【基础知识】 CPU 详细整理(个人整理)
本文只是个人对cpu的理解,不建议浏览
建议浏览:https://zhuanlan.zhihu.com/p/397260483
提要
64位/32位操作系统,64/32指的是通用寄存器的位数。
定义
中央处理器 (英語:Central Processing Unit,缩写:CPU)是计算机的主要设备之一,功能主要是解释计算机指令以及处理计算机软件中的数据。
组成
- 运算器:算术、逻辑(部件:算术逻辑单元、累加器、寄存器组、路径转换器、数据总线)
- 控制器:复位、使能(部件:计数器、指令寄存器、指令解码器、状态寄存器、时钟发生器、微操作信号发生器)
- 寄存器:100多个寄存器
CPU运行图(自己画的)
CPU的运作原理:取指令》译码》获取操作数》执行指令(ALU)》存储(寄存器)
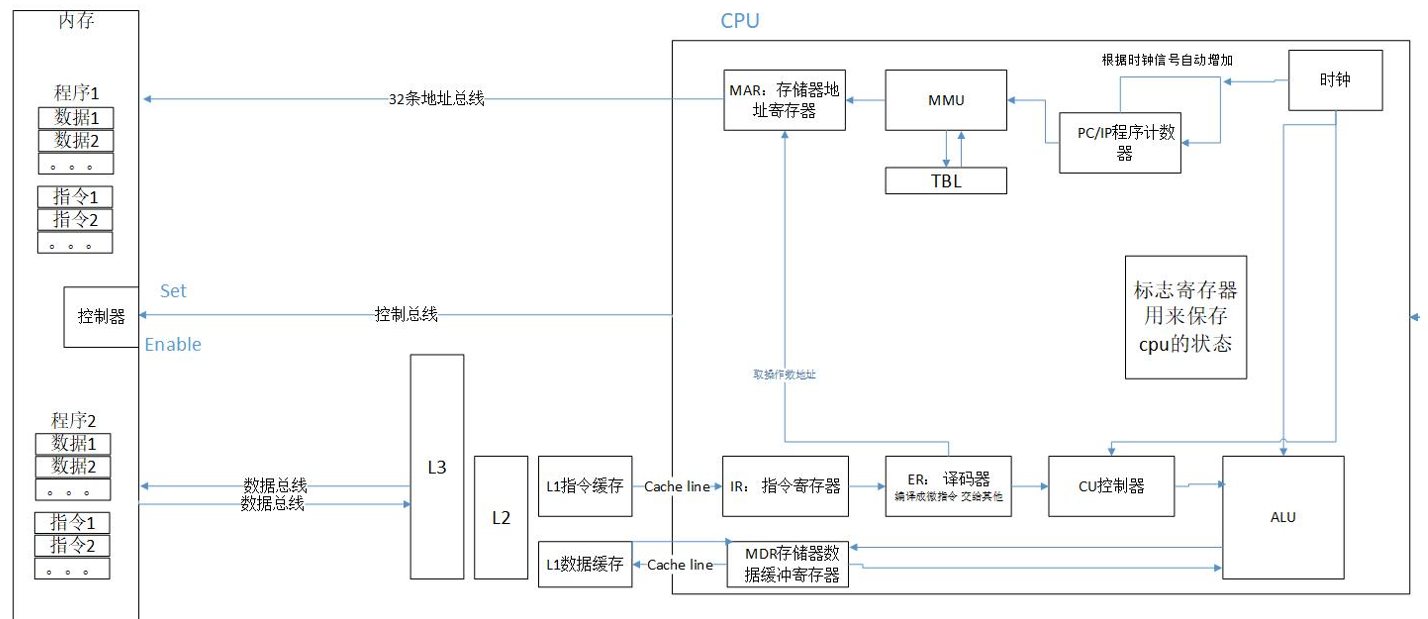
1、取指令
取指令(Instruction Fetch,IF)阶段是将一条指令从主存中取到指令寄存器的过程。 程序计数器 PC 中的数值,用来指示当前指令在主存中的位置。当一条指令被取出后,PC 中的数值将根据指令字长度而自动递增:若为单字长指令,则(PC)+1->PC;若为双字长指令,则(PC)+2->PC,依此类推。
2.指令译码阶段
取出指令后,计算机立即进入指令译码(Instruction Decode,ID)阶段。 在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。在组合逻辑控制的计算机中,指令译码器对不同的指令操作码产生不同的控制电位,以形成不同的微操作序列;在微程序控制的计算机中,指令译码器用指令操作码来找到执行该指令的微程序的入口,并从此入口开始执行。 在传统的设计里,CPU中负责指令译码的部分是无法改变的。不过,在众多运用微程序控制技术的新型 CPU 中,微程序有时是可重写的。
3.执行指令阶段
在取指令和指令译码阶段之后,接着进入执行指令(Execute,EX)阶段。 此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。为此,CPU 的不同部分被连接起来,以执行所需的操作。 例如,如果要求完成一个加法运算,算术逻辑单元 ALU 将被连接到一组输入和一组输出,输入端提供需要相加的数值,输出端将含有最后的运算结果。
4.访存取数阶段
根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数(Memory,MEM)阶段。 此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算。
5.结果写回阶段
作为最后一个阶段,结果写回(Writeback,WB)阶段把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到 CPU 的内部寄存器中,以便被后续的指令快速地存取;在有些情况下, 结果数据也可被写入相对较慢、但较廉价且容量较大的主存。许多指令还会改变程序状态字寄存器
中标志位 的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。
在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,计算机就接着从程序计数器 PC 中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。许多新型 CPU 可以同时取出、译码和执行多条指令,体现并行处理的特性。
CPU的内部结构解析
CPU和内存是由许多晶体管组成的电子部件,通常称为IC(Integrated Circuit,集成电路)。从功能方面来看,CPU的内部由寄存器,控制器,运算器和时钟四部分构成,各部分之间由电流信号相互连通。
寄存器:
可用来暂存指令,数据等处理对象,可以将其看做是内存的一种。根据种类的不同,一个CPU内部会有20~100个寄存器。
使用高级语言编写的程序会在编译后转化成机器语言,然后通过CPU内部的寄存器来处理。不同类型的CPU,其内部寄存器的数量,种类以及寄存器存储的数值范围都是不同的。根据功能的不同,我们可以将寄存器大致划分为八类。
累加寄存器:存储执行运算的数据和运算后的数据。
标志寄存器:存储运算处理后的CPU的状态。
pc程序计数器:指令指针 存储下一条指令所在内存的地址。
当程序转移时,转移指令执行的最终结果就是要改变PC的值,此PC值就是转去的地址,以此实现转移。有些机器中也称PC为指令指针IP(Instruction Pointer)
基址寄存器:存储数据内存的起始地址。
变址寄存器:存储基址寄存器的相对地址。
通用寄存器:存储任意数据。
指令寄存器:存储指令。CPU内部使用,程序员无法通过程序对该寄存器进行读写操作。
栈寄存器:存储栈区域的起始地址。
取指令:程序计数器是用于存放下一条指令所在单元的地址的地方。当执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”
其中,程序计数器,累加寄存器,标志寄存器,指令寄存器和栈寄存器都只有一个,其他的寄存器一般有多个。
译码器:指令译码器的东西根据IR的内容生成很多的微操作指令,从而去控制其他部件已完成相应的功能
控制器:
负责把内存上的指令,数据等读入寄存器,并根据指令的执行结果来控制整个计算机。
运算器:
负责运算从内存读入寄存器的数据。
时钟:
负责发出CPU开始计时的时钟信号。不过,也有些计算机的时钟位于CPU的外部。
详细内如:https://www.cnblogs.com/cdaniu/p/15620020.html
CPU指令集是什么
详细查看:https://www.cnblogs.com/cdaniu/p/15625234.html
微架构
微架构是指一套用于执行指令集的微处理器设计方法,每一个CPU都会用用一套微框架来处理指令集
详细请看:https://www.cnblogs.com/cdaniu/p/15625508.html
MMU(Memory Management Unit)内存管理单元:
CPU 的主频:CPU 的主频是由一个晶体振荡器来实现的
一种硬件电路单元负责将虚拟内存地址转换为物理内存地址
所有的内存访问都将通过 MMU 进行转换,除非没有使能 MMU。
MMU(内存管理单元):包括从逻辑地址到虚拟地址(线性地址)再到内存地址的变换过程、页式存储管理、段式存储管理、段页式存储管理、虚拟存储管理(请求分页、请求分段、请求段页)。 MMU位于CPU内部,可以假想为一个进程的所需要的资源都放在虚拟地址空间里面,而CPU在取指令时,机器指令中的地址码部分为虚拟地址(线性地址),需要经过MMU转换成为内存地址,才能进行取指令。
-
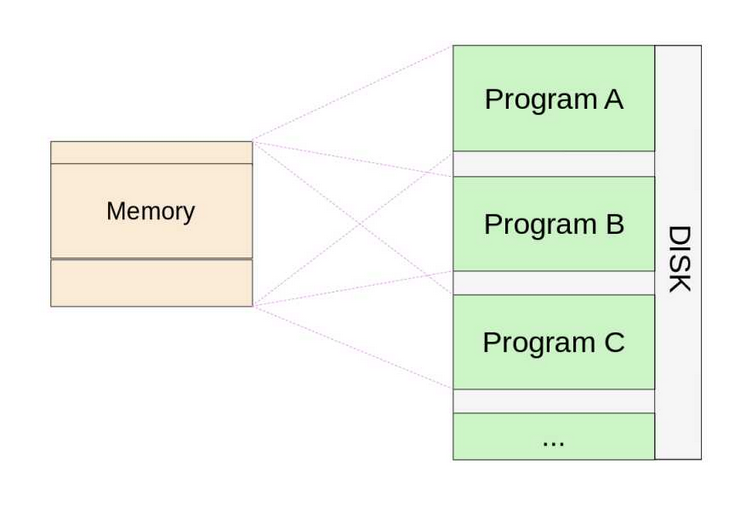
Swap模式时代
-
早期计算机在执行程序时,将程序从磁盘加载到内存执行中执行,在多用户系统中,当新的用户程序被执行前,需要先将当前用户的程序从内存swap到磁盘,然后从磁盘加载新的程序执行,当前用户退出后,在将前一用户程序从磁盘中加载到内存继续执行,每次用户切换伴随程序的swap,消耗较大。
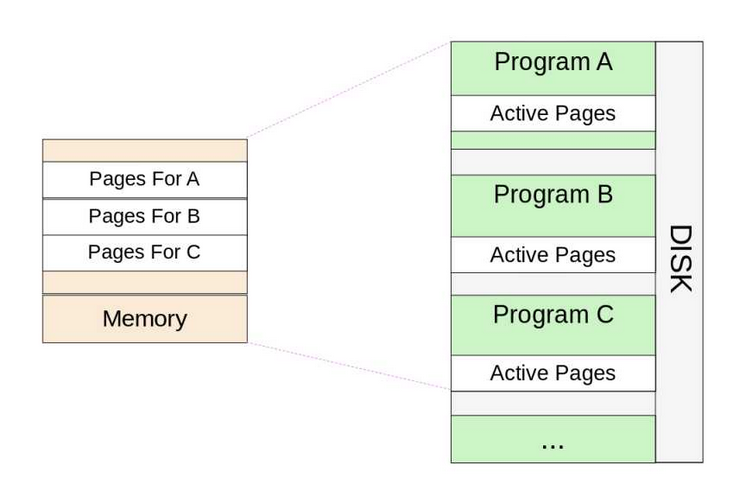
Page模式时代
后来人们将内存划分为固定大小的Page,一般为4K或者更小,这样用户程序按需以Page的方式加载到内存,不需要将整个程序加载到内存,这样内存可同时容纳更多程序,而无需按照用户切换进行swap,提升了内存利用率和加载时间(PageFault是Page时代的产物,而非MMU时代独有)。
-
动态地址转换(DAT - Dynamic Address Translation)时代
-
最早可以追溯到1966年IBM研发的System/360-Model67,在该计算机的设计中首先引入了动态的地址转换机制,在Page模式基础上,为用户程序分配虚地址(VA),通过DAT转换为物理地址(PA)进行访问。通过好处是用户可以使用连续的地址,而不再受制于物理内存大小和Page碎片化的限制,原则上用户的程序只受磁盘大小限制,代价是增加虚实地址转换机制。
-
实现方式
采用segment、page、offset模式,将24-bit虚拟地址分为3段,0-7bit保留,8-11bit索引segment,一共16个segment,12-19bit索引page,每个segment最多256个page,20-31bit为page offset,每个用户有一个虚实地址映射表,分为2级,即segment表和page表,每个segment指向一个page表。 -
转换过程
当CPU访问一个虚地址时,先通过VA的8-11bit查找segment表得到page表,再根据12-19bit在page表中找到PA的page起始地址,加上20-31bit的page offset就得到实际的PA了。
-
这就是MMU最早的雏形了。

现代MMU的实现
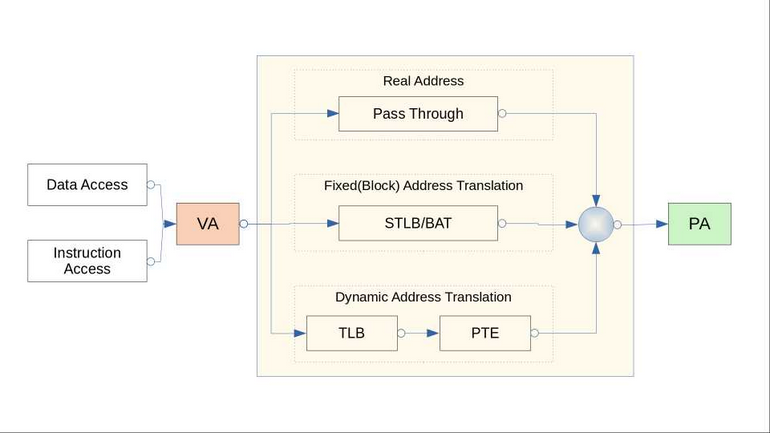
现代CPU的MMU的地址转换方式一般分为3种模式,即实地址模式、块地址转换、页地址转换。
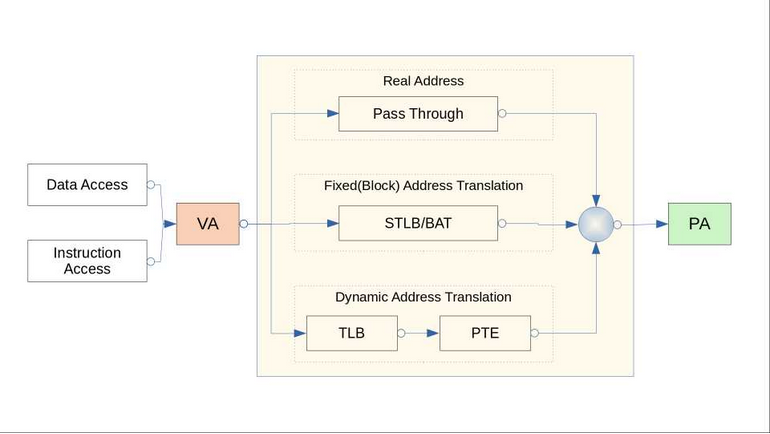
现代MMU的实现
现代CPU的MMU的地址转换方式一般分为3种模式,即实地址模式、块地址转换、页地址转换。
-
实地址模式
-
即CPU状态位中MMU使能位清零,MMU处于关闭状态,此时CPU操作的地址不经过转换(VA=PA),直接作为物理地址进行访问,CPU上电时或者在异常入口时处于该状态,在该状态下可以访问任意物理内存,非常危险,一般操作系统在CPU上电后做完必要初始化以后便使能MMU,或者在异常处理的入口保存好必要信息后使能MMU。
-
块地址转换
-
或者成为固定的地址转换或静态配置的地址转换表,这种模式支持配置一些固定的内存地址映射(VPN->RPN),比如Linux Kernel加载的地址,以PowerPC604为例,0xC0000000这段地址开始的256M内存映射使用了该模式的转换,好处是这种配置转换速度快,一般在特定的寄存器中配置,没有页表查找过程,缺点是缺乏灵活性,一次配置永久使用。
-
页地址转换
-
类似于早期的动态地址转换DAT,即将VA的一部分bit用于索引segment,另外一部分bit用于索引PTE表,最终得到物理地址的Page起始地址,再加上最后12bit(4K)的Page offset得到真正的物理地址。
相比早期的DAT,有以下优化:
-
增加了PTE表的缓存TLB(Translation lookaside Buffer),有些处理器将ITLB(指令)和DTLB(数据)分开,以减少指令和数据之间的缓存冲突。
-
支持更大的物理地址(36bit以上)或逻辑地址,如在PowerPC中,用以应对现代操作系统的多进程管理将32bit通过segment寄存器扩展为52bit的逻辑地址,然后通过hash函数得到key用来查找PTE,并最终转换为36bit物理地址,逻辑地址的扩展用于减少多进程之间的PTE冲突。
-
支持多种PTE查找方式,如硬件查找和软件查找。
MMU地址转换流程如下:
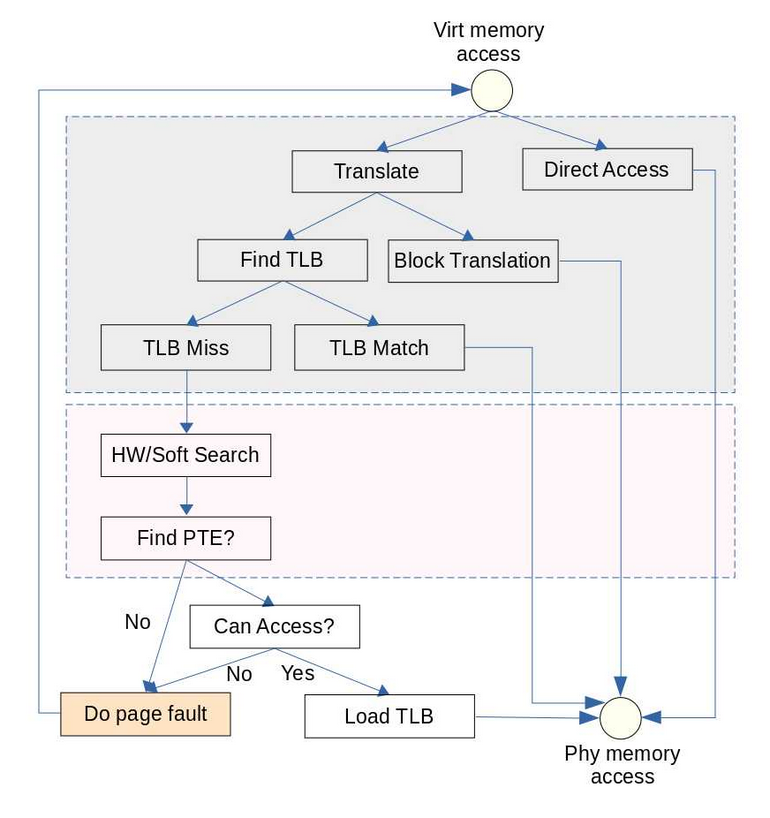
主要分为几个阶段:
- 用户进程访问虚存地址。
- 触发TLB查找过程,该部分通过硬件完成(灰色背景),没有软件参与。
- TLB miss场景下,查找PTE(粉色背景),该部分在不同CPU上实现不同,像X86都是硬件查找,PowerPC有些处理器使用软件查找,即在内核实现一个TLB miss的异常处理,可以灵活做到TLB查找。
- Do Page Fault,分为几种情况:
- 新申请内存第一次读写,触发物理内存分配
- 进程fork后子进程写内存触发Copy-On-Write。
- 非法内存读写,错误处理
汇编语言的的指令是和寄存器和运算器 存储器一 一对应的。如,加法指令00000011写成汇编语言就是 ADD。只要还原成二进制,汇编语言就可以被 CPU 直接执行,所以它是最底层的低级语言。
C# IL代码指令不是一 一对应的。IL的指令是组合出来的。是对机器指令的抽象。
内容来源:https://my.oschina.net/u/4274516/blog/3522193
https://my.oschina.net/u/4398626/blog/3929100
https://my.oschina.net/u/4370598/blog/3757485
https://my.oschina.net/u/4391341/blog/3612316

 浙公网安备 33010602011771号
浙公网安备 33010602011771号