Redis入门
Nosql
Nosql = Not Only SQL
泛指非关系型数据库的,随着web2.0互联网的诞生,传统的关系型数据库很难对付web2.0是滴啊,尤其是超大规模的高并发的社区,暴露出很多难以克服的问题,Nosql在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是当下必须要掌握的一门技术!很多数据类型用户的个人信息,社交网络,地理位置,这些数据类型的存储不需要一个固定的格式。<!--more-->
Nosql
不仅仅是数据
没有固定的查询语言
键值对存储,列存储,文档存储,图形数据库(社交关系)
最终一致性
CAP定理和BASE
高性能,高可用,高可拓
四大分类
KV键值对
-
新浪:Redis
-
美团:Redis + Tair
-
BA : Redis + memecache
文档型数据库
-
MongoDB
-
MongoDB是一个基于分布式文件存储的数据库,c++编写,主要用来处理大量文档
-
MongoDB是一个介于关系型数据库和非关系型数据中中间的产物,MongoDB是非关系型数据库中功能丰富,最像关系型数据库
-
-
ConthDB
列存储数据库
-
Hbase
-
分布式文件系统
图关系数据库
-
不是存放图形,存放的是关系,比如:朋友圈社交网络,广告推荐
-
Neo4j,InfoGrid
Redis入门
概述
Redis能干吗
-
内存存储,持久化,内存是断电即失,所以说持久化很重要(rdb,aof)
-
效率高,可以用于高速缓存
-
发布订阅系统
-
地图信息分析
-
计时器,计数器(微信,微博浏览量)
-
....
Linux安装
-
下载安装包 https://redis.io/
-
解压Redis安装包到opt文件夹下
图1 解压redis到opt目录下
-
基本环境的安装
图2 检验yum install gcc-c++成功
图3 检验make成功
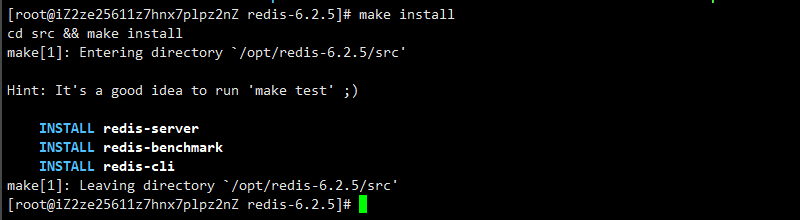
-
redis的默认安装路径是/usr/local/bin
图4 redis默认安装路径

将redis配置文件复制到当前目录下(这里在当前目录下创建一个目录用于存储配置文件)
图5 复制redis.conf所在位置
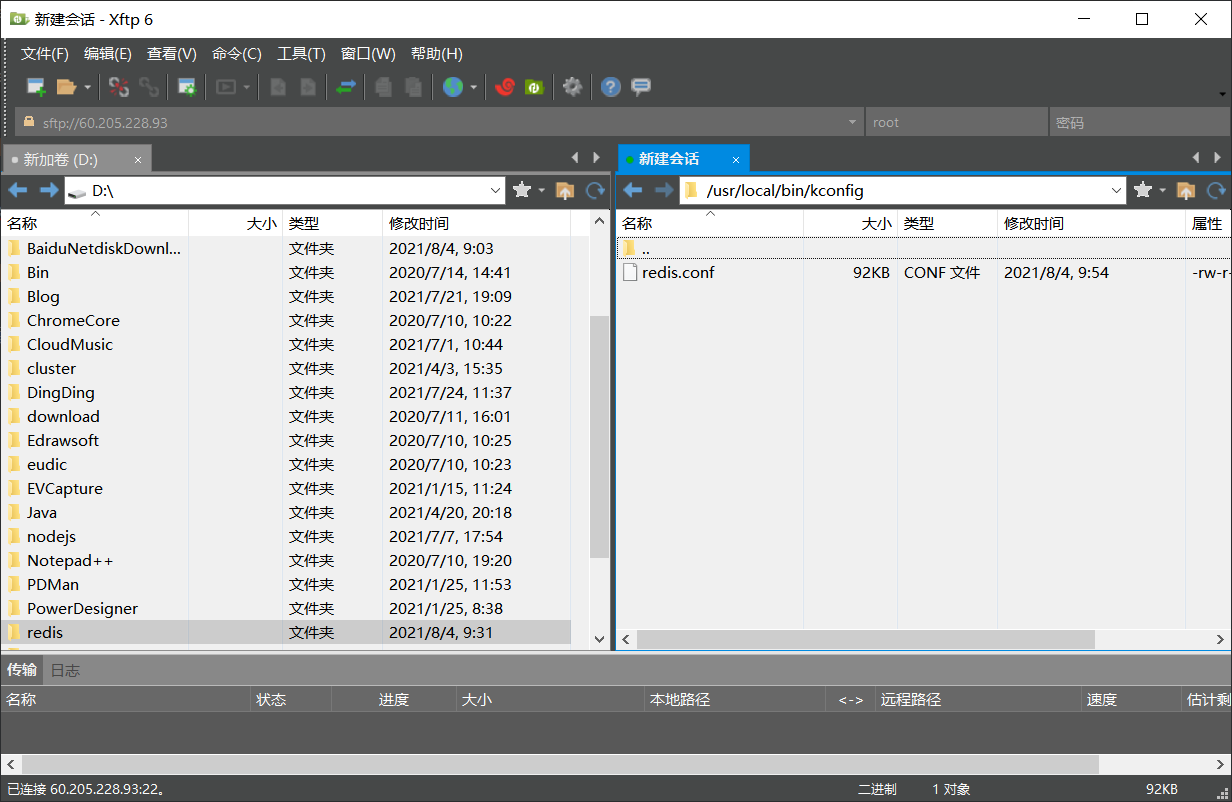
修改配置文件,将daemonize no修改为daemonize yes
图6 设置daemonize yes
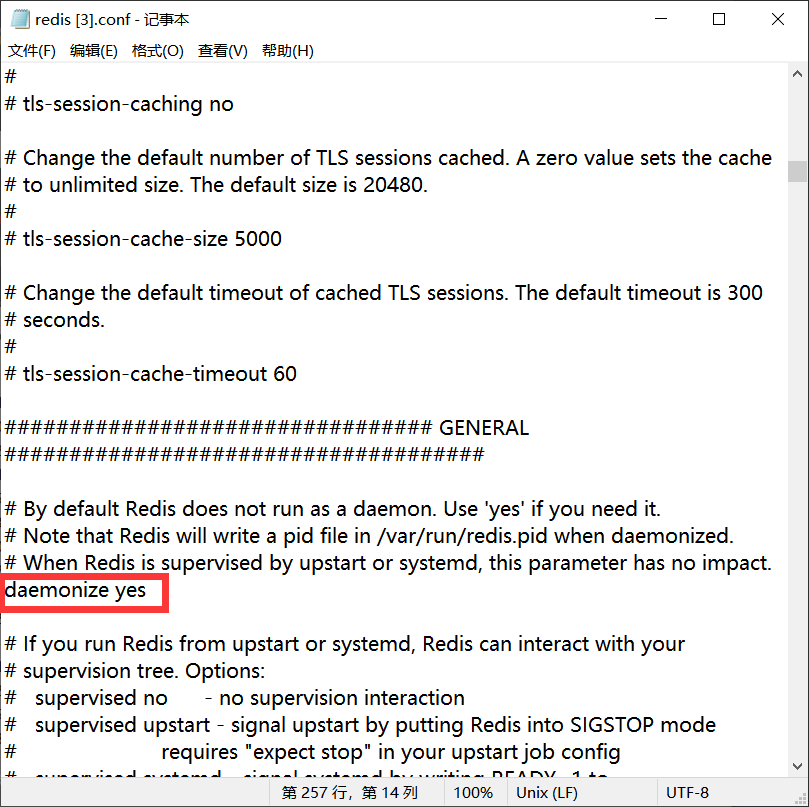
-
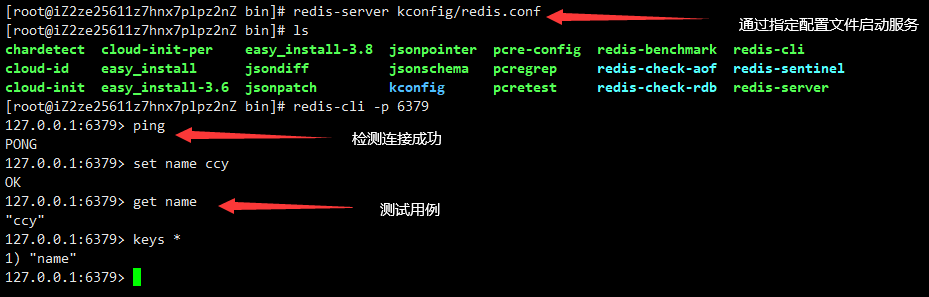
开启redis服务
图7 redis服务开启
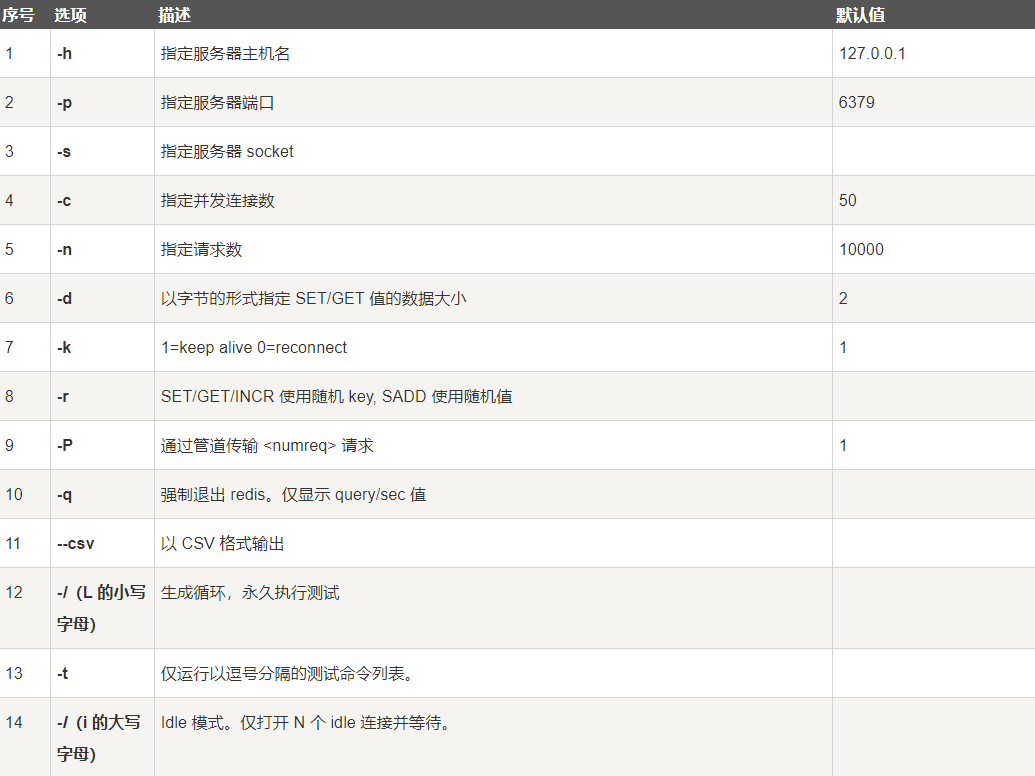
redis-benchmark
redis-benchmark是一个压力测试工具
官方自带的性能测试工具
图8 redis-benchmark命令参数
-
开启redis服务
-
进入redis 的目录下
redis-benchmark命令是在 redis 的目录下执行的,而不是 redis 客户端的内部指令。
-
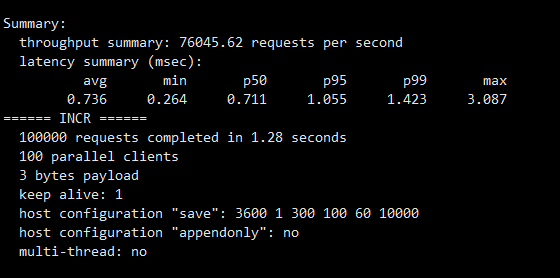
执行命令
图9 redis-benchmark压力测试结果