
第三次作业结对编程
一.Github项目地址和结对伙伴的作业地址:
github地址:https://github.com/wanyouyingli/WordCount.git
伙伴作业地址:https://www.cnblogs.com/wanyouyinli/p/10639724.html
二.结对的过程及psp表在伙伴作业给出
三.解题思路
问题需要我们处理长字符串,将单词统计起来,并且按照字典序顺序输出到文本,统计指定数量的单词和词频。
首先,为了解决保存问题,我选择了字典树这种数据结构用于维护所有单词,且在生成树之时就是按照字典序排列的。
其次,为了解决前n个单词及其词频的问题,选择了优先队列的数据结构维护前n大单词。
四.设计实现过程
首先需要字典树类,优先队列类,计算字符数量类,计算单词类,计算前n个单词及词频类;
字典树类为以字典序顺序维护所有单词,计算字符类在读入文件时统计,计算单词类需要先调用字典树类保存单词后读取单词数,计算前n个单词及词频类需要有限队列类维护前n个单词。
读入文件函数,写入文件函数,单词及词频结构体
单元测试:计算字符在读取字符时是否存在问题,计算单词类的数量,统计前n个单词及词频类的顺序
通过四次版本迭代更新,最终完成需求:
1.完成文件中的单词存储以及分析
2.将不同功能模块化
3.精简代码,相同代码模块化
4.加入根据cmd命令更改操作功能
五.代码规范或链接
我们选择了遵循谷歌的代码规范:具体要求
代码互审时发现队友在写统计前n个单词及词频时选择了复杂的算法:将所有单词按照词频-字典序排序后输出前n个,其复杂度高达O(mlog(m))。通过讨论给出采用优先队列维护前n个单词的解决方案,复杂度降为O(m).
六.性能分析
七.代码说明
单词结构体保存每个单词及其词频
public struct Word { public string word; public int cnt; public Word(string a, int b) { word = a; cnt = b; } }
字典树类
public class Trie { private static int SIZE = 100; public TrieNode root; public List<AnalyseTop10.Word> words = new List<AnalyseTop10.Word>(); //保存统计所有单词后的最终结果序列 private string pre_path = null; public class TrieNode //字典树结点 { public int num; public TrieNode[] son; public bool isEnd; public char val; public TrieNode() { num = 0; son = new TrieNode[SIZE]; isEnd = false; } } public Trie(string path) { if(pre_path != path) { root = new TrieNode(); string str = ReadFile.cal(path).Replace('\r', ' ').Replace('\n', ' '); string[] input = str.Split(' '); for (int i = 0; i < input.Length; ++i) { insert(input[i]); } Analyse(root); pre_path = path; } } public void insert(string str) //在树上插入一个单词 { if (str == null || str.Length < 4) return; //是否合法 TrieNode node = root; char[] word = str.ToCharArray(); int len = str.Length; for(int i = 0; i < len; ++i) { if (word[i] >= 'A' && word[i] <= 'Z') word[i] = (char)(word[i] - 'A' + 'a'); if (i <= 3 && !(word[i] >= 'a' && word[i] <= 'z')) return; int pos = word[i] - 33; if (node.son[pos] == null) { node.son[pos] = new TrieNode(); node.son[pos].val = word[i]; } node = node.son[pos]; } node.num++; node.isEnd = true; } char[] tmp = new char[100]; int tot = 0; public void Analyse(TrieNode node) //通过递归统计出所有单词 { if (node.isEnd) { words.Add(new AnalyseTop10.Word(new string(tmp, 0, tot), node.num)); } for (int i = 0; i < Trie.SIZE; ++i) { if (node.son[i] != null) { tmp[tot++] = node.son[i].val; Analyse(node.son[i]); tot--; } } } }
读入文件类
public static class ReadFile { public static string cal(string str) { string output = null; try { StreamReader sr = new StreamReader(str, Encoding.Default); String line; while ((line = sr.ReadLine()) != null) { output += line; } } catch { Console.WriteLine("文件不存在!"); //判断文件是否存在 } return output; } }
主函数
static void Main(string[] args) { if (args.Count() != 0) { Trie trie = null; int init_output_num = 10, words_len = -1; string output_path = @".\output.txt", path = null; for(int i = 0; i < args.Length; ++i) { //处理cmd命令的参数 if (args[i] == "-i") path = args[++i]; else if (args[i] == "-n") init_output_num = int.Parse(args[++i]); else if (args[i] == "-o") output_path = args[++i]; else if (args[i] == "-m") words_len = int.Parse(args[++i]); } if(path == null || File.Exists(path) == false) { Console.WriteLine("文件不存在!"); return; } trie = new Trie(path); Analyse analysetop10 = new Analyse(); CountWord.CountWord countWord = new CountWord.CountWord(); CountCharacter.CountChar countChar = new CountCharacter.CountChar(); Console.WriteLine("characters: " + countChar.Cnt(path)); Console.WriteLine("words: " + countWord.cnt(trie.words, output_path)); analysetop10.top10(trie.words, init_output_num); foreach(AnalyseTop10.Word word in trie.words) { Console.WriteLine("<{0}>: {1}", word.word, word.cnt); } } }
优先队列类(原理:小顶堆)
public class Priority_Queue<T> { IComparer<T> comparer; T[] heap; public int Count { get; private set; } public Priority_Queue() { } public Priority_Queue(IComparer<T> comparer, int capcity) { this.comparer = (comparer == null) ? Comparer<T>.Default : comparer; this.heap = new T[capcity]; } public void Push(T v) { if (Count >= heap.Length) Array.Resize(ref heap, Count * 2); heap[Count] = v; SiftUp(Count++); } public T Pop() { var v = Top(); heap[0] = heap[--Count]; if (Count > 0) SiftDown(0); return v; } public T Top() { if (Count > 0) return heap[0]; throw new InvalidOperationException("优先队列为空!"); } void SiftUp(int n) { var v = heap[n]; for (var n2 = n / 2; n > 0 && comparer.Compare(v, heap[n2]) > 0; n = n2, n2 /= 2) heap[n] = heap[n2]; heap[n] = v; } void SiftDown(int n) { var v = heap[n]; for (var n2 = n * 2; n2 < Count; n = n2, n2 *= 2) { if (n2 + 1 < Count && comparer.Compare(heap[n2 + 1], heap[n2]) > 0) n2++; if (comparer.Compare(v, heap[n2]) >= 0) break; heap[n] = heap[n2]; } heap[n] = v; } }
统计单词及词频
public class Analyse { public List<Word> top10(List<Word> words, int size) { Priority_Queue<Word> Q = new Priority_Queue<Word>(Com, size); List<Word> tmp = new List<Word>(); for (int i = 0; i < words.Count; ++i) { if (Q.Count < size) Q.Push(words[i]); //若还没统计出指定数量单词,无须比较 else if (Q.Top().cnt < words[i].cnt || (Q.Top().cnt == words[i].cnt && Q.Top().word.CompareTo(words[i].word) > 0))
//顶上元素比当前元素小,更换成当前元素 { Q.Pop(); Q.Push(words[i]); } } while (Q.Count != 0) { tmp.Add(Q.Pop()); } return tmp; } private Comparer com = null; private IComparer<Word> Com //自定义比较器 { get { if (com == null) { com = new Comparer(); } return com; } } private class Comparer : IComparer<Word> { int IComparer<Word>.Compare(Word x, Word y) { return (x.cnt == y.cnt) ? y.word.CompareTo(x.word) : x.cnt.CompareTo(y.cnt); } } }

统计单词类
class ReadFile { public static string cal(string str) { string output = null; StreamReader sr = new StreamReader(str, Encoding.Default); String line; while ((line = sr.ReadLine()) != null) { output += line; } return output; } } public class CountChar { public int Cnt(string path) { string str = ReadFile.cal(path).Replace('\r', ' ').Replace('\n', ' '); return str.Length; } }
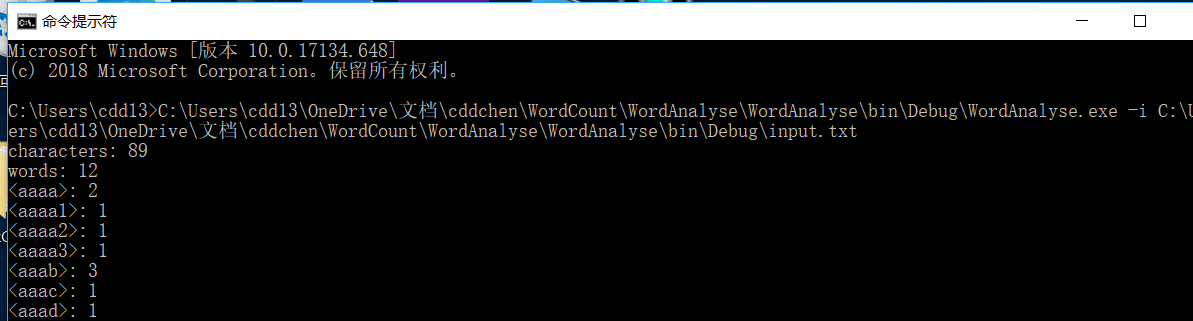
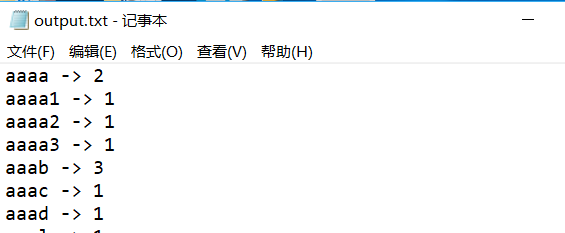
运行截图
最后.心得体会
刚开始和同学开始合作,都还不知道如何分析需求,分配任务。通过不断地沟通交流,及时同步进度,两个人之间的效率也不断提高了。两个人在面对问题的时候更容易想出解决方案,效率更高。在不断磨合之后,两个的配合更加融洽,达到了1+1>2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号