
【MYSQL】聚合函数介绍
聚合函数介绍
1.4 GROUP BY
1.5 Having
1.1 AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary) FROM employees WHERE job_id LIKE '%REP%'; /* +-------------+-------------+-------------+-------------+ | AVG(salary) | MAX(salary) | MIN(salary) | SUM(salary) | +-------------+-------------+-------------+-------------+ | 8272.727273 | 11500.00 | 6000.00 | 273000.00 | +-------------+-------------+-------------+-------------+ */
1.2 MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
SELECT MIN(hire_date), MAX(hire_date) FROM employees; /* +----------------+----------------+ | MIN(hire_date) | MAX(hire_date) | +----------------+----------------+ | 1987-06-17 | 2000-04-21 | +----------------+----------------+ */
1.3 COUNT函数
- COUNT(*)或COUNT(任意数字)返回表中记录总数,适用于任意数据类型。COUNT(任意数字),相当与用数字填充表的第一例。
SELECT COUNT(*) FROM employees WHERE department_id = 50; /* +----------+ | COUNT(*) | +----------+ | 45 | +----------+ */
COUNT(字段) 计算指定字段出现的个数时,是不计算NULL值的,相当于以下sql代码:
SELECT commission_pct FROM employees WHERE commission_pct IS NOT NULL;
例子
SELECT COUNT(commission_pct) FROM employees WHERE department_id = 50; /* +-----------------------+ | COUNT(commission_pct) | +-----------------------+ | 0 | +-----------------------+ */
需求:查询公司中平均奖金率
SELECT SUM (commission_pct) / COUNT(IFNULL (commission_pct,0)),AVG(IFNULL(comnission_pct,0)) FROM employees;
问题:用count(*), count(1),count(列名)谁好呢?
如何需要统计表中的记录数,使用count(*)、count(1)、count(具体字段)
哪个效率更高呢?
如果使用的是MyISAM存储引擎,则三者效率相同,都是o(1),有mate
如果使用的是InnoDB存储引擎,则三者效率:count(*) '= ‘count(1) '> count(字段),强两者会找优化的方式,后者只能执行没有优化的方式。
1.4 GROUP BY
特性:
1、SELECT中出现的非聚合函数的字段必须声明在GROUP BY中。GROUP BY中声明的字段可以不出现在SELECT中。
2、 GROUP BY声明在FROM后面、WHERE后面,ORDER BY前面、LIMIT前面
3、MysQL中GROUP BY中使用wiht ROLLUP 不要合order by 一起使用。
格式
SELECT column, group_function(column) FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column];
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id ; /* +---------------+--------------+ | department_id | AVG(salary) | +---------------+--------------+ | NULL | 7000.000000 | | 10 | 4400.000000 | | 20 | 9500.000000 | | 30 | 4150.000000 | | 40 | 6500.000000 | | 50 | 3475.555556 | | 60 | 5760.000000 | | 70 | 10000.000000 | | 80 | 8955.882353 | | 90 | 19333.333333 | | 100 | 8600.000000 | | 110 | 10150.000000 | +---------------+--------------+ */
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
SELECT AVG(salary) FROM employees GROUP BY department_id ; /* +--------------+ | AVG(salary) | +--------------+ | 7000.000000 | | 4400.000000 | | 9500.000000 | | 4150.000000 | | 6500.000000 | | 3475.555556 | | 5760.000000 | | 10000.000000 | | 8955.882353 | | 19333.333333 | | 8600.000000 | | 10150.000000 | +--------------+ */
使用多个列分组
SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id, job_id ; /* +---------+------------+-------------+ | dept_id | job_id | SUM(salary) | +---------+------------+-------------+ | NULL | SA_REP | 7000.00 | | 10 | AD_ASST | 4400.00 | | 20 | MK_MAN | 13000.00 | | 20 | MK_REP | 6000.00 | | 30 | PU_CLERK | 13900.00 | | 30 | PU_MAN | 11000.00 | | 40 | HR_REP | 6500.00 | | 50 | SH_CLERK | 64300.00 | | 50 | ST_CLERK | 55700.00 | | 50 | ST_MAN | 36400.00 | | 60 | IT_PROG | 28800.00 | | 70 | PR_REP | 10000.00 | | 80 | SA_MAN | 61000.00 | | 80 | SA_REP | 243500.00 | | 90 | AD_PRES | 24000.00 | | 90 | AD_VP | 34000.00 | | 100 | FI_ACCOUNT | 39600.00 | | 100 | FI_MGR | 12000.00 | | 110 | AC_ACCOUNT | 8300.00 | | 110 | AC_MGR | 12000.00 | +---------+------------+-------------+ */
在Mysql中 SELECT中出现的非聚合函数的字段必须声明在GROUP BY中。GROUP BY中声明的字段可以不出现在SELECT中。
错误写法
SELECT department_id,job_id,AVG (salary)PROM employees
GROUP BY department_id;
正确
SELECT department_id,job_id,AVG (salary)PROM employees
GROUP BY department_id,job_id;
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT department_id,AVG(salary) FROM employees WHERE department_id > 80 GROUP BY department_id WITH ROLLUP; /* +---------------+--------------+ | department_id | AVG(salary) | +---------------+--------------+ | 90 | 19333.333333 | | 100 | 8600.000000 | | 110 | 10150.000000 | | NULL | 11809.090909 | +---------------+--------------+ */
注意:
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
1.5 Having 聚合函数
(1) 则必须在HAVING中聚合函数过滤条件 ,不能在where中使用聚合函数过滤条件。否则,报错。
(2)HAVING必须声明在GROUP BY的后面,HAVING 通常跟 GROUP BY 一起使用。
(3)当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
当过滤条件中设有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。但是,建议大家声明在WHere
SELECT department_id, MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary)>10000 ; /* +---------------+-------------+ | department_id | MAX(salary) | +---------------+-------------+ | 20 | 13000.00 | | 30 | 11000.00 | | 80 | 14000.00 | | 90 | 24000.00 | | 100 | 12000.00 | | 110 | 12000.00 | +---------------+-------------+ */
#练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
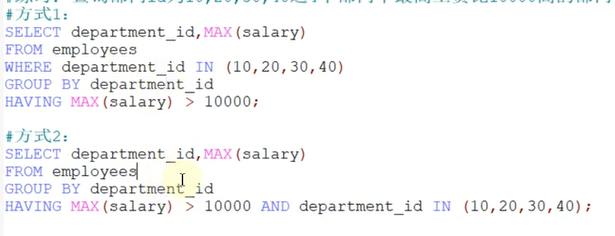
非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。如下:
SELECT department_id, AVG(salary) FROM employees WHERE AVG(salary) > 8000 GROUP BY department_id; #报错: #ERROR 1111 (HY000): Invalid use of group function

 浙公网安备 33010602011771号
浙公网安备 33010602011771号