MySQL索引
为什么MySQL索引是B+树?
本质上是IO问题,从两个方面分析
-
减少IO量
-
减少IO次数
从操作系统方面分析
局部性原理
时间:之前被访问过的数据很有可能再次被访问
空间:数据和程序都有聚集成群的倾向
磁盘预读:
内存跟磁盘在进行交互的时候有一个最小的逻辑单位,这个单位称之为页,一般是4k或者是8k,由操作系统决定,我们在进行数据读取的时候,一般会读取页的整数倍,也就是4k,8k,16k,Innodb存储引擎在进行数据加载的时候读取的是16kb的数据
从索引的数据结构分析
Hash对于范围查找有随机性
二叉树当需要向这些树中插入更多数据的时候,会导致当前树变得非常高,会加大读取的次数影响查询效率
B树每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小。当数据量很大的时候会导致深度比较大,增大查询时io次数,进而影响查询性能
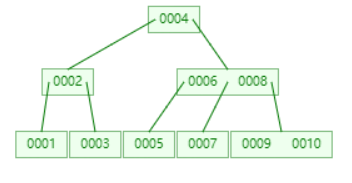
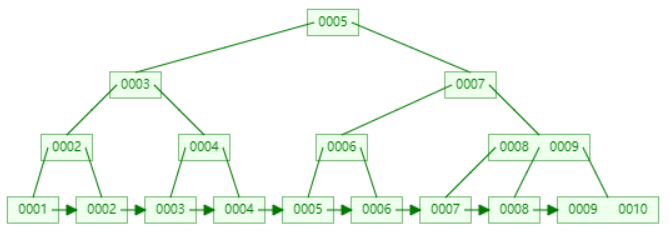
B+树
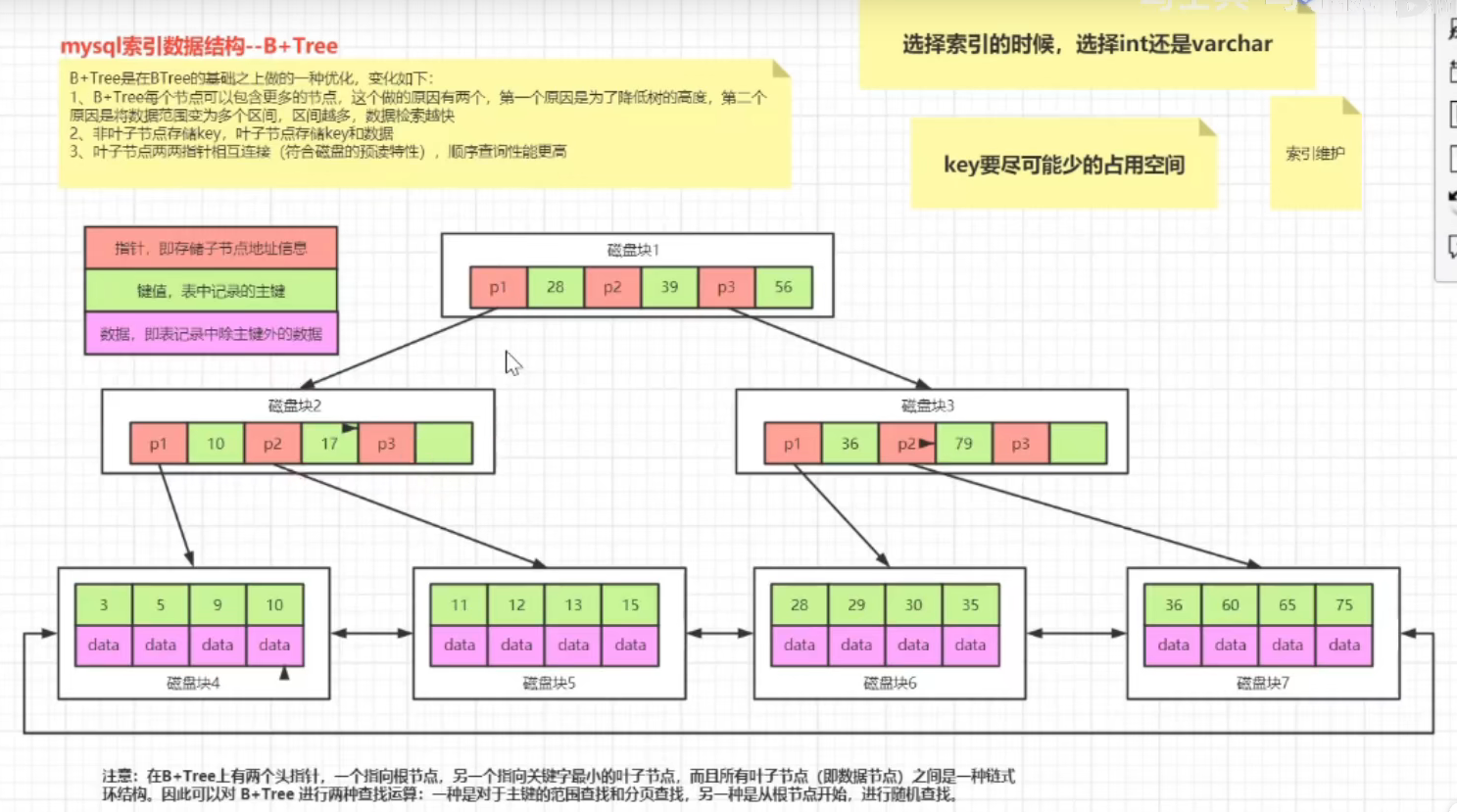
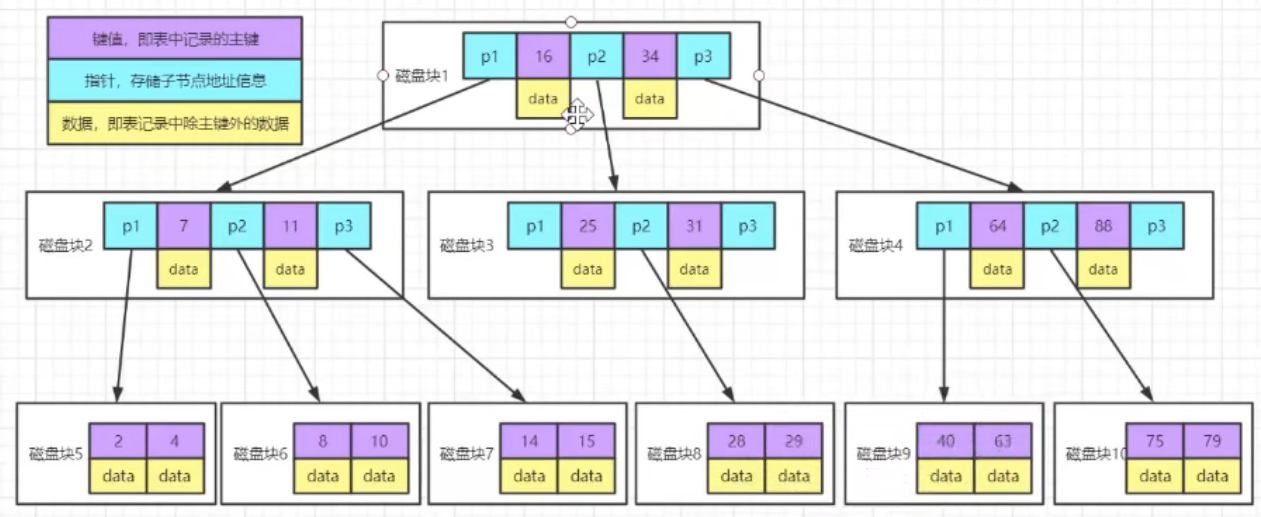
B+树是B树基础上的一种优化,使其更适合实现外存储索引结构,InoDB存储引擎就是用B+树实现其索引结构
从上一节中的B树结构图可以看到每一个结点不仅包含数据的key值还有data值,而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点能存储的key的数量很小,当存储的数据量很大时同样会导致B树的深度比较大,增大了查询时的磁盘I/O次数,进而影响效率,在B+树中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低了B+树的高度
B+树相对于B树的几点不同:
-
非叶子节点只存储键值信息
-
所有叶子节点之间都有一个链指针
-
数据记录都在叶子节点中
MySQL索引
MySQL
1.什么是索引
官方定义:一种帮助mysql提高查询效率得数据结构
索引的优点:
1. 大大加快数据查询速度
索引的缺点:
1. 维护索引需要消耗数据库资源
2. 索引需要占用磁盘
3. 当对表得数据进行增删改查的时候,因为要维护索引所以速度会受到影响
2.索引分类
InnoDB
-
主键索引 设定为主键后数据库会自动建立索引,innodb为聚簇索引不能为null
-
单值索引 即一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引 索引的值必须唯一,但允许有空值
-
复合索引 一个索引包含多个列
MyiSAM
-
全文索引
最左前缀原则中的细节
建立(name,age,bir)的索引 1.最左前缀原则 2.mysql在查询时为了更好的利用索引,在查询过程中会动态的调整字段顺序以便利用索引
name bir age 能利用索引
name age bir 能利用索引
age bir 不能利用索引
bir age name 能利用索引
age bir 不能利用索引
聚簇索引和非聚簇索引
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
在innodb中,在聚簇索引之上创建的索引称之为辅助索引,非聚簇索引都是辅助索引,像复合索引,前缀索引,唯一索引,辅助索引叶子节点存储的不再是行的物理位置而是主键值,辅助索引访问数据总是需要二次查找
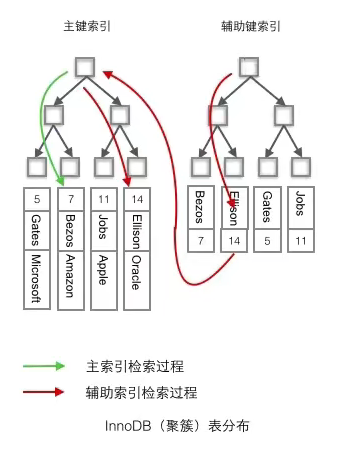
使用聚簇索引的优势
问题:每次使用辅助索引检索都需要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪?
-
由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多行数据,访问同一数据页不同记录时,已经把页加载到了Buffer中,再次访问时,不必访问磁盘,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
-
辅助索引的叶子节点,存储主键值,而不是数据的存放地址,好处是当行数据发生变化时,索引树的节点也需要分裂变化,或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引就好了,另一个好处是辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
聚簇索引需要注意什么
-
-
建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小,而且,主键值占用的存储空间越大,辅助索引中保存的主键值也随着变大,占用存储空间,也会影响IO操作读取到的数据量
聚簇索引一定是主键吗
有人会疑虑似乎聚簇索引一定会是主键,那如果数据表不建立主键的话是否就没有聚簇索引了? 在 InnoDB 中,聚集索引不一定是主键,但是主键一定是聚集索引:原因是如果没有定义主键,聚集索引可能是第一个不允许为 null 的唯一索引,如果也没有这样的唯一索引,InnoDB 会选择内置 6 字节长的 ROWID 作为隐含的聚集索引。 InnoDB 的数据是按照主键顺序存放的,而聚集索引就是按照每张表的主键构造一颗 B+ 树,它的叶子节点存放的是整行数据。 每张 InnoDB 表都有一个聚集索引,但是不一定有主键。
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引相邻的,那么对应的数据一定也是相邻的存放在磁盘上的,如果主键不是自增id,那么可以想象,它会干些什么,不断的调整数据的物理地址,分页,当然也有一些其他措施来减少这些操作,但无法彻底避免,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号