分布式服务如何保证幂等性,幂等性如何设计
1)建唯一索引:唯一索引或唯一组合索引来防止新增数据存在脏数据 (当表存在唯一索引,并发 时新增异常时,再查询一次就可以了,数据应该已经存在了,返回结果即可)。
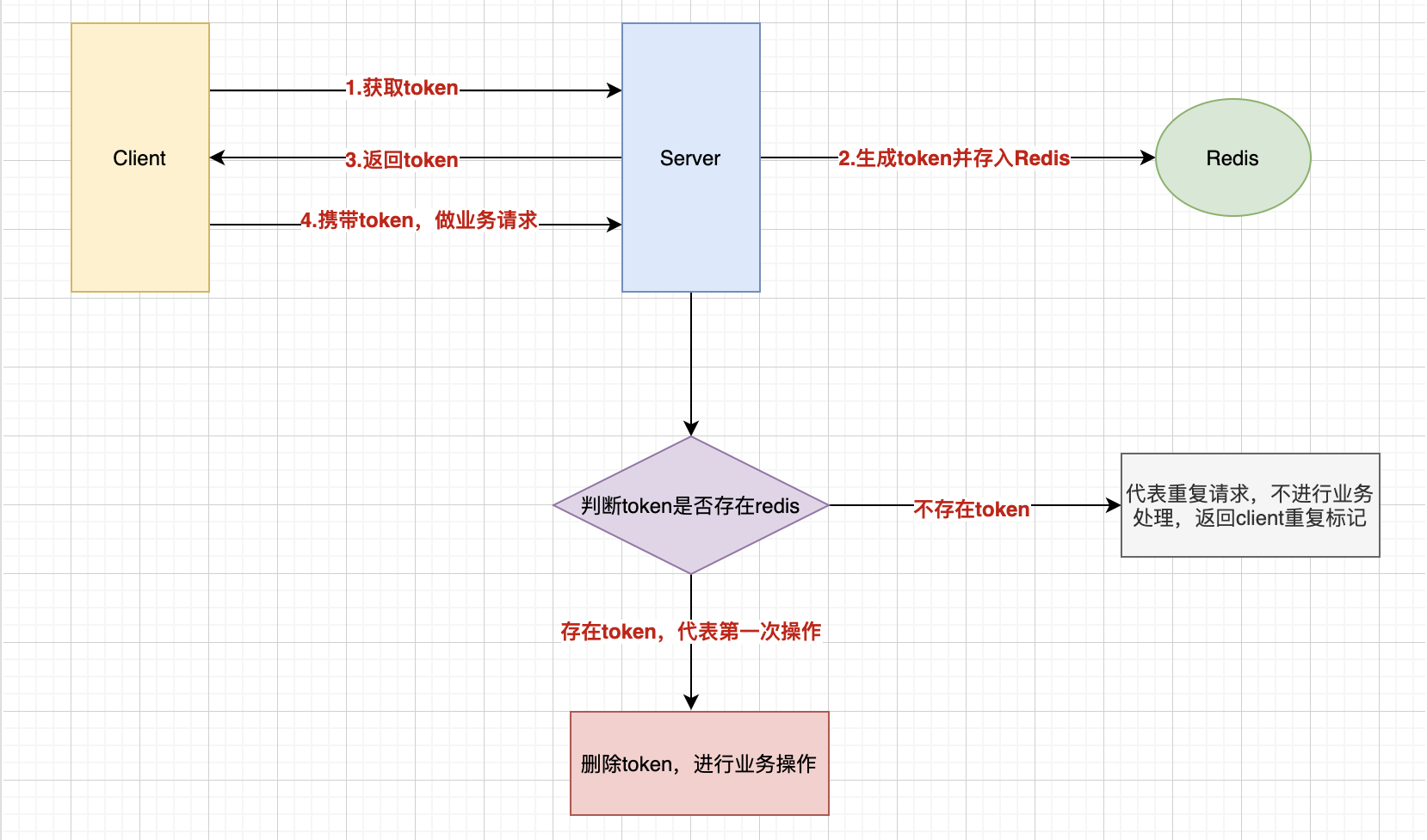
2)token机制:
token机制的幂等保障的主要流程就是:
服务端提供了发送token的接口。我们在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存到redis中。(微服务肯定是分布式了, 如果单机就适用jvm缓存)。
然后调用业务接口请求时,把token携带过去,一般放在请求头部。
服务器判断token是否存在redis中,存在表示第一次请求,这时把redis中的token删除,继续执行业务。
如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行。
缺点:业务请求每次请求,都会有额外的请求(一次获取token请求、判断token是否存在的业务)。其实真实的生产环境中,1万请求也许只会存在10个左右的请求会发生重试,为了这10个请求,我们让9990个请求都发生了额外的请求。(当然redis性能很好,耗时不会太明显)
注意:由于重复点击或者网络重发,或者nginx重发等情况会导致数据被重复提交。前端 在数据提交前要向后端服务的申请token,token放到 Redis 或 JVM 内存,token有效时间。提交后 后台校验token,同时删除token,生成新的token返回。redis要用删除操作来判断token,删除成 功代表token校验通过,如果用select+delete来校验token,存在并发问题,不建议使用。
3)悲观锁 悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用(另外还要考 虑id是否为主键,如果id不是主键或者不是 InnoDB 存储引擎,那么就会出现锁全表)。
4)乐观锁,给数据库表增加一个version字段,可以通过这个字段来判断是否已经被修改了
5)分布式锁,比如 Redis 、 Zookeeper 的分布式锁。单号为key,然后给Key设置有效期(防止支 付失败后,锁一直不释放),来一个请求使用订单号生成一把锁,业务代码执行完成后再释放锁。
分布式锁实现幂等性的逻辑是,在每次执行方法之前判断,是否可以获取到分布式锁,如果可以,则表示为第一次执行方法,否则直接舍弃请求即可。需要注意的是分布式锁的key必须为业务的唯一标识,通常适用redis或者zookeeper来实现分布式锁
如果是分布是系统,构建唯一索引比较困难,例如唯一性的字段没法确定,这时候可以引入分布式锁,通过第三方的系统,在业务系统插入数据或者更新数据,获取分布式锁,然后做操作,之后释放锁,这样其实是把多线程并发的锁的思路,引入多多个系统,也就是分布式系统中得解决思路;
目前主要有几种方式实现分布式锁:
5.1 redis setNx命令
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
优点:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
5.2 数据库
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
优点:实现简单
缺点:使用基于数据库的这种实现方式很简单,但是对于分布式锁应该具备的条件来说,它有一些问题需要解决及优化:
因为是基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以,数据库需要双机部署、数据同步、主备切换;
不具备可重入的特性,因为同一个线程在释放锁之前,行数据一直存在,无法再次成功插入数据,所以,需要在表中新增一列,用于记录当前获取到锁的机器和线程信息,在再次获取锁的时 候,先查询表中机器和线程信息是否和当前机器和线程相同,若相同则直接获取锁;
没有锁失效机制,因为有可能出现成功插入数据后,服务器宕机了,对应的数据没有被删除,当服务恢复后一直获取不到锁,所以,需要在表中新增一列,用于记录失效时间,并且需要有定时任务清除这些失效的数据;
不具备阻塞锁特性,获取不到锁直接返回失败,所以需要优化获取逻辑,循环多次去获取。
在实施的过程中会遇到各种不同的问题,为了解决这些问题,实现方式将会越来越复杂;依赖数据库需要一定的资源开销,性能问题需要考虑。
5.3 基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
(1)创建一个目录mylock;
(2)线程A想获取锁就在mylock目录下创建临时顺序节点;
(3)获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
优点:具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。
缺点:因为需要频繁的创建和删除节点,性能上不如Redis方式。
6)多版本控制
这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号,来做幂等
在实现时可以如下
7)状态机控制
在设计单据相关的业务,或者是任务相关的业务,肯定会涉及到状态机,就是业务单据上面有个状态,状态在不同的情况下会发生变更,一般情况下存在有限状态机,这时候,如果状态机已经处于下一个状态,这时候来了一个上一个状态的变更,理论上是不能够变更的,这样的话,保证了有限状态机的幂等。
很多业务表,都是有状态的,比如转账流水表,就会有0-待处理,1-处理中、2-成功、3-失败状态。转账流水更新的时候,都会涉及流水状态更新,即涉及状态机 (即状态变更图)。
状态机是怎么实现幂等的呢?
第1次请求来时,如流水号是 666,该流水的状态是处理中,值是 1,要更新为2-成功的状态,所以该update语句可以正常更新数据,sql执行结果的影响行数是1,流水状态最后变成了2。
第2请求也过来了,如果它的流水号还是 666,因为该流水状态已经2-成功的状态了,所以不会再处理业务逻辑,接口直接返回。
示例: 对于不少业务是有一个业务流转状态的,每一个状态都有前置状态和后置状态,以及最后的结束状态。例如流程的待审批,审批中,驳回,从新发起,审批经过,审批拒绝。订单的待提交,待支付,已支付,取消。
以订单为例,已支付的状态的前置状态只能是待支付,而取消状态的前置状态只能是待支付,经过这种状态机的流转就能够控制请求的幂等。假设当前状态是已支付,这时候若是支付接口又 接收到了支付请求,则会抛异常或拒绝这次处理。
状态机控制这种方法适合在有状态机流转的情况下,比如就会订单的创建和付款,订单的付款肯定是在之前,这时我们可以通过在设计状态字段时,使用int类型,并且通过值类型的大小来做幂等,比如订单的创建为0,付款成功为100。付款失败为99
在做状态机更新时,我们就这可以这样控制:
update `order` set status=#{status} where id=#{id} and status<#{status}
8)全局唯一ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、Redis等。如果存在则表示该方法已经执行。使用全局唯一ID是一个通用方案,可以支持插入、更新、删除业务操作。
结合redis的incr自增实现全局唯一ID,是一个常用的方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号