 4| 2| 13| 1| 42| 25|401.67121212121214| 0.0|1775.0833333333333| 107.3| 7.428571428571429| 2.25| 2.8| 981| 834| 42.13234953703704| 0.8045801526717558| 3.830213594276094| 1| 2282375000|
|200005| 1| 0| 0| 0| 2| 1| 0| 0| 5| 3| 87.39722222222223| 24.0|185.08333333333334|23.166666666666668| 1.75| 0.0| 2.5| 138| 131|113.13180555555556| 0.5517241379310345|18.855300925925928| 1| 315580000|
| 38| 1| 0| 12| 3| 2| 1| 9| 1| 30| 21|342.28749999999997| 25.716666666666665| 1179.95| 82.625| 5.909090909090909| 2.3333333333333335| 1.0| 1192| 939| 75.06532407407407| 0.9388535031847134| 4.691582754629629| 1| 16065000|
| 40| 0| 0| 9| 0| 1| 1| 2| 0| 39| 23|251.47058823529417| 9.383333333333333| 797.4833333333333|63.411764705882355| 4.125| 1.2222222222222223| 3.2857142857142856| 1004| 825| 78.96927083333334| 0.7042360060514372| 4.645251225490196| 1| 1274274000|
| 128| 1| 0| 6| 2| 1| 1| 14| 0| 53| 28| 416.6254901960784| 0.0| 1817.3| 108.0| 6.214285714285714| 1.5| 2.75| 1539| 1163| 95.33168981481481| 0.9661344944363812| 5.607746459694988| 1| 115894000|
|200024| 1| 1| 4| 1| 5| 1| 4| 0| 15| 9|211.70833333333331| 52.166666666666664| 579.0333333333333| 52.125| 3.1666666666666665| 1.8571428571428572| 4.5| 402| 368| 28.42769675925926| 0.3804347826086957|3.5534620949074074| 1| 3268889000|
| 23| 0| 0| 4| 0| 1| 1| 5| 0| 21| 15| 682.5541666666667| 29.783333333333335| 2374.633333333333| 164.0| 7.0| 6.0| 6.333333333333333| 624| 553|135.89708333333334| 0.7557544757033248|33.974270833333335| 1| 599798000|
| 41| 0| 0| 19| 1| 0| 0| 23| 0| 61| 36| 657.6722222222223|0.016666666666666666| 2278.2|157.83333333333334| 7.6| 2.0| 1.0| 1699| 1319|110.77247685185185| 1.0| 9.23103973765432| 1| 613144000|
|100021| 1| 1| 0| 2| 2| 0| 0| 0| 7| 7| 215.2266666666667| 30.4| 605.1833333333333| 46.0| 2.75| 1.6666666666666667| 6.0| 226| 207| 64.73886574074074| 0.0|12.947773148148148| 0| 478684000|
| 29| 1| 1| 28| 0| 5| 1| 18| 0| 89| 47| 365.7568627450981| 8.1|2167.7833333333333| 89.05882352941177| 5.703703703703703| 1.8333333333333333| 1.8333333333333333| 2562| 1804|60.104050925925925| 0.8917568692756037|1.7677662037037036| 1| 1441435000|
| 69| 0| 0| 7| 4| 1| 1| 9| 0| 33| 12| 526.6851851851852| 11.483333333333333|1263.7833333333333| 125.0| 8.0| 1.8| 1.5| 1036| 865| 71.42444444444445| 0.9709388971684053| 7.93604938271605| 1| 627235000|
+------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
only showing top 20 rows
root
|-- userId: string (nullable = true)
|-- gender: string (nullable = true)
|-- Churn: string (nullable = true)
|-- num_Help: string (nullable = true)
|-- num_Error: string (nullable = true)
|-- num_Upgrade: string (nullable = true)
|-- num_SubmitUpgrade: string (nullable = true)
|-- num_Downgrade: string (nullable = true)
|-- SubmitDowngrade: string (nullable = true)
|-- num_Add_to_Playlist: string (nullable = true)
|-- num_Add_Friend: string (nullable = true)
|-- avgSessionTime: string (nullable = true)
|-- minSessionTime: string (nullable = true)
|-- maxSessionTime: string (nullable = true)
|-- avgSessionSong: string (nullable = true)
|-- avgSessionThumbs_Up: string (nullable = true)
|-- avgSessionThumbs_Down: string (nullable = true)
|-- avgSessionRoll_Advert: string (nullable = true)
|-- userSongCount: string (nullable = true)
|-- userArtistCount: string (nullable = true)
|-- regDay: string (nullable = true)
|-- user_paied: string (nullable = true)
|-- SessionOfday: string (nullable = true)
|-- level: string (nullable = true)
|-- user_silence: string (nullable = true)
colNames = final_data.columns
for colName in colNames:
final_data = final_data.withColumn(colName, col(colName).cast("double"))
final_data.show()
+--------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
| userId|gender|Churn|num_Help|num_Error|num_Upgrade|num_SubmitUpgrade|num_Downgrade|SubmitDowngrade|num_Add_to_Playlist|num_Add_Friend| avgSessionTime| minSessionTime| maxSessionTime| avgSessionSong|avgSessionThumbs_Up|avgSessionThumbs_Down|avgSessionRoll_Advert|userSongCount|userArtistCount| regDay| user_paied| SessionOfday|level|user_silence|
+--------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
|100004.0| 0.0| 0.0| 6.0| 2.0| 8.0| 3.0| 10.0| 2.0| 23.0| 19.0|185.98650793650793| 0.0| 940.2166666666667| 47.1| 2.6923076923076925| 1.5714285714285714| 6.615384615384615| 881.0| 733.0|172.44008101851853|0.44497991967871486| 8.211432429453263| 1.0| 1.63401E8|
| 104.0| 0.0| 0.0| 15.0| 1.0| 3.0| 1.0| 24.0| 0.0| 43.0| 23.0| 281.0339743589744| 25.783333333333335| 993.65| 68.5| 3.8181818181818183| 1.4166666666666667| 2.3| 1571.0| 1214.0|125.58270833333333| 0.8363039399624765| 4.830104166666667| 1.0| 2.73696E8|
| 60.0| 1.0| 0.0| 7.0| 2.0| 1.0| 1.0| 21.0| 0.0| 58.0| 27.0|380.71481481481476| 7.716666666666667| 992.2333333333333| 91.33333333333333| 5.25| 1.2857142857142858| 1.0| 1477.0| 1137.0| 71.48456018518519| 0.982051282051282|3.9713644547325107| 1.0| 4.31789E8|
| 68.0| 0.0| 0.0| 0.0| 0.0| 1.0| 0.0| 0.0| 0.0| 0.0| 7.0| 63.74166666666667| 33.53333333333333| 93.95| 14.5| 1.0| 0.0| 2.0| 29.0| 29.0| 100.0112962962963| 0.0| 50.00564814814815| 0.0| 6.21492E8|
| 90.0| 1.0| 0.0| 2.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0| 29.70666666666667| 0.0| 74.38333333333334| 9.25| 0.0| 0.0| 1.5| 37.0| 37.0|101.98753472222222| 0.0|20.397506944444444| 0.0| 8.15529E8|
| 126.0| 1.0| 0.0| 15.0| 2.0| 3.0| 1.0| 22.0| 0.0| 72.0| 33.0| 357.505| 0.0| 1533.75| 88.86206896551724| 6.136363636363637| 1.9090909090909092| 2.6923076923076925| 2229.0| 1643.0| 62.09569444444445| 0.8588007736943907|2.0698564814814815| 1.0| 2.999E7|
| 131.0| 1.0| 0.0| 13.0| 4.0| 1.0| 1.0| 15.0| 2.0| 51.0| 26.0|340.22456140350874| 0.0| 855.6666666666666| 92.0| 4.5| 1.6666666666666667| 1.6666666666666667| 1403.0| 1100.0|120.89991898148148| 0.9447128287707998| 6.363153630604288| 0.0| 7.4383E7|
| 140.0| 0.0| 0.0| 34.0| 7.0| 10.0| 4.0| 50.0| 3.0| 148.0| 143.0|328.06525821596244| 0.0| 2230.266666666667| 84.53731343283582| 5.12962962962963| 2.027027027027027| 3.0| 4426.0| 2819.0| 80.60512731481481| 0.8229651162790698| 1.135283483307251| 1.0| 1.6074E7|
| 17.0| 0.0| 1.0| 5.0| 0.0| 4.0| 1.0| 12.0| 0.0| 30.0| 12.0| 601.25| 9.933333333333334|1546.4333333333334|132.42857142857142| 8.0| 3.25| 4.0| 875.0| 741.0|13.099016203703703| 0.9437386569872959|1.8712880291005292| 1.0| 4.156882E9|
| 103.0| 0.0| 1.0| 7.0| 0.0| 4.0| 2.0| 13.0| 1.0| 42.0| 25.0|401.67121212121214| 0.0|1775.0833333333333| 107.3| 7.428571428571429| 2.25| 2.8| 981.0| 834.0| 42.13234953703704| 0.8045801526717558| 3.830213594276094| 1.0| 2.282375E9|
|200005.0| 1.0| 0.0| 0.0| 0.0| 2.0| 1.0| 0.0| 0.0| 5.0| 3.0| 87.39722222222223| 24.0|185.08333333333334|23.166666666666668| 1.75| 0.0| 2.5| 138.0| 131.0|113.13180555555556| 0.5517241379310345|18.855300925925928| 1.0| 3.1558E8|
| 38.0| 1.0| 0.0| 12.0| 3.0| 2.0| 1.0| 9.0| 1.0| 30.0| 21.0|342.28749999999997| 25.716666666666665| 1179.95| 82.625| 5.909090909090909| 2.3333333333333335| 1.0| 1192.0| 939.0| 75.06532407407407| 0.9388535031847134| 4.691582754629629| 1.0| 1.6065E7|
| 40.0| 0.0| 0.0| 9.0| 0.0| 1.0| 1.0| 2.0| 0.0| 39.0| 23.0|251.47058823529417| 9.383333333333333| 797.4833333333333|63.411764705882355| 4.125| 1.2222222222222223| 3.2857142857142856| 1004.0| 825.0| 78.96927083333334| 0.7042360060514372| 4.645251225490196| 1.0| 1.274274E9|
| 128.0| 1.0| 0.0| 6.0| 2.0| 1.0| 1.0| 14.0| 0.0| 53.0| 28.0| 416.6254901960784| 0.0| 1817.3| 108.0| 6.214285714285714| 1.5| 2.75| 1539.0| 1163.0| 95.33168981481481| 0.9661344944363812| 5.607746459694988| 1.0| 1.15894E8|
|200024.0| 1.0| 1.0| 4.0| 1.0| 5.0| 1.0| 4.0| 0.0| 15.0| 9.0|211.70833333333331| 52.166666666666664| 579.0333333333333| 52.125| 3.1666666666666665| 1.8571428571428572| 4.5| 402.0| 368.0| 28.42769675925926| 0.3804347826086957|3.5534620949074074| 1.0| 3.268889E9|
| 23.0| 0.0| 0.0| 4.0| 0.0| 1.0| 1.0| 5.0| 0.0| 21.0| 15.0| 682.5541666666667| 29.783333333333335| 2374.633333333333| 164.0| 7.0| 6.0| 6.333333333333333| 624.0| 553.0|135.89708333333334| 0.7557544757033248|33.974270833333335| 1.0| 5.99798E8|
| 41.0| 0.0| 0.0| 19.0| 1.0| 0.0| 0.0| 23.0| 0.0| 61.0| 36.0| 657.6722222222223|0.016666666666666666| 2278.2|157.83333333333334| 7.6| 2.0| 1.0| 1699.0| 1319.0|110.77247685185185| 1.0| 9.23103973765432| 1.0| 6.13144E8|
|100021.0| 1.0| 1.0| 0.0| 2.0| 2.0| 0.0| 0.0| 0.0| 7.0| 7.0| 215.2266666666667| 30.4| 605.1833333333333| 46.0| 2.75| 1.6666666666666667| 6.0| 226.0| 207.0| 64.73886574074074| 0.0|12.947773148148148| 0.0| 4.78684E8|
| 29.0| 1.0| 1.0| 28.0| 0.0| 5.0| 1.0| 18.0| 0.0| 89.0| 47.0| 365.7568627450981| 8.1|2167.7833333333333| 89.05882352941177| 5.703703703703703| 1.8333333333333333| 1.8333333333333333| 2562.0| 1804.0|60.104050925925925| 0.8917568692756037|1.7677662037037036| 1.0| 1.441435E9|
| 69.0| 0.0| 0.0| 7.0| 4.0| 1.0| 1.0| 9.0| 0.0| 33.0| 12.0| 526.6851851851852| 11.483333333333333|1263.7833333333333| 125.0| 8.0| 1.8| 1.5| 1036.0| 865.0| 71.42444444444445| 0.9709388971684053| 7.93604938271605| 1.0| 6.27235E8|
+--------+------+-----+--------+---------+-----------+-----------------+-------------+---------------+-------------------+--------------+------------------+--------------------+------------------+------------------+-------------------+---------------------+---------------------+-------------+---------------+------------------+-------------------+------------------+-----+------------+
only showing top 20 rows
建模、训练、评估
数据准备
inputcols = [
'gender', 'num_Help', 'num_Error', 'num_Upgrade', 'num_SubmitUpgrade',
'num_Downgrade', 'SubmitDowngrade', 'num_Add_to_Playlist',
'num_Add_Friend', 'avgSessionTime', 'minSessionTime', 'maxSessionTime',
'avgSessionSong', 'avgSessionThumbs_Up', 'avgSessionThumbs_Down',
'avgSessionRoll_Advert', 'userSongCount', 'userArtistCount', 'regDay',
'user_paied', 'SessionOfday', 'level', 'user_silence'
]
# 数据转换成一个向量
assembler = VectorAssembler(inputCols=inputcols, outputCol="NumFeatures")
dataset = assembler.transform(final_data)
# 数据标准化
scaler = StandardScaler(inputCol="NumFeatures",
outputCol="ScaledNumFeatures",
withStd=True)
scalerModel = scaler.fit(dataset)
dataset = scalerModel.transform(dataset)
# 特征、标签划分
dataset = dataset.select(
col('Churn').alias('label'),
col('ScaledNumFeatures').alias('features'))
dataset.take(5)
[Row(label=0.0, features=DenseVector([0.0, 0.8284, 1.3581, 3.1268, 4.0879, 0.8522, 3.4033, 0.703, 0.9231, 1.0517, 0.0, 1.2999, 1.1052, 1.1114, 1.6969, 2.8845, 0.9828, 1.2137, 4.5787, 1.0911, 0.5432, 2.0844, 0.1135])),
Row(label=0.0, features=DenseVector([0.0, 2.0711, 0.6791, 1.1725, 1.3626, 2.0453, 0.0, 1.3143, 1.1175, 1.5892, 0.2844, 1.3737, 1.6074, 1.5762, 1.5298, 1.0029, 1.7526, 2.0101, 3.3345, 2.0507, 0.3195, 2.0844, 0.1902])),
Row(label=0.0, features=DenseVector([2.0013, 0.9665, 1.3581, 0.3908, 1.3626, 1.7896, 0.0, 1.7728, 1.3118, 2.1528, 0.0851, 1.3718, 2.1432, 2.1673, 1.3884, 0.436, 1.6477, 1.8826, 1.8981, 2.4081, 0.2627, 2.0844, 0.3])),
Row(label=0.0, features=SparseVector(23, {3: 0.3908, 8: 0.3401, 9: 0.3604, 10: 0.3699, 11: 0.1299, 12: 0.3403, 13: 0.4128, 15: 0.8721, 16: 0.0324, 17: 0.048, 18: 2.6555, 20: 3.3079, 22: 0.4318})),
Row(label=0.0, features=SparseVector(23, {0: 2.0013, 1: 0.2761, 9: 0.168, 11: 0.1028, 12: 0.2171, 15: 0.654, 16: 0.0413, 17: 0.0613, 18: 2.708, 20: 1.3493, 22: 0.5666}))]
dataset.count()
225
划分训练集、测试集
train, test = dataset.randomSplit([0.8, 0.2], seed=77)
train.count()
177
模型训练
怎样选择模型呢?我们看下数据分布,52/173的流失分布,数据不太平衡,但是不算严重到超过90%,由于决策树可以很好的拟合失衡数据,所以选择逻辑回归、决策树、随机森林三个算法进行比较选择。
逻辑回归
Logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0和1上。其损失函数的目的是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
应用:
用于分类:适合做很多分类算法的基础组件。
用于预测:预测事件发生的概率(输出)。
用于分析:单一因素对某一个事件发生的影响因素分析(特征参数值)。
适用:
基本假设:
输出类别服从伯努利二项分布。
样本线性可分。
特征空间不是很大的情况。
不必在意特征间相关性的情景。
后续会有大量新数据的情况。
逻辑回归的优缺点
优点:
1,实现简单,广泛的应用于工业问题上;
2,分类时计算量非常小,速度很快,存储资源低;
3, 便利的观测样本概率分数;
4,对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
5,计算代价不高,易于理解和实现;
缺点:
1,当特征空间很大时,逻辑回归的性能不是很好;
2, 容易欠拟合,一般准确度不太高
3,不能很好地处理大量多类特征或变量;
4,只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
5, 对于非线性特征,需要进行转换;
应用领域:
1、预测是否发生、发生的概率(流失、客户响应等预测)
2、影响因素、危险因素分析(找出影响结果的主要因素)
3、判别、分类
决策树
决策树是一个基本的分类回归算法
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
经典决策树算法:
ID3:只能对离散型属性的数据集构造决策树,信息增益作为节点特征选择
C4.5:ID3的扩展、可以处理连续型变量、可以处理缺失值、剪枝,信息增益比作为节点特征选择
CART:可以处理离散型或连续型变量、并可以分类/回归,使用gini系数作为节点特征选择
优点:
1、生成的决策树结果很直观
2、基本不需要预处理,不需要提前归一化,处理缺失值
3、既可以处理离散值也可以处理连续值
4、可以很容易处理分类问题
5、相比于神经网络之类的黑盒分类模型,决策树的可解释性很好
6、可以用交叉验证的剪枝来选择模型,从而提高泛化能力
7、对于异常值的容错能力号,健壮性高
缺点:
1、决策树算法容易过拟合
2、决策树会因为样本发生一点点的改动而导致结果变化
3、寻找最优的决策树是一个NP难的问题,容易陷入局部最优
4、有些复杂的关系,决策树很难学习到,例如异或关系
5、没有在线学习
适用情景:
因为它能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
应用场景:
1、熵的例子:论坛流失性跟性别还是和活跃度有关
2、基尼的列子:拖欠贷款和是否有房、婚姻状况、收入的关联性
3、贷款风险评估
4、保险推广预测
随机森林
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那麽随机森林就会把这个结果当做最终的结果。
构造随机森林的4个步骤:
假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中採用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
优点:
1、在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合。
2、在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力。
3、它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
4、在创建随机森林的时候,对generlization error使用的是无偏估计。
5、训练速度快,可以得到变量重要性排序。
6、在训练过程中,能够检测到feature间的互相影响。
7、容易做成并行化方法。
8、实现比较简单
缺点:
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
随机森林应用场景:应用于各项AI大赛。
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
如何确定评估指标?
常用分类指标有准确率、精确率、召回率、F1、AUC与对数损失(Logistic Loss,logloss)。
精确率和召回率多用于二分类问题,需要结合混淆矩阵介绍,如下所示:

其中,TP(真正,True Positive)表示真实结果为正例,预测结果也为正例;FP(假正,False Positive)表示真实结果为负例,预测结果却是正例;TN(真负,True Negative)表示真实结果为负例,预测结果是负例;FN(假负,False Negative)表示真实结果为正例,预测结果是负例。
显然,TP+FP+FN+TN=样本总数。
根据混淆矩阵可以引出如下指标定义:
准确率(Acc):所有的样本中预测正确的比例,计算公式如下:

召回率(Recall)也称查全率、敏感度(Sensitive):所有正样本中预测正确的比例,即正样本的准确率,计算公式如下:

特异性(Specificity):所有负样本中预测正确的比例,即负样本的准确率,计算公式如下:

精确率(Precision)也称查准率:所有预测为正样本的集合中预测正确的比例,计算公式如下:

F1 Score:综合精确率和召回率指标,计算公式如下:

ROC曲线就是以true positive rate 和 false positive rate为轴,取不同的threshold点画的。基本上,曲线下的面积(AUC)越大,或者说曲线更接近左上角(true positive rate=1, false positive rate=0),那么模型就越理想,越好。ROC curve 可以很好的回答什么问题呢——“不论class的基本概率怎么样,我的模型in general能表现得多好?”

以下是参考来源:
作者:邓小乔
链接:https://www.zhihu.com/question/30643044/answer/224360465
来源:知乎
作者:pptb
链接:https://www.jianshu.com/p/ce70c716c9d1
来源:简书
确定评估指标
由于本次数据分布不平衡,流失率约为25%,而且我们需要综合考虑模型预测的准确率与召回率,所以选择F1调和平均数作为评估指标。这样,可以保证评估的模型既能尽可能准确地预测,又能尽可能多地找到会流失的客户。
LR = create_model(LogisticRegression)
LR.save("LR_7")
Model Run Successfully ; Looking at metrics for <class 'pyspark.ml.classification.LogisticRegression'> model:
with total time taken 6.39 seconds
Accuracy: 0.8958333333333334
F-1 Score:0.8940476190476191
DC = create_model(DecisionTreeClassifier)
DC.save("DC_7")
Model Run Successfully ; Looking at metrics for <class 'pyspark.ml.classification.DecisionTreeClassifier'> model:
with total time taken 4.19 seconds
Accuracy: 0.9166666666666666
F-1 Score:0.9135964912280702
RF = create_model(RandomForestClassifier)
RF.save("RF_7")
Model Run Successfully ; Looking at metrics for <class 'pyspark.ml.classification.RandomForestClassifier'> model:
with total time taken 3.10 seconds
Accuracy: 0.9375
F-1 Score:0.9337833219412167
以上三个模型,随机森林表现最好。
网格搜索、调参
# 网格搜索、调参
model = RandomForestClassifier()
param_grid = ParamGridBuilder() \
.addGrid(model.maxDepth,[5,8,10]) \
.addGrid(model.numTrees,[5,10,20])\
.build()
cross_val = CrossValidator(
estimator=model,
estimatorParamMaps=param_grid,
evaluator=MulticlassClassificationEvaluator(metricName='f1'),
numFolds=3)
model_fit = cross_val.fit(train)
model_fit.avgMetrics
results = model_fit.transform(test)
evaluation = MulticlassClassificationEvaluator(predictionCol="prediction")
print('Metrics for RandomForestClassifier after Hypertuning the Parameters')
print('Accuracy: {}'.format(
evaluation.evaluate(results, {evaluation.metricName: "accuracy"})))
print('F-1 Score:{}'.format(
evaluation.evaluate(results, {evaluation.metricName: "f1"})))
Metrics for RandomForestClassifier after Hypertuning the Parameters
Accuracy: 0.875
F-1 Score:0.875
发现网格搜索后分数没有提升,模型之前拟合效果已经达到了。
小结:
本数据集只有200多行,训练规模有限,为了评估模型的综合表现,充分利用数据集,我们采用交叉验证的方式进行模型训练,并得到最好的模型。
根据交叉验证的最好的模型,我们进行进一步的调参,虽然分数没有提高,但是也是不错的尝试。
我们调参后的模型在整个训练集上进行拟合,训练集上拟合分数为,
在测试集上,我们验证最终模型的准确度,准确度、F1分值都达到85分左右,说明模型在预测的准确率和召回率都有不错的表现,没有出现过拟合的现象。因此相信,模型在大的数据集上可以有稳健的表现。
查看各因子的重要度
# 查看最佳模型的参数重要度
best_model = RF
coeffs = best_model.featureImportances
coeff_dict = dict(zip(inputcols, coeffs.toArray().tolist()))
coeff_df = pd.DataFrame.from_dict(coeff_dict,
orient='index',
columns=["coeff"])
coeff_df.index.name = 'Feature'
coeff_df = coeff_df.reset_index()
coeff_df
| Feature | coeff | |
|---|---|---|
| 0 | gender | 0.008490 |
| 1 | num_Help | 0.019056 |
| 2 | num_Error | 0.010006 |
| 3 | num_Upgrade | 0.015864 |
| 4 | num_SubmitUpgrade | 0.002033 |
| 5 | num_Downgrade | 0.022901 |
| 6 | SubmitDowngrade | 0.008575 |
| 7 | num_Add_to_Playlist | 0.056943 |
| 8 | num_Add_Friend | 0.019998 |
| 9 | avgSessionTime | 0.014511 |
| 10 | minSessionTime | 0.037277 |
| 11 | maxSessionTime | 0.034484 |
| 12 | avgSessionSong | 0.017918 |
| 13 | avgSessionThumbs_Up | 0.040048 |
| 14 | avgSessionThumbs_Down | 0.012691 |
| 15 | avgSessionRoll_Advert | 0.026755 |
| 16 | userSongCount | 0.037158 |
| 17 | userArtistCount | 0.030651 |
| 18 | regDay | 0.133935 |
| 19 | user_paied | 0.033902 |
| 20 | SessionOfday | 0.075400 |
| 21 | level | 0.004540 |
| 22 | user_silence | 0.336864 |
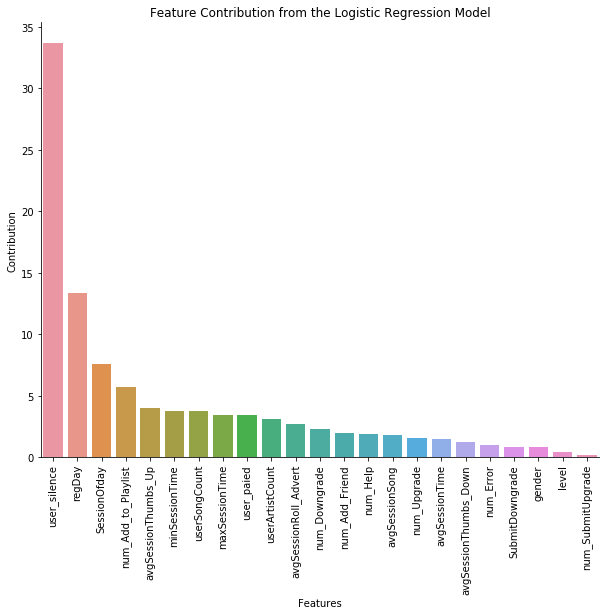
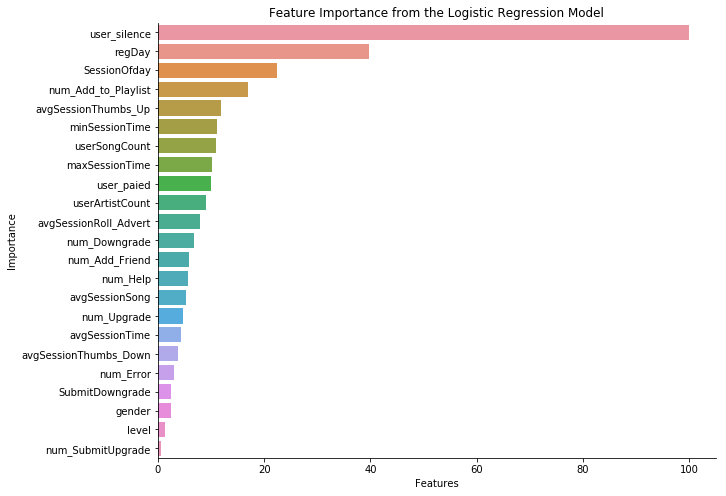
发现用户沉默的时间、用户注册的天数、平均每次登陆在线时长是最主要的影响因素,其他的每次登陆的统计指标也都有一定影响,几乎没有影响的是级别、性别、升级次数、倒赞的次数。比较意外的是,平常喜欢差评的用户,居然不是流失的主人群。流失最大影响还是用户是否上线,沉默用户最容易流失。
coeff_df["contribution"] = coeff_df["coeff"] * 100 / coeff_df["coeff"].abs(
).sum()
plt.figure(figsize=(10, 8))
ax = sns.barplot(data=coeff_df, y="contribution", x="Feature")
plt.xlabel('Features')
plt.ylabel('Contribution')
plt.xticks(rotation=90)
plt.title('Feature Contribution from the Logistic Regression Model')
sns.despine(ax=ax)
coeff_df["importance"] = coeff_df["coeff"].abs() * 100 / coeff_df["coeff"].abs(
).max()
coeff_df = coeff_df.sort_values('importance', ascending=False)
plt.figure(figsize=(10, 8))
ax = sns.barplot(data=coeff_df, x="importance", y="Feature", orient='h')
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importance from the Logistic Regression Model')
sns.despine(ax=ax)
案例总结
**1,困难和挑战-数据转换是关键
数据集是客户的原始日志,包括用户信息、时间信息、操作信息等,超过28万条,如何利用这些信息提取用户的特征是关键。我们通过数据的整合转换构造了包含200多个用户ID、23列特征的新表,所以事实上我们训练的数据并不大,可以说还比较有限,只有200多个用户。而且分布不平衡。**
2,关键点-特征构造要多思考
通过数据清洗、观察、探索等步骤,结合业务实际情况,我们构造了不同的用户特征,这些特征是否有效需要模型验证,但是构造特征的思考方法很重要。通过此次尝试,相信在未来的业务情境中,我们同样可以很好完成特征构造的任务。
3,了解模型和数据,再选择
根据数据集的分布特征,我们探索了如何选择合适的模型,以及有效的评估指标。
4,意外:随机森林时间短,分数高
在此基础上,没有经过复杂的调参,逻辑回归、决策树与随机森林表现都很好,说明我们的特征非常有效提供了训练信息。后续可以尝试在更大的数据集上去进行测试。出乎预料,随机森林反而是训练时间最短的,而且分数最高的。
5,发现-影响最大的是用户沉默时间
通过最高分数随机森林模型,查看到影响用户流失最大的三个因素是:用户沉默时间、用户注册日期、用户平均每次登陆在线时长。说明沉默的用户最容易流失,需要通过不同的push或者活动,激活这些用户,防止流失。
6,需要改进的方面
在实际的APP用户流失预测中,日志都是目前已有的,然后需要对未来进行预测,所以训练集、与实际验证的数据实际上在时间上分开的,或者说实际数据是随时间实时产生的。而在此项目中,用户特征的构造已经包含了所有时间点的信息。所以应用在实际中,该模型分数可能没这么高。改进的方式,可以尝试将日志分为t,t+1段两部分,通过t时间内的数据构造模型,通过t+1时间进行测试,以此来训练更有效应用的模型。
7,可以进行的尝试
真是训练的数据集只有200多个用户,可以考虑在分布式集群更多的数据上进行探索。
参考链接:
Brian&Rogers 《A!Simple!Guide!to!Churn!Analysis》
https://www.silect.is/blog/2019/4/2/random-forest-in-spark-ml
https://easyai.tech/ai-definition/logistic-regression/
https://www.jianshu.com/p/2b1b862d176a
https://blog.csdn.net/login_sonata/java/article/details/54288653
https://easyai.tech/ai-definition/random-forest/
https://zhuanlan.zhihu.com/p/31711537

 浙公网安备 33010602011771号
浙公网安备 33010602011771号