
mysql(2)—— 由笛卡尔积现象分析数据库表的连接
首先,先简单解释一下笛卡尔积。
现在,我们有两个集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的结果集就可以分别表示为以下这种形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
以上A×B和B×A的结果就可以叫做两个集合相乘的‘笛卡尔积’。
从以上的数据分析我们可以得出以下两点结论:
1,两个集合相乘,不满足交换率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数;
数据库表连接数据行匹配时所遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
比如现在数据库中有两张表,student表和 student_subject表,如下所示:
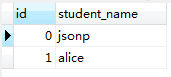
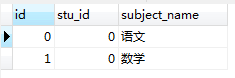
我们执行以下的sql语句,只是纯粹的进行表连接。
SELECT * from student JOIN student_subject; SELECT * from student_subject JOIN student;
看一下执行结果:
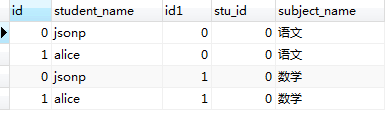
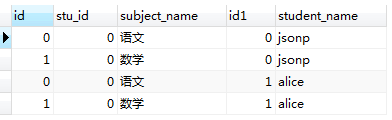
表1.0 表1.1
从执行结果上来看,结果符合我们以上提出的两点结论(红线标注部分);
以第一条sql语句为例我们来看一下他的执行流程,
1,from语句把student表 和 student_subject表从数据库文件加载到内存中。
2,join语句相当于对两张表做了乘法运算,把student表中的每一行记录按照顺序和student_subject表中记录依次匹配。
3,匹配完成后,我们得到了一张有 (student中记录数 × student_subject表中记录数)条的临时表。 在内存中形成的临时表如表1.0所示。我们又把内存中表1.0所示的表称为‘笛卡尔积表’。
针对以上的理论,我们提出一个问题,难道表连接的时候都要先形成一张笛卡尔积表吗,如果两张表的数据量都比较大的话,那样就会占用很大的内存空间这显然是不合理的。所以,我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN。
因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用 FROM table1,table2 WHERE xxx 的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。
根据上一篇博客(http://www.cnblogs.com/cdf-opensource-007/p/6502556.html),及本篇博客的分析,我们可以总结出一条查询sql语句的执行流程。
From
ON
JOIN
WHERE
GROUP BY
SELECT
HAVING
ORDER BY
LIMIT
最后,针对两张数据库表连接的底层实现,我用java代码模拟了一下,感兴趣的可以看一下,能够帮助我们理解:
package com.opensource.util; import java.util.Arrays; public class DecareProduct { public static void main(String[] args) { //使用二维数组,模拟student表 String[][] student ={ {"0","jsonp"}, {"1","alice"} }; //使用二维数组,模拟student_subject表 String[][] student_subject2 ={ {"0","0","语文"}, {"1","0","数学"} }; //模拟 SELECT * from student JOIN student_subject; String[][] resultTowArray1 = getTwoDimensionArray(student,student_subject2); //模拟 SELECT * from student_subject JOIN student; String[][] resultTowArray2 = getTwoDimensionArray(student_subject2,student); int length1 = resultTowArray1.length; for (int i = 0; i <length1 ; i++) { System.out.println(Arrays.toString(resultTowArray1[i])); } System.err.println("-----------------------------------------------"); int length2 = resultTowArray2.length; for (int i = 0; i <length2 ; i++) { System.out.println(Arrays.toString(resultTowArray2[i])); } } /** * 模拟两张表连接的操作 * @param towArray1 * @param towArray2 * @return */ public static String[][] getTwoDimensionArray(String[][] towArray1,String[][] towArray2){ //获取二维数组的高(既该二维数组中有几个一维数组,用来指代数据库表中的记录数) int high1 = towArray1.length; int high2 = towArray2.length; //获取二维数组的宽度(既二位数组中,一维数组的长度,用来指代数据库表中的列) int wide1 = towArray1[0].length; int wide2 = towArray2[0].length; //计算出两个二维数组进行笛卡尔乘积运算后获得的结果集数组的高度和宽度,既笛卡尔积表的行数和列数 int resultHigh = high1 * high2; int resultWide = wide1 + wide2; //初始化结果集数组,既笛卡尔积表 String[][] resultArray = new String[resultHigh][resultWide]; //迭代变量 int index = 0; //先对第二二维数组遍历 for (int i = 0; i < high2; i++) { //拿出towArray2这个二维数组的元素 String[] tempArray = towArray2[i]; //循环嵌套,对第towArray1这个二维数组遍历 for (int j = 0; j < high1; j++) { //初始化一个长度为'resultWide'的数组,作为结果集数组的元素,既笛卡尔积表中的一行 String[] tempExtened = new String[resultWide]; //拿出towArray1这个二维数组的元素 String[] tempArray1 = towArray1[j]; //把tempArray1和tempArray两个数组的元素拷贝到结果集数组的元素中去。(这里用到了数组扩容) System.arraycopy(tempArray1, 0, tempExtened, 0, tempArray1.length); System.arraycopy(tempArray, 0, tempExtened, tempArray1.length, tempArray.length); //把tempExtened放入结果集数组中 resultArray[index] = tempExtened; //迭代加一 index++; } } return resultArray; } }
执行结果:

最后说一点,我们作为程序员,研究问题还是要仔细深入一点的。当你对原理了解的有够透彻,开发起来也就得心应手了,很多开发中的问题和疑惑也就迎刃而解了,而且在面对其他问题的时候也可做到触类旁通。当然在开发中没有太多的时间让你去研究原理,开发中要以实现功能为前提,可等项目上线的后,你有大把的时间或者空余的时间,你大可去刨根问底,深入的去研究一项技术,我觉得这对一名程序员的成长是很重要的事情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号