LRU由浅入深讲解
我们常用缓存提升数据查询速度,由于缓存容量有限,当缓存容量达到上限,就需要删除部分数据挪出空间,这样新数据才可以添加进来,缓存数据不能随机删除,一般情况下我们需要根据某种算法删除缓存数据,常用的淘汰算法有LRU,LFU,FIFO
LRU简介
LRU是Least Recently Used的缩写,这种算法认为最近使用的数据是热门数据,下一次很大概率将会再次使用,而最近最少被使用的数据,很大概率下一次不再用到,当缓存容量满的时候,优先淘汰最近最少使用的
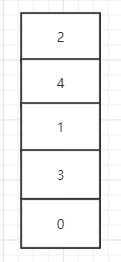
如下图所示,队列只能够存放5个元素
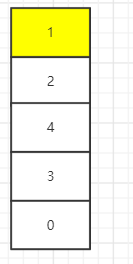
当调用缓存获取key = 1的数据,LRU算法需要将这个节点移动到头节点,其余节点不变
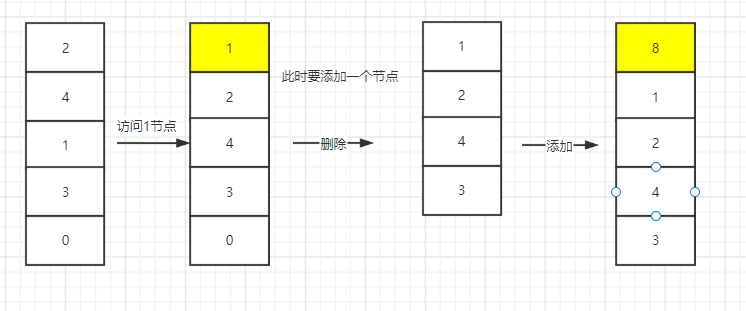
当缓存满的时候,添加新的数据会优先淘汰最近最少使用的
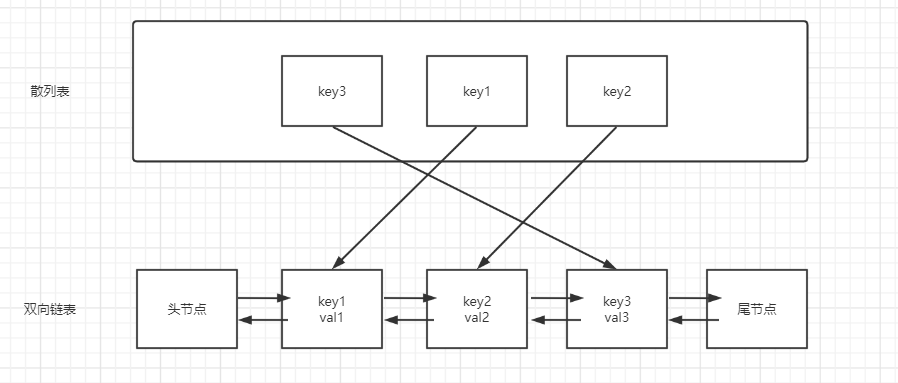
LRU数据结构选择
综合以上问题,可以结合其他数据结构解决
O(1) 的快速查找,就哈希表了。光靠哈希表可以吗?哈希表是无序的,无法知道里面的键值对哪些最近访问过,哪些很久没访问。 快速删除,谁合适?
-
数组?元素的插入/移动/删除都是 O(n)/O(n)。不行。
-
单向链表?删除节点需要访问前驱节点,只能花 O(n)/O(n) 从前遍历查找。不行。
-
双向链表,结点有前驱指针,删除/移动节点都是纯纯的指针变动,都是 O(1)/O(1)。