
SSD算法思想和结构详解
前言
目标检测近年来已经取得了很重要的进程,主流算法主要分成两个类型:
(1)Two-stage方法:如R-CNN系列算法,其主要思路就是通过Selective Search或者CNN网络产生一系列的稀疏矩阵的候选框,然后对这些候选框进行分类和回归,two-stage的方法优势在于准确率度高;
(2)One-stage方法:如YOLO、SSD,其主要思路就是均匀地在图片上不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类和回归,整个过程只需要一步,所以优势在于速度快,但是均匀密集采样的一个重要缺点就是训练比较困难,这主要是因为正样本和负样本极度不均衡,导致模型准确度比较低。
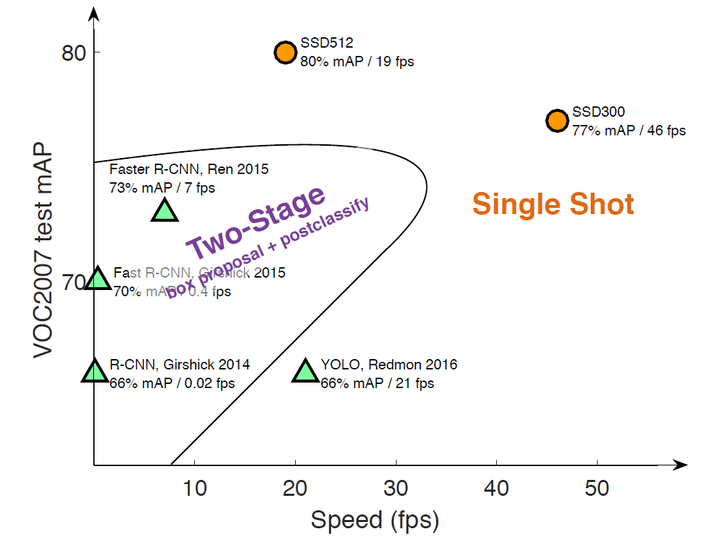
本文讲解的是SSD算法,其英文全名是Single Shot MultiBox Detector,名字取得不错,Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。对于Faster R-CNN,先通过CNN得到候选框,然后进行分类和回归,而YOLO和SSD可以一步完成检测,相比YOLO,SSD采用CNN来直接进行检测,而不是像YOLO那样采用全连接层后做检测。相对比于YOLO而言,还有其他两个特点地改变:
第一,SSD提取了不同尺度的特征图来做检测,大尺度特征图可以用来检测小物体,而小特征图用来检测大物体;
第二,SSD采用了不同尺度和长宽比的先验框,在faster r-cnn中称为Anchors。YOLO算法缺点是难以检测小物体,而且定位不准,但是对于这几点,SSD在一定程度上克服这些缺点。
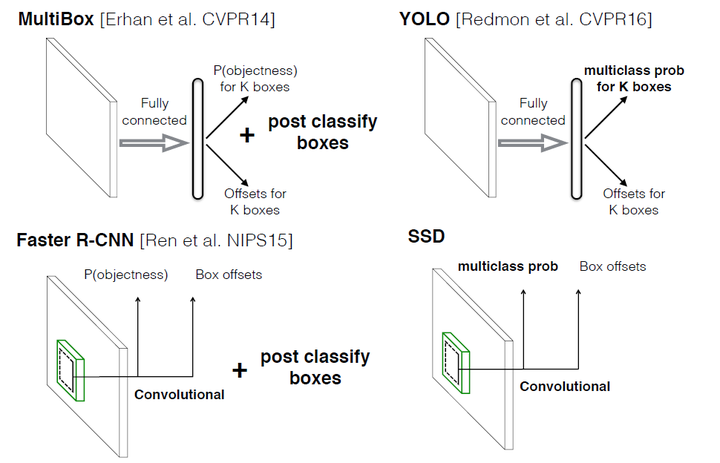
设计思想
目前复习下SSD模型,主要是为了帮助后面更多的网络模型的算法理解。SSD仅在输入图像上运行一个卷积网络并计算特征映射。作者在这个特征映射上运行一个3×3大小的卷积核来预测边界框和分类概率。SSD也使用类似于Faster-RCNN的各种宽高比的anchor boxes ,并学习偏移而不是学习box。为了处理这个尺度,SSD在多个卷积层之后预测边界框。 由于每个卷积层以不同的比例操作,因此能够检测各种比例的目标。
SSD的核心:
- 使用应用于要素图的小卷积滤波器来预测固定的默认边界框的类别得分和框偏移。
- 从不同尺度的特征图中快速检测不同尺度的准确度,并通过纵横比明确区分预测。
- 即使在低分辨率输入图像上,这些设计特征也可实现简单的端到端训练和高精度,从而进一步提高速度与精度之间的权衡。
- 实验包括对PASCAL VOC,COCO和ILSVRC评估的不同输入尺寸的模型进行定时和精度分析,并与一系列最新的最新方法进行比较。
核心设计理念
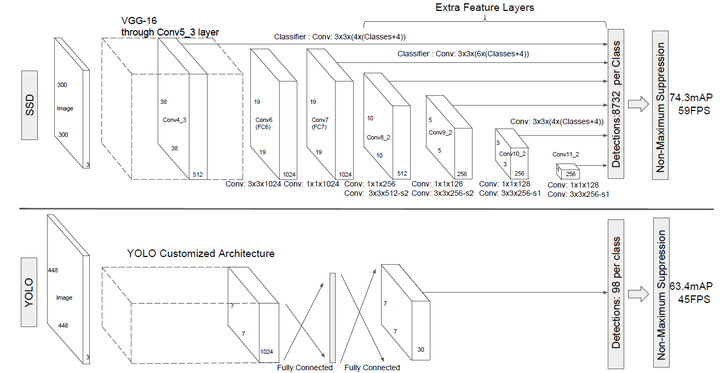
SSD和Yolo一样都是采用一个CNN网络来进行检测,但是SSD却采用了多尺度的特征图,其基本架构图如下:
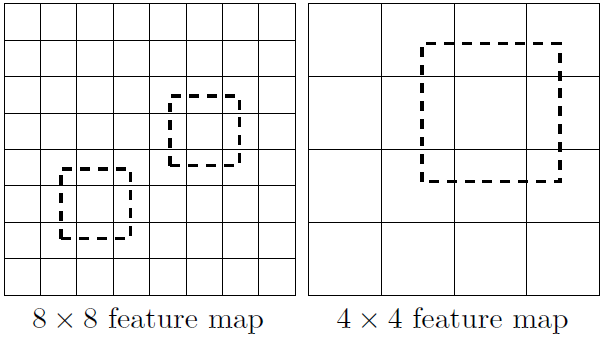
采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面逐渐采用stride=2的卷积或者pooling层来降低特征图大小。一个比较大的特征图和比较小的特征图都用来做检测,这样做的好处就是比较大的特征图用来检测相对比较小的的目标,而小的特征图负责用来检测大的物体,如图所示:(8x8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。)
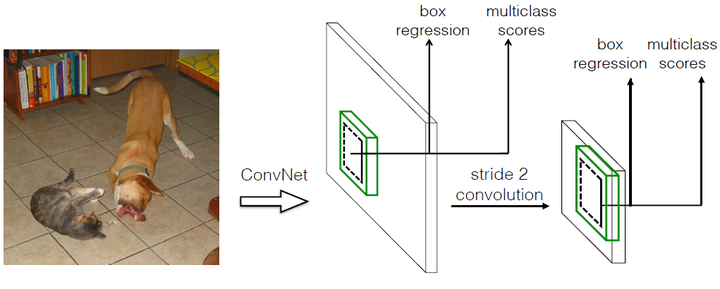
采用卷积做检测
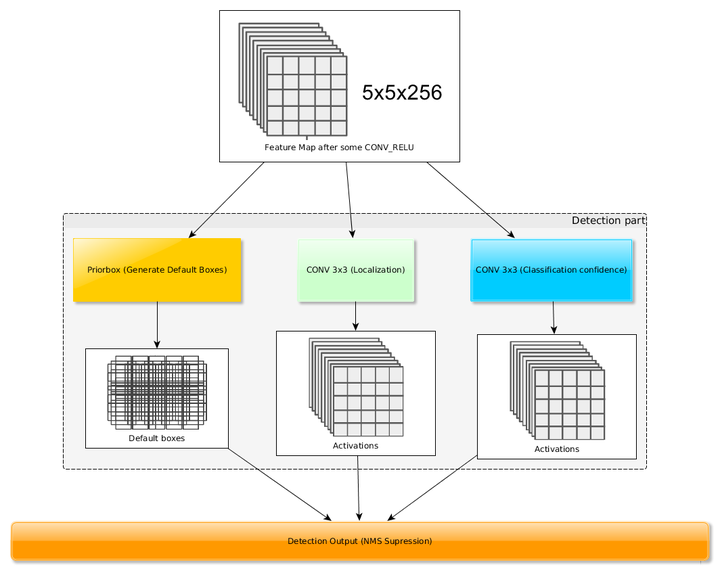
YOLO最后采用的是全连接层,SSD直接采用卷积对不同的特征图进行提取检测结果,对于形状为mxnxp的特征图,只需要采用3x3xp这样小的卷积核得到检测值。
设置先验框
在YOLO中,每个单元预测多个边界框,但是都是相对于这个单元本身而言,但是真实目标的形状时多变的,YOLO需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchors box的原理,每个单元设置尺度或者长宽比不同的先验框,预测的边界框都是以先验框为基准,在一定程度上减少了训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异。每个单元使用了4个不同的先验框。
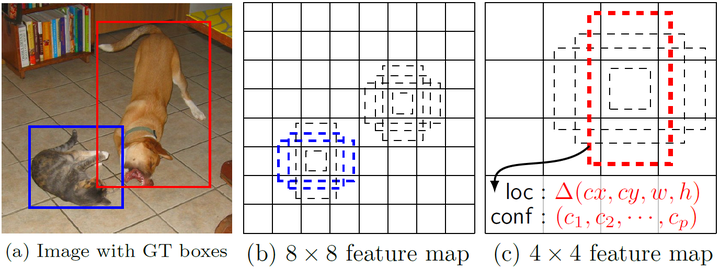
对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 个类别,SSD其实需要预测
个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说
个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有
个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值
,分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset)。先验框位置用
表示,其对应边界框用
表示,那么边界框的预测值
其实是
相对于
的转换值:
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值 中得到边界框的真实位置
:
然而,在SSD的Caffe源码实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式,当其为True时,表示variance被包含在预测值中,就是上面那种情况。但是如果是False(大部分采用这种方式,训练可能更容易),就需要手动设置超参数variance,用来对 的4个值进行放缩,此时边界框需要这样解码:
综上所述,对于一个大小 的特征图,共有
个单元,每个单元设置的先验框数目记为
,那么每个单元共需要
个预测值,所有的单元共需要
个预测值,由于SSD采用卷积做检测,所以就需要
个卷积核完成这个特征图的检测过程。
网络结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图5所示。上面是SSD模型,下面是Yolo模型,可以明显看到SSD利用了多尺度的特征图做检测。模型的输入图片大小是 300x300。
采用VGG16做基础模型,首先VGG16是在ILSVRC CLS-LOC数据集预训练。然后借鉴了DeepLab-LargeFOV,分别将VGG16的全连接层fc6和fc7转换成 卷积层 conv6和
卷积层conv7,同时将池化层pool5由原来的stride=2的
变成stride=1的
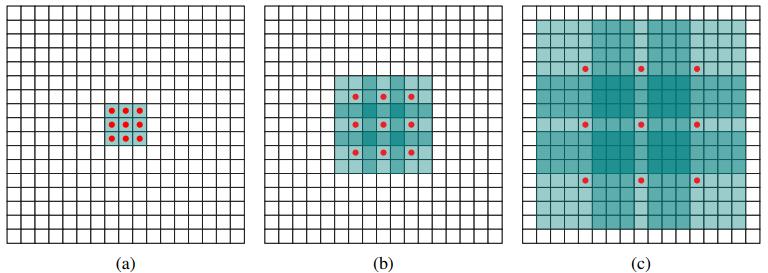
(猜想是不想reduce特征图大小),为了配合这种变化,采用了一种Atrous Algorithm,其实就是conv6采用扩展卷积或带孔卷积(Dilation Conv),其在不增加参数与模型复杂度的条件下指数级扩大卷积的视野,其使用扩张率(dilation rate)参数,来表示扩张的大小,如下图6所示,(a)是普通的
卷积,其视野就是
,(b)是扩张率为2,此时视野变成
,(c)扩张率为4时,视野扩大为
,但是视野的特征更稀疏了。Conv6采用
大小但dilation rate=6的扩展卷积。
然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 ,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层,以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma。
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是 ,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
其中 指的特征图个数,但却是
,因为第一层(Conv4_3层)是单独设置的,
表示先验框大小相对于图片的比例,而
和
表示比例的最小值与最大值,paper里面取0.2和0.9。对于第一个特征图,其先验框的尺度比例一般设置为
,那么尺度为
。对于后面的特征图,先验框尺度按照上面公式线性增加,但是先将尺度比例先扩大100倍,此时增长步长为
,这样各个特征图的
为
,将这些比例除以100,然后再乘以图片大小,可以得到各个特征图的尺度为
,这种计算方式是参考SSD的Caffe源码。综上,可以得到各个特征图的先验框尺度
。对于长宽比,一般选取
,对于特定的长宽比,按如下公式计算先验框的宽度与高度(后面的
均指的是先验框实际尺度,而不是尺度比例):
默认情况下,每个特征图会有一个 且尺度为
的先验框,除此之外,还会设置一个尺度为
且
的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。注意最后一个特征图需要参考一个虚拟
来计算
。因此,每个特征图一共有
个先验框
,但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为
的先验框。每个单元的先验框的中心点分布在各个单元的中心,即 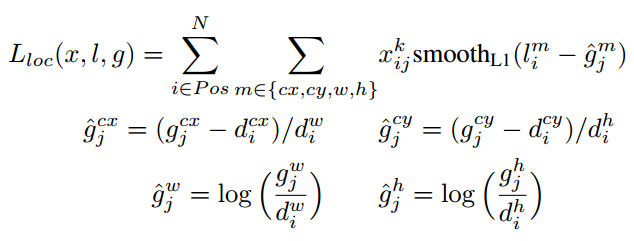
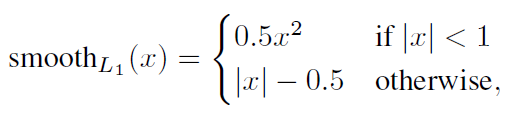
由于 的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的
进行编码得到
,因为预测值
也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
对于置信度误差,其采用softmax loss:
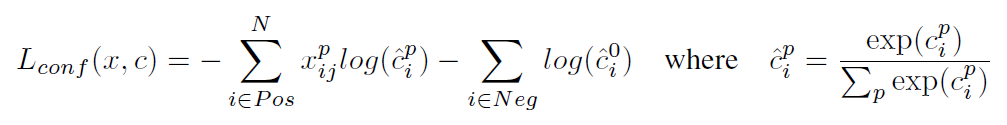
权重系数 通过交叉验证设置为1。
数据扩增
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如下图所示:


预测过程
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
性能评估
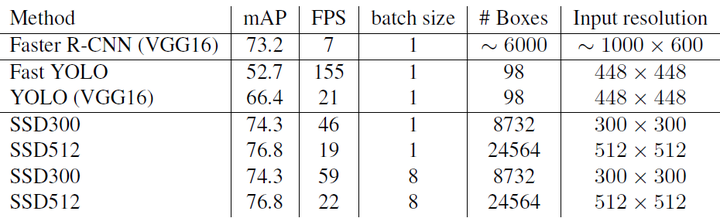
SSD在VOC2007,VOC2012及COCO数据集上的性能,如表1所示。相比之下,SSD512的性能会更好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号