【计算机组成原理】数据存储(大小端)和排列(内存对齐)
计算机中整数以补码的形式存储
正数的补码等于原码;负数的补码等于反码加1,而反码等于原码符号位不变,其余各位取反。为了简化计算机基本运算电路,使加减法都只需要通过加法电路实现,也就是让减去一个正数或加上一个负数这样的运算可以用加上一个正数来代替。于是改变负数存储的形式,存储成一种可以直接当成正数来相加的形式,这种形式就是补码。(正数不用变,所以接下来的讨论中一般略去正数)
大小对存储
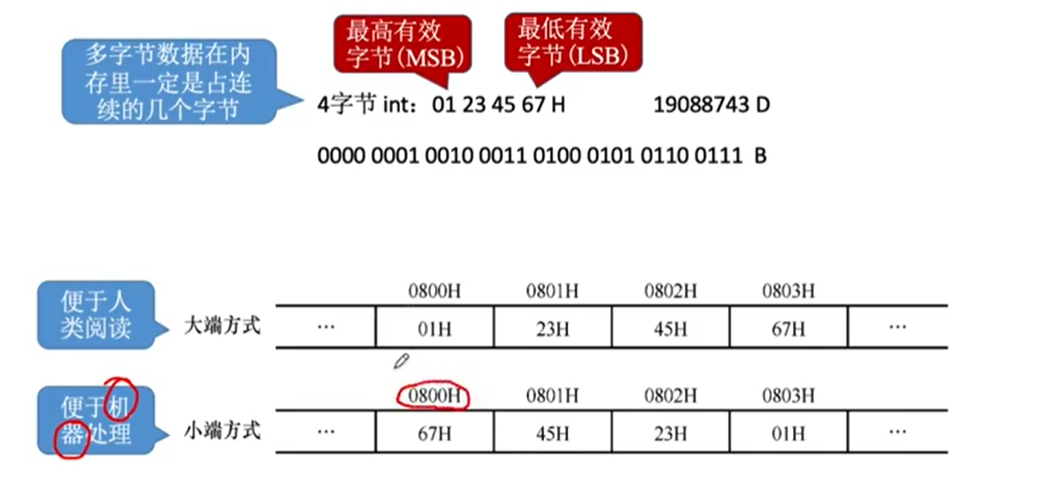
C#: 小端存储
网络发送字节流是按大端序发送,也就是从左到右发送
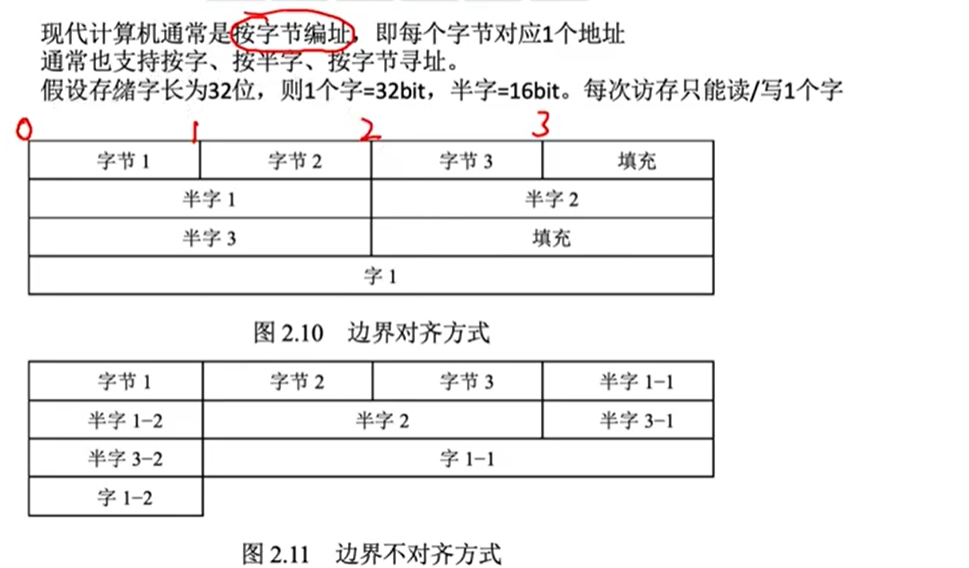
边界对齐
内存对齐,也叫边界对齐(boundary alignment),是处理器为了提高处理性能而对存取数据的起始地址所提出的一种要求。
边界对齐是系统层面的。系统一次性读取内存中数据的大小(尽管它能按字节读取),例如:字长为32 的操作系统,默认的一次读取4字节内容。
操作系统 会将内存中的地址编码,会从0开始,然后每次读取开始地址都要满足n mod 4=0。
为了满足操作系统这种读取数据习惯,我们代码运行时候产生的数据存储在内存中,也要满足这种规律,所以必须对数据结构进行布局以满足内存对齐要求。
每次只能读取一个字,不能跨行读取
为什么要边界对齐

sizeof用于检测,数据实例在内存中大小 数据结果对齐
在用sizeof运算符求算某结构体所占空间时,并不是简单地将结构体中所有元素磊自。占的空间相加,这里涉及到内存字节对齐的问题。
从理论上讲,对于任何变量的访问都可以从任何地址开始访问,但是事实上不是如此。实际上访问特定类型的变量只能在特定的地址访问,这就需要各个变量在空间上按一定的规
则排列,而不是简单地顺序排列,这就是内存对齐。
C#结构体的内存对齐(边界对齐)
对结构体的内存结构进行布局规则如下
规则1、每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。程序员可以通过[StructLayout(LayoutKind.Sequential, Pack =n)],n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。
C#对齐系数 n=0,1,2,4,8,16, 0表示默认的平台对齐系数,就是操作系统的字长/8。
规则2、数据成员对齐 :结构体的第一个字段的偏移量(offset)为0以后每一个成员相对于结构体首字段的offset都是该成员大小与有效对其值中较小的那个的整数倍,不满足条件,自动填补字节。
找最大数据长度时,如果结构体T有复杂类型成员A的,该A成员的长度为该复杂类型成员A的最大成员长度,例如 demail 由4个int 组成,它的最大成员是int,decimal a;a应是int 而不是decimal
备注:对齐单位(有效对齐值): 系统给定的对齐系数和结构体内最长数据长度,之中较小的那一个。有效对其值也叫做对齐单位。
规则3、结构的整体对齐:结构体总体size mod 对齐单位=0 ,结构体的总的大小时对齐单位的整数倍,不满足将自动填充。
案例一:
[StructLayout(LayoutKind.Sequential, Pack =4)]
unsafe struct ExampleStruct1
{
//对齐系数 pack=4
//最大对齐成员 是int =4
//对齐单位=pack>最大对齐成员?pcke:最大对齐成员
byte b;//第一个默认是对齐地址 为0=成员地址-对象地址
int a;// 4 a=对齐单位=4 ,因此a 从4开始对齐,前面补null
byte s;//8 b=1<对齐单位 ,因此 对齐地址= 对齐地址 mode b =0,不足在前面补0
short d;//10 d=2<对齐单位,因此 对齐地址= 对齐地址 mode d =0,不足在前面补0
byte c;//12
}
//最后一步是对象对齐= 结构体总体size mod 对齐单位=0 ,13/4!=0 所以 要补000 得到16/4=0
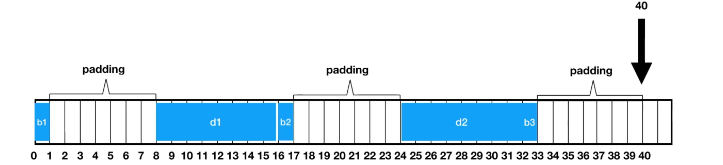
案例二:
struct Struct1 { public byte b1; public double d1; public byte b2; public double d2; public byte b3; }
第一个字段是一个字节,它 - 井 - 是1个字节大,它将被放置在位置0。
第二个字段是双精度值,即 8 个字节。现在,正如我们所看到的,默认情况下,编译器确保双精度值以 8 的倍数对齐 - 这是第二条规则 - 因此在本例中,它将第二个字段放在位置 8。在字节字段的末尾和双字段的开头之间,我们有填充,因此不使用这些位。然后我们有3。字段,又是 1 个字节,我们将其放置到位置 16,然后我们有一个双精度值,在这里我们需要再次填充,因此我们将其放置到位置 24,然后我们有最后一个字节字段,该字段将从位置 32 开始。现在结构必须与最大的成员类型对齐 - 记住,这是第一个规则 - 在这种情况下是8字节的大双精度类型,32 + 8是40,因此这个结构的大小是40。
案例三:
struct Struct2 { public double d1; public double d2; public byte b1; public byte b2; public byte b3; }
因此,我们将第一个双精度放在位置 8 处,其长度为 8 字节,因此我们不需要在此处填充。然后我们有另一个双字段,从位置8开始。然后我们有第一个字节字段,我们把它放在位置16,它将占用1字节的空间。然后我们有下一个字节字段,它又是1个字节,所以它仍然适合这个桶 - 记住第二个规则,一个1字节字段与1字节对齐 - 所以我们把它放在第一个字节字段旁边。然后我们有3。字节字段,我们对它做同样的事情。在此之前,我们使用19个字节,但同样,结构必须与最大的成员对齐,即8,因此16 + 8等于24,这正是运算符告诉我们的大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号