【C# XML 】开篇
内容来源:https://www.runoob.com/xml/xml-dtd.html
https://www.runoob.com/dtd/dtd-building.html
https://www.w3school.com.cn/xml/xml_editors.asp
XML学习框架
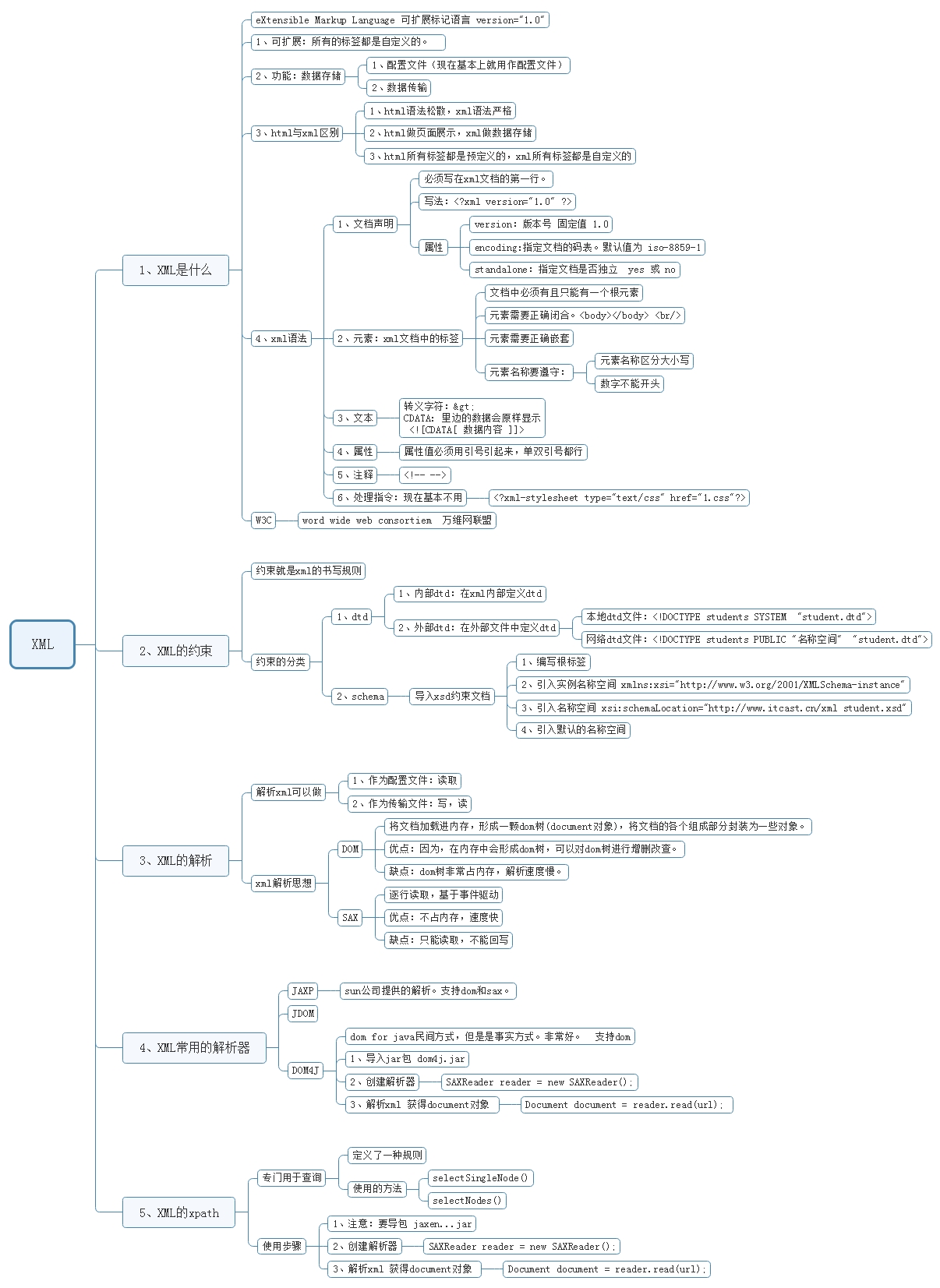
- XML 教程
- XML - 首页
- XML - 概述
- XML - 语法 Syntax
- XML - 文档 Documents
- XML - 声明 Declaration
- XML - 标记 Tag
- XML - 元素 Elements
- XML - 属性 Attributes
- XML - 注释 Comments
- XML - 字符实体 Character Entities
- XML - CDATA Sections
- XML - 空格 White Spaces
- XML - 处理指令 Processing
- XML - 编码 Encoding
- XML - 验证 Validation
基础概念
学习xml之前必须了解以下基础概念
SGML/XML有着陡峭的学习曲线,主要是因为一开始就要面对铺天盖地的新概念。学习DocBook,虽然并不需要对SGML/XML的所有概念都去透彻了解,但是需要掌握的也仍是够怕人的。下面的这些概念都熟悉么?如果答案是肯定的,那么你可以轻松的跳过这一章。
-
什么是标记语言?
传统意义上的标记(markup),我们都应该不会陌生。当我们还在读书的时候,老师改过的试卷,经常是满篇的红色的醒目的对号、错号、问号、波浪线,或者意味深长的评语,这些都是标记。广义上来说,一篇文章中的标点符号、空格也都可以称作是标记。看看韩愈是怎么说的,“句读之不知,惑之不解也”,就是这些语法标记对于帮助我们读懂文章,实在是太重要了。
标记语言(markup language),则特指用一系列约定好的标记来对电子文档进行标记,来实现对电子文档的语义、结构、格式的定义。这些标记必须能够和容易的和内容相区分,易于识别。标记语言必须定义什么样的标记是允许的,什么样的标记是必须的,标记是如何与文档的内容向区分的,以及标记的含义是什么?
-
什么是SGML?
标准通用标记语言(Standard Generalized Markup Language ,SGML),它是用来描述电子文档标记的国际标准,SGML 通过这些标记来描述文档结构,以便于存储、提取、处理文档中的数据。更准确地说,SGML 是一种元语言——关于语言的语言。为我们熟知的HTML就是源自SGML的一种语言,或者说方言。
-
什么是元素?
元素(Elements),就是SGML/XML文档中的具有一定结构的文字片断,是标记语言的基本组成部分。大多数元素的开头和结尾分别由一对相匹配的起始标签和结束标签构成,例如:HTML中的段落标记“<p>”和“</p>”和所标记的内容构成了一个段落元素。也有一些元素可以是空标签,没有结束标签和它相匹配,就像HTML中的断行标签“<br>”。
还要说明的是,不同类型的元素被赋予了不同的名称,但SGML本身并不关心这些元素的含义,而是关心这些元素的语法、相互之间的嵌套等。具体对这些元素的理解,则交给应用程序去完成,这就如同不同浏览器对于同一个网页可能有不同的表现形式。
-
什么是实体?
实体(Entities),就是一个被命名了的标记数据块,可以是一个字符串,也可以是一个完整的文件。实体可以包含已析(parsed)数据或未析(unparsed)数据。已析数据由字符组成,其中一些字符组成字符数据,另一些字符组成标记。未析数据则是那些不进行语法解析的数据,如图形文件等。
引用一个已经定义的实体的格式为:&实体名称;,即在实体名称前面加上“&”符号,在实体名称后面加上分号“;”。如HTML中的“<” 即代表小于号“<”。
-
什么是DTD?
SGML引入了文档类型的概念,并由此引入了文档类型定义(Document Type Definition: DTD)。文档按照其内容和结构可能分属于不同的类,如数学家能够用文档来记录数学公式,化学家用SGML文档来描述分子结构式,DocBook被用来撰写文档,等等,这些都是不同的文档类型的例子。
每种不同类型的文档,遵守各自的DTD规范。例如,一个DocBook文档,需要包含一个标题、作者信息、摘要、和由段落组成的文章内容。而缺少标题的文档,便不符合DocBook的DTD,不是合格的DocBook文档。具有标题,但是标题放在了正文的最后,也不符合DocBook DTD,也不是合格的DocBook文档。
文档类型定义 (DTD) 实际上就是一套关于标记符的语法规则,它包含了对元素的定义,指出可以在文档中使用哪些标记符, 它们应该按什么次序出现, 哪些标记符可以出现于其它标记符中, 哪些标记符有属性, 等等。属于某种类型的文档,可以通过一个应用程序来解析,检查是否所有的元素都被定义以及元素出现的次序是否正确。属于同一种类别的文档可以按照一致的方式来处理。
并不存在一个通用的DTD,想使用SGML/XML进行数据交换的行业或组织可以定义它们自己的DTD。HTML,DocBook都仅仅是DTD的一种,SGML的一个实例。
我们所熟知的HTML是SGML的一个实例,它的DTD作为标准被固定下来,因此,HTML不能作为定义其它置标语言的元语言。而目前的热点XML则是SGML的一个子集,严格地讲,XML也还是SGML。与HTML不同的是,XML有DTD,因而也可以象SGML那样,作为元语言,来定义其它文件系统,或称其它标记语言。
-
XML 命名空间(XML Namespaces)
【C# XML 】Namespaces ( xml命名空间) 和 xmlns 属性
【C# XML 】 命名空间和 XML Schema(xml架构也叫xml模式)
XML_介绍
可扩展标记语言(Extensible Markup Language,XML)XML里的X是个通配符,用做不同的地方就叫不同的名字,比如XHTML、YAML、MathML。。。,XML的产生就是为了简化SGML,XML规范的内容甚至不到SGML的十分之一,XML的简洁可见一斑。它是标准通用标记语言(Standard Generic Markup Language,SGML)的一个子集。
HTML和XML同样衍生于SGML:XML可以被认为是SGML的一个子集,而HTML是SGML的一个应用。SGML/XML则作为元语言,则可以定义出无数新的标记语言,如DocBook即是一种。
XML 没什么特别的。它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理 XML。
不过,能够读懂 XML 的应用程序可以有针对性地处理 XML 的标签。标签的功能性意义依赖于应用程序的特性。
XML 被设计用来结构化存储以及传输信息。XML 是独立于软件和硬件的信息传输工具。
XML 的基本格式是标准化的,所以如果您跨系统或平台共享或传输 XML ,无论是在本地还是在互联网上,接收方仍然可以根据标准化的 XML 语法解析数据。
SGML:Standard Generalized Markup Language(标准通用标记语言)是现时常用的超文本格式的最高层次标准,是可以定义标记语言的元语言,甚至可以定义不必采用< >的常规方式。由于它的复杂,因而难以普及。
XML:Extensible Markup Language(可扩展标记语言) XML的产生就是为了简化SGML。html:HTML是SGML的实例应用,Html 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如 <p>、<h1> 等等)。html5 不在基于SGML
有许多基于 XML 的语言;一些示例是 XHTML, MathML, SVG, XUL, XBL, RSS, 和 RDF。你也可以创建自己的。
XML分类
XML分为:XML Schema和Xml实列文件
XML Schema(模式|框架):用于定义框架,一套元素的约束规范;还可以定义新的数据类型;或者定义一套新的框架语言
Xml实列文件:普通xml文件,可以应用框架约束,也可以引用框架约束。
XML处理器
可以读取和处理XML文档的任何程序被称为XML处理器。
XML处理器被划分为验证或无验证类型,这取决于他们是否检查XML文档的有效性。在发现一个有效性的错误处理器必须能够汇报,但可继续进行正常的处理.
一些验证解析器 : xml4c (IBM, in C++), xml4j (IBM, in Java), MSXML (Microsoft,
in Java), TclXML (TCL), xmlproc (Python), XML::Parser (Perl), Java
Project X (Sun, in Java).
一些非验证解析器 : OpenXML (Java), Lark (Java), xp (Java), AElfred (Java), expat (C), XParse (JavaScript), xmllib
设计规则的标准
判定一个 XML 文档正确的标准是:
- 文档必须是一个格式良好的文档。
- 文档遵循 XML 所有的语法规则并且有效。
- 文档遵循特定语义的规则,这些规则通常规定在 XML 或 DTD 规范中(Document Type Definition (en-US))。
良好的 XML 文档
我们把符合 XML 语法的文档称为形式良好的 XML 文档,比如:
- XML 文档必须有根元素
- XML 文档必须有关闭标签
- XML 标签对大小写敏感
- XML 元素必须被正确的嵌套
- XML 属性必须加引号
一个 良好的 XML 文档实例
XML 文档使用简单的具有自我描述性的语法:
<?xml version="1.0" encoding="UTF-8"?> <note> <to>Tove</to> <from>Jani</from> <heading>Reminder</heading> <body>Don't forget me this weekend!</body> </note>
XML 语法
- XML 文档声明(可选)
- XML 文档必须有根元素
- 所有的 XML 元素都必须有一个关闭标签
- XML 标签对大小写敏感
- XML 必须正确嵌套
- XML 属性值必须加引号
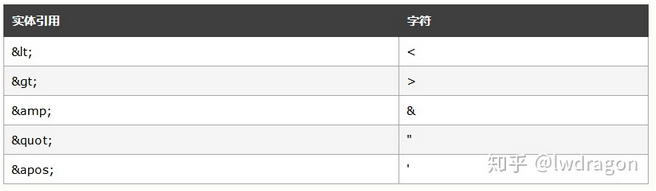
- 实体引用
- XML 中的注释
- 在 XML 中,空格会被保留
- XML 以 LF 存储换行
XML 语义
通过xml schemas 和DTD来定义。
XML元素语法:
名称中可以包含字母、数字或者其他字符;
名称不能以数字开头;
不能以XML/xml/Xml…开头;
名称中不能含空格;
名称中不能含冒号(注:冒号留给命名空间使用)。
XML 用于创建新的 Internet 语言
很多新的 Internet 语言是通过 XML 创建的:
其中的例子包括:
- XHTML - 最新的 HTML 版本
- WSDL - 用于描述可用的 web service
- WAP 和 WML - 用于手持设备的标记语言
- RSS - 用于 RSS feed 的语言
- RDF(博客园的 xml文档) 和 OWL - 用于描述资源和本体
- SMIL - 用于描述针针对 web 的多媒体
通过 XML 您可以发明自己的标签
上面实例中的标签没有在任何 XML 标准中定义过(比如 <to> 和 <from>)。这些标签是由 XML 文档的创作者发明的。
这是因为 XML 语言没有预定义的标签。
HTML 中使用的标签都是预定义的。HTML 文档只能使用在 HTML 标准中定义过的标签(如 <p>、<h1> 等等)。
XML 允许创作者定义自己的标签和自己的文档结构。
第一行是 XML 声明。它定义 XML 的版本(1.0)和所使用的编码(UTF-8 : 万国码, 可显示各种语言)。
下一行描述文档的根元素(像在说:"本文档是一个便签"):
<note>
接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body):
最后一行定义根元素的结尾:
</note>
XML 文档形成一种树结构
XML 文档必须包含根元素。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
![]()
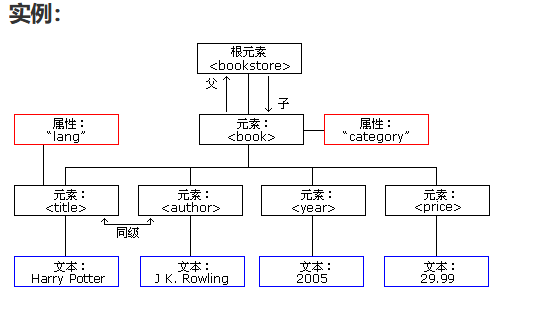
XML 文档的构成:
SGML/XML语法
- 处理指令(可选)
- 文件类型声明(可选)
- 标记和元素
- 属性
- 实体和实体引用(可选)
- 标记片段(CDTD)(可选)
- 注释(可选)
- 处理指令PI(可选)
- 应用css (可选)
【处理指令】
处理指令是向SGML/XML处理程序传递的特殊指令。例如:xml处理指令,必须作为XML文件的第一行存在。(可选)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>//在许多时候即使不包含文档声明,XML也可以被正常使用,但是这是不符合标准的,存在风险,因此强烈推荐大家在书写XML时写上文档声明。
version属性:有1.1和1.0两个版本。版本号对命名空间 xmlns用法用影响
encoding属性:文档解析编码
standalone属性:standalone表示该xml是不是独立的,如果是yes,则表示这个XML文档时独立的,不能引用外部的DTD规范文件;如果是no,则该XML文档不是独立的,表示可以用外部的DTD规范文档。其中no是默认值。
//对应C#
protected internal XmlDeclaration (string version, string? encoding, string? standalone, System.Xml.XmlDocument doc);
【文档类型声明】
文档类型声明位于SGML/XML文件头部,
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE 根元素标记名[
<!--实体声明-->
]>
主要有如下作用:
指定文件的根元素。
指出文件的外部DTD。
内部DTD,为文件定义元素、属性和实体等。
xml验证方式有两种XML Schema(新)和XML DTD(旧)两种方式
XML 如果基于DTD框架约束,所以必须告诉浏览器 文档采用哪种框架约束。
XML Schema:采用的是命名空间,所以不需要<--!DOCTYPE-->。
schema约束和dtd约束的区别:
⑴XML Schema符合XML语法结构。
⑵DOM、SAX等XML API很容易解析出XML Schema文档中的内容。
⑶XML Schema支持名称空间支 。
⑷XML Schema比XML DTD支持更多的数据类型,并支持用户自定义新的数据类型。
⑸XML Schema定义约束的能力非常强大,可以对XML实例文档作出细致的语义限制。
⑹XML Schema不能像DTD一样定义实体,比DTD更复杂,但Xml Schema现在已是w3c组织的标准,它正逐步取代DTD
有关DTD的内容请查看
如下的例子即是本书的文档类型声明:
<!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook V4.2b1//EN" [ <!ENTITY author "<ulink url='mailto:johnson@worldhello.net'>Johnson</ulink>"> <!ENTITY orgname "<ulink url='http://www.worldhello.net'>worldhello.net</ulink>"> <!ENTITY chap1 system "chap1.sgml"> <!ENTITY chap2 system "chap2.sgml"> <!ENTITY chap3 system "chap3.sgml"> <!ENTITY chap4 system "chap4.sgml"> <!ENTITY chap5 system "chap5.sgml"> <!ENTITY chap6 system "chap6.sgml"> <!ENTITY chap7 system "chap7.sgml"> <!ENTITY chap8 system "chap8.sgml"> <!ENTITY chap9 system "chap9.sgml"> <!ENTITY chap10 system "chap10.sgml"> <!ENTITY appendix system "appendix.sgml"> ]>
【标记和元素】
标记(Tag)用来描述元素,是语法中最显而易见的组成部分。
元素(Elements),这一术语,和标记的概念密不可分。它指的是SGML/XML文档中的具有一定结构的文字片断,大多数元素的开头和结尾分别由一对相匹配的起始标签和结束标签构成,也有一些元素可以是空标签,没有结束标签和它相匹配,就像HTML中的断行标签“<br>”。<title>Harry Potter</title> XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。一个元素可以包含:其他元素\ 文本\属性\或混合以上所有...XML 命名规则
【实体】
实体叫ENTITY,实体的作用是避免重复输入。作用相当于宏或者变量。就是一个被命名了的标记数据块,可以是一个字符串,也可以是一个完整的文件。实体可以包含已析(parsed)数据或未析(unparsed)数据。已析数据由字符组成,其中一些字符组成字符数据,另一些字符组成标记。未析数据则是那些不进行语法解析的数据,如图形文件等。
引用一个已经定义的实体的格式为:&实体名称;,即在实体名称前面加上“&”符号,在实体名称后面加上分号“;”。如HTML中的“<” 即代表小于号“<”。
//定义实体
例如:<!ENTITY writer "entity-value"><!ENTITY entity-name "entity-value"> //xml文档内部<!ENTITY entity-name SYSTEM "URI/URL"> //xml文档外部
//引用实体
&writer; <author>&writer;//应用writer变量 ©right;</author>
【属性】
XML 属性必须加引号
属性值必须被引号包围,不过单引号和双引号均可使用。比如一个人的性别,person 标签可以这样写:
<person sex="female">
或者这样也可以:
<person sex='female'>
注释:如果属性值本身包含双引号,那么有必要使用单引号包围它,就像这个例子:
<gangster name='George "Shotgun" Ziegler'>
或者可以使用实体引用:
<gangster name="George "Shotgun" Ziegler">
XML 元素 vs. 属性
请看这些例子:
<person sex="female"> <firstname>Anna</firstname> <lastname>Smith</lastname> </person> <person> <sex>female</sex> <firstname>Anna</firstname> <lastname>Smith</lastname> </person>
在第一个例子中,sex 是一个属性。在第二个例子中,sex 则是一个子元素。两个例子均可提供相同的信息。
避免 XML 属性?
因使用属性而引起的一些问题:
- 属性无法包含多重的值(元素可以)
- 属性无法描述树结构(元素可以)
- 属性不易扩展(为未来的变化)
- 属性难以阅读和维护
请尽量使用元素来描述数据。而仅仅使用属性来提供与数据无关的信息。
不要做这样的蠢事(这不是 XML 应该被使用的方式):
<note day="08" month="08" year="2008" to="George" from="John" heading="Reminder" body="Don't forget the meeting!"> </not
没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用子元素。我的经验是在 HTML 中,属性用起来很便利,但是在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用子元素吧。
【 CDATA(character data)片段(可选)】
CDATA片段,即是未解析字符数据片段。扩在CDATA片段中的内容,将不被XML解析器处理,而直接提供给应用程序。CDATA 是不会被解析器解析的文本(字符串)。在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。用来告诉xml解析器(eg.浏览器),这部分内容不用解析,是给其他程序用的,比如js代码等。
<![CDATA[
if(i<10){
System.out.println("i<10");
}
在范围你出现>, <, &, ', " 以及实体等特殊字符 都没有特殊意义。就是普通的字符
]]>
如果不用CDATA片段,想在文中显示上例中的文件类型声名,需要用如下方法表示,非常的不直观。
<screen> <!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook V4.2b1//EN" [ <!ENTITY author "<ulink url='mailto:johnson@worldhello.net'>Johnson</ulink>"> <!ENTITY orgname "<ulink url='http://www.worldhello.net'>worldhello.net</ulink>"> <!ENTITY chap1 system "chap1.sgml"> <!ENTITY chap2 system "chap2.sgml"> <!ENTITY chap3 system "chap3.sgml"> <!ENTITY chap4 system "chap4.sgml"> <!ENTITY chap5 system "chap5.sgml"> <!ENTITY chap6 system "chap6.sgml"> <!ENTITY chap7 system "chap7.sgml"> <!ENTITY chap8 system "chap8.sgml"> <!ENTITY chap9 system "chap9.sgml"> <!ENTITY chap10 system "chap10.sgml"> <!ENTITY appendix system "appendix.sgml"> ]> </screen>
但是采用CDATA段,就非常的简单而直观。
<screen> <![CDATA[ <!DOCTYPE article PUBLIC "-//OASIS//DTD DocBook V4.2b1//EN" [ <!ENTITY author "<ulink url='mailto:johnson@worldhello.net'>Johnson</ulink>"> <!ENTITY orgname "<ulink url='http://www.worldhello.net'>worldhello.net</ulink>"> <!ENTITY chap1 system "chap1.sgml"> <!ENTITY chap2 system "chap2.sgml"> <!ENTITY chap3 system "chap3.sgml"> <!ENTITY chap4 system "chap4.sgml"> <!ENTITY chap5 system "chap5.sgml"> <!ENTITY chap6 system "chap6.sgml"> <!ENTITY chap7 system "chap7.sgml"> <!ENTITY chap8 system "chap8.sgml"> <!ENTITY chap9 system "chap9.sgml"> <!ENTITY chap10 system "chap10.sgml"> <!ENTITY appendix system "appendix.sgml"> ]> ]]> </screen>
【PCDATA】
PCDATA(parsed character data )(可选):PCDATA 是会被解析器解析的文本(可以被xml解析的字符窜),解析器会检查这些文本中的实体以及标记 。#PCDATA 解析器将检查这些文本中的实体、标记
<!ELEMENT to (#PCDATA)>
<to> 在范围你出现>, <, &, ', "这5个特殊字符 都有其他意义,因此必须被转化成实体,还可以包含其他xml标签</to>
【注释】
<!-- 这是一端注释... --> 且序列- -不能出现在注释中。
注释(可选):<!-- 注释内容 -->
【处理指令PI】
处理指令用于XML解析器传递信息到应用程序。
语法:<?target instruction(指令)?>
PI必须以一个叫做目标的标识符开头,这个标识符遵从如同元素和属性一样的规则,目标是指令所指向的应用的名称,指令是传递给应用程序的信息。
其中:
target - 标识指令指向哪个应用程序。
instruction - 字符,描述了应用程序要处理的信息。
处理指令以特殊的 <? 标记开始,以 ?> 结尾。处理的内容在遇到字符串 ?> 时立即结束。
处理指令很少被使用。主要用于链接 XML 文档到样式表。下面是一个例子:
<?xml-stylesheet href="tutorialspointstyle.css" type="text/css"?>
这里,target 就是 xml-stylesheet。href="tutorialpointstyle.css" 和 type="text/css" 就是数据或者目标应用程序用将要用来处理给定 XML 文档的指令。
在开始标记<?后的第一个字符串xml-styesheet 叫做处理指令的目标,它必须标识要用到的应用程序,要注意的是对于其它的非W3C定义的处理指令不能以字符串XML和xml开头,其余的部分是传递给应用程序的字符数据,应用程序从处理指令中取得目标和数据,执行要求的动作。
处理指令的目标可以是要使用的程序的名字,或者是一个类似于xml-stylesheet这样的很多程序可以识别的通过标识符。不同的应用程序支持不同的处理指令,对于不认识的处理指令,大多数应用程序采取忽略的方式进行处理。对于自定义的处理指令,它通常都是由选定的某个应用程序进行处理。因为你所定义的这个处理指令,对于其它应用程序来说并不能识别,这时就会忽略的方式来处理。
【可以使用CSS】
实例XML 中使用
XML操作类
为什么使用 XML 编辑器?
当今,XML 是非常重要的技术,并且开发项目正在使用这些基于 XML 的技术:
-
用 XML Schema 定义 XML 的结构和数据类型
-
XML Schema 是一种基于 XML 的 DTD 替代。
不像 DTD,XML Schema 支持数据类型,且使用 XML 语法。
如果您想要学习更多有关
-
-
XSLT(XML 样式表语言转换)
-
XSLT 是 XML 文件的样式表语言。
通过使用 XSLT,可以把 XML 文档转换为其他格式,比如 XHTML。
如果您想要学习更多有关 XSLT 的知识,请访问我们的 XSLT 教程。
-
-
用 SOAP 来交换应用程序之间的 XML 数据
-
用 WSDL 来描述网络服务
-
用 RDF 来描述网络资源
-
用 XPath 和 XQuery 来访问 XML 数据
-
用 SMIL 来定义图形
-
XML DOM(Document Object Model)
XML DOM 定义了一种访问和处理 XML 文档的标准方式。
XML DOM 是平台和语言独立的,可用于任何编程语言,如 Java、JavaScript 和 VBScript。
如果您想要学习更多有关 DOM 的知识,请访问我们的 XML DOM 教程。
为了能够编写出无错的 XML 文档,您需要一款智能的 XML 编辑器!
XML 编辑器
专业的 XML 编辑器会帮助您编写无错的 XML 文档,根据某种 DTD 或者 schema 来验证 XML,以及强制您创建合法的 XML 结构。
XML 编辑器应该具有如下能力:
- 为开始标签自动添加结束标签
- 强制您编写合法的 XML
- 根据某种 DTD 来验证 XML
- 根据某种 Schema 来验证 XML
- 对您的 XML 语法进行代码的颜色化
推荐使用:vs code +xml tools插件
C#中XML操作命名空间
- XMLTextReader------提供以快速、单向、无缓冲的方式存取XML数据。(单向意味着你只能从前往后读取XML文件,而不能逆向读取), 使用 XmlReaderSettings 类和 Create 方法创建一个验证的 XML 读取器。
- XMLDocument------遵循W3C文档对象模型规范的一级和二级标准,实现XML数据随机的、有缓存的存取。一级水平包含了DOM的最基本的部分,而二级水平增加多种改进,包括增加了对名称空间和级连状图表(CSS)的支持。
- Net中的XmlDocument类。它支持并扩展了W3C XML DOM标准。可使用此类在文档中加载、验证、编辑、添加和放置 XML。
它将整个XML文档都先装载进内存中,然后再对XML文档进行操作,所以如果XML文档内容过大,不建议使用XmlDocument类,因为会消耗过多内存。
对于很大的XML文档,可以使用XmlReader类来读取。因为XmlReader使用Steam(流)来读取文件,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作,所以不会对内存造成太大的消耗。
- Net中的XmlDocument类。它支持并扩展了W3C XML DOM标准。可使用此类在文档中加载、验证、编辑、添加和放置 XML。
- XMLTextWriter------生成遵循 W3C XML 1.0 规范的XML文件。从 .NET Framework 2.0 开始,建议改用 XmlReader 类。
- XMLValidatingReader------ .net 2.0开始已经过时
System.Xml.Serialization
System.Xml.XPath XPathNavigator类包含移动和选择XML所需元素的所有方法。和 XmlDocument 类的工作方式很相似。它把所有信息都加载到内存中并允许你在节点中移动。关键的区别是它使用基于游标的方式允许你使用 MoveToNext()之类的方法在 XML 数据间移动。每次 XPathNavigator 类只能定位到一个节点。它提供比 XML DOM 稍快、更有效的模型,并增强了一些搜索功能,但不能修改或保存 XML 。
System.Xml.Schema 框架设置
访问XML文件的两个基本模型和一个C#特有的模型

1)DOM模型(XML Doc的Xpath)----【C# XML】XmlDocument 类
使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性加载整个文档到内存中,对于大型的文档,这会造成资源问题。
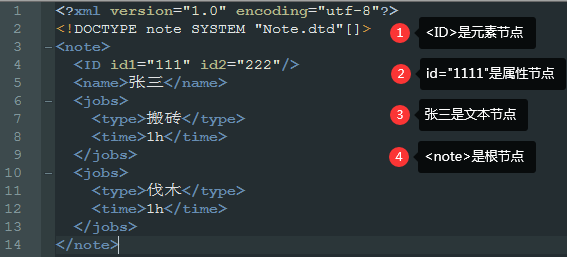
根据 DOM,XML 文档中的每个成分都是一个节点。关于节点(非常重要)
- 整个文档是一个文档节点
- 每个 XML 标签是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释属于注释节点
![]()
2)流模型(Stream的XMLReader)
流模型很好的解决了这个问题,因为它对XML文件的访问采用的是流的概念,也就是说,任何时候在内存中只有当前节点,但它也有它的不足,它是只读的,仅向前的,不能在文档中执行向后导航操作。虽然是各有千秋,但我们也可以在程序中两者并用实现优劣互补。
在C#中,使用SAX进行解析的类为XmlReader, XmlWriter,这两个类都是抽象类,由具体的子类来实现相关的功能。
3)C#特有的Linq to Xml读取复杂xml(带命名空间)
处理内存中 XML 数据有三种方式
使用 DOM 模型处理 XML 数据(读写)
使用 XPath 数据模型处理 XML 数据(只读 快)
使用 LINQ to XML 处理 XML 数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号