【C# XML】XML的解析器
访问XML文件的两个基本模型和一个C#特有的模型
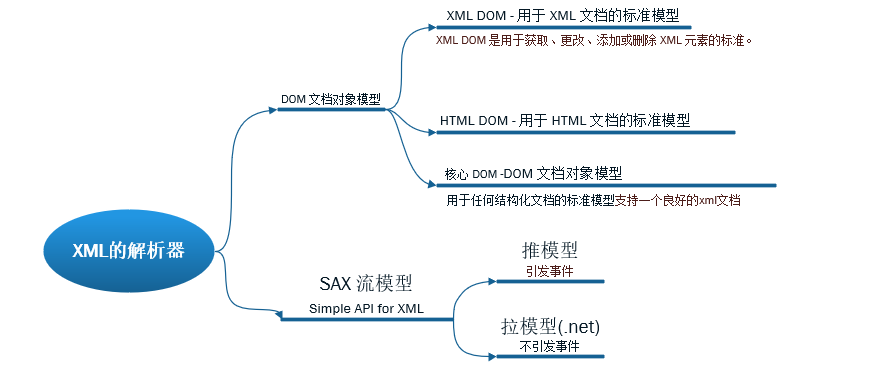
1)DOM文档模型(XML Doc的Xpath)
DOM模型是W3C标准,C#对DOM文档模型的实现类 为 XmlDocument 类
使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性加载整个文档到内存中,对于大型的文档,这会造成资源问题。
根据 DOM,XML 文档中的每个成分都是一个节点。关于节点(非常重要)
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
![]()
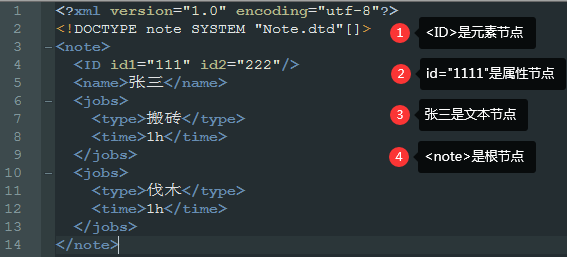
注意:
文本总是存储在文本节点中
在 DOM 处理中一个普遍的错误是,认为元素节点包含文本。
不过,元素节点的文本是存储在文本节点中的。
在这个实例中:<year>2005</year>,元素节点 <year>,拥有一个值为 "2005" 的文本节点。
"伐木" 不是 <type> 元素的值!
详细学习DOC文档模型:https://www.runoob.com/dom/dom-methods.html
2)流模型(Stream的XMLReader)
流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。虽然是各有千秋,但我们也可以在程序中两者并用实现优劣互补。
在C#中,使用SAX进行解析的类为XmlReader, XmlWriter,这两个类都是抽象类,由具体的子类来实现相关的功能。
3)C#特有的Linq to Xml读取复杂xml(带命名空间)
编程是个人爱好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号