【C# XML】XPath 表达式 以及对应的C#xml.Xpath命名空间
简介
XPath是一种在一个XML文档中寻址的语言,为XSLT和XPointer而设计。Path的主要目的是在一个XML文档中寻址。支持这个主要目的,它还提供基本功能来操纵字符串、数字和布尔值。
在XPath 1.0和XSLT 1.0中,通常使用节点树。 解析的XML文档是一棵包含文档节点及其后代的树。 使用该节点树,您可以找到根元素的节点,以及所有根元素的后代,属性和同级。 (XML文件的根元素之外的任何注释或处理指令都被视为根元素的同级。)
XPath 2.0和XSLT 2.0中的主要新概念之一是,一切都是序列。.net 6.0xpath 是xpath 2.0
XQuery1.0与XPath2.0有共同的数据模型即使:7个节点(即处理指令,元素,文档节点,属性,命名空间,文本节点和注释。),所有的值都成为序列,序列由节点或原子值组成,如整数,字符串或布尔值。
Xpath 数据模型
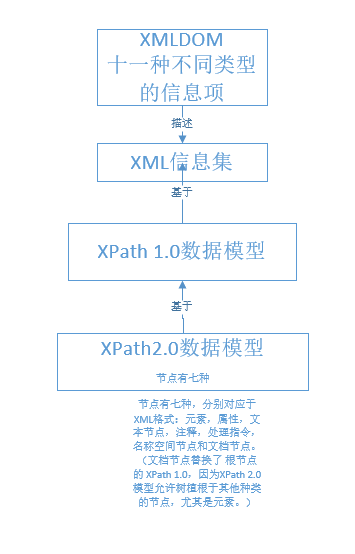
XPath1.0与XPath2.0的区别
XPath2.0任何东西都是序列:这是因为XPath 2.0所有的表达式都返回序列。 节点集是有序的,
XPath2.0序列和包含重复的节点
XPath2.0完全支持 XML Schema 数据类型
XPath2.0序列很浅:序列之间不会发生嵌套,如果你试图在序列中嵌套序列,当然在句法上可以接受,不过你得到的是一个“膨胀的”序列,子序列和包含它的序列仍然是依次排列的。
XPath2.0序列是有序的:XPath 2.0清楚的理解和表示序列中的次序,可以保持或者创造任何你指明的顺序作为结果。在XPath 2.0中,序列取代了1.0中所谓的节点集(node-sets)。
XPath2.0Xpath加入了一些重要的关键字包括序列操作符,比如for、条件表达式、定量修饰符(quantifiers)和集合操作(集合的交、差和并)。同样还有一个except操作符,它允许一项操作应用于一个序列中除了特定的成员之外的其他所有成员。你也会发现很多类型映射和强制转换(coercion)的关键字。
C# 相对应的xpath命名空间
System.Xml.XPath概览
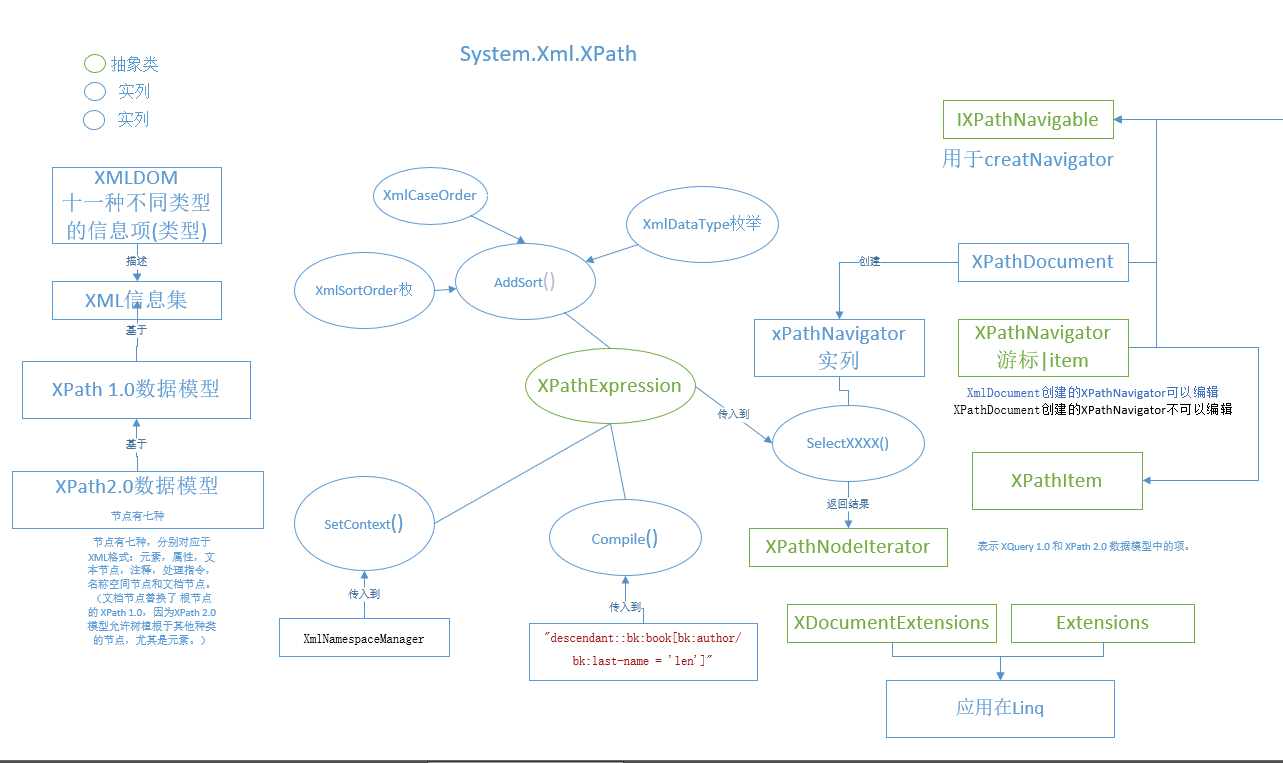
该命名空间有两个重要的类型:XPathDocument、XPathNavigator
XPathNavigator实现了DOM2级 种 遍历和范围模块
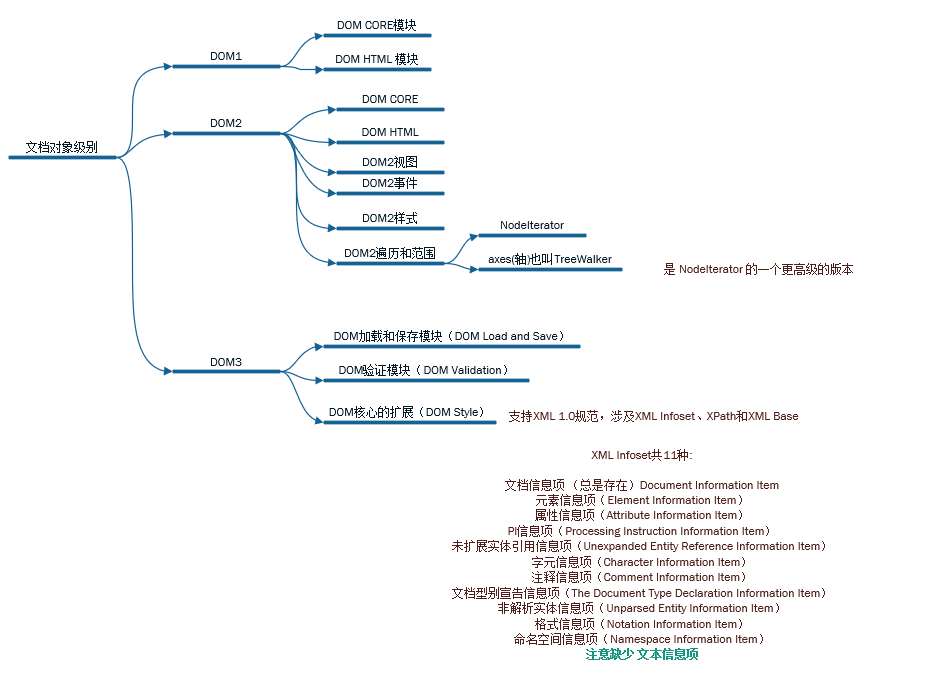
XPath
重点:在应用xpath时候,要注意DOM标准 对节点的定义
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
XPath 的意思是 XML 路径语言。它使用的一个非 XML 语法提供一种灵活地定位 XML (en-US) 文档的不同部分的方法。它同时也可以用于检测文档中某个节点是否与某个模式(pattern)匹配。
XPath 主要被用于 XSLT,也可用于定位文档元素,像类 XML 语言文档(如HTML 和 XUL ) 通过 DOM (en-US) 定位元素一样。替代 document.getElementById 方法、 element.childNodes 属性和其他DOM核心特性。
XPath 使用路径标识符通过层级结构来导航XML文档。它使用非XML语法,以致于它可以被用在URIs和XML属性值上。
【C# XPath】
xml常用的元素定位方式:css选择器、 xpath
Xpath表达式
XPath工具
vs2022 XPath Tools
1、vs2022 扩展》管理扩展》下载 XPath Tools> 重启 vs2022
2、光标定位 到元素的开始标签,鼠标右键复制 xpath
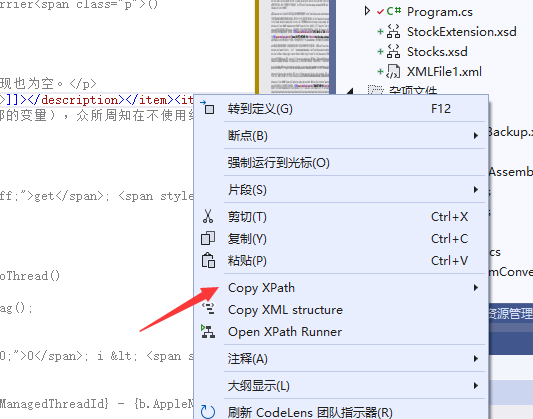
3、可以鼠标右键 调出xpath tools 。自行写xpath 测试

vscode xpath工具:xml tools
vscode Xpath工具:XSLT/XPath
1、vscode xpath下载插件xml tools
2、光标放在要定位的 开始元素标签上,这边用博客园的 "备份.xml"做测试
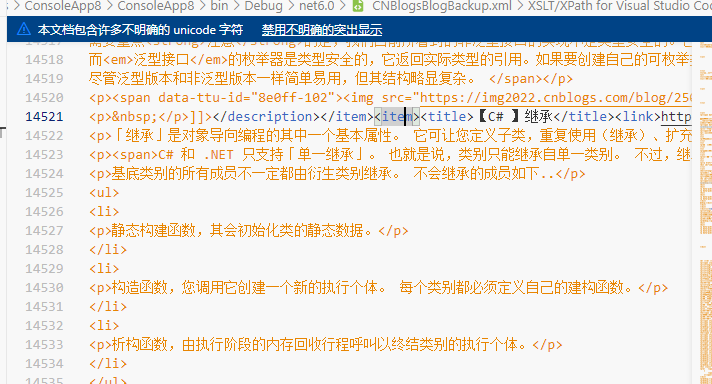
3、shift +ctrl+p >选择 get current xpath
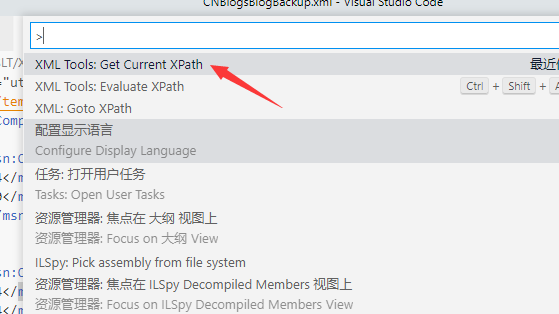
4、结果:/rss/channel/item[90]
浏览器 自带的支持Xpath
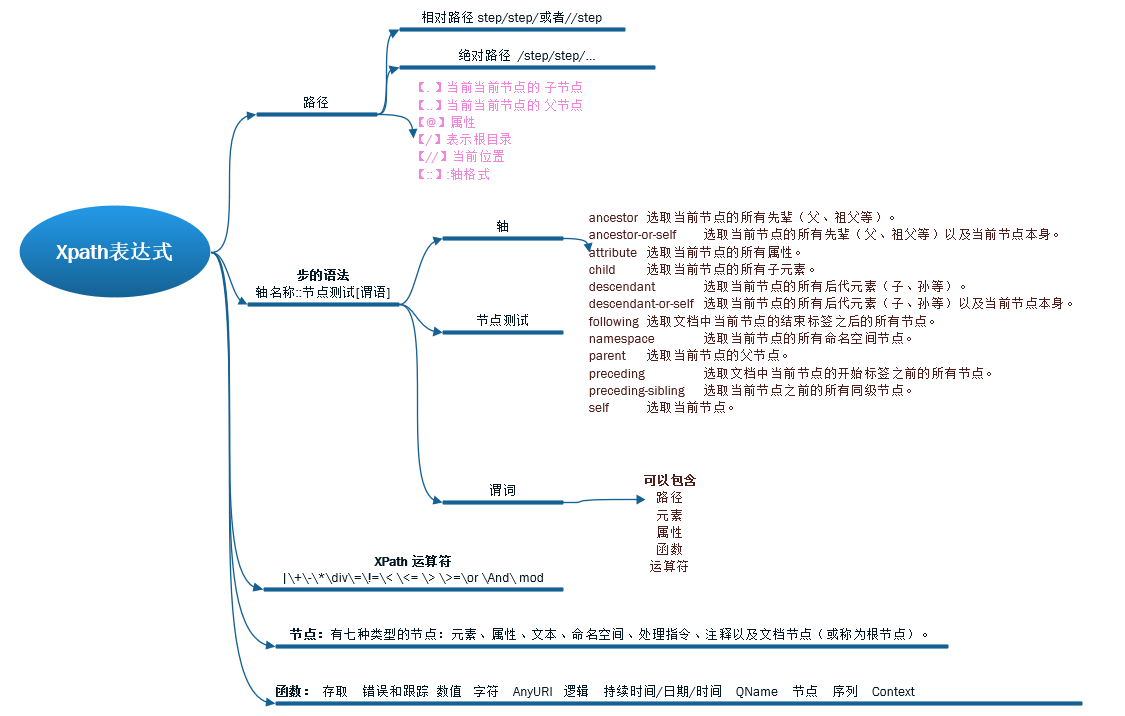
路径定位方式
绝对路径:/setp/setp
相对路径:setp/setp
案例:/root/parent/my/child/son
step:轴名称::节点测试[谓语]
轴(axis相当于家族):定义所选节点与当前节点之间的树关系
节点测试(node-test):识别某个轴内部的节点
零个或者更多谓语(predicate):更深入地提炼所选的节点集
/:表示根目录 例如 # res=html.xpath('/html/body/*') # 找html下body下的所有标签(只找子,不找孙)
//:当前位置 例如# res=html.xpath('/html/body//*') # 找html下body下的所有标签(子子孙孙)
Xpath的基本使用方法
这部分内容来源:https://blog.csdn.net/ZYX_jber/article/details/120986932
实例 '//div[@id="example1"/input[@class="color:red"]'
斜线”/”是从根节点选择,双斜线”//”从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置,点”.”选取当前节点,两点”..”选取当前节点的父节点,“@”为选取属性。
1、斜线/从根节点选择,基本的XPath语法类似于在一个文件系统中定位文件,如果路径以斜线 / 开始, 那么该路径就表示到一个元素的绝对路径,获取满足该路径的所有节点:
选择根元素 语法:/AAA
选择AAA的所有CCC子元素 语法:/AAA/CCC
2、如果路径以双斜线 // 开头, 则表示选择文档中所有满足双斜线//之后规则的元素(无论层级关系),//会做全文档扫描。
选择所有BBB元素 语法://BBB
选择所有父元素是DDD的BBB元素 语法://DDD/BBB
选择AAA的CCC的所有BBB元素 语法:/AAA/CCC//BBB
3、点“.” 选取当前节点。
4、“..”选取当前节点的父节点。
5、”@”选取属性。
选择所有的id属性 语法://@id 注意:这里选取的是属性而不是方法。
选择有id属性的BBB元素 语法://BBB[@id] 区别于上面的属性选择
选择id属性为“b1”的BBB元素 语法://BBB[@id="b1"]
选择有任意属性的BBB元素 语法://BBB[@*]
选择不具有任何属性的BBB元素 语法://BBB[not(@*)]
谓语在XPath是重要的一部分,谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。[谓语]
1、选择AAA下的第一个BBB元素 语法:/AAA/BBB[1]
2、选择AAA下的最后一个BBB元素 语法:/AAA/BBB[last()]
3、选择AAA下的倒数第二个BBB元素 语法:/AAA/BBB[last()-1]
4、选择AAA下的前面两个BBB元素 语法:/AAA/BBB[position()<3]
5、获取AAA下的BBB下的有s属性的CCC元素 语法:/AAA/BBB/CCC[@s]
6、选取所有 bookstore 元素的 book 元素,且其中的 price 元素的值须大于 35.00。 语法:/bookstore/book[price>35.00]
7、选取所有 bookstore 元素中的 book 元素的 title 元素,且其中的 price 元素的值须大于 35.00. 语法:/bookstore/book[price>35.00]/title
选择未知的XML元素和选择若干路径。 *
1、星号 * 表示选择所有由星号之前的路径所定位的元素,*是通配符,表示该路径下的所有元素,也表示层次。
选择所有路径依附于/AAA/CCC/DDD的元素 语法:/AAA/CCC/DDD/*
选择所有的有3个祖先元素的BBB元素,即在第四层的BBB元素 语法:/*/*/*/BBB
选择所有元素 语法://*
2、“@*”匹配任何属性的节点,not(@*)匹配没有任何属性的节点。
3、“|”是多个路径选择的并集,可以利用“|”查找符合多个条件的节点。
获取所有的BBB元素和EEE元素 语法://BBB|//EEE
获取AAA下XXX下的DDD的BBB元素和EEE元素 语法:/AAA/XXX/DDD/BBB|/AAA/XXX/DDD/EEE
XPath 轴(axis::)定位方式(类比族谱)
【. 】: 当前当前节点的 子节点
【..】:当前当前节点的 父节点
【@】:属性
【::】:轴格式 例如:轴(axis)::元素或者通配符*
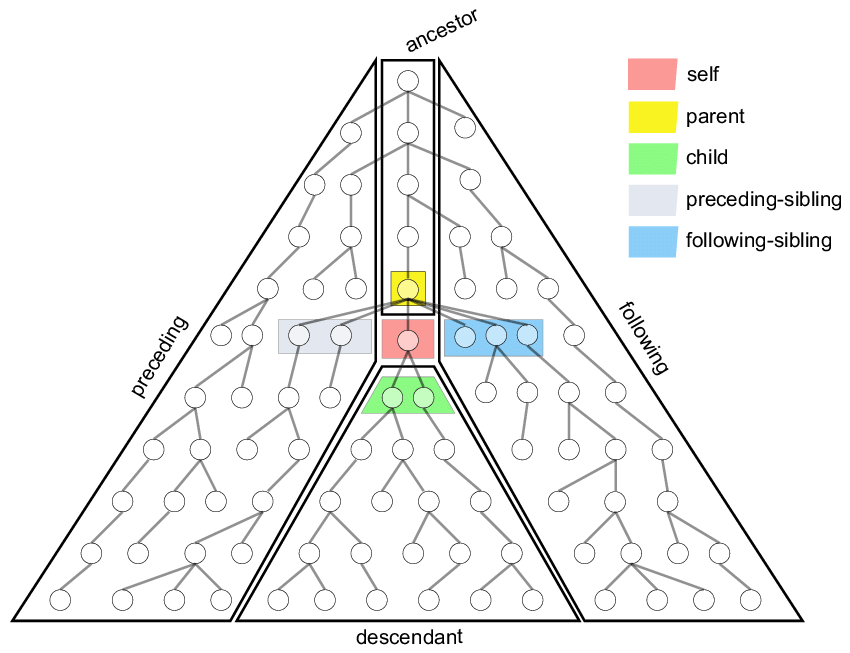
| Xpath轴关键字 | 轴的定义说明 | 定位表达式实例 | 表达式解释 |
| parent | 父母 | //img[@alt='div2-img2']/parent::div | 查找到alt属性为div2-img2的img元素,并基于图片找到其上一级的div元素 |
| child | 子代 | //div[@id='div1']/child::img | 查找id为div1的div标签,基于当前div查找标签为img的子节点 |
| ancestor | 祖代,父亲和父亲的父亲,以此类推 | //img[@alt='div2-img2']/ancestor::div | 查找alt属性为div2-img2的图片,基于当前图片找到其上级的div页面元素 |
| descendant | 后代,儿子和他们孩子以此类推 | //div[@id='div2']/descendant::img | 查找id属性为div2的div元素,在查找其下级所有节点中的img元素 |
| following | 弟弟妹妹和他们的孩子 | //div[@id='div1']/following::img | 查找到ID属性为div1的div元素,并基于div的位置找到它后面节点中的img元素 |
| following-sibling | 弟弟妹妹 | //img[@alt='div1-img1']/following-sibling::input | 查找到alt属性为div1-img1的img页面元素,并基于img的位置找到后续节点中的input元素 |
| preceding | 哥哥姐姐和他们的孩子 | //img[@alt='div2-img2']/preceding::div | 查找到alt属性为div2-img2的图片页面元素,并基于图片的位置找到它前面节点中的div元素 |
| preceding-sibling | 哥哥姐姐 | //img[@alt='div2-img2']/preceding-sibling::a[1] | 查找到alt属性值为div2-img2的图片元素,基于图片位置找到它前面同级节点的第二个链接页面元素 |
轴(类比族谱树结构)Xpath的基本使用方法
XPath轴(XPath Axes)可定义某个相对于当前节点的节点集:
1、child 选取当前节点的所有子元素
child是Xpath默认的轴,可以省略不写。下面看些简单例子:
/child::AAA 等价于/AAA
2、parent 选取当前节点的父节点
parent轴是选取当前节点父节点,下面看简单示例:
//DDD/parent::* 获取所有节点DDD的父节点
/AAA/BBB/parent::* 得到根节点AAA,这样写在实际中没有意义。
/AAA/parent::* 根节点无法获取到parent
3、descendant 选取当前节点的所有后代元素(子、孙等)
descendant选取当前节点的所有后代元素(包括子节点、子孙节点…),descendant (后代)轴包含上下文节点的后代,一个后代是指子节点或者子节点的子节点等等。
/descendant::* 选择文档根元素的所有后代.即所有的元素被选择
/AAA/BBB/descendant::* 选择/AAA/BBB的所有后代元素
//CCC/descendant::* 选择所有CCC元素的所有后代元素
//CCC/descendant::DDD 择所有以CCC为祖先元素的DDD元素
4、ancestor 选取当前节点的所有先辈(父、祖父等)
ancestor轴(axis)包含上下节点的祖先节点, 该祖先节点由其上下文节点的父节点以及父节点的父节点等等诸如此类的节点构成,所以ancestor轴总是包含有根节点,除非上下文节点就是根节点本身.
/AAA/BBB/DDD/CCC/EEE/ancestor::* 选择一个绝对路径上的所有节点
//FFF/ancestor::* 选择FFF元素的所有祖先节点
5、descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身
descendant-or-self跟descendant类似,多了节点本身。
/AAA/BBB/descendant-or-self::* 选择/AAA/BBB本身及所有后代元素
//CCC/descendant-or-self::* 选择CCC的所有后代元素及本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
ancestor-or-self跟ancestor类似,多了本身节点,选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
/AAA/BBB/DDD/CCC/EEE/ancestor-or-self::* 选择/AAA/BBB/DDD/CCC/EEE的先辈及本身
//FFF/ancestor-or-self::* 选择FFF元素的所有先辈以及FFF本身
7、preceding-sibling 选取当前节点之前的所有同级节点(前面的)
preceding-sibling,选取当前节点之前的所有同级节点,同一个parent下该节点之前的节点,即“哥哥”节点(是同父的哥哥节点)。
/AAA/XXX/preceding-sibling::* /AAA/XXX节点的所有之前同级节点
//CCC/preceding-sibling::* 选取所有CCC节点的同级哥哥节点
8、following-sibling 选取当前节点之后的所有同级节点(后面的)
following-sibling 选取当前节点之后的所有同级节点,跟preceding-sibling一样都是选取同级同父的节点,只不过following是取对应节点之后的节点,preceding-sibling取的是该节点之前的节点。
/AAA/BBB/following-sibling::* 取/AAA/BBB节点的之后的所有同级节点
//CCC/following-sibling::* 选取所有CCC元素的之后所有同级节点
9、preceding 选取当前节点的开始标签之前的所有节点
preceding选取文档中当前节点的开始标签之前的所有节点,包含同一文档中按文档顺序位于上下文节点之前的所有节点,除了祖先节点。
/AAA/XXX/preceding::* 选取/AAA/XXX节点所有之前节点(除其祖先外)
//FFF/preceding::* 选取所有FFF节点的所有之前节点(除祖先外),在下面的例子中,选取的结果跟/AAA/XXX/DDD/FFF/preceding::*一样
10、following 选取当前节点的结束标签之后的所有节点
following选取文档中当前节点的结束标签之后的所有节点,包含同一文档中按文档顺序位于上下文节点之前的所有节点,除了祖先节点。 following选取文档中当前节点的结束标签之后的所有节点跟preceding的范围一样,只是方向不同,following是向后选取,preceding是向前选取。
/AAA/BBB/following::* 选取/AAA/BBB节点后的所有节点
//ZZZ/following::* 选取所有ZZZ节点之后的节点
11、self 选取当前节点
self选取当前节点,单独使用没有什么意思,主要是跟其他轴一起使用,如ancestor-or-self,descendant-or-self.
12、attribute 选取当前节点的所有属性
attribute轴选取当前节点的所有属性,获取的结果是属性而不是节点,前面所有的轴都是选取节点。
/AAA/BBB/attribute::* 选取/AAA/BBB节点的所有属性
//CCC/attribute::* 选取所有CCC节点的所有属性
13、namespace 选取当前节点的所有命名空间节点
名称空间轴用来选取名称空间结点。每个元素结点都有一个专门名称空间结点表示每个作用域名称空间。
常用定位语句实例
-
//NODE[not(@class)] 所有节点名为node,且不包含class属性的节点
-
//NODE[@class and @id] 所有节点名为node,且同时包含class属性和id属性的节点
-
//NODE[contains(text(),substring] 所有节点名为node,且其文本中包含substring的节点
//a[contains(text(),"下一页")] 所有包含“下一页”字符串的超链接节点
//a[contains(@title,"文章标题")] 所有其title属性中包含“文章标题”字符串的超链接节点
-
//NODE[@id="myid"]/text() 节点名为node,且属性id为myid的节点的所有直接text子节点
-
BOOK[author/degree] 所有包含author节点同时该author节点至少含有一个的degree孩子节点的book节点
-
AUTHOR[.="Matthew Bob"] 所有值为“Matthew Bob”的author节点
-
//*[count(BBB)=2] 所有包含两个BBB孩子节点的节点
-
//[count()=2] 所有包含两个孩子节点的节点
-
//*[name()='BBB'] 所有名字为BBB的节点,等同于//BBB
-
//*[starts-with(name(),'B')] 所有名字开头为字母B的节点
-
//*[contains(name(),'C')] 所有名字中包含字母C的节点
-
//*[string-length(name()) = 3] 名字长度为3个字母的节点
-
//CCC | //BBB 所有CCC节点或BBB节点
-
/child::AAA 等价于/AAA
-
//CCC/descendant:😗 所有以CCC为其祖先的节点
-
//DDD/parent:😗 DDD节点的所有父节点
-
//BBB[position() mod 2 = 0] 偶数位置的BBB节点
-
AUTHOR[not(last-name = "Bob")] 所有不包含元素last-name的值为Bob的节点
-
P/text()[2] 当前上下文节点中的P节点的第二个文本节点
-
ancestor::BOOK[1] 离当前上下文节点最近的book祖先节点
-
//A[text()="next"] 锚文本内容等于next的A节点
练习案例
using System; using System.IO; using System.Xml; using System.Xml.XPath; public class Sample { public static void Main() { XmlDocument doc = new XmlDocument(); doc.Load("Books.xml"); XPathNavigator xPathNavigator=doc.CreateNavigator();//XmlDocument可以编辑 Console.WriteLine(xPathNavigator.CanEdit); XPathNavigator xPathNavigator2 = new XPathDocument("Books.xml").CreateNavigator();//XPathDocument不可以编辑 Console.WriteLine(xPathNavigator2.CanEdit); //定位到书列表 xPathNavigator.MoveToChild("bookstore", "http://www.contoso.com/books"); //添加一本书 using XmlWriter xmlWriter = xPathNavigator.AppendChild(); xmlWriter.WriteStartElement("book");//只能改变内存中文档的结构,不能修改文件中文档的结构,xmlWriter 不会影响xPathNavigator的位置 xmlWriter.WriteAttributeString("genre", "autobiography"); xmlWriter.WriteAttributeString("publicationdate", "2011-03-22"); xmlWriter.WriteElementString("title", "zhanzheng与和平"); xmlWriter.WriteStartElement("author"); xmlWriter.WriteElementString("first-name", "ai"); xmlWriter.WriteElementString("last-name", "len"); xmlWriter.WriteEndElement(); xmlWriter.WriteEndElement(); xmlWriter.WriteStartElement("book");//只能改变内存中文档的结构,不能修改文件中文档的结构,xmlWriter 不会影响xPathNavigator的位置 xmlWriter.WriteAttributeString("genre", "autobiography"); xmlWriter.WriteAttributeString("publicationdate", "2011-03-22"); xmlWriter.WriteElementString("title", "jinrong"); xmlWriter.WriteStartElement("author"); xmlWriter.WriteElementString("first-name", "ai"); xmlWriter.WriteElementString("last-name", "len"); xmlWriter.WriteEndElement(); xmlWriter.WriteEndElement(); //AppendChildElement xPathNavigator.AppendChildElement(xPathNavigator.Prefix, "pages", xPathNavigator.LookupNamespace(xPathNavigator.Prefix), "100"); Console.WriteLine(xPathNavigator.OuterXml); //选择书本 带有命名空间 XmlNamespaceManager xmlNamespaceManager = new(xPathNavigator.NameTable);//命名空间管理 xmlNamespaceManager.AddNamespace("bk", "http://www.contoso.com/books");//添加命名空间 XPathExpression xPathExpression =XPathExpression.Compile("descendant::bk:book[bk:author/bk:last-name = 'len']");//新建表达子 xPathExpression.SetContext(xmlNamespaceManager);//将命名空间和表达式关联 XPathNodeIterator items= xPathNavigator.Select(xPathExpression); do { //clone 一本书 XPathNavigator item = items.Current; Console.WriteLine("book title:{0}", item.Value); Console.WriteLine($" Count:{items.Count} Current:{items.Current} CurrentPosition:{items.CurrentPosition}"); //删除 一本书 items.Current.DeleteSelf(); } while (items.MoveNext()); //删除范围之内的书 xPathNavigator.MoveToRoot(); XPathNavigator first = xPathNavigator.SelectSingleNode("descendant::bk:book[1]", xmlNamespaceManager); XPathNavigator last = xPathNavigator.SelectSingleNode("//bk:book[2]", xmlNamespaceManager); xPathNavigator.MoveTo(first); xPathNavigator.DeleteRange(last); Console.Clear(); Console.WriteLine(xPathNavigator.OuterXml); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号