


从零开始的 CPT (Continual Pre-Training): 摆脱复杂的训练框架
由于要解决一些业务问题,需要将领域知识喂给大模型。之前只做过简单的 finetuning(在 GLM 的框架上跑了一些 lora,数据量也不大),但是现在要将整个细分工业领域的相关数据都收集起来训练,规模上比之前半手动构造的微调数据集要大了很多,调研了一圈,更适合在 pre-train 阶段去做训练。
尝试使用训练框架:
- LLaMA Factory
是的,大名鼎鼎的 LLaMA Factory 不仅能 finetune,还能做 pre-train 阶段的训练。这个还是阿里的朋友告知才知道的... - GPT-NeoX
高性能训练框架。人家 Readme 中就提醒了,心里没点数别来用我:
If you are not looking to train models with billions of parameters from scratch, this is likely the wrong library to use.
- Pai-Megatron-Patch
跟 GPT-NeoX 一样是基于Megatron的训练框架,不过感觉阿里除了 antd 就没啥好用的开源项目...
说实话,这些框架的使用配置还是有些复杂(对于我这样的 pre-train 菜鸟来说),光是看文档就能把自己绕进去。
当然 LLaMA Factory 的使用还是比较傻瓜式的,毕竟是有 UI 操作界面的,点点点就能把最终运行的 command line 拼出来,就是它在产品的设计上完全是为了 finetune 而生的,感觉完全没有考虑 pre-train 这个 feature。比如 stage 选项中,pre-train 是排在最下面的;我明明选的是 pre-train,无论是训练开始前的命令行预览,还是训练的结果保存路径,都包含了 lora 是怎么回事?一头雾水,文档也不清楚。
那有没有可能不使用这些高大上的训练框架呢?我只想简简单单验证一下技术可行性,那只能从 transformer 库入手了。
首先,初始化 model 和 tokenizer:
model_name = os.path.join(
"/home/ubuntu/ycd/pretrained_models", "Qwen2.5-Coder-0.5B-Instruct"
)
output_dir = os.path.join("models", "qwen2.5-coder")
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
加载数据并 token 化:
raw_datasets = load_dataset(data_files="/home/ubuntu/ycd/continual-pretrain-qwen2.5-coder/data")
def tokenize_function(example):
return tokenizer(example["text"], truncation=True, padding=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
配置训练参数,这里除了 output_dir 是必填项,其他都可以使用默认值,不过数据集中的 column 名称要指定一下 text,否则默认回去找 label 字段,找不到会报错。
training_args = TrainingArguments(
output_dir=output_dir,
label_names=["text"],
# num_train_epochs=3,
# per_device_train_batch_size=4,
# save_steps=10_000,
# save_total_limit=2
)
使用 Trainer 启动训练:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
tokenizer=tokenizer,
)
trainer.train()
简单验证一下推理效果,zero-shot 可以生成 AFSIM 脚本代码,说明已经学到了训练数据中的知识
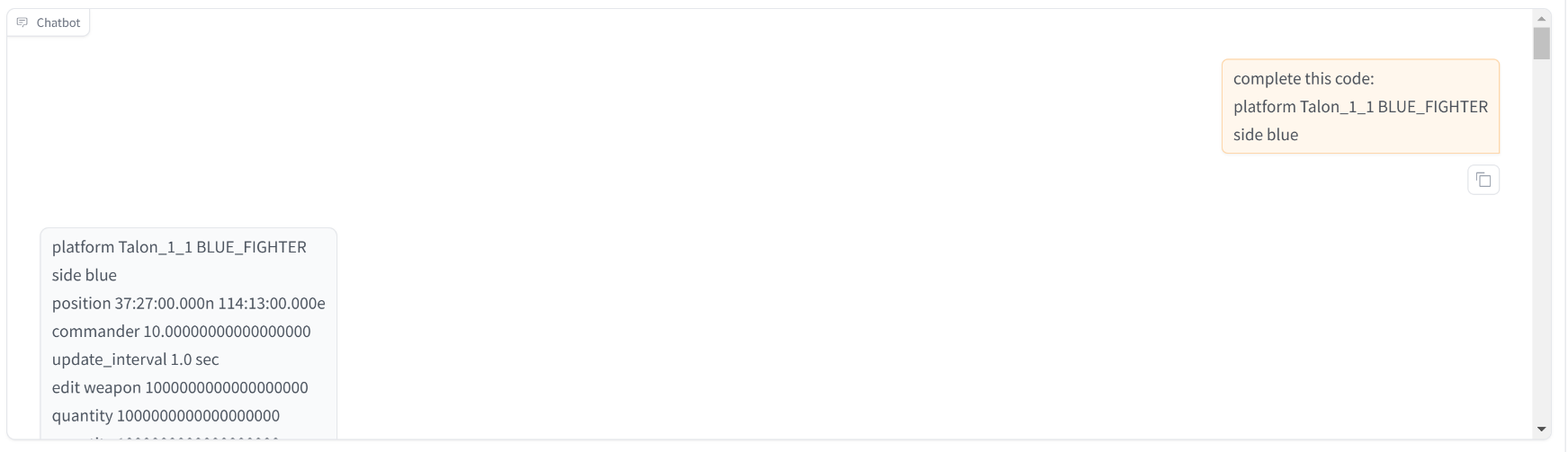
不过在 Qwen2.5-coder 0.5B 的模型上,会出现复读机的效果,用 3B 的模型倒是没有出现了。
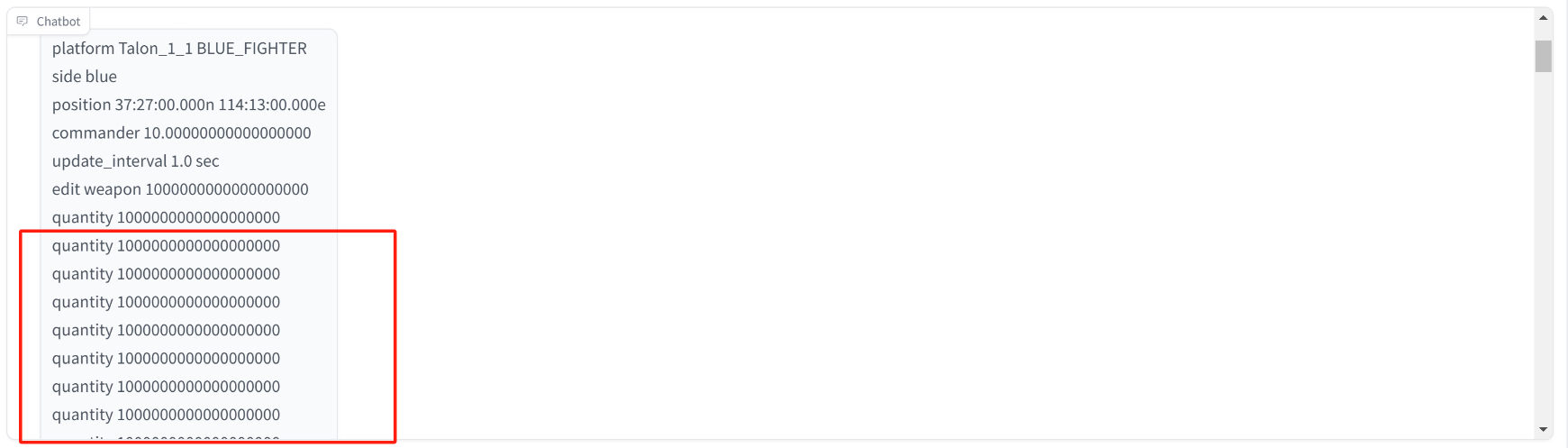
后续还要继续加强训练数据质量的处理。并且这次的训练中,数据主要是 AFSIM 的相关代码,需要增加 C++/C# 等不同类型的数据进行一定比例的配比。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY