
YOLOv3的论文详解
引言
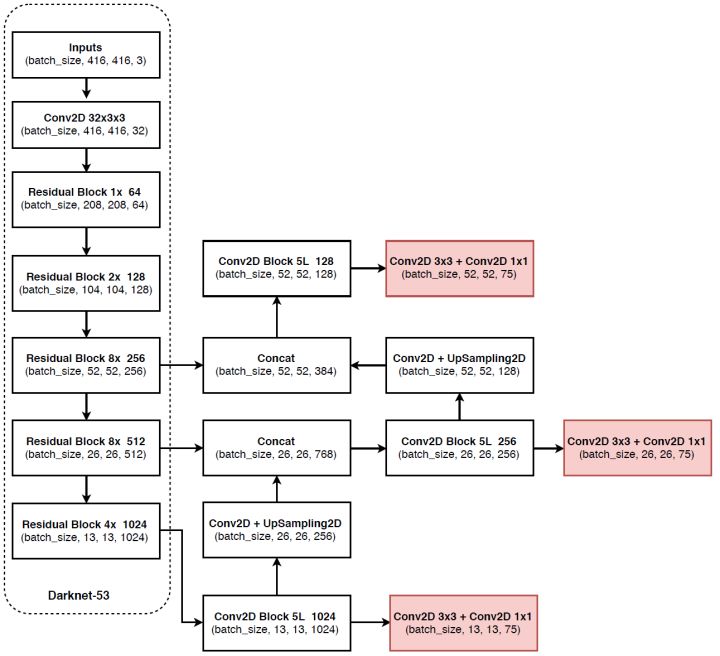
YOLOv3发布了,但是正如作者所说,这仅仅是他们近一年的一个工作报告(TECH REPORT),不算是一个完整的paper,因为他们实际上是把其它论文的一些工作在YOLO上尝试了一下。相比YOLOv2,我觉得YOLOv3最大的变化包括两点:使用残差模型和采用FPN架构。YOLOv3的特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53,从网络结构上看,相比Darknet-19网络使用了残差单元,所以可以构建得更深。另外一个点是采用FPN架构(Feature Pyramid Networks for Object Detection)来实现多尺度检测。YOLOv3采用了3个尺度的特征图(当输入为416 x 416时):(13 x 13), (26 x 26),(52 x 52) ,VOC数据集上的YOLOv3网络结构如图15所示,其中红色部分为各个尺度特征图的检测结果。YOLOv3每个位置使用3个先验框,所以使用k-means得到9个先验框,并将其划分到3个尺度特征图上,尺度更大的特征图使用更小的先验框,和SSD类似。
论文地址:YOLOv3: An Incremental Improvement.
YOLOv3与其它检测模型的对比如下图所示,可以看到在速度上YOLOv3完胜其它方法,虽然AP值并不是最好的(如果比较AP-0.5,YOLOv3优势更明显)。

成功的Trick(创新点)
- 考虑到检测物体的重叠情况,用多标签的方式替代了之前softmax单标签方式;
- 骨干架构使用了更为有效的残差网络,网络深度也更深;
- 多尺度特征使用的是FPN的思想;
- 锚点聚类成了9类。
具体详细的可以参考:
个人觉得在看一些好的论文,可以在一些大佬的基础上进行学习,并思考这些观点是否是正确的,这样有利于更快地更容易地学习经典论文里面的思想。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号