



页面加载性能优化
页面加载性能优化
在互联网网站百花齐放的今天,网站响应速度是用户体验的第一要素,其重要性不言而喻,这里有几个关于响应时间的重要条件:
用户在浏览网页时,不会注意到少于0.1秒的延迟;
少于1秒的延迟不会中断用户的正常思维, 但是一些延迟会被用户注意到;
延迟时间少于10秒,用户会继续等待响应;
延迟时间超过10秒后,用户将会放弃并开始其他操作;
因此大家都开始注重性能优化,很多厂商都开始做一些性能优化。比较有名的是雅虎军规,不过随着浏览器和协议等的发展,有一些已经逐渐被淘汰了。因此建议大家以历史的目光看待它。比如.尽量减少HTTP请求数这一条,在HTTP2协议下就不管用了,因为HTTP2实现了HTTP复用,HTTP请求变少,反而降低性能。因此一定要结合历史环境看待具体的优化原则和手段,否则会适得其反。
随着移动互联网的高速发展,移动终端的数量正在以指数级增长,很多厂商对于移动端体验都开始重视起来了。比如Google Chrome 的工程师 Alex就提出了Progressive Web App(以下简称PWA),用来提高移动端web的性能。PWA的核心是Service Worker, 通过它可以使得在JS主线程之外,程序员通过编程的方式控制网络请求,结合浏览器本身的缓存,往往可以达到非常棒的用户体验。PWA提出了许多类似Native的“功能”- 比如离线加载和桌面快捷方式,使得移动端web体验更加友好。另外加上web端本身的特性-比如快速迭代,可索引(你可以通过搜索引擎搜索,而native app 则不行)等,使得更多的人投入到给web端用户提供更佳的用户体验的PWA中去。Google在更早的时候,提出了AMP。 2017年Google dev上海站就宣传了PWA 和 AMP,并且通过一张动图形象地展示了两者(PWA的P和A翻过来,然后W上下翻转就是AMP,反之亦然)。AMP是一种面向手机端的轻量级的web展现,通过将重量级元素重新实现等方式提高了手机端性能。 另外诸如使用asm.js 使得代码更容易编译成机器指令,也是性能优化的一环。如果你仔细查看应用执行的profile的时候,你会发现js代码compile的时间会很久,尤其你写了很多无用js代码,或者没必要第一时间执行的代码的时候,这种影响更加大。js代码最终也是编译成二进制给机器执行,而js是动态语言,也就是说js代码是执行到哪编译到哪,这是和java这样的静态语言的一个很大的差别。V8已经对这部分做了相当大的优化,一般情况下我们不必担心,通常来讲这也不会成为性能瓶颈,因为这些时间和网络IO的时间根本不是一个数量级。但是在特定场合,提前编译成更容易解释执行的代码,可能就会派上用场。
过早优化是万恶之源
在我刚刚接触前端的时候,经常看到这样的性能优化例子:
// bad
for(var i = 0;i < data.length;i++){
// do something...
}
// good
for(var i = 0,len = data.length;i < len;i++){
// do something...
}
理由是上面的会每次去计算data.length。个人上面的优化非常可笑,且不说实际运行情况怎样。就算下面的性能比上面的好,我觉得这样的性能优化应该交给编译器来做,不应该交给上层业务去做,这样做反而丧失了可理解性,大家很明显的看出上面的更容易理解,不是吗?
过早的优化,会让人陷入心理误区。这种心理误区就是典型的手中有锤子,处处都是钉子。
还有一点就是如果过早优化,往往会一叶障目。性能优化要遵守木桶原理,即影响系统性能的永远是系统的性能短板。如果过早优化,往往会头痛医脚,忙手忙脚却毫无收效。
一个经典问题
让我们回忆一下浏览器从加载url开始到页面展示出来,经过了哪些步骤:
- 浏览器调用loadUrl解析url
-
浏览器调用DNS模块,如果浏览器有dns缓存则直接返回IP。 否则查询本地机器的DNS,并逐层往上查找。
最终返回IP,然后将其存到DNS缓存并设置过期时间。
tips: 在chrome浏览器中, 可以输入 chrome://dns/ 查看chrome缓存的dns记录
- 浏览器调用网络模块。 网络模块和目标IP 建立TCP连接,途中经过三次握手。
- 浏览器发送http请求,请求格式如下:
header
(空行)
body
- 请求到达目标机器,并通过端口与目标web server 建立连接。
- web server 获取到请求流,对请求流进行解析,然后经过一些列处理,可能会查询数据库等, 最终返回响应流到前端。
- 浏览器下载文档(content download),并对文档进行解析。解析的过程如下所示:

知道了浏览器加载网页的步骤,我们就可以从上面每一个环节采取”相对合适“的策略优化加载速度。 比如上面第二步骤会进行dns查找,那么dns查找是需要时间的,如果提前将dns解析并进行缓存,就可以减少这部分性能损失。在比如建立TCP连接之后,保持长连接的情况下可以串行发送请求。熟悉异步的朋友肯定知道串行的损耗是很大的,它的加载时间取决于资源加载时间的和。而采取并行的方式是所有加载时间中最长的。这个时候我们可以考虑减少http 请求或者使用支持并行方式的协议(比如HTT2协议)。如果大家熟悉浏览器的原理或者仔细观察网络加载图的化,会发现同时加载的资源有一个上限(根据浏览器不同而不同),这是浏览器对于单个域名最大建立连接个数的限制,所以可以考虑增加多个domain来进行优化。类似的还有很多,留给大家思考。但是总结下来只有两点,一是加载优化,即提高资源加载的速度。第二个是渲染优化,即资源拿到之后到解析完成的阶段的优化。
经过上面简单的讲解,我想大家对浏览器加载HTML开始到页面呈现出来,有了一个大概的认识,后面我会更详细地讲解这个过程。有一个名词叫关键路径(Critical Path),它指的是从浏览器收到 HTML、CSS 和 JavaScript 字节到对其进行必需的处理,从而将它们转变成渲染的像素。这一过程中有一些中间步骤,优化性能其实就是了解这些步骤中发生了什么。记住关键路径上的资源有HTML,CSS,JavaScript,其中并不包括图片,虽然图片在我们的应用中非常普遍,但是图片并不会阻止用户的交互,因此不计算到关键路径,关于图片的优化我会在下面的小节中重点介绍。
为了让大家有更清晰地认识,我将上面浏览器加载网站步骤中的第七步中的CSSOM和DOM以及render tree的构建过程,更详细地讲解一下。
浏览器请求服务端的HTML文件,服务端响应字节流给浏览器。浏览器接受到HTML然后根据指定的编码格式进行解码。完成之后会分析HTML内容,将HTML分成一个个token,然后根据不同token生成不同的DOM,最后根据HTML中的层级结构生成DOM树。
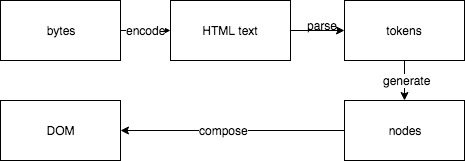
其中要注意的是,如果碰到CSS标签和JavaScript标签(不是async或者defer的js脚本)会暂停渲染,等到资源加载完毕,继续渲染。如果加载了CSS文件(内敛样式同理),会在加载完成CSS之后生成CSSOM。CSSOM的生成过程类似,也是将CSS分成一个个token,然后根据不同token生成CSSOM,CSSOM是用来控制DOM的样式的。最后将DOM和CSSOM合成render tree。
CSS 是阻塞渲染的资源。需要将它尽早、尽快地下载到客户端,以便缩短首次渲染的时间。
为弄清每个对象在网页上的确切大小和位置,浏览器从渲染树的根节点开始进行遍历,根据盒模型和CSS计算规则生成计算样式(chrome中叫computed style),最后调用绘制线程将DOM绘制到页面上。因此优化上面每一个步骤都非常重要。现在我们有了清晰的认识,关键资源HTML是一切的起点,没有HTML后面就没有意义。CSS应该尽快下载并解析,通常我们将css放在head里面优先加载执行,就像app shell的概念一样。我们应该优先给用户呈现最小子集,然后慢慢显示其他的内容,就好像PJPEG(progressive jpeg)一样。如下图是一个渐进式渲染的一个例子(图片来自developers.google.com):

我们还没有讨论JavaScript,理论上JavaScript既可以操作CSS,也可以直接修改DOM。浏览器不知道JavaScript的具体内容,因此默认情况下JavaScript会阻止渲染引擎的执行,转而去执行JS线程,如果是外部 JavaScript 文件,浏览器必须停下来,等待从磁盘、缓存或远程服务器获取脚本,这就可能给关键渲染路径增加数十至数千毫秒的延迟,除非遇到带有async或者defer的标签。向script标记添加异步关键字可以指示浏览器在等待脚本可用期间不阻止DOM构建,这样可以显著提升性能。
经过上面的分析,我们知道了关键路径。我们可以借助chrome开发工具查看瀑布图,分析网站的关键路径,分析加载缓慢,影响网站速度的瓶颈点。
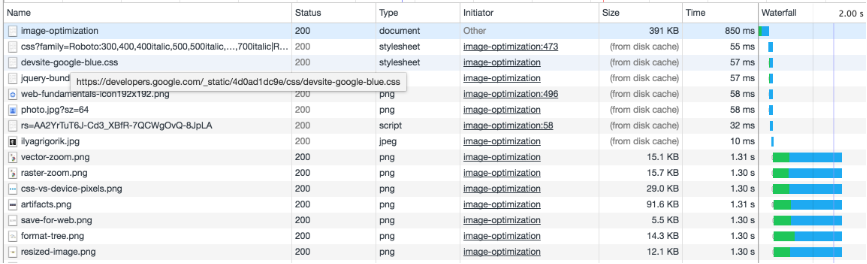
也可以使用一些工具检测,比如前面提到的web performance test,也可以尝试下Lighthouse。
在后面的小节,我会介绍performance api,大家可以在前端埋点,然后分析网站的性能指标,这也是对其他分析手法的一个重要补充。
性能优化系统论
性能优化属于一个整体内容,它应该是一个软件的特性。我将性能优化分为如下几个步骤:
1. 测量
其中测量分为手动测量和自动测量。
- 自动测量
通过浏览器自身的事件和指标,我们将这些数据收集起来。 这些和业务无关的,我们可以做到自动化。 有名的比如lighthouse这种产品, 自动化测量部分的最佳实践是将自动化测量加入到CI中,通常会伴随着评分等信息用于辅助开发者判断。 开发者推送合并新的代码到主分支的时候触发执行,并且可以设置一个阀值,低于这个阀值不允许合并等。
- 手动测量
通过脚本检测指标。 比如 performanceObserver, 比如FID,Long task 等。基本上就是我们关心的指标且不能自动化检测的就需要手动
2. 收集用户真实数据,并提供可视化展现
将上面这一步检测的结果放到一个dashboard中,可以直观感受到。 这部分可以参考lighthouse的UI。 我会在后面介绍朱雀的时候详细介绍。
3. 分析瓶颈点, 分析代码,并优化代码
可以通过一些工具分析,比如webpack-bunlde-analysis, code coverafe of chrome dev tool 等。 这部分的最佳实践非常多, 通常来讲随着时间的推移,技术的更替,这部分内容也会不断更新。 因此这部分我不打算深入讲解,但是这部分很重要,这部分是真正落地的部分,更加偏实践的部分。
一个重要的原则就是只传输给用户所需要的代码。
4. 重复上述步骤
可以看出性能优化是一个不断反馈和优化的闭环,每一个环节都至关重要。下面我们一一分析各个环节。
浏览器性能指标
性能优化的第一步就是测量,没有测量就没有优化。我们不能为了优化而优化, 而是看到了某些点需要优化才去优化的。 而发现这个点一个重要的方式就是要靠测量。
说到测量,普遍接受的方式是,在浏览器中进行打点,将浏览器打开网页的过程看作是一个旅行。 那么我们每到一个地方就拍张带有时间的照片(事件),最后我们对这些照片按照时间进行排列, 然后分析哪部分是我们的瓶颈点等。
几个关键的指标
白屏时间
用户从打开页面开始到有页面开始呈现为止。白屏时间长是无法忍受的,因此有了很多的缩短白屏时间的方法。 比如减少首屏加载内容,首屏内容渐出等。白屏的测量方法最古老的方法是这样的:
<head>
<script>
var t = new Date().getTime();
</script>
<link src="">
<link src="">
<link src="">
<script>
tNow = new Date().getTime() - t;
</script>
</head>
但是上面这种只能测量首屏有html内容的情况,比如像react这样客户端渲染的方式就不行了。如果采用客户端渲染的方式,就需要在首屏接口返回, 并渲染页面的地方打点记录。
通过类似的方法我们还可以查看图片等其他资源的加载时间,以图片为例:
<img src="xx" id="test" />
<script>
var startLoad = new Date().getTime()
document.getElementById('test').addEventListener('load', function(){
var duration = new Date().getTime() - startLoad();
}, false)
</script>通过这种方法未免太麻烦,还在浏览器performance api 提供了很多有用的接口,方便大家计算各种性能指标。下面performance api 会详细讲解。
首屏加载时间
我们所说的首屏时间,就是指用户在没有滚动时候看到的内容渲染完成并且可以交互的时间。至于加载时间,则是整个页面滚动到底部,所有内容加载完毕并可交互的时间。用户可以进行正常的事件输入交互操作。
firstscreenready - navigationStart
这个时间就是用户实际感知的网站快慢的时间。firstscreenready 没有这个 performance api, 而且不同的渲染手段(服务端渲染和客户端渲染计算方式也不同),不能一概而论。具体计算方案,这边文章写得挺详细的。首屏时间计算
完全加载时间
通常网页以两个事件的触发时间来确定页面的加载时间.
- DOMContentLoaded 事件,表示直接书写在HTML页面中的内容但不包括外部资源被加载完成的时间,其中外部资源指的是css、js、图片、flash等需要产生额外HTTP请求的内容。
- onload 事件,表示连同外部资源被加载完成的时间。
domComplete - domLoading
Performance API
上面介绍了古老的方法测量关键指标,主要原理就是基于浏览器从上到下加载的原理。只是上面的方法比较麻烦,不适合实际项目中使用。 实际项目中还是采用打点的方式。 即在关键的地方埋点,然后根据需要将打点信息进行计算得到我们希望看到的各项指标,performance api 就是这样一个东西。
The Performance interface provides access to performance-related information for the current page. It’s part of the High Resolution Time API, but is enhanced by the Performance Timeline API, the Navigation Timing API, the User Timing API, and the Resource Timing API.
—— 摘自MDN
在浏览器console中输入performance.timing
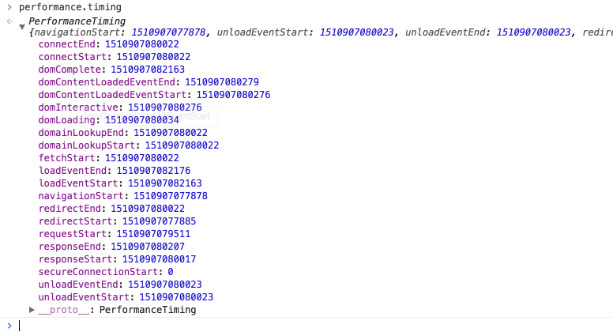
返回的各字节跟下面的performance流程的各状态一一对应,并返回时间。这个和js中直接new Date().getTime()的时间是不一样的。 这个时间和真实时间没有关系,而且perfermance api精确度更高。
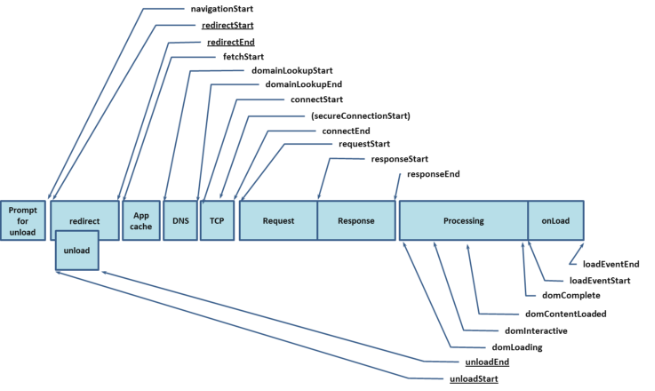
有了这个performance api 我们可以很方便的计算各项性能指标。如果performamce api ”埋的点“不够我们用,我们还可以自定义一些我们关心的指标,比如请求时间(成功和失败分开统计),较长js操作时间,或者比较重要的功能等。总之,只要我们想要统计的,我们都可以借助performance api 轻松实现。
performance api 更多介绍请查看 https://developer.mozilla.org/en-US/docs/Web/API/Performance
性能监测的手段
日志
监控是基于日志的
一个格式良好,内容全面的日志是实现监控的重要条件,可以说基础决定上层建筑。 良好的的日志系统通常有以下几个部分构成:
- 接入层
日志由产生到进入日志系统的过程。 比如rsyslog生成的日志,通过logstash(transport and process your logs, events, or other data)接入到日志系统。这种比较简单,由于是基于原生linux的日志系统,学习使用成本也比较低。公司不同系统如果需要介入日志系统,只需要将日志写入log目录,通过logstash等采集就可以了。
- 日志 处理层
这部分是日志系统的核心,处理层可以将接入层产生的日志进行分析。过滤日志发送到监控中心(监控系统状态)和存储中心(数据汇总,查询等)
- 日志存储层
将日志入库,根据业务情况,建立索引。这部分通常还可以接入像elastic search这样的库,提供日志的查询,上面的logstash 就是elastic家族的。
除了上面核心的几层,通常还有其他层完成更为细化的工作。
通常来说,一个公司的日志有以下几个方面
- 性能日志
记录一些关键指标,具体的关键指标可以参阅“浏览器性能指标”一节。
- 错误日志
记录后端的服务器错误(500,502等),前端的脚本错误(script error)。
- 硬件资源日志
记录硬件资源的使用率,比如内存,网络带宽和硬盘等。
- 业务日志
记录业务方比较关心的用户的操作。方便根据用户报的异常,定位问题。
- 统计日志
统计日志通常是基于存储日志的内容进行统计。统计日志有点像数据库视图的感觉,通过视图屏蔽了数据库的结构信息,将数据库一部分内容透出到用户。用户行为分析等通常都是基于统计日志分析的。有的公司甚至介入了可视化的日志统计系统(比如Kibana)。随着人工智能的崛起,人工智能+日志是一个方向。
性能日志
性能日志的产出
除了上面介绍的关键指标记录。我们通常还比较关心接口的响应速度。这时候我们可以通过打点的方式记录。
性能日志的消费
我们已经产出了日志,有了日志数据源。那么如何消费数据呢? 现在普遍的做法是服务端将收集的日志进行转储,并通过可视化手段(图标等)展示给管理员。还有一种是用户自己消费,即自产自销。用户产生数据,同时自己消费,提供更加的用户体验。 详情查阅 locus 但是性能日志明显不能自产自销,我们暂时只考虑第一种。
性能监测平台
监控平台大公司基本都有自己的系统。比如有赞的Hawk,阿里的SunFire。小公司通常都是使用开源的监控系统或者干脆没有。 我之前的公司就没有什么监控平台,最多只是阿里云提供的监控数据而已。所以我在这一方面做了一定的探索。并开始开发朱雀平台,但是限于精力有限,该计划最后没有最终投入使用,还是蛮可惜的。性能监测的本质是基于监测的数据,提供方便的查询和可视化的统计。并对超过临界值(通常还有持续时长限制)发出警告。 上一节介绍了性能监控平台,提到了性能监控平台的两个组成部分,一个是生产者一个是消费者。 这节介绍如何搭建一个监控平台。那么我先来看下整体的架构
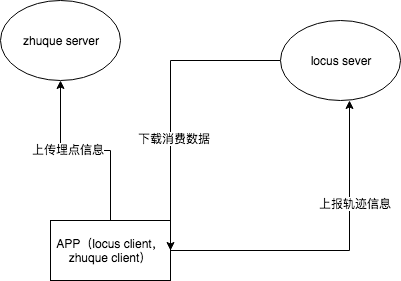
为了方便讲解,这里只实现一个最简化的模型,读者可以在此基础上进一步划分子系统,比如接入SSO,存储展示分离等。
客户端
客户端一方面上报埋点信息,另一方面上报轨迹信息。
上报埋点信息
这一部分主要借助一些手段,比如performance api 将网页相关加载时间信息上报到后端。
performance.getEntriesByType("resource").forEach(function(r) {
console.log(r.name + ": " + r.duration)
})
另一方面对特定的异步请求接口,打点。对用户所有的交互操作打点(点击,hover等)
const startTime = new Date().getTime();
fetch(url)
.then(res => {
const endTime = new Date().getTime();
report(url , 'success', endTime - startTime);
})
.catch(err => {
const endTime = new Date().getTime();
report(url, 'failure', endTime - startTime);
})
上报轨迹信息
上传轨迹信息就简单了。如果是页面粒度,直接在页面上报就可以了。如果使用了前端路由,还可以在路由的钩子函数中进行上报。
pageA.js
// 上报轨迹
report('pageA',{userId: '876521', meta: {}})
这样我们就有了数据源了。
服务端
服务端已经有了数据,后端需要将数据进行格式化,并输出。
locus server
客户端将自己的信息上报到server,由server进行统计汇总,并在合适的时候将处理后的数据下发到客户端,指导客户端的行为(如预加载)。
前面说了客户端上传的信息大概是
{
userId: 876521,
page: "index",
area: "",
age: "",
// 其他群体特征
}
我们称地域,年龄等为群体特征,群体特征对于分析统计有非常重要的意义。
我们可以对单用户进行汇总,也可以对群体特征进行汇总从而预测客户的行为。
我们汇总的数据可能是:
{
userId: '876521',
pages: {
"index": {
"detail": 0.5,
"return": 0.4,
"personnal-center": 0.1
}
}
}
如上是以用户为纬度进行分析。上面的数据代表,如果用户876521在首页(index),那么ta下一步访问详情页(detail)的概率是50%,访问个人中心(personal-center)的概率为10%,退出页面概率为40%。
我们就可以在可能的情况下,用户停留在首页的时候预加载详情页。
我们还可以对群体特征进行汇总,
汇总的结果可能是:
{
age: 'teen',
pages: {
"index": {
"detail": 0.5,
"return": 0.4,
"personnal-center": 0.1
}
}
}
其实和上面差不多,不过这里并不是只是用来指导某一个用户,而是可以指导同一个群体特征(这里指同一年龄段)的用户。
zhuque server
客户端会上传性能信息给zhuque server。
zhuque server 在这里主要有两个职责:
- 将用户上报的数据可视化输出出来,供不同的人查看。
这部分通常做起来简单,做好难。 我在这方面经验不够多,就不误导大家了。
- 提供警报服务,如页面超长时间无响应,打不开,关键资源404等问题。
警报种类有很多,比如邮件,电话,短信,钉钉等。 我们只要设置好触发条件,然后写一个定时任务或者在请求级别进行检查,如果满足就触发警报即可。逻辑非常简单。
定时任务对系统的压力较小,但是及时性较低,适合对实时性要求不强的业务。 请求级别检查謉系统压力较大,但是及时性有保障,适合对实时性要求非常高的业务。
性能优化的手段
要做性能优化,首先要对系统运行的过程有一个完整的理解,然后从各个环节分析,找到系统瓶颈,从而进行优化。在这里我不罗列性能优化的各种手段,而是从前端三层角度逐个描述下性能优化的常见优化方向和手段。如果大家希望有一个完整的优化清单, 这里有一份比较完整的Front-End-Checklist,对于性能优化,有一定的借鉴意义。另外你也可以访问webpagetest测试你的网站的性能,并针对网站提供的反馈一步步优化你的网站加载速度,这些内容不在本文论述范围。 性能优化一个最重要的原则是:永远呈现必要的内容,我们可以通过懒加载非首屏资源,或者采用分页的方式将数据”按需加载“。下面讲述一些具体的优化手段。 很多人都知道,前端将应用分为三层,分别是结构层,表现层和行为层。我们就从三层角度讲一下性能优化的方向。
这部分的优化手段指的是在给定传输文件大小的情况下去优化,也就是说不考虑传输层面的优化
结构层
结构层指的是DOM结构,而DOM结构通常是由HTML结构决定的,因此我们主要分析下HTML结构的性能优化点。 我们知道DOM操作是非常昂贵的,这在前面讲述前端发展历史的时候也提到了。如何减少DOM数量,减少DOM操作是优化需要 重点关注的地方。
AMP HTML
说到HTML优化,不得不提AMP HTML。 AMP的核心思想是提供移动端更佳的用户体验,。由AMP HTML, AMP JS 和 AMP Cache 三个核心部分组成。
AMP HTML is HTML with some restrictions for reliable performance.
下面是典型的AMP HTML
<!doctype html>
<html ⚡>
<head>
<meta charset="utf-8">
<link rel="canonical" href="hello-world.html">
<meta name="viewport" content="width=device-width,minimum-scale=1,initial-scale=1">
<style amp-boilerplate>body{-webkit-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-moz-animation:-amp-start 8s steps(1,end) 0s 1 normal both;-ms-animation:-amp-start 8s steps(1,end) 0s 1 normal both;animation:-amp-start 8s steps(1,end) 0s 1 normal both}@-webkit-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-moz-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-ms-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@-o-keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}@keyframes -amp-start{from{visibility:hidden}to{visibility:visible}}</style><noscript><style amp-boilerplate>body{-webkit-animation:none;-moz-animation:none;-ms-animation:none;animation:none}</style></noscript>
<script async src="https://cdn.ampproject.org/v0.js"></script>
</head>
<body>Hello World!</body>
</html>
可以看出AMP HTML由普通的HTML标签和amp标签组成。amp标签是做什么呢?且听我跟你说,DOM虽然操作比较昂贵,但是不同的DOM效率也是不意义的。比如渲染一个a标签和渲染一个img或者table时间肯定不是一样的。我们称a标签这样渲染较快的元素为轻元素。称table,img这样的元素为重元素。那么我们就应该尽量避免重元素的出现,比如table 可以采用ul li 实现。 img之所以比较慢的原因是图片下载虽然是异步的,但是会占用网络线程,同时会多发一个请求(浏览器并发请求数是有限制的),因此可以进一步封装称轻元素(比如x-image,组件内部可以延迟发送图片请求,等待主结构渲染完毕再发图片请求)。 可以考虑将其封装为web-component或者其他组件形式(如react组件)
回到刚才AMP HTML, 其实在amp 中 有一个amp-image这样的接口,大概可以根据需要自己实现,上面我们说的x-image 其实就是实现了amp接口规范的组件。
减少没有必要的嵌套
前面说到了尽可能使用轻元素。那么除了使用轻元素,还有一点也很重要,就是减少DOM数量。减少DOM数量的一个重要的途径就是减少冗余标签。比如我们通过新增加一个元素清除浮动。
<div class="clear"></div>
不过目前都是采用伪元素实现了。另一个途径是减少嵌套层次。很多人都会在<form>或者<ul>外边包上<div>标签,为什么加上一个你根本不需要的<div>标签呢?实际上你完全可以用CSS selector,实现同样的效果。 重要的是,这种代码我见过很多。
<div class="form">
<form>
...
</form>
</div>
完全可以这样写:
<form class="form">
...
</form>
表现层
表现层就是我们通常使用的CSS。CSS经过浏览器的解析会生成CSS TREE,进而和DOM TREE合成 RENDER TREE。有时候一些功能完全可以通过CSS去实现,没有必要使用javaScript,尤其是动画方面,CSS3增加了transition 和 transform 用来实现动画,开发者甚至可以通过3D加速功能来充分发挥GPU的性能。因此熟练使用CSS,并掌握CSS的优化技巧是必不可少的。CSS 的性能优化通常集中在两方面:
提高CSS的加载性能
提高加载性能就是减少加载所消耗的时间。简单说就是减小CSS文件的大小,提高页面的加载速度,尽可以的利用http缓存等。代码层面我们要避免引入不需要的样式,合理运用继承减少代码。
<body>
<div class="list" />
</body>
body { color: #999 }
.list {color: #999} // color 其实可以继承body,因此这一行没必要
其他可以继承的属性有color,font-size,font-family等。
通常来说这部分和JS等静态资源的优化道理是一样的。只不过目前网站有一个理念是框架优先,即先加载网站的主题框架,这部分通常是静态部分,然后动态加载数据,这样给用户的感觉是网站”很快“。而这部分的静态内容,通常可以简单的HTML结构(Nav + footer),加上CSS样式来完成。 这就要求主题框架的CSS优先加载,我们设置可以将这部分框架样式写到内敛样式中去,但是有的人觉得这样不利于代码的维护。
提高CSS代码性能
浏览器对不同的代码执行效率是不同的,复杂的样式(多层嵌套)也会降低css解析效率,因此可以将复杂的嵌套样式进行转化。
.wrapper .list .item .success {}
// 可以写成如下:
.wrapper .list .item-success {}
还有一部分是网站的动画,动画通常来说要做到16ms以内,以让用户感觉到非常流畅。另外我们还可以通过3D加速来充分应用GPU的性能。 这里引用于江水的一句话:
只有在非常复杂的页面,样式非常多的时候,CSS 的性能瓶颈才会凸显出来,这时候更多要考虑的应该是有没有必要做这么复杂的页面。
行为层
行为层指的是用户交互方面的内容,在前端主要通过JavaScript实现。目前JavaScript 规范已经到es2017。 前端印象较为深刻的是 ES6(也就是ES2015),因为ES5是2009年发布的,之后过了6年,也就是2015年ES6才正式发布,其中增加了许多激动人心的新特性, 被广大前端所熟悉。甚至曾一度称目前前端状态是536(HTML5,CSS3,ES6),可见其影响力。 JS或许是前端最昂贵的资源了,其相对于css,fonts,images的处理,需要更多的资源。这里有一篇很棒的文章the-cost-of-javascript-in-2018,详细阐述了为什么js这么昂贵,以及如何改进。
毫不夸张的说,目前前端项目绝大多数代码都是javascript。既然js用的这么多,为什么很少有人谈js性能优化呢? 一是因为现在工业技术的发展,硬件设备的性能提升,导致前端计算性能通常不认为是一个系统的性能瓶颈。二是随着V8引擎的发布,js执行速度得到了很大的提升。三是因为计算性能是本地CPU和内存的工作,其相对于网路IO根本不是一个数量级,因此人们更多关注的是IO方面的优化。那么为什么还要将js性能优化呢?一方面是目前前端会通过node做一些中间层,甚至是后端,因此需要重点关注内存使用情况,这和浏览器是大相径庭的。另一方面是因为前端有时候也会写一个复杂计算,也会有性能问题。 最后一点是我们是否可以通过JS去优化网络IO的性能呢,比如使用JS API 操作 webWorker 或者使用localStorage缓存。
计算缓存
前端偶尔也会有一些数据比较大的计算。 对于一些复杂运算,通常我们会将计算结果进行缓存,以供下次使用。前面提到了纯函数的概念,要想使用计算缓存,就要求函数要是纯函数。一个简单的缓存函数代码如下:
// 定义
function memoize(func) {
var cache = {};
var slice = Array.prototype.slice;
return function() {
var args = slice.call(arguments);
if (args in cache)
return cache[args];
else
return (cache[args] = func.apply(this, args));
}
}
// 使用
function cal() {}
const memoizeCal = memoize(cal);
memoizeCal(1) // 计算,并将结果缓存
memoizeCal(1) // 直接返回
网络IO缓存
前面讲了计算方面的优化,它的优化范围是比较小的。因为并不是所有系统都会有复杂计算。但是网络IO是所有系统都存在的,而且网络IO是不稳定的。网络IO的 速度和本地计算根本不是一个数量级,好在我们的浏览器处理网络请求是异步的(当然可以代码控制成同步的)。一种方式就是通过本地缓存,将网络请求结果存放到本地,在下次请求的时候直接读取,不需要重复发送请求。一个简单的实现方法是:
function cachedFetch(url, options) {
const cache = {};
if (cache[url]) return cache[url];
else {
return fetch(url, options).then(res) {
cache[url] = res
return res;
}
}
}
当然上面的粗暴实现有很多问题,比如没有缓存失效策略(比如可以采用LRU策略或者通过TTL),但是基本思想是这样的。 这种方式的优点很明显,就是显著减少了系统反馈时间,当然缺点也同样明显。由于使用了缓存,当数据更新的时候,就要考虑缓存更新同步的问题,否则会造成数据不一致,造成不好的用户体验。
数据结构,算法优化
数据结构和算法的优化是前端接触比较少的。但是如果碰到计算量比较大的运算,除了运用缓存之外,还要借助一定的数据结构优化和算法优化。 比如现在有50,000条订单数据。
const orders = [{name: 'john', price: 20}, {name: 'john', price: 10}, ....]
我需要频繁地查找其中某个人某天的订单信息。 我们可以采取如下的数据结构:
const mapper = {
'john|2015-09-12': []
}
这样我们查找某个人某天的订单信息速度就会变成O(1),也就是常数时间。你可以理解为索引,因为索引是一种数据结构,那么我们也可以使用其他数据结构和算法适用我们各自独特的项目。对于算法优化,首先就要求我们能够识别复杂度,常见的复杂度有O(n) O(logn) O(nlogn) O(n2)。而对于前端,最基本的要识别糟糕的复杂度的代码,比如n三次方或者n阶乘的代码。虽然我们不需要写出性能非常好的代码,但是也尽量不要写一些复杂度很高的代码。
多线程计算
通过HTML5的新API webworker,使得开发者可以将计算转交给worker进程,然后通过进程通信将计算结果回传给主进程。毫无疑问,这种方法对于需要大量计算有着非常明显的优势。
代码摘自Google performance:
var dataSortWorker = new Worker("sort-worker.js");
dataSortWorker.postMesssage(dataToSort);
// The main thread is now free to continue working on other things...
dataSortWorker.addEventListener('message', function(evt) {
var sortedData = evt.data;
// Update data on screen...
});
由于WebWorker 被做了很多限制,使得它不能访问诸如window,document这样的对象,因此如果你需要使用的话,就不得不寻找别的方法。
一种使用web worker的思路就是分而治之,将大任务切分为若干个小任务,然后将计算结果汇总,我们通常会借助数组这种数据结构来完成,下面是一个例子:
// 很多小任务组成的数组
var taskList = breakBigTaskIntoMicroTasks(monsterTaskList);
// 使用更新的api requestAnimationFrame而不是setTimeout可以提高性能
requestAnimationFrame(processTaskList);
function processTaskList(taskStartTime) {
var taskFinishTime;
do {
// Assume the next task is pushed onto a stack.
var nextTask = taskList.pop();
// Process nextTask.
processTask(nextTask);
// Go again if there’s enough time to do the next task.
taskFinishTime = window.performance.now();
} while (taskFinishTime - taskStartTime < 3);
if (taskList.length > 0)
requestAnimationFrame(processTaskList);
}
线程安全问题都是由全局变量及静态变量引起的。 若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,就需要考虑线程同步,就可能产生线程安全问题。
大家可以不必太担心,web worker已经在这方面做了很多努力,例如你没有办法去访问非线程安全的组件或者是 DOM,此外你还需要通过序列化对象来与线程交互特定的数据。因此大家如果想写出线程不安全的代码,还真不是那么容易的。
V8引擎下的代码优化
V8是由Google提出的,它通过将js代码编译成机器码,而非元组码或者解释它们,进而提高性能。V8内部还封装了很多高效的算法,很多开发者都会研究V8的源码来提升自己。 这里有些js优化的实践,详情可看下这篇文章 还有很多其他有趣的研究。
Benedikt Meurer(Tech Lead of JavaScript Execution Optimization in Chrome/V8)本人致力于V8的性能研究,写了很多有深度的文章,并且开源了很多有趣的项目,有兴趣的可以关注一下。
内存泄漏
前端中的内存泄漏不是很常见,但是还是有必要知道一下,最起码能够在出现问题的时候去解决问题。更为低级的语言如C语言,有申请内存malloc和销毁内存free的操作。而在高级语言比如java和js,屏蔽了内存分配和销毁的细节,然后通过GC(垃圾回收器)去清除不需要使用的内存。
只有开发人员自己知道什么时候应该销毁内存。
好在内存销毁还是有一定规律可循,目前GC的垃圾回收策略主要有两种,一种是引用计数,另一种是不可达检测。目前主流浏览器都实现了上述两种算法,并且都会综合使用两种算法对内存进行优化。但是确实还存在上述算法无法覆盖的点,比如闭包。因此还是依赖于开发者本身的意识,因此了解下内存泄漏的原理和解决方案还是非常有用的。下面讲述容易造成内存泄漏的几种情况。
尾调用
函数调用是有一定的开销的,具体为需要为函数分配栈空间。如果递归调用的话,有可能造成爆栈。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(100) // 一切正常
factorial(1000) // 有可能爆栈,但是现在浏览器做了优化,通常会输出Infinite
}
如果在这里你使用了比较复杂的运算情况就会变糟,如果再加上闭包就更糟糕了。
闭包
由于js没有私有属性,js如果要实现私有属性的功能,就要借助闭包实现。
function closure() {
var privateKey = 1;
return function() {
return privateKey
}
}
但是由于js的垃圾回收机制,js会定期将没有引用的内存释放,如果使用闭包,函数会保持变量的引用,导致垃圾回收周期内不能将其销毁,滥用闭包则可能产生内存泄漏。
图片优化
上面从前端三层角度分析了性能优化的手段,但是还有一个,而且是占比非常大的资源没有提到,那就是图片。俗话说,一图胜千言,图片在目前的网站中占据了网站中大部分的流量。虽然图片不会阻止用户的交互,不影响关键路径,但是图片加载的速度对于用户体验来说非常重要。尤其是移动互联网如此发达的今天,为用户节省流量也是非常重要的。因此图片优化主要有两点,一点是在必要的时候使用图片,不必要的时候换用其他方式。另一种就是压缩图片的体积。
明确是否需要图片
首先要问问自己,要实现所需的效果,是否确实需要图像。好的设计应该简单,而且始终可以提供最佳性能。如果您可以消除图像资源(与 HTML、CSS、JavaScript 以及网页上的其他资源相比,需要的字节数通常更大),这种优化策略就始终是最佳策略。不过,如果使用得当,图像传达的信息也可能胜过千言万语,因此需要由您来找到平衡点。
压缩图片体积
首先来看下图片体积的决定因素。这里可能需要一些图像学的相关知识。图片分为位图和矢量图。位图是用比特位来表示像素,然后由像素组成图片。位图有一个概念是位深,是指存储每个像素所用的位数。那么对于位图计算大小有一个公式就是图片像素数 * 位深 bits。 注意单位是bits,也可以换算成方便查看的kb或者mb。
图片像素数 = 图片水平像素数 * 图片垂直像素数
而矢量图由数学向量组成,文件容量较小,在进行放大、缩小或旋转等操作时图象不会失真,缺点是不易制作色彩变化太多的图象。那么矢量图是电脑经过数据计算得到的,因此占据空间小。通常矢量图和位图也会相互转化,比如矢量图要打印就会点阵化成位图。
下面讲的图片优化指的是位图。知道了图片大小的决定因素,那么减少图片大小的方式就是减少分辨率或者采用位深较低的图片格式。
减少分辨率
我们平时开发的时候,设计师会给我们1x2x3x的图片,这些图片的像素数是不同的。2x的像素数是1x的 2x2=4倍,而3x的像素数高达3x3=9倍。图片直接大了9倍。因此前端使用图片的时候最好不要直接使用3倍图,然后在不同设备上平铺,这种做法会需要依赖浏览器对其进行重新缩放(这还会占用额外的 CPU 资源)并以较低分辨率显示,从而降低性能。 下面的表格数据来自Google Developers
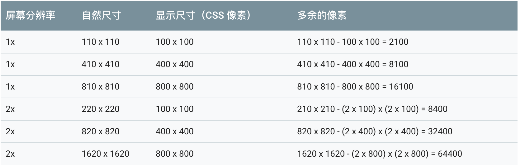
请注意,在上述所有情况下,显示尺寸只比各屏幕分辨率所需资源“小 10 个 CSS 像素”。不过,多余像素数及其相关开销会随图像显示尺寸的增加而迅速上升!因此,尽管您可能无法保证以精确的显示尺寸提供每一个资源,但您应该确保多余像素数最少,并确保特别是较大资源以尽可能接近其显示尺寸的尺寸提供。
我们可以使用媒体查询或者srcset等针对不同屏幕加载不同资源。但是9倍这样的大小我们还是很难接受。因此有了下面的方法。
减少位深
位深是用来表示一个颜色的字节数。位深是24位,表达的是使用256(2的24/3次方)位表示一个颜色。因此位深越深,图片越精细。如果可能的话,减少位深可以减少体积。
压缩
前面说了图片大小 = 图片像素数 * 位深, 其实更严格的是图片大小 = 图片像素数 * 位深 * 图片质量, 因此图片质量(q)越低,图片会越小。 影响图片压缩质量的因素有很多,比如图片的颜色种类数量,相邻像素颜色相同的个数等等。对应着有很多的图片压缩算法,目前比较流行的图片压缩是webp格式。因此条件允许的话,尽量使用webp格式。
图片优化的具体实践
有了上面的理论之后,我们需要将理论具体运用在实践上。 我们平时开发的时候会有缩略图的需求,如果你将原始图片加载过来通过css控制显示的话,你会发现你会加载一个非常大的图片,然而本身应该很小才对。那么如果我们可以控制只下载我们需要缩略显示的部分就好了。我们希望可以通过https://test.imgix.net/some_file?w=395&h=96&crop=faces的方式指定图片的大小,从而减少传输字节的浪费。已经有图片服务商提供了这样的功能。比如imgix。
imgix有一个优势就是能够找到图片中有趣的区域并做裁剪。而不是仅仅裁剪出图片的中心
上面提到的webp最好也可以通过CDN厂商支持,即我们上传图片的时候,CDN厂商对应存储一份webp的。比如我们上传一个png图片https://img.alicdn.com/test/TB1XFdma5qAXuNjy1XdXXaYcVXa-29-32.png。然后我们可以通过https://img.alicdn.com/test/TB1XFdma5qAXuNjy1XdXXaYcVXa-29-32.webp访问其对应的webp资源。我们就可以根据浏览器的支持情况加载webp或者png图片了。
第二个有效的方式是懒加载,一个重要的思想就是只加载应该在此时展示的图片。假如你正在使用react,那么你可以通过react-lazyload使用图片懒加载。其他框架可以自行搜索。
import LazyLoad from 'react-lazyload';
<LazyLoad once height={200} offset={50}>
<img
srcSet={xxx}
sizes={xxxxx}
/> </LazyLoad>一个实例
前面说了性能优化更像是软件的一个指标,是一种被全体人员(包括非技术人员)普遍认同的一个特性。 因此它需要各方面的人员通力合作,虽然从表现上来看,性能优化最终是开发人员(可以是前端,也可以是后端,DBA等),但是它一定要是全体员工的认同。
假设公司给出计划,计划在下一个季度将首次访问移动端商城首页的首屏时间优化到5s以内。 接下来访问白屏时间在2s以内。 我们现在被要求来做这件事情,我们应该怎么做呢?
首先这个目标需要被更清晰的描述。 3s是一个具体的数字,本身没有问题,但是这个目标本身缺乏限定条件。比如什么样的手机,什么样的网络情况,什么样的地址位置。
因此我们需要与决策者进行沟通,将限定条件搞清楚。假设我们搞清楚了限定条件, 是1000块的中端机以及苹果6s,在3g条件下,地理位置就在本省行政区域内。 接下来我们需要实际的测量数据,以便我们分析数据以及和优化后的数据做对比。
首次渲染
假设DNS查询和TLS握手需要花费1.6s. 那么我们只剩下5s - 1.6s = 3.4s
1.6s 是根据实际测量结果给出的
国内三大运营商的3G网络数据理论上是350kb/s , 由于地地形和周边设施等因素,实际测试平均大约在100kb/s左右。 这里以100kb/s计算。
那么我们可以传输的文件大小理论上最大 为 100kb/s * 3.4s = 340kb. 因此我们需要将我们的网站的首屏加载的文件大小总和控制在340kb. 通常来说,控制在170kb以内比较理想。 我们按照170kb计算。
前面已经探讨了网页加载的原理,那么文件传输只是其中一部分, 但是由于其所占比例非常大,我们这里注明是理论上的最大值。
前面说过的170kb是gzip之后的文件大小,通常来说gzip对文件大小的压缩比率为5x - 7x.
压缩比率取决于算法本身,文件重复率等
那么压缩前文件的大小为850kb - 1M 左右。
如今,我们的项目大都会引用一些UI框架如reactjs, vuejs,会用状态管理库,比如redux,vuex等,为了兼容低版本的浏览器会有polyfill,会有UI组件库等等. 他们都会给我们的应用增加体积, 因此引入一个库的时候一定要知道它给我们带来了什么,我们是否需要它的全部功能。 比如momentjs,我们是否一定要引入这样一个库,是否可以使用更精简的库来代替,或者将locales去除等。
如上所说其实是项目的依赖,项目的依赖要比我们的代码多得多。因此管理依赖要比管理我们的代码本身更具有复杂性和挑战性。
如下一个实际项目的业务代码和依赖的代码分布情况。
du -s src
# 6
du -s node_modules
# 257
可以看出依赖的大小为业务代码的40多倍。而且我的这个项目本身来说还属于比较简单的, 更复杂的项目通常这个比例会更大。你也可以试试你自己的项目。
明白了这些基本点,并且我们已经拿到了一组测量的数据。 通过这组数据,我们大可以分析出占用时间较长的环节。 然后我们就需要一些知识和工具帮助我们正确地找到真正的问题。 比如我们可以通过light house来测量数据,然后通过chrome dev tool来分析单次的访问记录。 比如我们可以找出耗时较长的任务是什么, 是重排还是JS执行等。 然后找到影响的相关代码进行优化,最后别忘了验证。 然后拿出前后的对比数据来给自己和大家看。
强烈建议大家将性能检测加入到CI中,然后给项目进行打分。 低于一定分数的项目当成是构建失败对待。 只有将性能的重要性提到这个高度,我们才能够真正的不断精进,而不是一时之快。 市面上这样的工具很多,比如light-house-ci。
加入到CI另一个好处,项目的性能是透明可视化的,这对于管理层了解项目的情况尤为重要。不要小看这一点,很多管理层对于你的各种理论无动于衷, 但是他们对于数字(分数,性能指标)有着很高的兴趣和敏感性。 如果你这么做了,那么你更会体会到性能优化远不止技术上的优化, 它伴随着很多其他过程和各方面的取舍。
非首次渲染
关于非首次渲染,我们可以通过网络缓存的形式减少静态资源的下载时间。这部分时间是相当可观的,它占据了网页访问的大部分时间。
那么非首次访问就不需要考虑网络因素,那么影响非首次访问速度的因素大概会有:
- 加载webview以及webview的启动时间
- 从磁盘读取缓存的时间
- 渲染的时间(执行代码,layout,paint等)
明白了优化点之后,就需要对症下药。 首先还是要测量各个部分实际的时间,然后利用工具诊断,发现问题。由于每一个部分都有可能拖慢整体的速度,并且引起各个部分变慢的因素理论上说是无限的。因此不可能在这里涵盖,希望大家可以利用之前讲过的技巧来分析并找到问题。
总结
如果你已经采取了非常多的优化手段,用户还是觉得非常慢,怎么办呢?要知道,性能好不好不是数据测量出来的,而是用户的直观感觉,就像我开篇讲述的那样。有一个方法可以在速度不变的情况下,让用户感觉更快,那就是合理使用动画。如一个写着当前90%进度的进度条,一个奔跑的小熊?但是一定要慎用,因为不合理的动画设计,反而让用户反感,试想一下,当你看到一个期待已久的确定按钮,但是它被一个奔跑的小熊挡在了身后,根本点不到,你内心会是怎样的?
另外我在这里只是提供了性能优化的思路,并没有覆盖性能优化的所有点,比如google的protobuffer可以减少前后端传输数据的体积,进而提升性能。但是我们 有了上面的优化理论和思想,我相信这些东西都是可以看到并做到的
欢迎关注公众号,进一步技术交流:


