


强化学习课程学习(3)——初识Reinforcement Learning
在整理一些相关的数学基础知识后,接下来就让我们来和Reinforcement Learning来个第一次的约会😊😝吧!
这门课程学习笔记会不断更新哦,欢迎关注和沟通学习~~
个人觉得,在学习一个新知识的过程中,一般都会是What->How->Why的思路去认识以及理解这个新知识,那么下面就按照这个思路开始描述强化学习门技术👩💻——
什么是强化学习?
- 强化学习(英语:
Reinforcement Learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。 - 核心思想:智能体
agent在环境environment中学习,根据环境的状态state(或观测到的observation),执行动作action,并根据环境的反馈reward(奖励)来指导更好的动作。
注意:从环境中获取的状态,有时候叫
state,有时候叫observation,这两个其实一个代表全局状态,一个代表局部观测值,在多智能体环境里会有差别,但我们刚开始学习遇到的环境还没有那么复杂,可以先把这两个概念划上等号。

强化学习能用来干什么?
有了强化写学习这个强大的技术,那么这个技术一把能用来干什么呢?能在现实应用中做些什么呢?譬如————
- 游戏(马里奥、Atari、Alpha Go、星际争霸等)
- 机器人控制(机械臂、机器人、自动驾驶、四轴飞行器等)
- 用户交互(推荐、广告、NLP等)
- 交通(拥堵管理等)
- 资源调度(物流、带宽、功率等)
- 金融(投资组合、股票买卖等)
- 其他
强化学习和监督学习的区别
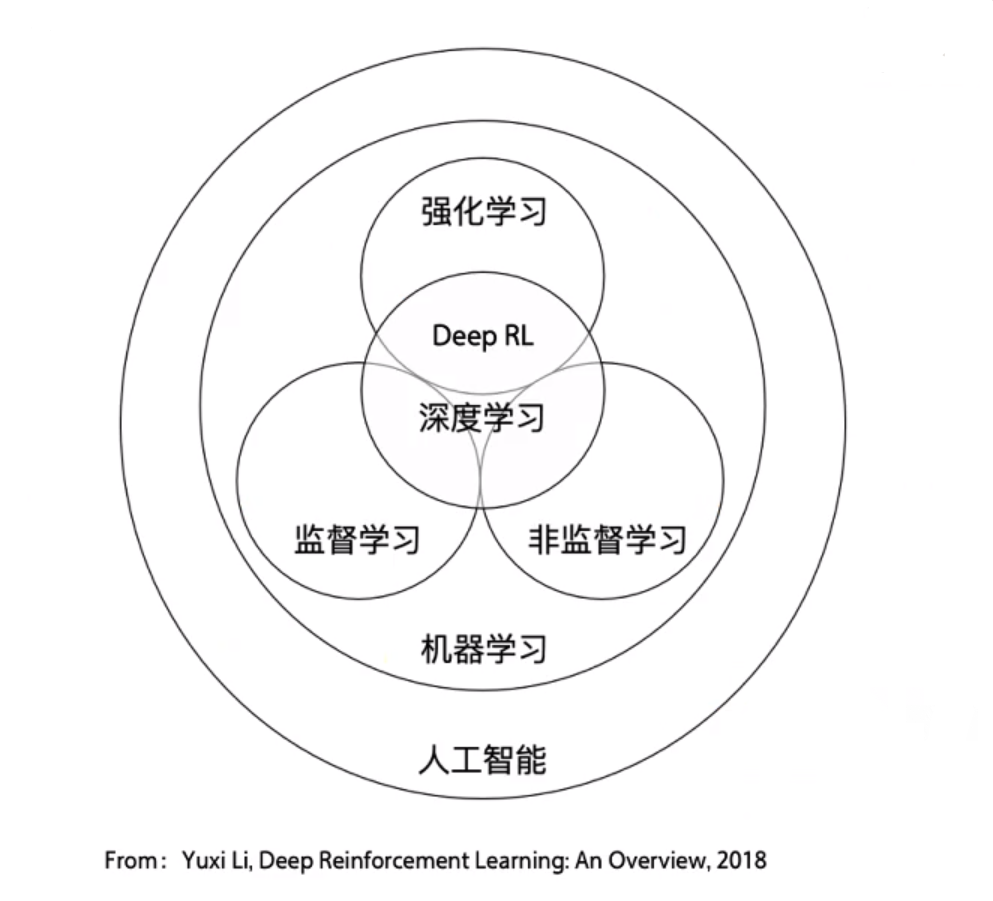
-
强化学习、监督学习和非监督学习都是机器学习中三个不同的领域,都和深度学习有交集;
-
监督学习寻找输入到输出之间的映射,比如分类和回归问题;非监督学习则在于寻找数据之间的隐藏关系,比如聚类问题;强化学习则需要在于与环境的交互中学习和寻找最佳决策方案;
-
监督学习处理的是认知问题,强化学习处理的是决策问题。
换句话说,强化学习和监督学习最大的区别在于强化学习没有监督学习已经准备好的训练数据输出值,强化学习只有奖励值,但是这个奖励值和监督学习的输出值不一样,它不是事先给出的,而是延后计算出的。比如最上面的图,比如学习走路,如果摔倒了,那么我们大脑后面会给一个负面的奖励值,说明走的姿势不好。然后我们从摔倒状态中爬起来,如果后面正常走了一步,那么大脑会给一个正面的奖励值,我们会知道这是一个好的走路姿势。同时,强化学习的每一步与时间顺序前后关系紧密,而监督学习的训练数据之间相互独立,没有前后依赖关系。
强化学习如何解决问题
在了解强化学习和常见的监督学习和非监督学习的区别后,那么强化到底是如何解决问题的呢?——
实际上,强化学习是通过不断地试错探索,吸取教训和经验,持续不断地优化策略,从环境中拿到更好的反馈。一般情况下,强化学习有两种学习方案:基于价值(value-based)&& 基于策略(policy-based) 。
强化学习模型要素
假如根据最上面的那张图为例,上面的大脑代表我们的算法执行个体,我们可以操作个人来作决策,即选择一个合适的动作(action)\(A_t\)。下面的地球代表我们要研究的环境,它有自己的状态模型,我们选择了动作\(A_t\)后,环境的状态(State)会变,我们会发现环境状态已经变为\(S_{t+1}\),同时我们得到了我们采取动作\(A_t\)的延时奖励(Reward)\(R_{t+1}\)。然后个体可以继续选择下一个合适的动作,然后环境的状态又会变,又有新的奖励值。要素如下:
-
环境的状态\(S\), \(t\)时刻环境的状态\(S_t\)是它的环境状态集中某一个状态;
-
个体动作\(A\),\(t\)时刻个体的采取的动作\(A_t\)是它的动作集中的某一个动作;
-
环境的奖励\(R\) , \(t\)时刻个体在状态\(S_t\)采取的动作\(A_t\)对应的奖励\(R_{t+1}\)会在\(t+1\)时刻得到;
-
个体的策略(policy)\(\pi\),代表个体采取动作的依据,即个体会依据策略\(\pi\)来选择动作。最常见的策略方式是一个条件概率分布\(\pi(a|s)\),即在状态\(s\)时采取的动作\(a\)的概率。即\(\pi(a|s)=P(A_t = a | S_t = s)\).此时概率大的动作被个体选择的概率较高。
-
个体在策略\(\pi\)和状态s\(时,采取行动后的价值(value),一般用\)\(v_{\pi}(s)\)表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励\(R_{t+1}\),但是光看这个延时奖励是不行的,因为当前的延时奖励高,不代表到了\(t+1,t+2,...\)时刻的后续奖励也高。比如下象棋,我们可以某个动作可以吃掉对方的车,这个延时奖励是很高,但是接着后面我们输棋了。此时吃车的动作奖励值高但是价值并不高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。价值函数\(v_{\pi}(s)\)一般可以表示为下式,不同的算法会有对应的一些价值函数变种,但思路相同:
\[v_{\pi}(s)=E_{\pi}(R_{t+1}+γR_{t+2}+γ^2R_{t+3}+...|S_t=s) \] -
\(γ\)是第六个模型要素,即奖励衰减因子,在\([0,1]\)之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。大多数时候,我们会取一个0到1之间的数字,即当前延时奖励的权重比后续奖励的权重大。
-
环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态\(s\)下采取动作\(a\),转到下一个状态\(s′\)的概率,表示为\(P^a_{ss′}\)。
-
探索率\(ϵ\),这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率\(ϵ\)不选择使当前轮迭代价值最大的动作,而选择其他的动作。


