布隆过滤器——海量数据下位数组的强大
问题提出
Redis中如果出现缓存穿透的情况,我们通常采用两种方式
-
缓存空对象,对于数据库中查询不到的对象就写入Redis中并设置过期时间,
-
布隆过滤器,布隆过滤器可以方便的判断一个数据是否存在于海量数据中
介绍
布隆过滤器是一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。

原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
-
使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
-
根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
-
对给定元素再次进行相同的哈希计算;
-
得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
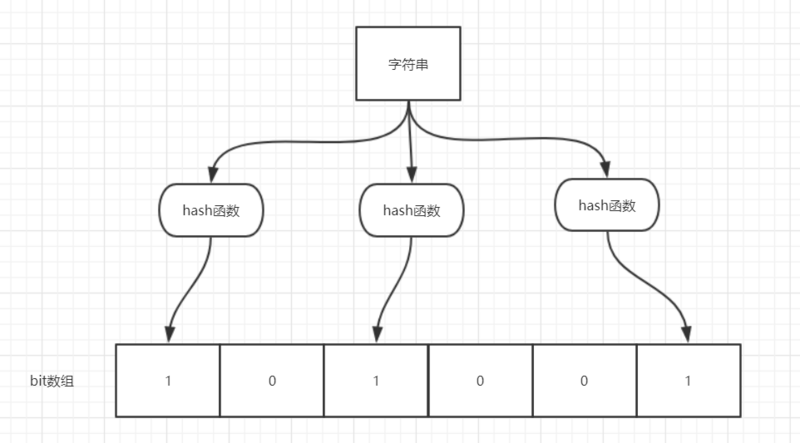
明白原理后,我们就容易理解到为什么会有误判的情况了,正是因为在海量数据的情况下即使不存在的数据有可能在经过多个哈希函数的运算下都得到1
布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
使用场景
-
判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号