索引原理及SQL优化思路
索引是一种数据库结构,能够就数据库中的某列或某几列提供快速查询,而不用检索整个表格。建立索引时,oracle会首先对全表进行搜索,然后把要建立索引的字段排序,并构建索引条目(包含字段值和该字段在原表中的地址值rowid),把索引条目存储到索引段中。
索引类型
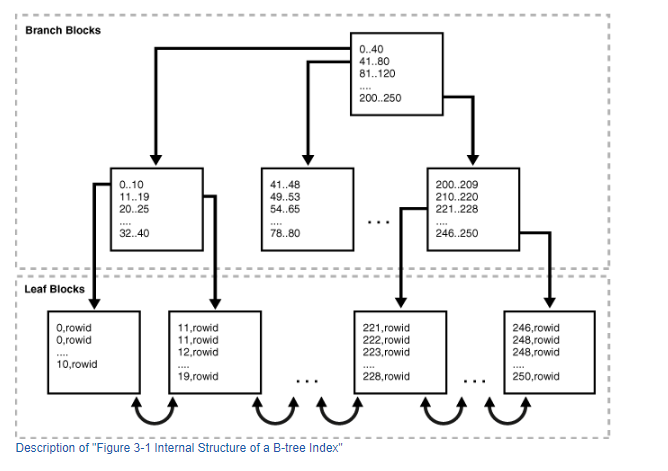
B-Tree索引(ORACLE默认)
- 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
- 分支节点(Branch node):最小的键值前缀(minimum key prefix),用于在(本块的)两个键值之间做出分支选择,指向包含所查找键值的子块(child block)的指针。
- 叶子节点(Leaf node):数据行的键值(key value)、键值对应数据行的 ROWID。
注意:
- 在Oracle中null被定义为无限大,故在索引不会存有与null值对应的条目。如果不加其他限制条件的对表进行is null扫描,将会是全表扫描;如果是is not null扫描将会是带索引扫描
- 不在低基数列上建立单列索引,例如“性别”
- 通过索引查询数据,行数一般不要超过全表的20%,否则采用全表扫描方式更合适
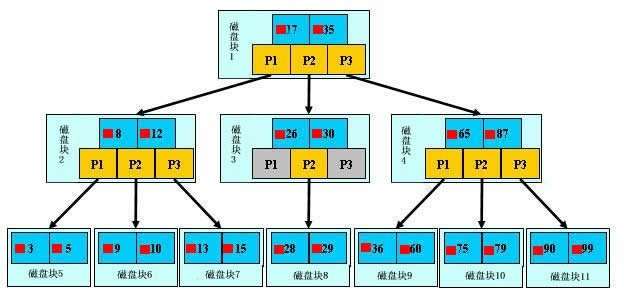
复合索引
位图索引
位图索引是从oracle 7.3版本开始引入的。位图索引是这样一种结构,其中用一个索引键条目存储指向多行的指针,这与B*树结构不同,在b*树结构中,索引键和表中的行存在着对应关系。在位图索引中,可能只有很少的索引条目,每个索引条目指向多行,而在传统的B*树中,一个索引条目就指向一行。
如下表,由三列组成,分别是姓名、性别和婚姻状况,其中性别只有男和女两项,婚姻状况由已婚、未婚、离婚这三项,该表共有100w个记录。现在有这样的查询:select * from table where Gender=‘男’ and Marital=“未婚”;
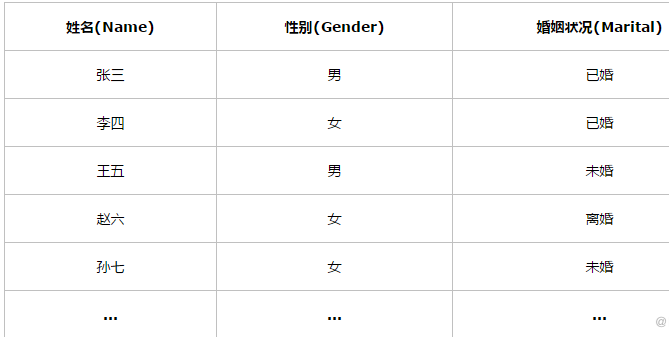
1)不使用索引
不使用索引时,数据库只能一行行扫描所有记录,然后判断该记录是否满足查询条件。
2)B树索引
对于性别,可取值的范围只有'男','女',并且男和女可能各站该表的50%的数据,这时添加B树索引还是需要取出一半的数据, 因此完全没有必要。相反,如果某个字段的取值范围很广,几乎没有重复,比如身份证号,此时使用B树索引较为合适。事实上,当取出的行数据占用表中大部分(超过20%)的数据时,即使添加了B树索引,数据库如oracle、mysql也不会使用B树索引,很有可能还是一行行全部扫描。
位图索引原理:
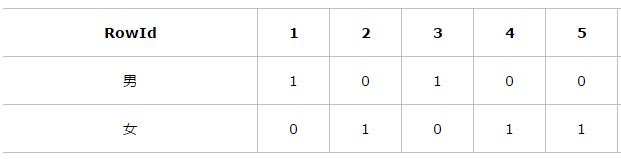
如果在性别列上建立了位图索引,对于性别这个列,针对每行的rowid(rowid可以理解为每行的物理位置),位图索引形成两个向量,男向量为10100...,向量的每一位表示该行是否是男,如果是则位1,否为0,同理,女向量位01011,(可以理解为给每行数据的性别列中为产生两个向量分别为男向量和女向量:男向量中 值为男:用1表示,值不是男用0表示,同理女向量中 值为女:用1表示,值不是女:用0表示)
如果在婚姻状况列上建立了位图索引 对于婚姻状况这一列,位图索引生成三个向量,已婚为11000...,未婚为00100...,离婚为00010...。
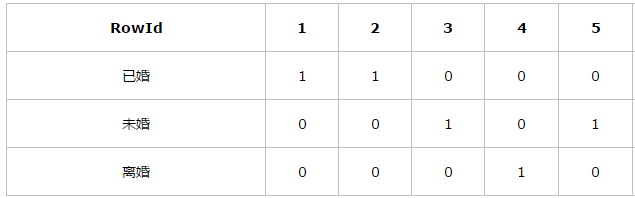
位图索引检索数据的过程:
当我们使用查询语句“select * from table where Gender=‘男’ and Marital=“未婚”;”的时候 首先取出男向量10100...,然后取出未婚向量00100...,将两个向量做and操作,这时生成新向量00100...,可以发现rowid=3的and之后的结果为1,表示该表的rowid=3的这行数据就是我们需要查询的结果(如下“and的结果”为1的就是需要查询的结果),然后根据rowid找到需要的数据
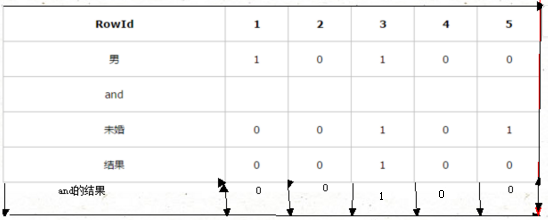
HASH索引
使用HASH索引必须要使用HASH集群。建立一个集群或HASH集群的同时,也就定义了一个集群键。这个键告诉Oracle如何在集群上存储表。在存储数据时,所有与这个集群键相关的行都被存储在一个数据库块上。如果数据都存储在同一个数据库块上,并且将HASH索引作为WHERE子句中的确切匹配,Oracle就可以通过执行一个HASH函数和I/O来访问数据。Oracle可以快速使用该值,基于HASH函数确定行的物理存储位置。
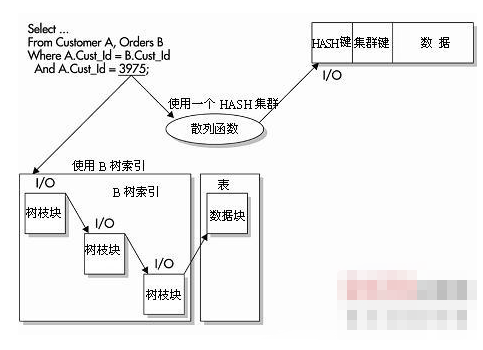
Oracle 执行计划
什么是Oracle执行计划
执行计划是一条查询语句在Oracle中执行过程或者访问路径的描述.
查看Oracle执行计划
1.执行计划常用的列字段解释
基数:返回的结果集行数
字节:执行该步骤后返回的字节数
耗费(cust),CPU耗费:Oracle估计的该步骤的执行成本,用于说明SQL执行的代价,理论上越小越好.
看懂Oracle执行计划
1) plSql : Fn+F5 通过tree查看

2)plSql : Fn+F5通过text查看

3)navicat查看
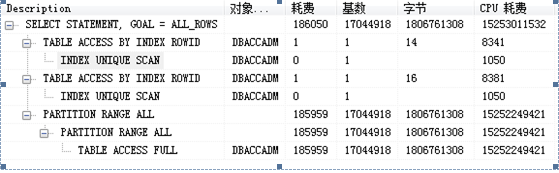
注:根据缩进来判断,缩进最多的最先执行(缩进相同时,最上面的最先执行)
表的访问方式
-
TABLE ACCESS FULL(全表扫描)
-
TABLE ACCESS BY ROWID(通过rowid的表存取)
-
TABLE ACCESS BY INDEX SCAN(索引扫描)
ABLE ACCESS FULL(全表扫描)
Oracle会读取表中的所有行,并检查是否满足where语句中条件;
使用建议:数据量太大的表不建议全表扫描 一般5000行以下可以使用全表扫描。
TABLE ACCESS FULL(全表扫描)
Oracle会读取表中的所有行,并检查是否满足where语句中条件;
使用建议:数据量太大的表不建议全表扫描
TABLE ACCESS BY ROWID(通过ROWID的表存取)
ROWID的解释:oracle会自动加在表的每一行的最后一列伪列,表中并不会物理存储ROWID的值,一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
TABLE ACCESS BY INDEX SCAN(索引扫描)
在索引块中即存储每个索引的键值,也存储具有该键值所对的ROWID.
索引的扫描分两步:首先是找到索引所对的ROWID,其次通过ROWID读取改行数据
索引扫描又分五种:
- INDEX UNIQUE SCAN(索引唯一扫描)
- INDEX RANGE SCAN(索引范围扫描)
- INDEX FULL SCAN(索引全扫描)
- INDEX FAST FULL SCAN(索引快速扫描)
- INDEX SKIP SCAN(索引跳跃扫描)
(a).INDEX UNIQUE SCAN(索引唯一扫描):
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录,主要针对该字段为主键或者唯一;
(b). INDEX RANGE SCAN(索引范围扫描)
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
(c). INDEX FULL SCAN(索引全扫描)
- 进行全索引扫描时,查询出的数据都必须从索引中可以直接得到
(d). INDEX FAST FULL SCAN(索引快速扫描)
- 扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
(e). INDEX SKIP SCAN(索引跳跃扫描):
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号