
【C# 序列化】 ReadOnlySequence<T>
转自:https://www.cnblogs.com/TianFang/p/10084049.html
序列(Sequences)
例如,(C,Y,R)是一个字母的序列:顺序是C第一,Y第二,R第三。序列可以是有限的(就像前面这个例子),也可以是无限的,就像所有正偶数的序列(2,4,6,...)。有限序列包含空序列(),它没有元素。序列中的元素也称为项,项的个数(可能是无限的)称为序列的长度。
序列写作(a1,a2, ...)。简单起见,也可以用符号(an)。
有限的序列称为列表(lists)。有限的字符串序列称为字符串(string)。无限的序列称为字符串流(stream)。
ReadOnlySequenceSegment<T>
在我们读取数据的过程,很多时候会出现如下场景:
-
不知道数据实际大小
-
一次性申请大量内存开销太大
此时我们往往会使用动态内存的方案,通过链表的方式串联起来,从而形成逻辑意义上的数据流。如下图所示:

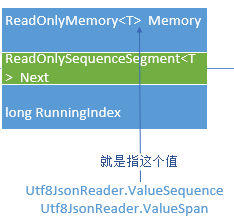
ReadOnlySequenceSegment<T>就是这样一个表示数据流节点的内存模型,它是一个抽象类,包含如下三个元素:
-
1 public ReadOnlyMemory<T> Memory { get; protected set; } 2 public ReadOnlySequenceSegment<T>? Next { get; protected set; } 3 public long RunningIndex { get; protected set; }
- Memory:表示这个链表节点下的内存数据,也就是上面的Memory1、2、3
- Next:就是指向的下一个节点
- RunningIndex:指当前节点之前的节点的数据之和,比如Memory1里有1个字节、Memeory2里有2个字节,那么Memory3对应节点的RunningIndex就是3
这玩意是个抽象类,不过暂时可以不关心,因为我们通常开发时都可以从某个方法的参数获得ReadOnlySequenceSegment<T>(下面马上会说),而它里面就保存着这个链表的收尾两个节点。
这里重点记住:
- ReadOnlySequenceSegment里面存储的ReadOnlyMemory<T>(理解上约等于byte[])
- 多个ReadOnlySequenceSegment可以组成一个链表,从逻辑上表示一个完整的数据,ReadOnlySequenceSegment只是其中一个节点
其中Memory和Next还比较容易理解,典型的链表结构。主要难理解的是RunningIndex,他表示该节点在数据流中的Memory起始索引。
一般的来讲,某节点的RunningIndex为其上一个节点的RunningIndex + Memory.Length。加上RunningIndex估计主要是为了快速索引的。
例如:对于如下3快内存 100byte, 200byte, 300byte组成的链表,其RunningIndex分别是0, 100, 200。
另外,在实际的使用过程中,往往是不停的释放链表头部的节点,并且在尾部添加新节点。 RunningIndex表示的索引一般是逻辑意义上的索引,在释放头节点时,一般不用更新其子节点以及后续节点的RunningIndex。
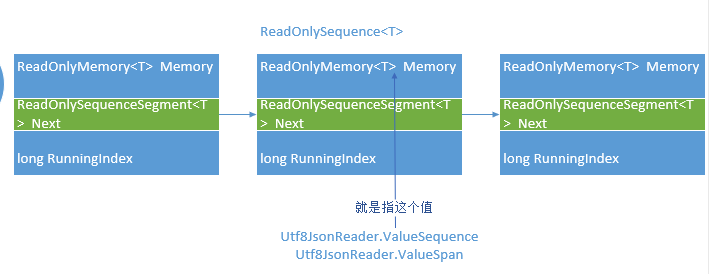
ReadOnlySequence<T>
ReadOnlySequenceSegment<T>虽然能解决我们的动态内存的申请和释放问题,但它往往并不好用,因为很容易出现一段连续的数据被分割在多个节点的情况,在这段不连续的数据里进行查询是非常不便的。
为了解决这个问题,.net core中推出了一个视图类ReadOnlySequence<T>

ReadOnlySequence<T>由两个属性标记:
-
Start: 起始SequenceSegment以及起始索引
-
End: 结尾SequenceSegment以及结尾索引
可以通过foreach遍历各节点的Memory
var seq = new ReadOnlySequence<byte>();
foreach (ReadOnlyMemory<byte> memory in seq)
{
}
ReadOnlySequence的主要优势在于,它可以看成一段逻辑意义上的连续内存,常用的函数有:
-
Slice: 对视图数据切片
-
PositionOf: 查询元素的缩影
-
ToArray: 转换成数组
其中的ToArray涉及到大量的数据拷贝,需要谨慎使用。
另外.net core 3.0中还内置了一个SequenceReader,用起来是十分方便的:


private static ReadOnlySpan<byte> CRLF => new byte[] { (byte)'\r', (byte)'\n' };
public static void ReadLines(ReadOnlySequence<byte> sequence)
{
SequenceReader<byte> reader = new SequenceReader<byte>(sequence);
while (!reader.End)
{
if (!reader.TryReadToAny(out ReadOnlySpan<byte> line, CRLF, advancePastDelimiter: false))
{
// Couldn't find another delimiter
// ...
}
if (!reader.IsNext(CRLF, advancePast: true))
{
// Not a good CR/LF pair
// ...
}
// line is valid, process
ProcessLine(line);
}
}
关于.net core高性能编程中的Span<T>和Memory<T>网上资料很多,这里就不说了。今天一直在看ReadOnlySequenceSegment<T>和SequenceReader<T>,看得脑壳痛,本篇着重说说对ReadOnlySequenceSegment<T>的理解。
如果对Span<T>和Memory<T>不了解,可以暂时理解为byte[],最好先去搜下相关资料。缓冲区相关知识可以参考官方文档:https://docs.microsoft.com/zh-cn/dotnet/standard/io/buffers
内存片段ReadOnlySequenceSegment<T>
假设你已经了解了Memory<T>,它表示一段连续的内存,有时候我们读取一条数据,它可能并不是存在连续的内存中。
这个我理解得不是很准确,但总体来说就是我们一个完整的数据分成了多个内存片段,每个内存片段用Memory<byte>(你也可以暂时理解为byte[])表示,那么可以以链表的形式,从逻辑上来表示这段完整的数据。比如Memory1上有个next属性指向Memory2,同理Memory2上的next属性指向Memory3,这样的链表就能表示这段完整的数据了。
ReadOnlySequenceSegment<T>就是这样一个链表,3个核心属性定义如下:
1 public ReadOnlyMemory<T> Memory { get; protected set; }
2 public ReadOnlySequenceSegment<T>? Next { get; protected set; }
3 public long RunningIndex { get; protected set; }
- Memory:表示这个链表节点下的内存数据,也就是上面的Memory1、2、3
- Next:就是指向的下一个节点
- RunningIndex:指当前节点之前的节点的数据之和,比如Memory1里有1个字节、Memeory2里有2个字节,那么Memory3对应节点的RunningIndex就是3
这玩意是个抽象类,不过暂时可以不关心,因为我们通常开发时都可以从某个方法的参数获得ReadOnlySequenceSegment<T>(下面马上会说),而它里面就保存着这个链表的收尾两个节点。
这里重点记住:
- ReadOnlySequenceSegment里面存储的ReadOnlyMemory<T>(理解上约等于byte[])
- 多个ReadOnlySequenceSegment可以组成一个链表,从逻辑上表示一个完整的数据,ReadOnlySequenceSegment只是其中一个节点
内存片段容器ReadOnlySequence<T>
上面说的这个内存片段链表其实已经可以从逻辑上表示一段完整的数据了,但是ReadOnlySequenceSegment<T>只是这个链表中的一个节点,它能提供的属性、方法等api只能针对自己这个节点,所以需要一个容器来容纳整个链表,以提供对此连续内存片段操作的api
这里说的容器不是很准确,因为ReadOnlySequence只是存储了整个链表的首位节点,但是由于是链表,其实只要知道首节点,就可以通过Next递归获得整个链表的所有节点,因此我这里把它称为容器
下面引用官方文档的一张图
绿色框中有3段蓝色块,我们可以理解为是链表中的一个节点(ReadOnlySequenceSegment),由于这个节点内部重要的就是保存着具体的数据Memory<T>,所以我们可以简单的看成是3个Memory<T>,这里便于理解,也可以看成是3个byte[]。
根据绿色部分的3个不连续的内存片段,可以生成一个表示逻辑上连续的内存片段集合ReadOnlySequence,这个ReadOnlySequence包含3个Memory<T>,其中首位的片段只取原始片段的一部分。下面我根据理解再来一张图
注:上面简写的16进制,A=0x0A
连续内存片段中的索引SequencePosition
只要知道一个数据在哪个片段中,并且知道它在这个片段中的哪个位置,就能表示一个具体的索引了。
但特别注意这个索引是针对原始链表来说的,也就是上面绿色快的部分,比如图片中的“4”在第1段的索引3的位置;“A”,在第2段的索引2处。这种情况没有办法用单个数字来表示索引,因此单独定义了SequencePosition来表示索引。
ReadOnlySequence的api
- 构造函数ReadOnlySequence(ReadOnlySequenceSegment<T> startSegment,
int startIndex, ReadOnlySequenceSegment<T> endSegment, int
endIndex)
- startSegment:链表的首个节点
- startIndex:首个节点不一定完全加入到ReadOnlySequence,此参数表示从第几个值开始
- endSegment:链表的尾节点
- endIndex:尾节点也不一定完全加入ReadOnlySequence,此参数表示要加入的索引+1
- 按上图所示,代码应该这样:new ReadOnlySequence(片段1,3,片段3,1); 注意最后一个参数是1,可以简单理解为在尾节点取前几个值加入到ReadOnlySequence
- End:就是最后一个片段的最后一个数据的索引对象,就是图片中的片段3索引1
- Start:第一个片段的索引,片段1,索引2
- Length:ReadOnlySequence包含的值的长度,按图中就是4 5 6 ....D F 2 长度为10
- GetPosition(int index):获取第几个值的索引对象,比如GetPosition(0),那就是黄色块的0为4,它所处于绿色块的索引为:片段1,索引2;GetPosition(4),那就是黄色块的2,所处绿色快的片段2,索引1
- PositionOf(T value):查早某个值在这个序列中所处的索引,比如PositionOf(4),那就是在黄色块的片段1的索引0处,最终结果就是绿色块片段1的索引3处
- Slice():从这个连续内存片段集合中指定索引处开始,取一段数据,返回的是一个新的ReadOnlySequence。有几个重载,比较容易猜到它的意义
-
bool TryGet(ref SequencePosition position, out ReadOnlyMemory<T> memory, bool advance = true)
尝试从指定索引处开始读取,所指定的索引处所在片段还有剩余数据,则本次读取这些剩余数据,否则读取下一个片段的数据。最终若读取成功,则返回true,且将读取到的数据赋值给memory参数。advance为true时,position将被直接赋值为下一个片段的索引0处。理解这个再看官方文档那个循环就容易了。
主要api就这几个。
SequenceReader<T>
.net core 3.x提供了SequenceReader来帮我们更容易的读取ReadOnlySequence的数据。我们只要理解一点就能很容易的理解此对象。先看看下图
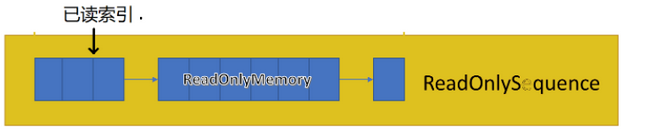
这里我取名叫“已读索引”,就是表示已经读取过了。SequenceReader.Advance(2)就是将这个索引往后移2位,SequenceReader.Rewind(1)则表示将这个索引前移1位。
以图中为例,若此时调用TryRead方法,则将获取第3个位的数据,并且已读索引向后移1位
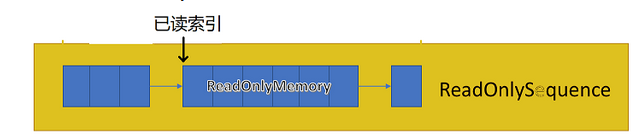
理解这个再看官方文档就简单了,举几个例子
- Consumed:表示已经读取了多数个数据,也就是“已读索引”之前有几个数据
- Remaining:表示整个序列还剩几个数据,也就是“已读索引”之后有几个数据
- Advance(Int64):将“已读索引”移动到指定位置
- AdvancePast(T):将"已读索引"移动到指定值所在的位置
- TryRead(T):尝试从“已读索引”开始读取1个值,并将“已读索引”向后移动1位
- TryPeek(T):尝试从“已读索引”开始读取1个值,但不移动“已读索引”
- TryReadBigEndian():尝试从“已读索引”开始读取4个值,并将其转换位int类型的值,然后将“已读索引”向后移动4位
如何使用
用过System.IO.Pipelines的朋友就知道,ReadOnlySequence在该库中是非常好用的。但如果我们想创建一个ReadOnlySequence,发现并不是那么容易,因为:
-
ReadOnlySequence依赖于ReadOnlySequenceSegment
-
ReadOnlySequenceSegment是抽象类,需要自己继承
也就是说我们需要自己实现ReadOnlySequenceSegment<T>,然后再将其封装到ReadOnlySequence中,目前.net core中并没有内置实现可能是因为在高效内存管理的方案中并没有什么通用的解决方案吧。
如果我们要自己实现ReadOnlySequence,一般需要如下几个步骤:
-
继承ReadOnlySequenceSegment类,实现自己的SequenceSegment
-
在申请内存过程中,创建SequenceSegment,并将其挂成链表
-
使用数据时,在该链表中创建ReadOnlySequence
-
当SequenceSegment节点的内存使用完成的时候,从链表中接触该节点,并释放内存。
简单来说就是如下几种操作:
-
数据读取: 创建SequenceSegment
-
数据使用: 在SequenceSegment链表上创建ReadOnlySequence
-
使用完成: 释放SequenceSegment
如果要更进一步优化,在SequenceSegment中的内存申请和释放可以使用内存池。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号