【windows 操作系统】进程间通信(IPC)简述|无名管道和命名管道 消息队列、信号量、共享存储、Socket、Streams等
一、进程间通信简述
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess
Communication),即指在不同进程之间传播或交换信息。
IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。其中
Socket和Streams支持不同主机上的两个进程IPC。IPC资源必须删除,否则不会⾃动清除,除⾮重启,所以system V
IPC资源的⽣命周期随内核而共生。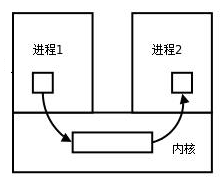
进程间通信模型
进程间通信的本质:让两个不同的进程看到同一份资源(该资源通常由操作系统直接或间接提供)
进程间通信目的:
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享有同样的资源
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如:进程终止时要通知父进程)
进程控制:有些进程希望完全控制另一个进程的运行(如:Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
IPC的分类:
管道
匿名管道
命名管道
System V IPC
System V 消息队列
System V 共享存储
System V 信号量
POSIX IPC
消息队列
共享内存
信号量
互斥量
条件变量
读写锁
其它概念引入
临界资源:多道程序系统中存在许多进程,它们共享各种资源,然而有很多资源一次只能供一个进程使用。一次仅允许一个进程使用的资源称为临界资源。许多物理设备都属于临界资源,如输入机、打印机、磁带机等。
临界区:每个进程中访问临界资源的那段代码称为临界区。
互斥:任何一个时刻,只允许有一个进程进入临界资源进行资源访问,在其资源访问期间其他进程不得访问。
同步:在保证安全的前提条件下,进程按照特定的顺序访问临界资源。
原子性:指一个操作是不可中断的,要么执行成功要么执行失败,不会有第三态。
二、进程间通信的7种方式
第一类:传统的Unix通信机制
1. 管道/匿名管道(pipe)
管道,一般指匿名管道,是 UNIX 系统中 IPC最古老的形式。
通常把从一个进程链接到另一个进程的一个数据流成为一个“管道”。管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程)。
单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。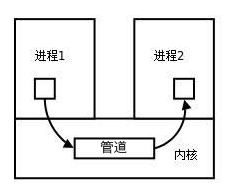
进程间管道通信模型
管道的实质:
管道的实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据,管道一端的进程顺序的将数据写入缓冲区,另一端的进程则顺序的读出数据。
该缓冲区可以看做是一个循环队列,读和写的位置都是自动增长的,不能随意改变,一个数据只能被读一次,读出来以后在缓冲区就不复存在了。
当缓冲区读空或者写满时,有一定的规则控制相应的读进程或者写进程进入等待队列,当空的缓冲区有新数据写入或者满的缓冲区有数据读出来时,就唤醒等待队列中的进程继续读写。
管道的局限:
管道的主要局限性正体现在它的特点上:
只支持单向数据流;
只能用于具有亲缘关系的进程之间;
没有名字;
管道的缓冲区是有限的(管道制存在于内存中,在管道创建时,为缓冲区分配一个页面大小);
管道所传送的是无格式字节流,这就要求管道的读出方和写入方必须事先约定好数据的格式,比如多少字节算作一个消息(或命令、或记录)等等;
特点:
管道是一种特殊的文件,对于它的读写可以使用普通的read、write 等函数。但是它不同于普通文件,它不属于其他任何文件系统,且只存在于内存中。
管道是半双工的,只允许单向通信(即数据只能向一个方向上流动),具有固定的读端和写端;需要双方通信时,需要建立起两个管道
面向字节流
一般,内核会对管道操作进行同步与互斥(即管道自带互斥和同步机制)
进程退出,管道释放,所以管道的生命周期随通信双方的进程
匿名管道
只能用于具有亲缘关系的进程之间的通信,常用于父子进程或者兄弟、爷孙进程之间通信。
子进程继承父进程的文件描述符、数据、代码等。
子进程不可直接继承父进程的时间片,由父进程分配(时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片,即该进程允许运行的时间,使各个程序从表面上看是同时进行的。)
原型
#include <unistd.h>
int pipe(int fd[2]);
功能:创建一个匿名管道
参数:fd—>文件描述符,其中fd[0]表示读端,fd[1]表示写端
返回值:若成功返回0,失败返回错误代码
建立一个管道时,会创建两个文件描述符,读端和写段,如下图: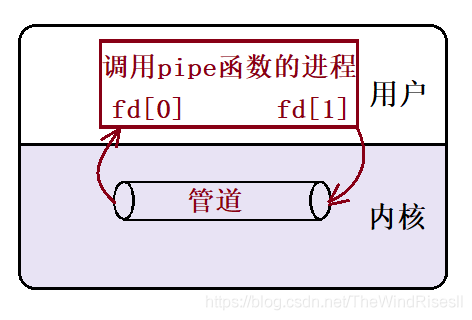
用fork共享管道原理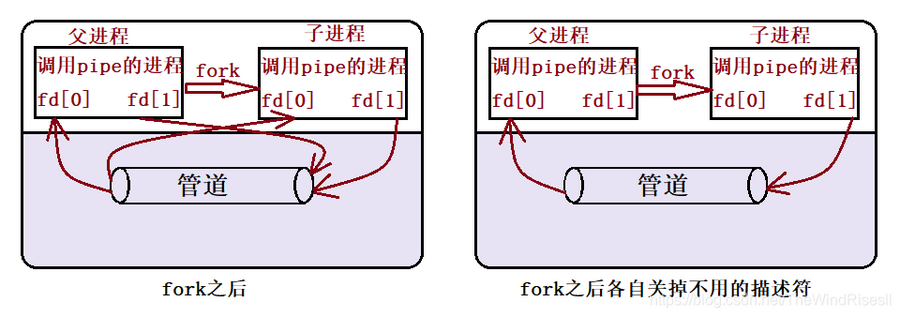
若要数据流从父进程流向子进程,则关闭父进程的读端(fd[0])与子进程的写端(fd[1]);反之,则可以使数据流从子进程流向父进程。
#include<stdio.h>
#include<unistd.h>
int main(){
int fd[2]; // 两个文件描述符
pid_t pid;
char buf[20];
if(pipe(fd) < 0) // 创建管道
printf("Create Pipe Error!\n");
if((pid = fork()) < 0) // 创建子进程
printf("Fork Error!\n");
else if(pid > 0){ // 父进程
close(fd[0]); // 关闭读端
write(fd[1], "hello world\n", 12);
}else{
close(fd[1]); // 关闭写端
read(fd[0], buf, 20);
printf("%s", buf);
}
return 0;
}
2. 命名管道(FIFO)
匿名管道,由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道(FIFO)。
有名管道不同于匿名管道之处在于它提供了一个路径名与之关联,以有名管道的文件形式存在于文件系统中,这样,即使与有名管道的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过有名管道相互通信,因此,通过有名管道不相关的进程也能交换数据。值的注意的是,有名管道严格遵循先进先出(first
in first
out),对匿名管道及有名管道的读总是从开始处返回数据,对它们的写则把数据添加到末尾。它们不支持诸如lseek()等文件定位操作。有名管道的名字存在于文件系统中,内容存放在内存中。
匿名管道和有名管道总结:
(1)管道是特殊类型的文件,在满足先入先出的原则条件下可以进行读写,但不能进行定位读写。
(2)匿名管道是单向的,只能在有亲缘关系的进程间通信;有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
(3)无名管道阻塞问题:无名管道无需显示打开,创建时直接返回文件描述符,在读写时需要确定对方的存在,否则将退出。如果当前进程向无名管道的一端写数据,必须确定另一端有某一进程。如果写入无名管道的数据超过其最大值,写操作将阻塞,如果管道中没有数据,读操作将阻塞,如果管道发现另一端断开,将自动退出。
(4)有名管道阻塞问题:有名管道在打开时需要确实对方的存在,否则将阻塞。即以读方式打开某管道,在此之前必须一个进程以写方式打开管道,否则阻塞。此外,可以以读写(O_RDWR)模式打开有名管道,即当前进程读,当前进程写,不会阻塞。
命名管道可以从命令行上创建,使用下面的命令:
$ mkfifo filename
命名管道也可以从程序里创建,相关函数为:
#include <sys/stat.h>
int mkfifo ( const char *filename, mode_t mode );
返回值:成功返回0,出错返回-1
创建命名管道:
int main ( int argc , char *argv[]){
mkfifo ( "p2" , 0644 );
return 0 ;
}
匿名管道与命名管道的区别
匿名管道由 pipe 函数创建并打开
命名管道由 mkfifo 函数创建,打开用 open
FIFO(命名管道)与 pipe(匿名管道)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,就会有相同的语义。
例子:读取文件,写入命名管道
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#define ERR_EXIT(m)
do{
perror(m);
exit(EXIT_FAILURE);
} while(0)
int main(int argc, char *argv[]){
mkfifo("tp", 0644);
int infd;
infd = open("abc", O_RDONLY);
if (infd == -1) ERR_EXIT("open");
int outfd;
outfd = open("tp", O_WRONLY);
if (outfd == -1) ERR_EXIT("open");
char buf[1024];
int n;
while ((n=read(infd, buf, 1024))>0){
write(outfd, buf, n);
}
close(infd);
close(outfd);
return 0;
}
延伸阅读:该博客有匿名管道和有名管道的C语言实践
3. 信号(Signal)
信号是Linux系统中用于进程间互相通信或者操作的一种机制,信号可以在任何时候发给某一进程,而无需知道该进程的状态。
如果该进程当前并未处于执行状态,则该信号就有内核保存起来,知道该进程回复执行并传递给它为止。
如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消是才被传递给进程。
Linux系统中常用信号:
(1)SIGHUP:用户从终端注销,所有已启动进程都将收到该进程。系统缺省状态下对该信号的处理是终止进程。
(2)SIGINT:程序终止信号。程序运行过程中,按Ctrl+C键将产生该信号。
(3)SIGQUIT:程序退出信号。程序运行过程中,按Ctrl+\\键将产生该信号。
(4)SIGBUS和SIGSEGV:进程访问非法地址。
(5)SIGFPE:运算中出现致命错误,如除零操作、数据溢出等。
(6)SIGKILL:用户终止进程执行信号。shell下执行kill -9发送该信号。
(7)SIGTERM:结束进程信号。shell下执行kill 进程pid发送该信号。
(8)SIGALRM:定时器信号。
(9)SIGCLD:子进程退出信号。如果其父进程没有忽略该信号也没有处理该信号,则子进程退出后将形成僵尸进程。
信号来源
信号是软件层次上对中断机制的一种模拟,是一种异步通信方式,,信号可以在用户空间进程和内核之间直接交互,内核可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件主要有两个来源:
硬件来源:用户按键输入Ctrl+C退出、硬件异常如无效的存储访问等。
软件终止:终止进程信号、其他进程调用kill函数、软件异常产生信号。
信号生命周期和处理流程
(1)信号被某个进程产生,并设置此信号传递的对象(一般为对应进程的pid),然后传递给操作系统;
(2)操作系统根据接收进程的设置(是否阻塞)而选择性的发送给接收者,如果接收者阻塞该信号(且该信号是可以阻塞的),操作系统将暂时保留该信号,而不传递,直到该进程解除了对此信号的阻塞(如果对应进程已经退出,则丢弃此信号),如果对应进程没有阻塞,操作系统将传递此信号。
(3)目的进程接收到此信号后,将根据当前进程对此信号设置的预处理方式,暂时终止当前代码的执行,保护上下文(主要包括临时寄存器数据,当前程序位置以及当前CPU的状态)、转而执行中断服务程序,执行完成后在回复到中断的位置。当然,对于抢占式内核,在中断返回时还将引发新的调度。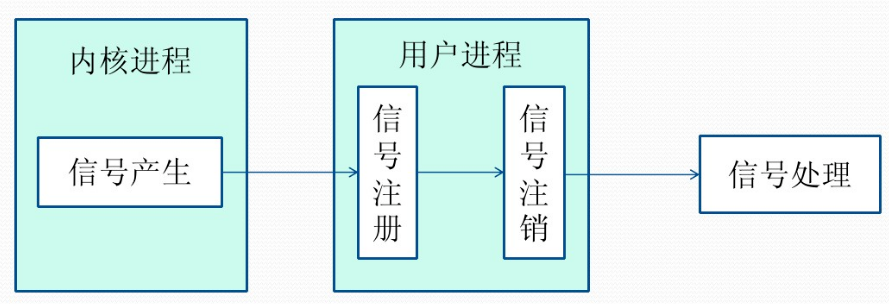
信号的生命周期
4. 消息(Message)队列
消息队列是存放在内核中的消息链表,每个消息队列由消息队列标识符表示。
与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显示地删除一个消息队列时,该消息队列才会被真正的删除。
另外与管道不同的是,消息队列在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达。
消息队列提供了⼀个从⼀个进程向另外⼀个进程发送⼀块数据的⽅法;每个数据块都被认为是有⼀个类型,接收者进程接收的数据块可以有不同的类型值;消息队列也有管道⼀样的不⾜,就是每个消息的最⼤⻓度是有上限的(MSGMAX),每个消息队列的总的字节数是有上限的(MSGMNB),系统上消息队列的总数也有⼀个上限(MSGMNI)。
延伸阅读:消息队列C语言的实践
消息队列特点总结:
(1)消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识.
(2)消息队列允许一个或多个进程向它写入与读取消息.
(3)管道和消息队列的通信数据都是先进先出的原则。
(4)消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比FIFO更有优势。
(5)消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺。
(6)目前主要有两种类型的消息队列:POSIX消息队列以及System V消息队列,系统V消息队列目前被大量使用。系统V消息队列是随内核持续的,只有在内核重起或者人工删除时,该消息队列才会被删除。
消息队列函数
msgget
原型
int msgget(key_t key, int msgflg);
功能:⽤来创建和访问⼀个消息队列
参数:
key—> 某个消息队列的名字
msgflg—>由九个权限标志构成,它们的⽤法和创建⽂件时使⽤的mode模式标志是⼀样的
返回值:成功返回⼀个⾮负整数,即该消息队列的标识码;失败返回-1
msgctl
原型
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
功能 :消息队列的控制函数
参数 :
msqid—>由msgget函数返回的消息队列标识码
cmd—>是将要采取的动作,(有三个可取值)
返回值 :成功返回0,失败返回-1
5. 共享内存(share memory)
使得多个进程可以可以直接读写同一块内存空间,是最快的可用IPC形式,是针对其他通信机制运行效率较低而设计的。
为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间。进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率。
由于多个进程共享一段内存,因此需要依靠某种同步机制(如信号量)来达到进程间的同步及互斥。
特点
共享内存是最快的一种 IPC,因为进程是直接对内存进行存取(⼀旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执⾏进⼊内核的系统调⽤来传递彼此的数据)。
因为多个进程可以同时操作,所以需要进行同步。
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
共享内存示意图: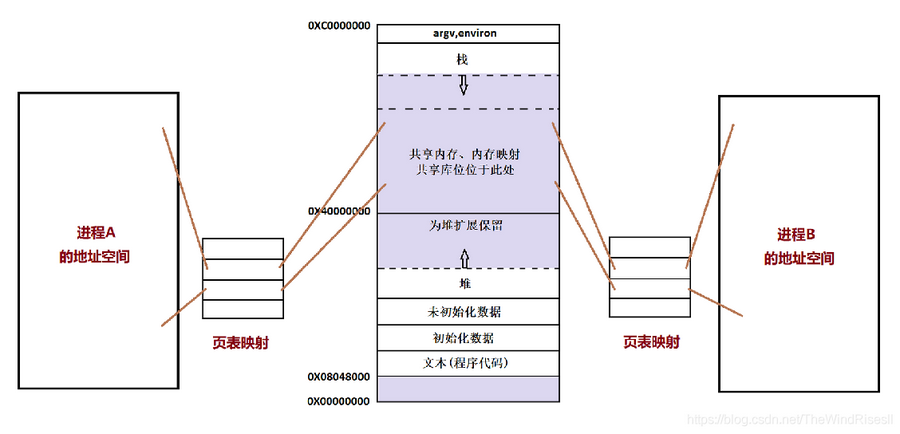
延伸阅读:Linux支持的主要三种共享内存方式:mmap()系统调用、Posix共享内存,以及System V共享内存实践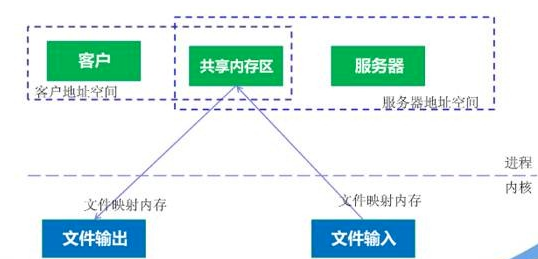
共享内存原理图
共享内存函数
shmget
原型
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
功能:⽤来创建共享内存
参数 :
key—> 这个共享内存段名字
size—>共享内存⼤⼩
shmflg—>由九个权限标志构成,它们的⽤法和创建⽂件时使⽤的mode模式标志是⼀样的
(内部有 IPC_CREAT 和 IPC_EXCL :当两个参数共同使用时,返回正常,则会创建新的共享内存;返回失败,则已存在共享内存)
返回值:成功返回⼀个⾮负整数,即该共享内存段的标识码;失败返回-1
shmat(挂接、映射)
原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
功能:将共享内存段连接到进程地址空间
参数:
shmid—> 共享内存标识
shmaddr—>指定连接的地址
shmflg—>它的两个可能取值是SHM_RND和SHM_RDONLY
返回值(映射的地址):成功返回⼀个指针,指向共享内存第⼀个节;失败返回-1
注意:
shmaddr为NULL,核⼼⾃动选择⼀个地址
shmaddr不为NULL且shmflg⽆SHM_RND标记,则以shmaddr为连接地址。
shmaddr不为NULL且shmflg设置了SHM_RND标记,则连接的地址会⾃动向下调整为SHMLBA的整数倍。公式:s
hmaddr - (shmaddr % SHMLBA)
shmflg(权限)=SHM_RDONLY,表⽰连接操作⽤来只读共享内存
shmdt(取消关联)
原型
int shmdt(const void *shmaddr);
功能:将共享内存段与当前进程脱离
参数:
shmaddr—>由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
shmctl
原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
功能:⽤于控制共享内存
参数:
shmid—>由shmget返回的共享内存标识码
cmd—>将要采取的动作(有三个可取值)
buf—>指向⼀个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1
6. 信号量(semaphore)
信号量主要用于同步和互斥,其本质上是一个具有原子特性的计数器,这一计数器用来描述临界资源当中资源的数目。信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。为了获得共享资源,进程需要执行下列操作:
(1)创建一个信号量:这要求调用者指定初始值,对于二值信号量来说,它通常是1,也可是0。
(2)等待一个信号量:该操作会测试这个信号量的值,如果小于0,就阻塞。也称为P操作。
(3)挂出一个信号量:该操作将信号量的值加1,也称为V操作。
信号量结构体伪代码 :
struct semaphore{
int value;
pointer_PCB queue;
}
为了正确地实现信号量,信号量值的测试及减1操作应当是原子操作。为此,信号量通常是在内核中实现的。Linux环境中,有三种类型:Posix(可移植性操作系统接口)有名信号量(使用Posix
IPC名字标识)、Posix基于内存的信号量(存放在共享内存区中)、System
V信号量(在内核中维护)。这三种信号量都可用于进程间或线程间的同步。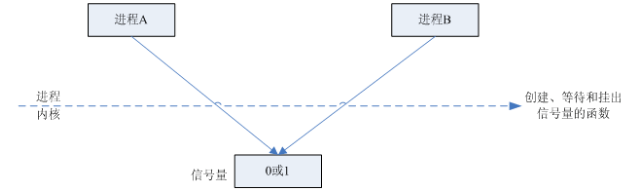
两个进程使用一个二值信号量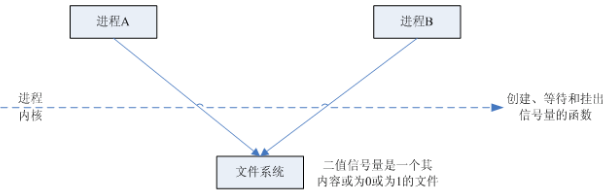
两个进程所以用一个Posix有名二值信号量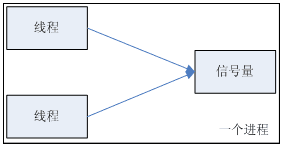
一个进程两个线程共享基于内存的信号量
信号量与普通整型变量的区别:
(1)信号量是非负整型变量,除了初始化之外,它只能通过两个标准原子操作:wait(semap) , signal(semap) ; 来进行访问;
(2)操作也被成为PV原语(P来源于荷兰语proberen"测试",V来源于荷兰语verhogen"增加",P表示通过的意思,V表示释放的意思),而普通整型变量则可以在任何语句块中被访问;
信号量与互斥量之间的区别:
(1)互斥量用于线程的互斥,信号量用于线程的同步。这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
(2)互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
(3)互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
进程互斥
由于各进程要求共享资源,⽽且有些资源需要互斥使⽤,因此各进程间竞争使⽤这些资源,进程的这种关系为进程的互斥
系统中某些资源⼀次只允许⼀个进程使⽤,称这样的资源为临界资源或互斥资源
在进程中涉及到互斥资源的程序段叫临界区
特性:IPC资源必须删除,否则不会自动清除,除非重启,所以 System V IPC 资源的生命周期随内核。
信号量函数
semget
int semget(key_t key, int nsems, int semflg);
功能:⽤来创建和访问⼀个信号量集
参数 :
key—>信号集的名字
nsems—>信号集中信号量的个数
semflg—> 由九个权限标志构成,它们的⽤法和创建⽂件时使⽤的mode模式标志是⼀样的
返回值:成功返回⼀个⾮负整数,即该信号集的标识码;失败返回-1
shmctl
原型
int semctl(int semid, int semnum, int cmd, ...);
功能:⽤于控制信号量集
参数:
semid—>由semget返回的信号集标识码
semnum—>信号集中信号量的序号
cmd—>将要采取的动作(有三个可取值)
最后⼀个参数根据命令不同⽽不同
返回值:成功返回0;失败返回-1
semop
原型
int semop(int semid, struct sembuf *sops, unsigned nsops);
功能:⽤来创建和访问⼀个信号量集
参数:
semid—>是该信号量的标识码,也就是semget函数的返回值
sops—>是个指向⼀个结构数值的指针
nsops—>信号量的个数
返回值:成功返回0;失败返回-1
7. 套接字(socket)
套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。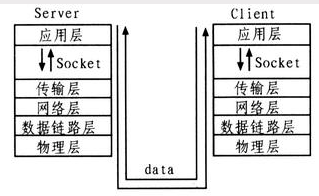
Socket是应用层和传输层之间的桥梁
套接字是支持TCP/IP的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
套接字特性
套接字的特性由3个属性确定,它们分别是:域、端口号、协议类型。
(1)套接字的域
它指定套接字通信中使用的网络介质,最常见的套接字域有两种:
一是AF_INET,它指的是Internet网络。当客户使用套接字进行跨网络的连接时,它就需要用到服务器计算机的IP地址和端口来指定一台联网机器上的某个特定服务,所以在使用socket作为通信的终点,服务器应用程序必须在开始通信之前绑定一个端口,服务器在指定的端口等待客户的连接。另一个域AF_UNIX,表示UNIX文件系统,它就是文件输入/输出,而它的地址就是文件名。
(2)套接字的端口号
每一个基于TCP/IP网络通讯的程序(进程)都被赋予了唯一的端口和端口号,端口是一个信息缓冲区,用于保留Socket中的输入/输出信息,端口号是一个16位无符号整数,范围是0-65535,以区别主机上的每一个程序(端口号就像房屋中的房间号),低于256的端口号保留给标准应用程序,比如pop3的端口号就是110,每一个套接字都组合进了IP地址、端口,这样形成的整体就可以区别每一个套接字。
(3)套接字协议类型
因特网提供三种通信机制:
一是流套接字,流套接字在域中通过TCP/IP连接实现,同时也是AF_UNIX中常用的套接字类型。流套接字提供的是一个有序、可靠、双向字节流的连接,因此发送的数据可以确保不会丢失、重复或乱序到达,而且它还有一定的出错后重新发送的机制。
二个是数据报套接字,它不需要建立连接和维持一个连接,它们在域中通常是通过UDP/IP协议实现的。它对可以发送的数据的长度有限制,数据报作为一个单独的网络消息被传输,它可能会丢失、复制或错乱到达,UDP不是一个可靠的协议,但是它的速度比较高,因为它并一需要总是要建立和维持一个连接。
三是原始套接字,原始套接字允许对较低层次的协议直接访问,比如IP、
ICMP协议,它常用于检验新的协议实现,或者访问现有服务中配置的新设备,因为RAW
SOCKET可以自如地控制Windows下的多种协议,能够对网络底层的传输机制进行控制,所以可以应用原始套接字来操纵网络层和传输层应用。比如,我们可以通过RAW
SOCKET来接收发向本机的ICMP、IGMP协议包,或者接收TCP/IP栈不能够处理的IP包,也可以用来发送一些自定包头或自定协议的IP包。网络监听技术很大程度上依赖于SOCKET_RAW。
原始套接字与标准套接字的区别在于:
原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
套接字通信的建立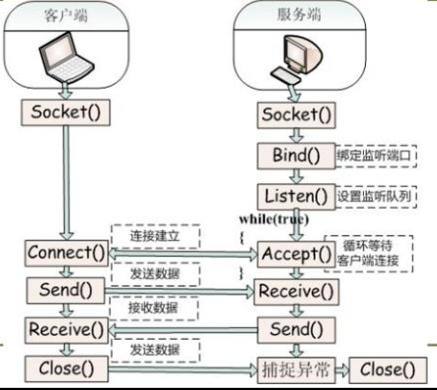
Socket通信基本流程
服务器端
(1)首先服务器应用程序用系统调用socket来创建一个套接字,它是系统分配给该服务器进程的类似文件描述符的资源,它不能与其他的进程共享。
(2)然后,服务器进程会给套接字起个名字,我们使用系统调用bind来给套接字命名。然后服务器进程就开始等待客户连接到这个套接字。
(3)接下来,系统调用listen来创建一个队列并将其用于存放来自客户的进入连接。
(4)最后,服务器通过系统调用accept来接受客户的连接。它会创建一个与原有的命名套接不同的新套接字,这个套接字只用于与这个特定客户端进行通信,而命名套接字(即原先的套接字)则被保留下来继续处理来自其他客户的连接(建立客户端和服务端的用于通信的流,进行通信)。
客户端
(1)客户应用程序首先调用socket来创建一个未命名的套接字,然后将服务器的命名套接字作为一个地址来调用connect与服务器建立连接。
(2)一旦连接建立,我们就可以像使用底层的文件描述符那样用套接字来实现双向数据的通信(通过流进行数据传输)。
套接字(socket)也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。通信操作过程函数如下:
(1).命名socket
SOCK_STREAM 式本地套接字的通信双方均需要具有本地地址,其中服务器端的本地地址需要明确指定,指定方法是使用 struct sockaddr_un 类型的变量。
(2).绑定
SOCK_STREAM
式本地套接字的通信双方均需要具有本地地址,其中服务器端的本地地址需要明确指定,指定方法是使用 struct sockaddr_un
类型的变量,将相应字段赋值,再将其绑定在创建的服务器套接字上,绑定要使用 bind 系统调用,其原形如下:
int bind(int socket, const struct sockaddr *address, size_t address_len);
其中 socket表示服务器端的套接字描述符,address 表示需要绑定的本地地址,是一个 struct sockaddr_un 类型的变量,address_len 表示该本地地址的字节长度。
(3).监听
服务器端套接字创建完毕并赋予本地地址值(名称,本例中为Server Socket)后,需要进行监听,等待客户端连接并处理请求,监听使用 listen 系统调用,接受客户端连接使用accept系统调用,它们的原形如下:
int listen(int socket, int backlog);
int accept(int socket, struct sockaddr *address, size_t *address_len);
其中
socket 表示服务器端的套接字描述符;backlog 表示排队连接队列的长度(若有多个客户端同时连接,则需要进行排队);address
表示当前连接客户端的本地地址,该参数为输出参数,是客户端传递过来的关于自身的信息;address_len
表示当前连接客户端本地地址的字节长度,这个参数既是输入参数,又是输出参数。
(4).连接服务器
客户端套接字创建完毕并赋予本地地址值后,需要连接到服务器端进行通信,让服务器端为其提供处理服务。对于SOCK_STREAM类型的流式套接字,需要客户端与服务器之间进行连接方可使用。连接要使用 connect 系统调用,其原形为:
int connect(int socket, const struct sockaddr *address, size_t address_len);
其中socket为客户端的套接字描述符,address表示当前客户端的本地地址,是一个 struct sockaddr_un 类型的变量,address_len 表示本地地址的字节长度。实现连接的代码如下:
connect(client_sockfd, (struct sockaddr*)&client_address, sizeof(client_address));
(5).相互发送接收数据
无论客户端还是服务器,都要和对方进行数据上的交互,这种交互也正是我们进程通信的主题。一个进程扮演客户端的角色,另外一个进程扮演服务器的角色,两个进程之间相互发送接收数据,这就是基于本地套接字的进程通信。发送和接收数据要使用
write 和 read 系统调用,它们的原形为:
int read(int socket, char *buffer, size_t len);
int write(int socket, char *buffer, size_t len);
其中 socket 为套接字描述符;len 为需要发送或需要接收的数据长度;
对于 read 系统调用,buffer 是用来存放接收数据的缓冲区,即接收来的数据存入其中,是一个输出参数;
对于 write 系统调用,buffer 用来存放需要发送出去的数据,即 buffer 内的数据被发送出去,是一个输入参数;返回值为已经发送或接收的数据长度。
(6).断开连接
交互完成后,需要将连接断开以节省资源,使用close系统调用,其原形为:
int close(int socket);
三、以Linux中的C语言编程为例
-------------------------------
管道
管道,通常指无名管道,是 UNIX 系统IPC最古老的形式。
1、特点
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
2、原型
#include <unistd.h>
int pipe(int fd[2]); // 返回值:若成功返回0,失败返回-1
当一个管道建立时,它会创建两个文件描述符:fd[0]为读而打开,fd[1]为写而打开。如下图: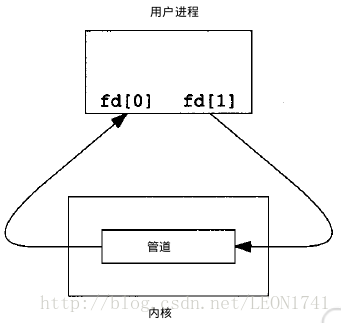
要关闭管道只需将这两个文件描述符关闭即可。
3、例子
单个进程中的管道几乎没有任何用处。所以,通常调用 pipe 的进程接着调用 fork,这样就创建了父进程与子进程之间的 IPC 通道。如下图所示: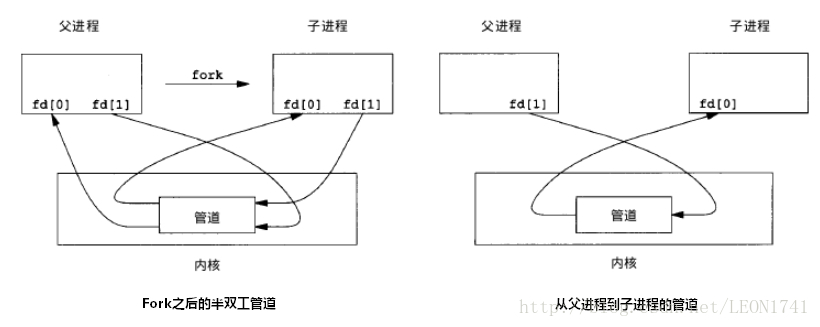
若要数据流从父进程流向子进程,则关闭父进程的读端(fd[0])与子进程的写端(fd[1]);反之,则可以使数据流从子进程流向父进程。
#include<stdio.h>
#include<unistd.h>
int main(){
int fd[2]; // 两个文件描述符
pid_t pid;
char buff[20];
if (pipe(fd) < 0) // 创建管道
printf("Create Pipe Error!\n");
if ((pid = fork()) < 0) { // 创建子进程
printf("Fork Error!\n");
} else if(pid > 0) { // 父进程
close(fd[0]); // 关闭读端
write(fd[1], "hello world\n", 12);
} else {
close(fd[1]); // 关闭写端
read(fd[0], buff, 20);
printf("%s", buff);
}
return 0;
}
-------------------------------
FIFO
FIFO,也称为命名管道,它是一种文件类型。
1、特点
FIFO可以在无关的进程之间交换数据,与无名管道不同。
FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
2、原型
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode); // 返回值:成功返回0,出错返回-1
其中的 mode 参数与open函数中的 mode 相同。一旦创建了一个 FIFO,就可以用一般的文件I/O函数操作它。
当 open 一个FIFO时,是否设置非阻塞标志(O_NONBLOCK)的区别:
若没有指定O_NONBLOCK(默认),只读 open 要阻塞到某个其他进程为写而打开此 FIFO。类似的,只写 open 要阻塞到某个其他进程为读而打开它。
若指定了O_NONBLOCK,则只读 open 立即返回。而只写 open 将出错返回 -1。如果没有进程已经为读而打开该 FIFO,其errno置ENXIO。
3、例子
FIFO的通信方式类似于在进程中使用文件来传输数据,只不过FIFO类型文件同时具有管道的特性。在数据读出时,FIFO管道中同时清除数据,并且“先进先出”。下面的例子演示了使用 FIFO 进行 IPC 的过程:
write_fifo.c
#include<stdio.h>
#include<stdlib.h>
#include<fcntl.h>
#include<sys/stat.h>
#include<time.h>
int main(){
int fd;
int n, i;
char buf[1024];
time_t tp;
printf("I am %d process.\n", getpid()); // 说明进程ID
if((fd = open("fifo1", O_WRONLY)) < 0) { // 以写打开一个FIFO
perror("Open FIFO Failed");
exit(1);
}
for(i=0; i<10; ++i){
time(&tp); // 取系统当前时间
n=sprintf(buf,"Process %d's time is %s",getpid(),ctime(&tp));
printf("Send message: %s", buf); // 打印
if(write(fd, buf, n+1) < 0) { // 写入到FIFO中
perror("Write FIFO Failed");
close(fd);
exit(1);
}
sleep(1);
}
close(fd); // 关闭FIFO文件
return 0;
}
read_fifo.c
#include<stdio.h>
#include<stdlib.h>
#include<errno.h>
#include<fcntl.h>
#include<sys/stat.h>
int main(){
int fd;
int len;
char buf[1024];
if (mkfifo("fifo1", 0666) < 0 && errno!=EEXIST) { // 创建FIFO管道
perror("Create FIFO Failed");
}
if ((fd = open("fifo1", O_RDONLY)) < 0) { // 以读打开FIFO
perror("Open FIFO Failed");
exit(1);
}
while((len = read(fd, buf, 1024)) > 0) { // 读取FIFO管道
printf("Read message: %s", buf);
}
close(fd);
return 0;
}
在两个终端里用 gcc 分别编译运行上面两个文件,可以看到输出结果如下:
$ ./write_fifo
I am 5954 process.
Send message: Process 5954's time is Mon Apr 20 12:37:28 2015
Send message: Process 5954's time is Mon Apr 20 12:37:29 2015
Send message: Process 5954's time is Mon Apr 20 12:37:30 2015
Send message: Process 5954's time is Mon Apr 20 12:37:31 2015
Send message: Process 5954's time is Mon Apr 20 12:37:32 2015
Send message: Process 5954's time is Mon Apr 20 12:37:33 2015
Send message: Process 5954's time is Mon Apr 20 12:37:34 2015
Send message: Process 5954's time is Mon Apr 20 12:37:35 2015
Send message: Process 5954's time is Mon Apr 20 12:37:36 2015
Send message: Process 5954's time is Mon Apr 20 12:37:37 2015
上述例子可以扩展成
客户进程—服务器进程
通信的实例,write_fifo的作用类似于客户端,可以打开多个客户端向一个服务器发送请求信息,read_fifo类似于服务器,它适时监控着FIFO的读端,当有数据时,读出并进行处理,但是有一个关键的问题是,每一个客户端必须预先知道服务器提供的FIFO接口,下图显示了这种安排: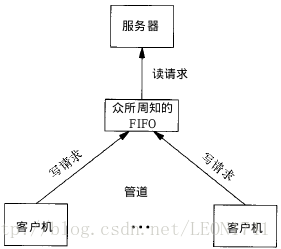
-------------------------------
消息队列
消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
1、特点
消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
2、原型
#include <sys/msg.h>
// 创建或打开消息队列:成功返回队列ID,失败返回-1
int msgget(key_t key, int flag);
// 添加消息:成功返回0,失败返回-1
int msgsnd(int msqid, const void *ptr, size_t size, int flag);
// 读取消息:成功返回消息数据的长度,失败返回-1
int msgrcv(int msqid, void *ptr, size_t size, long type,int flag);
// 控制消息队列:成功返回0,失败返回-1
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
在以下两种情况下,msgget将创建一个新的消息队列:
如果没有与键值key相对应的消息队列,并且flag中包含了IPC_CREAT标志位。
key参数为IPC_PRIVATE。
函数msgrcv在读取消息队列时,type参数有下面几种情况:
type == 0,返回队列中的第一个消息;
type > 0,返回队列中消息类型为 type 的第一个消息;
type < 0,返回队列中消息类型值小于或等于 type 绝对值的消息,如果有多个,则取类型值最小的消息。
可以看出,type值非 0 时用于以非先进先出次序读消息。也可以把 type 看做优先级的权值。(其他的参数解释,请自行Google之)
3、例子
下面写了一个简单的使用消息队列进行IPC的例子,服务端程序一直在等待特定类型的消息,当收到该类型的消息以后,发送另一种特定类型的消息作为反馈,客户端读取该反馈并打印出来。
msg_server.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
// 用于创建一个唯一的key
#define MSG_FILE "/etc/passwd"
// 消息结构
struct msg_form {
long mtype;
char mtext[256];
};
int main(){
int msqid;
key_t key;
struct msg_form msg;
// 获取key值
if((key = ftok(MSG_FILE,'z')) < 0){
perror("ftok error");
exit(1);
}
// 打印key值
printf("Message Queue - Server key is: %d.\n", key);
// 创建消息队列
if ((msqid = msgget(key, IPC_CREAT|0777)) == -1){
perror("msgget error");
exit(1);
}
// 打印消息队列ID及进程ID
printf("My msqid is: %d.\n", msqid);
printf("My pid is: %d.\n", getpid());
// 循环读取消息
for(;;) {
msgrcv(msqid, &msg, 256, 888, 0);// 返回类型为888的第一个消息
printf("Server: receive msg.mtext is: %s.\n", msg.mtext);
printf("Server: receive msg.mtype is: %d.\n", msg.mtype);
msg.mtype = 999; // 客户端接收的消息类型
sprintf(msg.mtext, "hello, I'm server %d", getpid());
msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
}
return 0;
}
msg_client.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/msg.h>
// 用于创建一个唯一的key
#define MSG_FILE "/etc/passwd"
// 消息结构
struct msg_form {
long mtype;
char mtext[256];
};
int main(){
int msqid;
key_t key;
struct msg_form msg;
// 获取key值
if ((key = ftok(MSG_FILE, 'z')) < 0) {
perror("ftok error");
exit(1);
}
// 打印key值
printf("Message Queue - Client key is: %d.\n", key);
// 打开消息队列
if ((msqid = msgget(key, IPC_CREAT|0777)) == -1) {
perror("msgget error");
exit(1);
}
// 打印消息队列ID及进程ID
printf("My msqid is: %d.\n", msqid);
printf("My pid is: %d.\n", getpid());
// 添加消息,类型为888
msg.mtype = 888;
sprintf(msg.mtext, "hello, I'm client %d", getpid());
msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
// 读取类型为777的消息
msgrcv(msqid, &msg, 256, 999, 0);
printf("Client: receive msg.mtext is: %s.\n", msg.mtext);
printf("Client: receive msg.mtype is: %d.\n", msg.mtype);
return 0;
}
-------------------------------
信号量
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
1、特点
信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
信号量基于操作系统的 PV操作,程序对信号量的操作都是原子操作。
每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
支持信号量组。
2、原型
最简单的信号量是只能取
0 和 1 的变量,这也是信号量最常见的一种形式,叫做二值信号量(Binary
Semaphore)。而可以取多个正整数的信号量被称为通用信号量。Linux
下的信号量函数都是在通用的信号量数组上进行操作,而不是在一个单一的二值信号量上进行操作。
#include <sys/sem.h>
// 创建或获取一个信号量组:若成功返回信号量集ID,失败返回-1
int semget(key_t key, int num_sems, int sem_flags);
// 对信号量组进行操作,改变信号量的值:成功返回0,失败返回-1
int semop(int semid, struct sembuf semoparray[], size_t numops);
// 控制信号量的相关信息
int semctl(int semid, int sem_num, int cmd, ...);
当semget创建新的信号量集合时,必须指定集合中信号量的个数(即num_sems),通常为1; 如果是引用一个现有的集合,则将num_sems指定为 0 。
在semop函数中,sembuf结构的定义如下:
struct sembuf {
short sem_num; // 信号量组中对应的序号,0~sem_nums-1
short sem_op; // 信号量值在一次操作中的改变量
short sem_flg; // IPC_NOWAIT, SEM_UNDO
}
其中 sem_op 是一次操作中的信号量的改变量:
若sem_op > 0,表示进程释放相应的资源数,将 sem_op的值加到信号量的值上。如果有进程正在休眠等待此信号量,则唤醒它们。
若sem_op < 0,请求 sem_op的绝对值的资源。
如果相应的资源数可以满足请求,则将该信号量的值减去sem_op的绝对值,函数成功返回。
当相应的资源数不能满足请求时,这个操作与sem_flg有关。
sem_flg指定IPC_NOWAIT,则semop函数出错返回EAGAIN.
sem_flg没有指定IPC_NOWAIT,则将该信号量的semncnt值加1,然后进程挂起直到下述情况发生:
当相应的资源数可以满足请求,此信号量的semncnt值减1,该信号量的值减去sem_op的绝对值。成功返回;
此信号量被删除,函数smeop出错返回EIDRM;
进程捕捉到信号,并从信号处理函数返回,此情况下将此信号量的semncnt值减1,函数semop出错返回EINTR。
若sem_op== 0,进程阻塞直到信号量的相应值为0:
当信号量已经为0,函数立即返回。
如果信号量的值不为0,则依据sem_flg决定函数动作:
sem_flg指定IPC_NOWAIT,则出错返回EAGAIN。
sem_flg没有指定IPC_NOWAIT,则将该信号量的semncnt值加1,然后进程挂起直到下述情况发生:
信号量值为0,将信号量的semzcnt的值减1,函数semop成功返回;
此信号量被删除,函数smeop出错返回EIDRM;
进程捕捉到信号,并从信号处理函数返回,在此情况将此信号量的semncnt值减1,函数semop出错返回EINTR。
在semctl函数中的命令有多种,这里就说两个常用的:
SETVAL:用于初始化信号量为一个已知的值。所需要的值作为联合semun的val成员来传递。在信号量第一次使用之前需要设置信号量。
IPC_RMID:删除一个信号量集合。如果不删除信号量,它将继续在系统中存在,即使程序已经退出,它可能在你下次运行此程序时引发问题,而且信号量是一种有限的资源。
3、例子
#include<stdio.h>
#include<stdlib.h>
#include<sys/sem.h>
// 联合体,用于semctl初始化
union semun{
int val; /*for SETVAL*/
struct semid_ds *buf;
unsigned short *array;
};
// 初始化信号量
int init_sem(int sem_id, int value){
union semun tmp;
tmp.val = value;
if(semctl(sem_id, 0, SETVAL, tmp) == -1){
perror("Init Semaphore Error");
return -1;
}
return 0;
}
// P操作:
// 若信号量值为1,获取资源并将信号量值-1
// 若信号量值为0,进程挂起等待
int sem_p(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = -1; /*P操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("P operation Error");
return -1;
}
return 0;
}
//V操作:
//释放资源并将信号量值+1
//如果有进程正在挂起等待,则唤醒它们
int sem_v(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = 1; /*V操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("V operation Error");
return -1;
}
return 0;
}
//删除信号量集
int del_sem(int sem_id){
union semun tmp;
if(semctl(sem_id, 0, IPC_RMID, tmp) == -1){
perror("Delete Semaphore Error");
return -1;
}
return 0;
}
int main(){
int sem_id; // 信号量集ID
key_t key;
pid_t pid;
// 获取key值
if((key = ftok(".", 'z')) < 0){
perror("ftok error");
exit(1);
}
// 创建信号量集,其中只有一个信号量
if((sem_id = semget(key, 1, IPC_CREAT|0666)) == -1){
perror("semget error");
exit(1);
}
// 初始化:初值设为0资源被占用
init_sem(sem_id, 0);
if((pid = fork()) == -1)
perror("Fork Error");
else if(pid == 0){ /*子进程*/
sleep(2);
printf("Process child: pid=%d\n", getpid());
sem_v(sem_id); /*释放资源*/
}
else{ /*父进程*/
sem_p(sem_id); /*等待资源*/
printf("Process father: pid=%d\n", getpid());
sem_v(sem_id); /*释放资源*/
del_sem(sem_id); /*删除信号量集*/
}
return 0;
}
上面的例子如果不加信号量,则父进程会先执行完毕。这里加了信号量让父进程等待子进程执行完以后再执行。
-------------------------------
共享内存
共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。
1、特点
共享内存是最快的一种IPC,因为进程是直接对内存进行存取。
因为多个进程可以同时操作,所以需要进行同步。
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
2、原型
#include <sys/shm.h>
// 创建或获取一个共享内存:成功返回共享内存ID,失败返回-1
int shmget(key_t key, size_t size, int flag);
// 连接共享内存到当前进程的地址空间:成功返回指向共享内存的指针,失败返回-1
void *shmat(int shm_id, const void *addr, int flag);
// 断开与共享内存的连接:成功返回0,失败返回-1
int shmdt(void *addr);
// 控制共享内存的相关信息:成功返回0,失败返回-1
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
当用shmget函数创建一段共享内存时,必须指定其 size;而如果引用一个已存在的共享内存,则将 size 指定为0 。
当一段共享内存被创建以后,它并不能被任何进程访问。必须使用shmat函数连接该共享内存到当前进程的地址空间,连接成功后把共享内存区对象映射到调用进程的地址空间,随后可像本地空间一样访问。
shmdt函数是用来断开shmat建立的连接的。注意,这并不是从系统中删除该共享内存,只是当前进程不能再访问该共享内存而已。
shmctl函数可以对共享内存执行多种操作,根据参数 cmd 执行相应的操作。常用的是IPC_RMID(从系统中删除该共享内存)。
3、例子
下面这个例子,使用了【共享内存+信号量+消息队列】的组合来实现服务器进程与客户进程间的通信。
共享内存用来传递数据;
信号量用来同步;
消息队列用来 在客户端修改了共享内存后 通知服务器读取。
server.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/shm.h> // shared memory
#include<sys/sem.h> // semaphore
#include<sys/msg.h> // message queue
#include<string.h> // memcpy
// 消息队列结构
struct msg_form {
long mtype;
char mtext;
};
// 联合体,用于semctl初始化
union semun{
int val; /*for SETVAL*/
struct semid_ds *buf;
unsigned short *array;
};
// 初始化信号量
int init_sem(int sem_id, int value){
union semun tmp;
tmp.val = value;
if(semctl(sem_id, 0, SETVAL, tmp) == -1){
perror("Init Semaphore Error");
return -1;
}
return 0;
}
// P操作:
// 若信号量值为1,获取资源并将信号量值-1
// 若信号量值为0,进程挂起等待
int sem_p(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = -1; /*P操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("P operation Error");
return -1;
}
return 0;
}
// V操作:
// 释放资源并将信号量值+1
// 如果有进程正在挂起等待,则唤醒它们
int sem_v(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = 1; /*V操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("V operation Error");
return -1;
}
return 0;
}
// 删除信号量集
int del_sem(int sem_id){
union semun tmp;
if(semctl(sem_id, 0, IPC_RMID, tmp) == -1){
perror("Delete Semaphore Error");
return -1;
}
return 0;
}
// 创建一个信号量集
int creat_sem(key_t key){
int sem_id;
if((sem_id = semget(key, 1, IPC_CREAT|0666)) == -1){
perror("semget error");
exit(-1);
}
init_sem(sem_id, 1); /*初值设为1资源未占用*/
return sem_id;
}
int main(){
key_t key;
int shmid, semid, msqid;
char *shm;
char data[] = "this is server";
struct shmid_ds buf1; /*用于删除共享内存*/
struct msqid_ds buf2; /*用于删除消息队列*/
struct msg_form msg; /*消息队列用于通知对方更新了共享内存*/
// 获取key值
if((key = ftok(".", 'z')) < 0){
perror("ftok error");
exit(1);
}
// 创建共享内存
if((shmid = shmget(key, 1024, IPC_CREAT|0666)) == -1){
perror("Create Shared Memory Error");
exit(1);
}
// 连接共享内存
shm = (char*)shmat(shmid, 0, 0);
if((int)shm == -1){
perror("Attach Shared Memory Error");
exit(1);
}
// 创建消息队列
if ((msqid = msgget(key, IPC_CREAT|0777)) == -1){
perror("msgget error");
exit(1);
}
// 创建信号量
semid = creat_sem(key);
// 读数据
while(1){
msgrcv(msqid, &msg, 1, 888, 0); /*读取类型为888的消息*/
if(msg.mtext == 'q') /*quit - 跳出循环*/
break;
if(msg.mtext == 'r'){ /*read - 读共享内存*/
sem_p(semid);
printf("%s\n",shm);
sem_v(semid);
}
}
// 断开连接
shmdt(shm);
/*删除共享内存、消息队列、信号量*/
shmctl(shmid, IPC_RMID, &buf1);
msgctl(msqid, IPC_RMID, &buf2);
del_sem(semid);
return 0;
}
client.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/shm.h> // shared memory
#include<sys/sem.h> // semaphore
#include<sys/msg.h> // message queue
#include<string.h> // memcpy
// 消息队列结构
struct msg_form{
long mtype;
char mtext;
};
// 联合体,用于semctl初始化
union semun{
int val; /*for SETVAL*/
struct semid_ds *buf;
unsigned short *array;
};
// P操作:
// 若信号量值为1,获取资源并将信号量值-1
// 若信号量值为0,进程挂起等待
int sem_p(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = -1; /*P操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("P operation Error");
return -1;
}
return 0;
}
// V操作:
// 释放资源并将信号量值+1
// 如果有进程正在挂起等待,则唤醒它们
int sem_v(int sem_id){
struct sembuf sbuf;
sbuf.sem_num = 0; /*序号*/
sbuf.sem_op = 1; /*V操作*/
sbuf.sem_flg = SEM_UNDO;
if(semop(sem_id, &sbuf, 1) == -1){
perror("V operation Error");
return -1;
}
return 0;
}
int main(){
key_t key;
int shmid, semid, msqid;
char *shm;
struct msg_form msg;
int flag = 1; /*while循环条件*/
// 获取key值
if((key = ftok(".", 'z')) < 0){
perror("ftok error");
exit(1);
}
// 获取共享内存
if((shmid = shmget(key, 1024, 0)) == -1){
perror("shmget error");
exit(1);
}
// 连接共享内存
shm = (char*)shmat(shmid, 0, 0);
if((int)shm == -1){
perror("Attach Shared Memory Error");
exit(1);
}
// 创建消息队列
if ((msqid = msgget(key, 0)) == -1){
perror("msgget error");
exit(1);
}
// 获取信号量
if((semid = semget(key, 0, 0)) == -1){
perror("semget error");
exit(1);
}
// 写数据
printf("***************************************\n");
printf("* IPC *\n");
printf("* Input r to send data to server. *\n");
printf("* Input q to quit. *\n");
printf("***************************************\n");
while(flag){
char c;
printf("Please input command: ");
scanf("%c", &c);
switch(c){
case 'r':
printf("Data to send: ");
sem_p(semid); /*访问资源*/
scanf("%s", shm);
sem_v(semid); /*释放资源*/
/*清空标准输入缓冲区*/
while((c=getchar())!='\n' && c!=EOF);
msg.mtype = 888;
msg.mtext = 'r'; /*发送消息通知服务器读数据*/
msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
break;
case 'q':
msg.mtype = 888;
msg.mtext = 'q';
msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
flag = 0;
break;
default:
printf("Wrong input!\n");
/*清空标准输入缓冲区*/
while((c=getchar())!='\n' && c!=EOF);
}
}
// 断开连接
shmdt(shm);
return 0;
}
注意:当scanf()输入字符或字符串时,缓冲区中遗留下了\n,所以每次输入操作后都需要清空标准输入的缓冲区。但是由于 gcc 编译器不支持fflush(stdin)(它只是标准C的扩展),所以我们使用了替代方案:
while((c=getchar())!='\n' && c!=EOF);
四、总结
接⼝
创建IPC(msgqueue, shm, sem), ipcget
删除IPC(msgqueue, shm, sem), ipcctl + IPC_RMID
每种IPC都有⾃⼰个性化的操作接⼝
命令
ipcs : 显示IPC资源
ipcs -m 查看共享内存
ipcs -s 查看信号
ipcs -q 查看消息队列
ipcrm : 手动删除IPC资源
ipcrm -m 查看共享内存
ipcrm -s 查看信号
ipcrm -q 查看消息队列
五、参考资料
进程间通信IPC (InterProcess Communication)
Unix域套接字(Unix Domain Socket)
Linux进程间通信之管道与消息队列实践
linux下的多进程通信(IPC)原理及实现方案(管道、队列、信号量、共享内存)
linux进程间通信(IPC)的五种方式(管道、FIFO、共享内存、信号量、消息队列)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号