
学号:351
原创作品转载请注明出处
本实验来源 https://github.com/mengning/linuxkernel/
实验要求
从整理上理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换:
实验内容
阅读理解task_struct数据结构
task_struct:
操作系统使用数据结构来代表处理不同的实体,这个数据结构就是通常所说的进程描述符或进程控制块(PCB)。
而在linux操作系统下这就是task_struct结构 ,所属的头文件#include <sched.h>每个进程都会被分配一个task_struct结构,它包含了这个进程的所有信息,在任何时候操作系统都能够跟踪这个结构的信息。
包括这个进程的主要信息:
1、与进程相关的唯一标识符,区别正在执行的进程和其他进程
2、状态:描述进程的状态,因为进程有阻塞、挂起、运行等好几个状态,所以都有个表示符来记录进程的执行状态。
3、优先级:如果有好几个进程正在执行,就涉及到进程的执行的先后顺序,这和进程的优先级这个标识符有关。
4、程序计数器:程序中即将被执行指令的下一条地址。
5、内存指针:程序代码和进程相关数据的指针。
6、上下文数据:进程执行时处理器的寄存器中的数据。
7、I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
8、记账信息:包括处理机的时间总和,记账号等等。
使用gdb跟踪分析一个fork系统调用内核处理函数do_fork
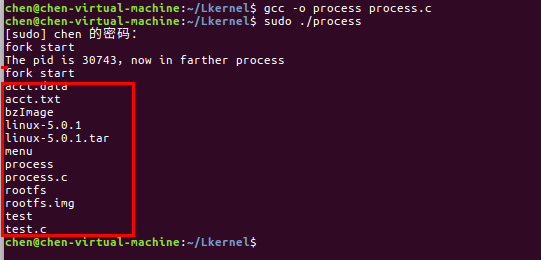
1,先编写proces.c查看fork()运行结果
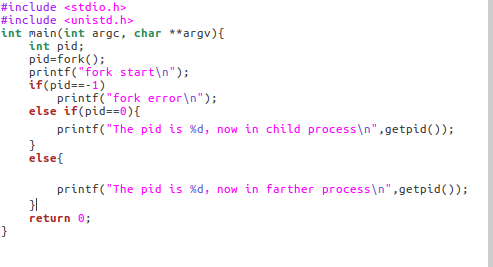
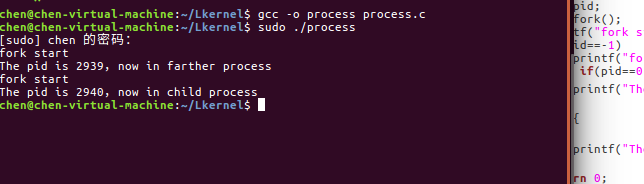
从运行结果中,可以看出父进程和子进程各返回一次。pid == 0时,子进程运行,pid == 其他值,父进程运行,
2,使用gdb跟踪fork系统调用
1.使用内核5.0.1启动Menu OS
cd LinuxKernel
rm menu -rf
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c
设置断点
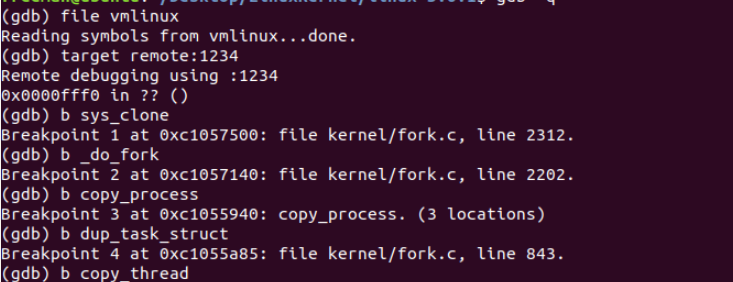
观察运行结果
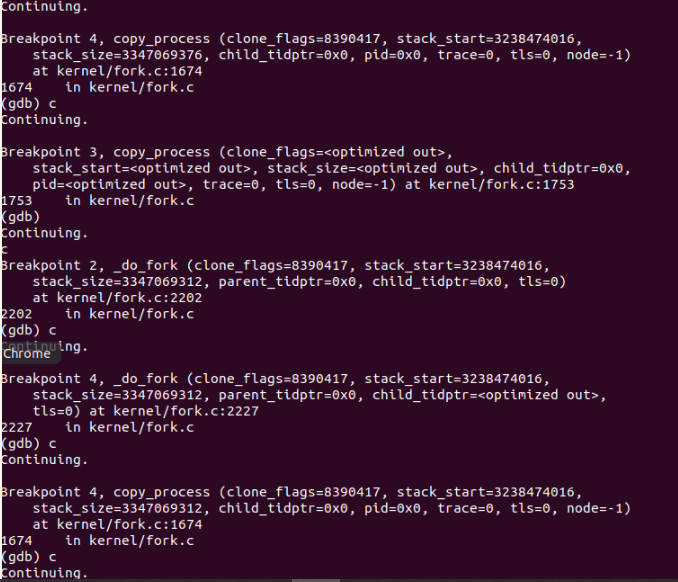
理解编译链接的过程和ELF可执行文件格式
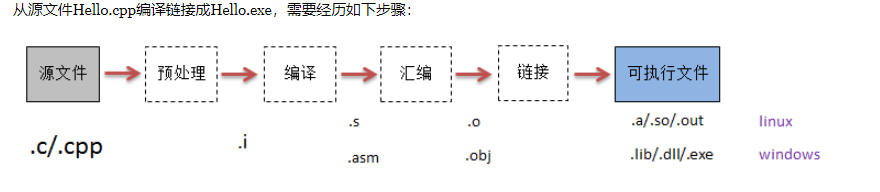
预处理:主要是做一些代码文本的替换工作。(该替换是一个递归逐层展开的过程。)
(1)将所有的#define删除,并展开所有的宏定义
(2)处理所有的条件预编译指令,如:#if #ifdef #elif #else #endif
(3)处理#include预编译指令,将被包含的文件插进到该指令的位置,这个过程是递归的
(4)删除所有的注释//与/* */
(5)添加行号与文件名标识,以便产生调试用的行号信息以及编译错误或警告时能够显示行号
(6)保留所有的#pragma编译器指令,因为编译器需要使用它们
编译:
把预处理完的文件进行一系列词法分析(lex)、语法分析(yacc)、语义分析及优化后生成汇编代码,这个过程是程序构建的核心部分。
汇编:
将汇编代码转成机器指令。
链接:
此时的链接,严格说应该叫静态链接。将多个目标文件、库拼合成最终的可执行文件。
ELF文件在Linux下,可执行文件/动态库文件/目标文件(可重定向文件)都是同一种文件格式,将其称之为ELF文件格式。 虽然它们三个都是ELF文件格式但都各有不同:可执行文件没有section header table 。 目标文件没有program header table。 动态库文件俩个 header table 都有,
整体结构 :
ELF头部(ELF_Header): 每个ELF文件都必须存在一个ELF_Header,这里存放了很多重要的信息用来描述整个文件的组织,如: 版本信息,入口信息,偏移信息等。程序执行也必须依靠其提供的信息。
程序头部表(Program_Header_Table): 可选的一个表,用于告诉系统如何在内存中创建映像,在图中也可以看出来,有程序头部表才有段,有段就必须有程序头部表。其中存放各个段的基本信息(包括地址指针)。
节区头部表(Section_Header_Table): 类似与Program_Header_Table,但与其相对应的是节区(Section)。
节区(Section): 将文件分成一个个节区,每个节区都有其对应的功能,如符号表,哈希表等。
段(Segment):就是将文件分成一段一段映射到内存中。段中通常包括一个或多个节区
使用exec*库函数加载一个可执行文件
exec()族函数功能是将当前的进程替换成一个新的进程,执行到exec()函数时当前进程就会结束新进程则开始执行。但新进程保留之前进程的进程号,本文以execl()函数为例来进行讲解。
execl()函数原型
#include <unistd.h> int execl(const char *path, const char *arg, .../* (char *) NULL */);
参数
path - 执行文件的路径
arg - 执行文件的参数,可以比作arg0,,arg1,,arg2,…,argn
最后一个参数必须赋值为NULL
返回值
execl()函数只有在失败时才会返回,返回值为-1并设置errno信息。
修改之前process.c的代码

执行结果:pid == 0 时,子进程并不会执行,而是被替换成一个新的进程,相当于执行了 "ls -l"命令,执行结果如下:
Linux系统中进程调度
调度的实际
-
中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
-
内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
-
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
gdb跟踪分析一个schedule()函数
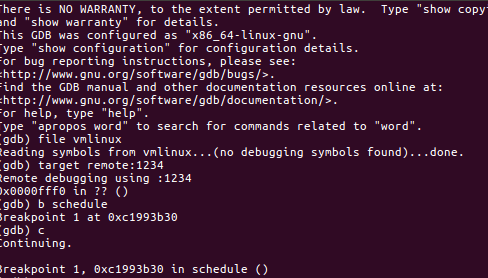
schecule函数的所作的工作:
确定当前就绪队列, 并在保存一个指向当前(仍然)活动进程的task_struct指针
检查死锁, 关闭内核抢占后调用__schedule完成内核调度
恢复内核抢占, 然后检查当前进程是否设置了重调度标志TLF_NEDD_RESCHED, 如果该进程被其他进程设置了TIF_NEED_RESCHED标志, 则函数重新执行进行调度
分析switch_to中的汇编代码,理解进程上下文的切换机制,以及与中断上下文切换的关系
schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换 next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部 context_switch(rq, prev, next);//进程上下文切换 switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程 31#define switch_to(prev, next, last) \ 32do { \ /* \ * Context-switching clobbers all registers, so we clobber \ * them explicitly, via unused output variables. \ * (EAX and EBP is not listed because EBP is saved/restored \ * explicitly for wchan access and EAX is the return value of \ * __switch_to()) \ */ \ unsigned long ebx, ecx, edx, esi, edi; \ \ asm volatile("pushfl\n\t" /* save flags */ \ "pushl %%ebp\n\t" /* save EBP */ \ 当前进程堆栈基址压栈 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \ 将当前进程栈顶保存prev->thread.sp "movl %[next_sp],%%esp\n\t" /* restore ESP */ \ 讲下一个进程栈顶保存到esp中 "movl $1f,%[prev_ip]\n\t" /* save EIP */ \ 保存当前进程的eip "pushl %[next_ip]\n\t" /* restore EIP */ \ 将下一个进程的eip压栈,next进程的栈顶就是他的的起点 __switch_canary \ "jmp __switch_to\n" /* regparm call */ \ "1:\t" \ "popl %%ebp\n\t" /* restore EBP */ \ "popfl\n" /* restore flags */ \ 开始执行下一个进程的第一条命令 \ /* output parameters */ \ : [prev_sp] "=m" (prev->thread.sp), \ [prev_ip] "=m" (prev->thread.ip), \ "=a" (last), \ \ /* clobbered output registers: */ \ "=b" (ebx), "=c" (ecx), "=d" (edx), \ "=S" (esi), "=D" (edi) \ \ __switch_canary_oparam \ \ /* input parameters: */ \ : [next_sp] "m" (next->thread.sp), \ [next_ip] "m" (next->thread.ip), \ \ /* regparm parameters for __switch_to(): */ \ [prev] "a" (prev), \ [next] "d" (next) \ \ __switch_canary_iparam \ \ : /* reloaded segment registers */ \ "memory"); \ 77} while (0)
所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
同理,硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理,中断上下文就可以理解为硬件传递过来的这些参数和内核需要保存的一些环境,主要是被中断的进程的环境。
Linux内核工作在进程上下文或者中断上下文。提供系统调用服务的内核代码代表发起系统调用的应用程序运行在进程上下文;另一方面,中断处理程序,异步运行在中断上下文。中断上下文和特定进程无关。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号