新闻文字分词-词云图展示
主要流程是将所给文件内容导入数据库,并对类别进行统计。然后对文本主要内容进行分词及统计次数,继而以词云图进行展示。
我这里用到了 jieba 分词,首先应该准备jieba的环境。
1.起始数据如下:
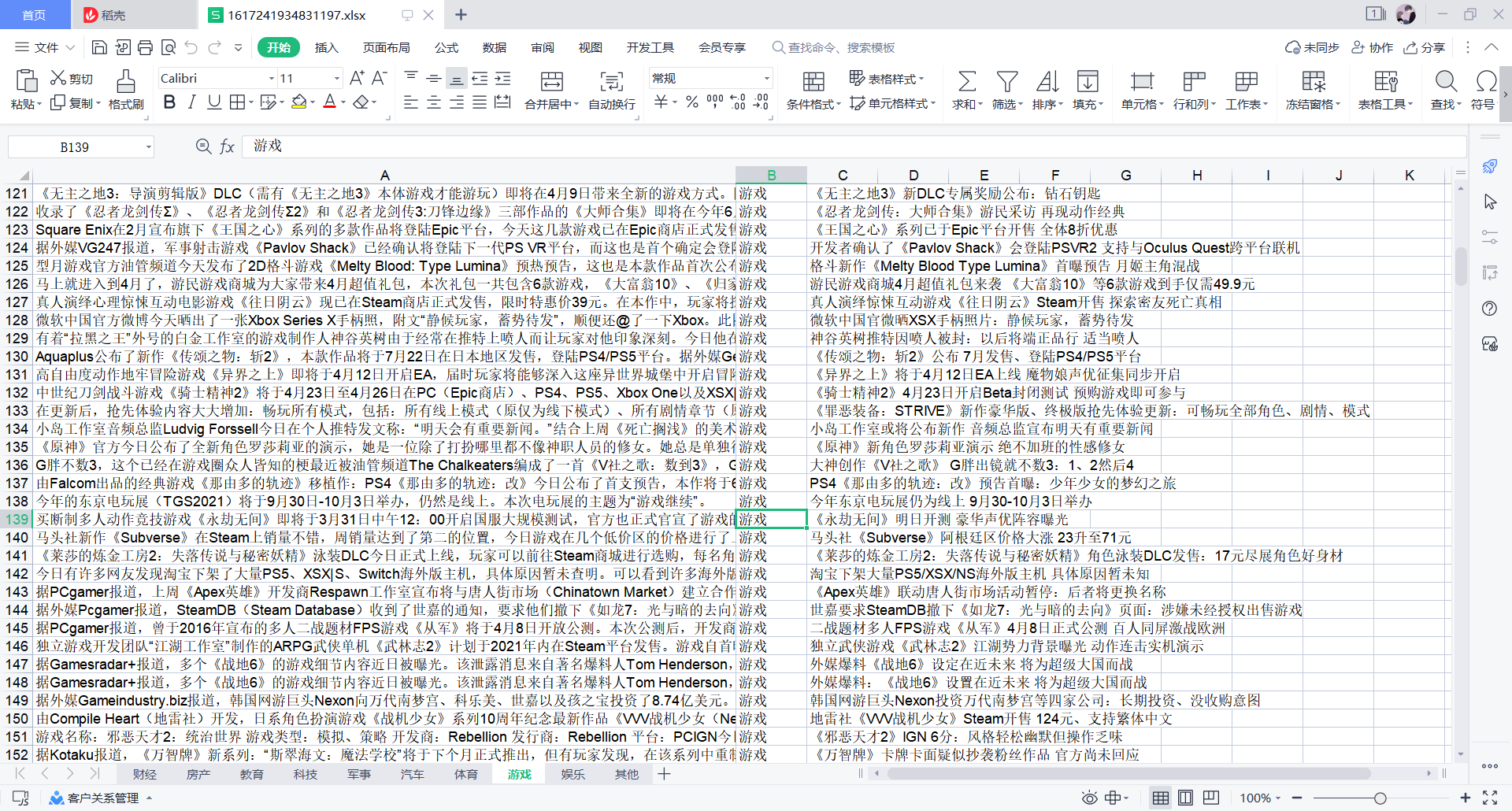
2.导入数据库中:

2.对类别进行统计并进行可视化展示(这里用到的是layui的模板)
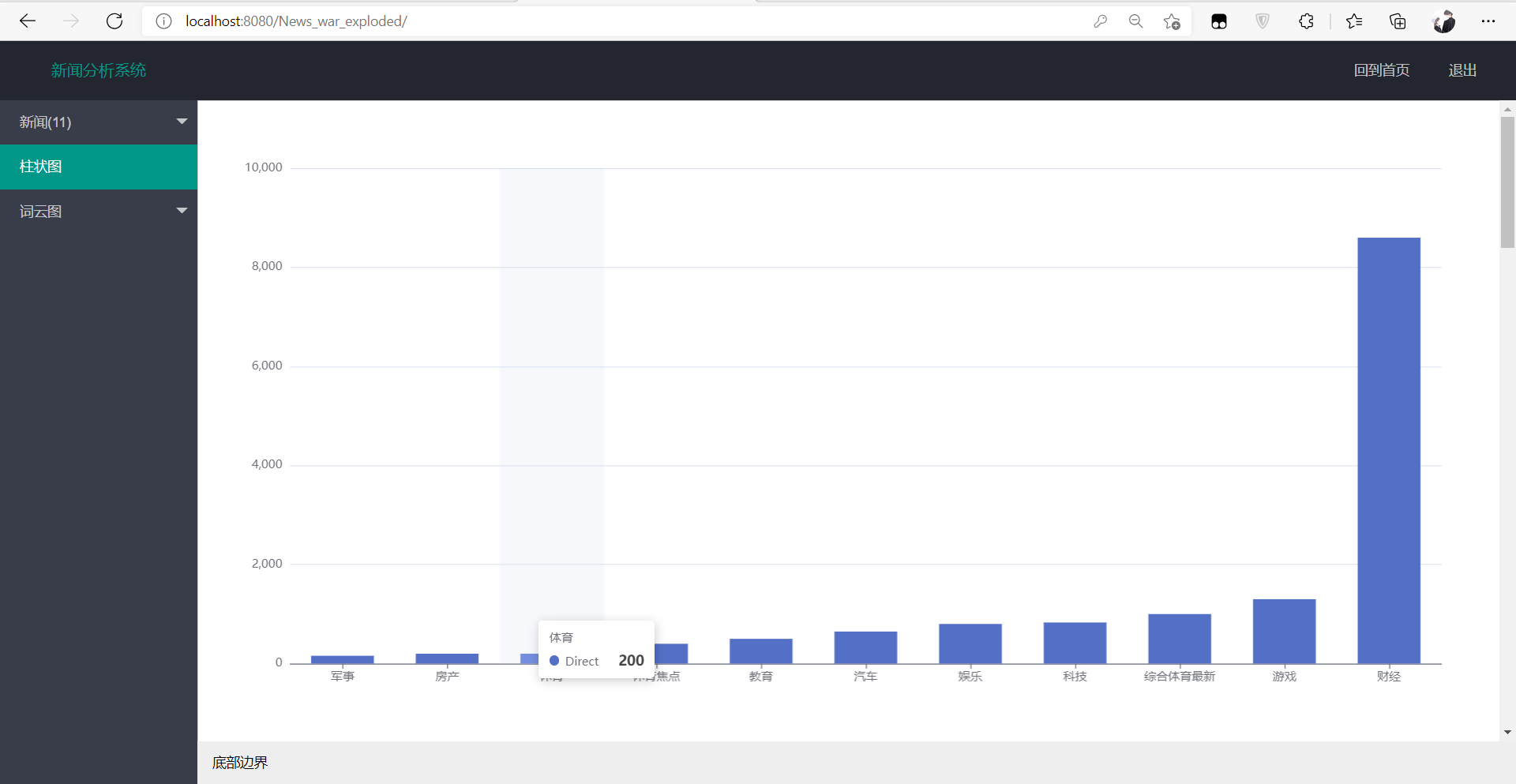
3.接下来采用jieba对文件文本进行分词并统计次数


import jieba import re from collections import Counter import pandas as pd import numpy as np cut_words="" for line in open('yule.txt', encoding='utf-8'): line.strip('\n') line = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”]", "", line) seg_list=jieba.cut(line,cut_all=False) cut_words+=(" ".join(seg_list)) all_words=cut_words.split() print(all_words) c=Counter() for x in all_words: if len(x)>1 and x != '\r\n': c[x] += 1 print('\n词频统计结果:') for (k,v) in c.most_common(100):# 输出词频最高的前两个词 print("%s:%d"%(k,v)) #for (k,v) in c.most_common(1000):# 输出词频最高的前两个词 # df = pd.DataFrame([{ k, # v}]) # df.to_csv('2.txt', mode='a', sep=',', header=True, index=True)
然后可以直接将分好的词和次数存入数据库(利用pymysql)
# 导入pymysql模块 import pymysql # 连接database conn = pymysql.connect(host="localhost", user="root",password="root1",database="test",charset="utf8") for (k,v) in c.most_common(10000):# 输出词频最高的前两个词 # 得到一个可以执行SQL语句的光标对象 cursor = conn.cursor() sql = "INSERT INTO yule(val, count) VALUES (%s, %s);" # 执行SQL语句 cursor.execute(sql, [k, v]) # 提交事务 conn.commit() cursor.close() conn.close()
词云图效果:
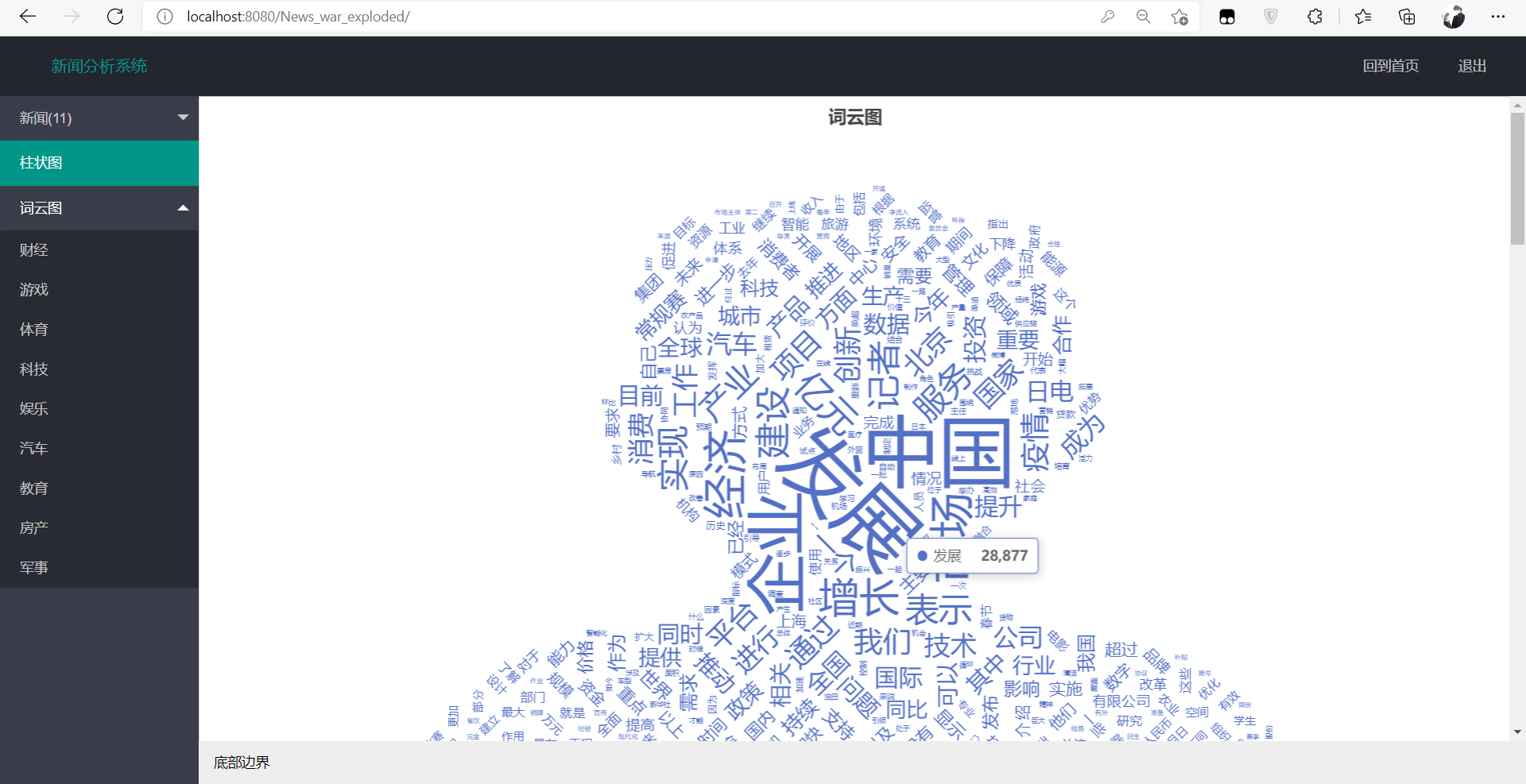
还可以对各个类别进行词云图展示,例如房产的词云图:
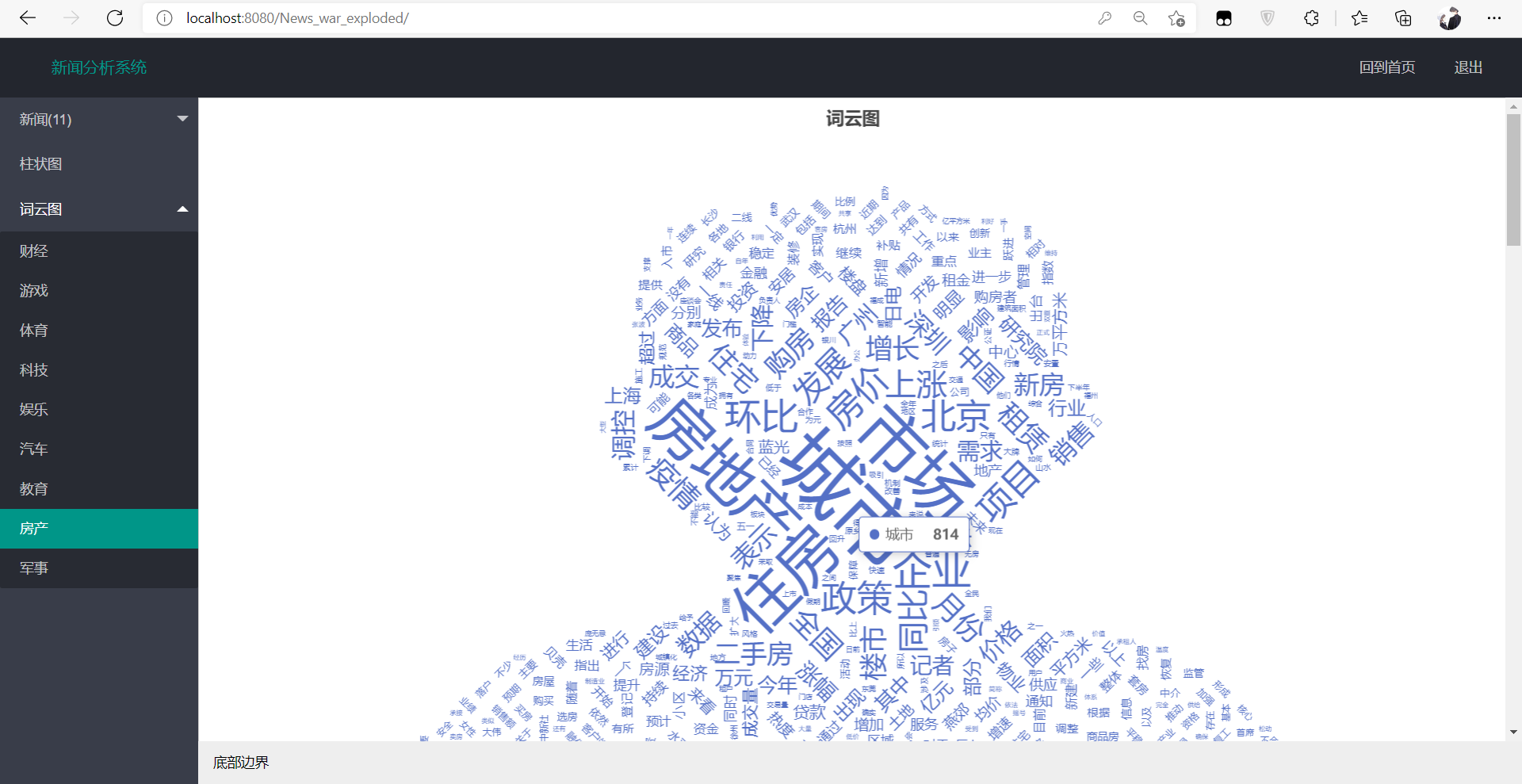
至此,此项目就完成了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号