【C# 数据结构与算法】B+树 多路查找树
阅读本章需要知识储备
B+树的背景
由于B树非终端节点存储了除了关键字,还存储了数据库的指针,所以导致b树的效率高。所以为了改进效率,就讲让非终端节点只存储关键字,于是就有了B+树。
B+树
视频地址7.7B+树 - YouTube
B+ 树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
备注:多路查找树是二叉搜索树的扩展。用空间复杂度换取时间复杂度。二叉搜索树是在内存中内存空间有限,而cpu查找内存速度快,所以二叉树就用时间换取空间。

B+ 树在节点访问时间远远超过节点内部访问时间的时候,比可作为替代的实现有着实在的优势。这通常在多数节点在次级存储比如硬盘中的时候出现。通过最大化在每个内部节点内的子节点的数目减少树的高度,平衡操作不经常发生,而且效率增加了。这种价值得以确立通常需要每个节点在次级存储中占据完整的磁盘块或近似的大小。
B+树的规则
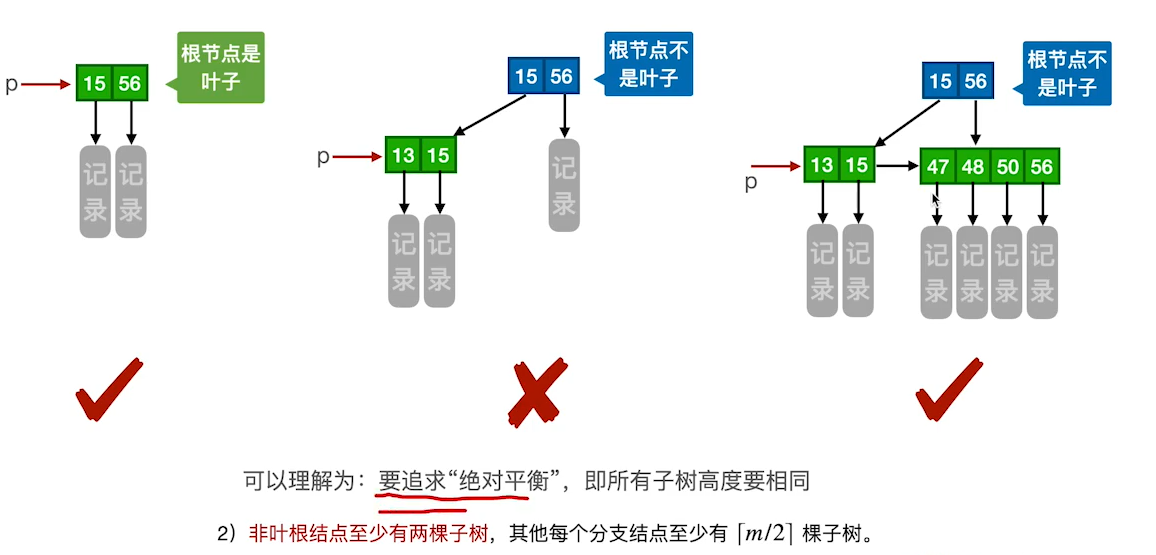
一棵m阶的B+树需满足下列条件︰
1)每个分支结点最多有m棵子树(孩子结点)。
2)非叶根结点至少有两棵子树,为了保证树绝对平衡,其他每个分支结点至少有「m/2]棵子树。
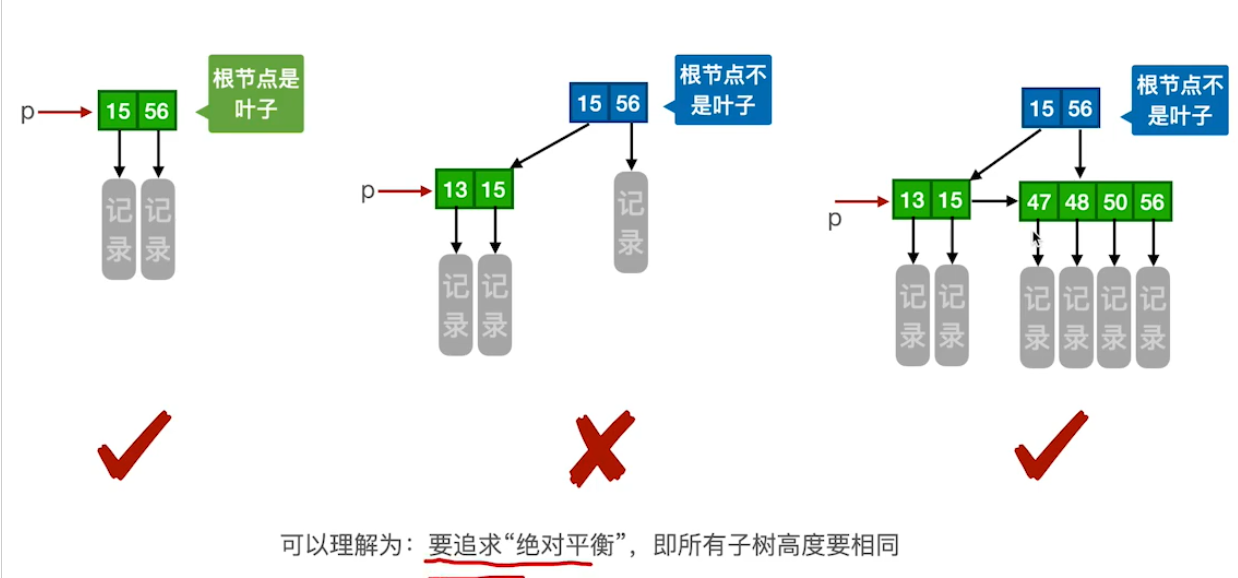
3)结点的子树个数与关键字个数相等。
4)所有吐结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序相互链接起来。
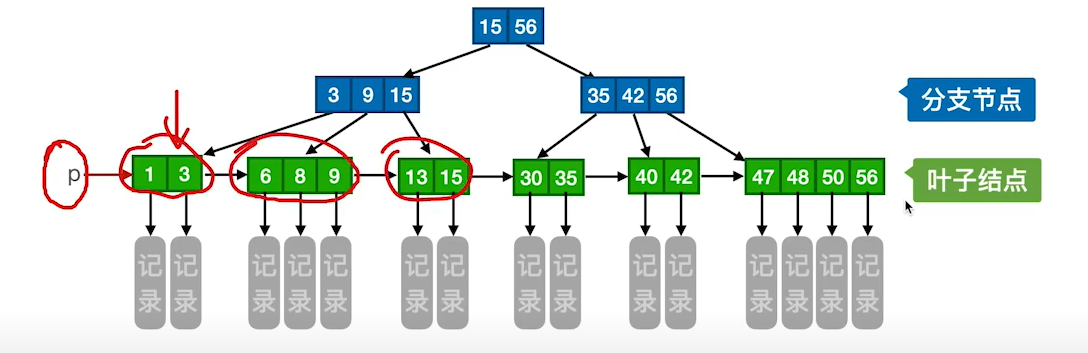
5)所有分支结点中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针。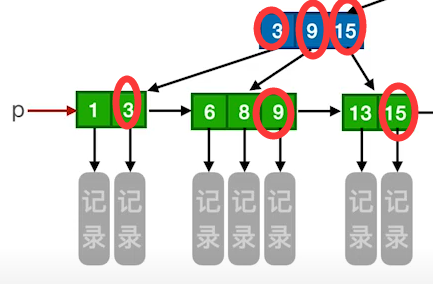
B+的平衡机制
非叶的根结点至少有两棵子树。其他分支结点至少有【m/2】棵子树
查找
B+树的查找一定要查找到叶子结点,才能确定记录是否存在。而B只要在某一次层就可以确定数据是否存在。
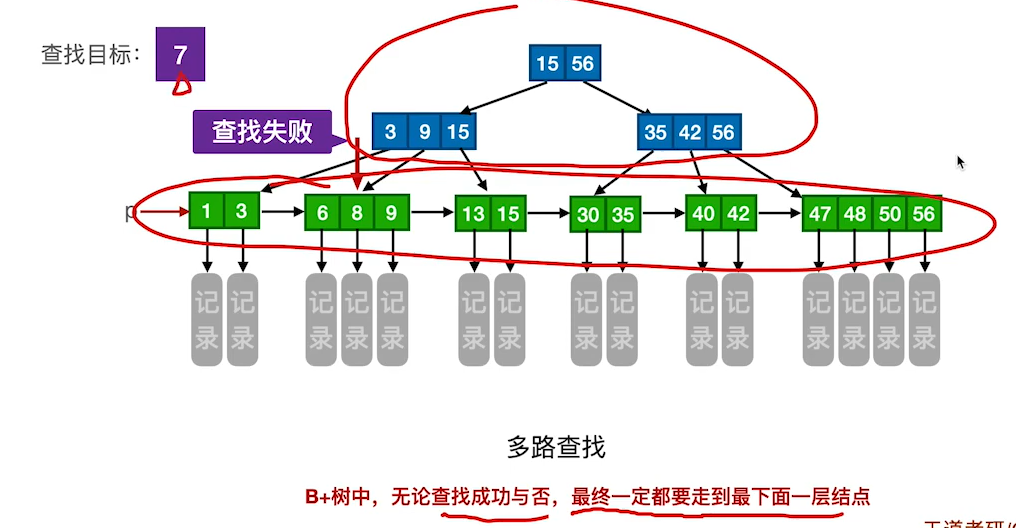
B+树和B树的区别
1)结点中的n个关键字对应n棵子树
2)B树根节点的关键字数n=[1, m],其他结点的关键字数n=[[m/2], m]。而B+树非叶根结点至少有两个关键子,一个关键字对应一棵子树
3)在B+树中,叶结点包含全部关键字,非叶结点中出现过的关键字也会出现在叶结点中
4)在B+树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
B树的结点中都包含了关键字对应的记录的存储地址
5)在B+树中,非叶结点不含有该关键字对应记录的存储地址。可以使一个磁盘块可以包含更多个关键字,使得B+树的阶更大,树高更矮,读磁盘次数更少,查找更快。
而B树种每个关键字都需要保存对应记录的存储地址,所以他的更占用
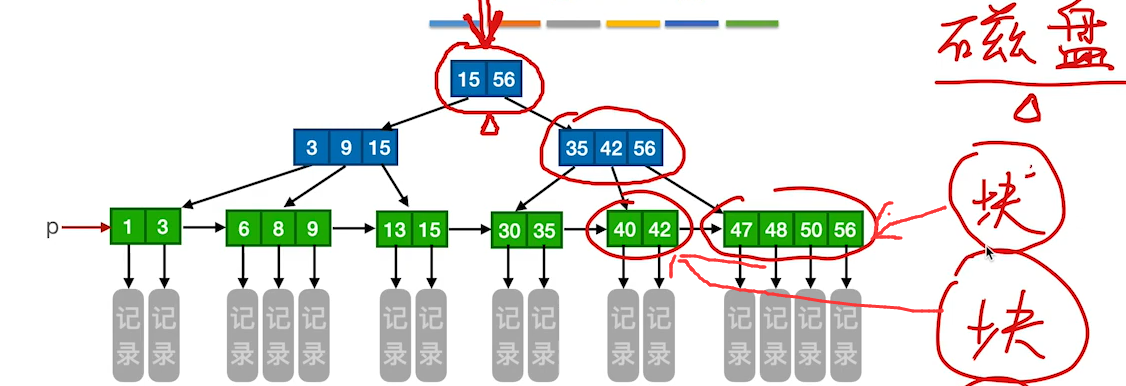

B+树的应用
mysql的B+树索引有多少阶?
对于这个问题,我们需要先了解下磁盘相关知识.
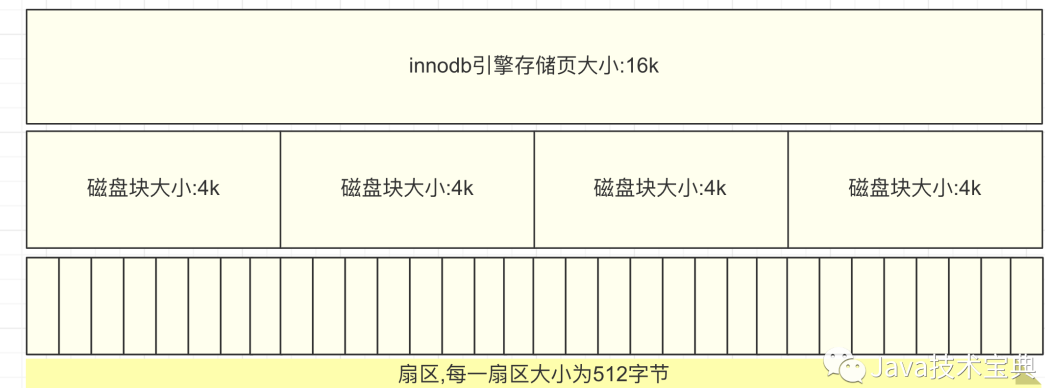
磁盘的最小存储单位是扇区(512字节)
磁盘的读取是以块为基本单位,一块大小为8个扇区,即4kb
B+树的每一个节点占用的空间就是一个块大小
由于B+树节点中只存储元素和指针.如果有n个元素,那么就有n+1个指针,假设现在索引存储int类型的值,一个int(32位)占用4个字节,一个指针占用8个字节(64位操作系统),那么一个块最多能存4096/(4n+8(n+1))即340个元素,那么索引即为341阶(m阶数最多包含m-1个元素).
mysql的B+树索引能存多少数据?
以innodb引擎的索引数据结构为例,它的存储单元为一页,每页大小默认为16kb,该值可以通过参数调整,如下图.

假设每个节点中索引元素占8个字节,指针占用6个字节,那么每页可存(16*1024)/(8+6)=1170个索引元素
假设B+树的高度为3,一条数据大小为1k,那么: 第一层可以存1170个元素; 第二层可以存11701170=1368900个元素; 第三层属于叶子结点,可以存的数据条数为页大小16k/每条数据大小1k,即16条,那么总共可以存储的数据条数即为161368900=21902400
总结:mysql 单表使用innodb引擎(表数据文件本身就是一个B+树组织的索结构文件),默认至少可以存2000w数据(实际每个节点不只存储了元素及指针),并且查找数据,最多3次io即可.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号