新生51场
问题 D: 方格取数
题目描述
设有n×m的方格图,每个方格中都有一个整数。现有一只小熊,想从图的左上角走到右下角,每一步只能向上、向下或向右走一格,并且不能重复经过已经走过的方格,也不能走出边界。小熊会取走所有经过的方格中的整数,求它能取到的整数之和的最大值。
输入
第1行两个正整数n,m。
接下来n行每行m个整数,依次代表每个方格中的整数。
接下来n行每行m个整数,依次代表每个方格中的整数。
输出
一个整数,表示小熊能取到的整数之和的最大值。
样例输入 Copy
【样例1】
3 4
1 -1 3 2
2 -1 4 -1
-2 2 -3 -1
【样例2】
2 5
-1 -1 -3 -2 -7
-2 -1 -4 -1 -2
样例输出 Copy
【样例1】
9
【样例2】
-10
提示
样例1解释:
![]()
按上述走法,取到的数之和为 1 + 2 + (-1) + 4 + 3 + 2 + (-1) + (-1) = 9,可以证明为最大值。
![]()
注意,上述走法是错误的,因为第 2 行第 2 列的方格走过了两次,而根据题意,不能重复经过已经走过的方格。
![]()
另外,上述走法也是错误的,因为没有走到右下角的终点。
样例2解释:
![]()
按上述走法,取到的数之和为(-1) + (-1) + (-3) + (-2) + (-1) + (-2) = -10,可以证明为最大值。因此,请注意,取到的数之和的最大值也可能是负数。
对于20%的数据,n,m≤5。
对于40%的数据,n,m≤50。
对于70%的数据,n,m≤300。
对于100%的数据,1≤n,m≤1000。方格中整数的绝对值不超过104。

按上述走法,取到的数之和为 1 + 2 + (-1) + 4 + 3 + 2 + (-1) + (-1) = 9,可以证明为最大值。

注意,上述走法是错误的,因为第 2 行第 2 列的方格走过了两次,而根据题意,不能重复经过已经走过的方格。

另外,上述走法也是错误的,因为没有走到右下角的终点。
样例2解释:

按上述走法,取到的数之和为(-1) + (-1) + (-3) + (-2) + (-1) + (-2) = -10,可以证明为最大值。因此,请注意,取到的数之和的最大值也可能是负数。
对于20%的数据,n,m≤5。
对于40%的数据,n,m≤50。
对于70%的数据,n,m≤300。
对于100%的数据,1≤n,m≤1000。方格中整数的绝对值不超过104。
这个我也想到了dp,但是硬是没有做出来
因为我不知道一个东西:dp无后效性
这是DP中最重要的一点, 他要求每个子问题的决策不能对后面其他未解决的问题产生影响, 如果产生就无法保证决策的最优性, 这就是无后效性。往往需要我们找到一个合适的状态。上述的问题还有另外一个描述方式, 对于后一个节点的判断不能以前面节点的路径为依据。
而这个问题是它可以向上,也可以向下,如果这个时候令f[i][j]为走到(i,j)的最大值,要记住for循环是依次遍历的,相当于是一行一行遍历,第一行遍历结束之后才开始下一行,上面的都遍历过了,之前的解决过的问题不能和后面为解决的问题能相互产生影响,如果都遍历过一遍,但是它依然可以向上走,找到那个所谓的不合法的最优解那当然是不行的
这个题咱们知道得用dp,但是不能这么写,那转化一下思路,把整个图翻转90°,那就只能是向左向右向下走,上面的最优解已经出来,并且不会影响到下面的决策,这个时候令f[i][j]为走到i,j的最优解才合理
但我们实际上不知道它下一步到底怎么走,之前的dp题只能向下向右,那很好办,那最后的结果就只是到达那个点而已,只是到达的方式不一样,但这里可以向左向右不唯一啊
那就多开一维吧,f[i][j][0/1]01就表示当前的方向
向下走(下面的状态和上面没有任何关系,f[i][j][0/1]表示走到i,j,方向是0或者1的最小值),那这个走到下面,是可以从向左的方向走到下面,也可以向右的方向走到下面:
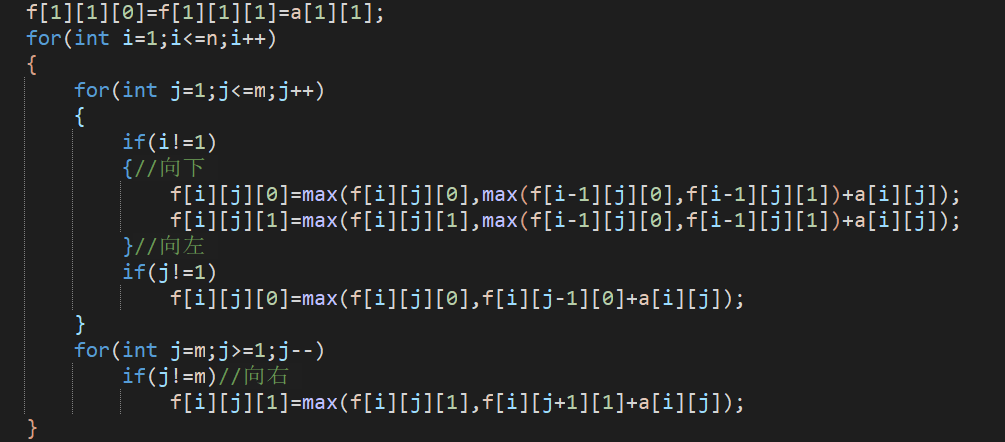
但是这个方法感觉还是不太容易能想到的
这个题有个很重要的特点,就是不能重复,如果从上往下走了,就不能走回头路了,如果再往上走就相当于重复了
所以可以一列一列来看,感谢一位大佬的指点,呜呜呜
#include<iostream> #include<cstring> using namespace std; const int N=1005; long long int f[N][N],w[N][N]; int main(){ int n,m; cin>>n>>m; for(int i=1;i<=n;i++) for(int j=1;j<=m;j++) cin>>w[i][j]; memset(f,-0x3f,sizeof(f)); f[1][0]=0;//初始化 for(int j=1;j<=m;j++) { long long int s=-1e4; for(int i=1;i<=n;i++) { s=max(f[i][j-1],s)+w[i][j]; f[i][j]=max(s,f[i][j]); } s=-1e4; for(int i=n;i>=1;i--) { s=max(f[i][j-1],s)+w[i][j]; f[i][j]=max(s,f[i][j]); } } cout<<f[n][m]<<endl; return 0; }
问题 F: 异或序列
题目描述
Venn有一个数列a1,a2,...,an。有一天,BLUESKY007拿来了一个正整数X。Venn是一个特别喜欢异或(xor)运算的孩子,她也很喜欢BLUESKY007。于是,Venn就想知道,自己能找到多少对数(i,j)能够满足aixoraj=X。两个数对(i1,j1)与(i2,j2)不同,当且仅当i1≠i2或者j1≠j2。
输入
第一行两个正整数n,X,分别表示数列的长度以及Bluesky带来的整数。
第二行包含n个正整数,表示数列{an}。
第二行包含n个正整数,表示数列{an}。
输出
一行一个整数表示答案。
样例输入 Copy
5 1
1 4 2 2 5
样例输出 Copy
2
提示
样例解释:这两对是(2,5)与(5,2)。
【数据范围】
对于50%的数据,1≤n≤2000。
对于接下来20%的数据,1≤ai≤100000。
对于100%的数据,1≤n≤1000000,1≤ai≤230,1≤X≤230。
【数据范围】
对于50%的数据,1≤n≤2000。
对于接下来20%的数据,1≤ai≤100000。
对于100%的数据,1≤n≤1000000,1≤ai≤230,1≤X≤230。
关于这个我好像还真的不是太知道...看了大佬写的,我留着再琢磨琢磨...
问题 G: Secret Message
Jack and Jill developed a special encryption method, so they can enjoy conversations without worrrying about eavesdroppers. Here is how: let L be the length of the original message, and M be the smallest square number greater than or equal to L. Add (M − L) asterisks to the message, giving a padded message with length M. Use the padded message to fill a table of size K × K, where K2= M. Fill the table in row-major order (top to bottom row, left to right column in each row). Rotate the table 90 degrees clockwise. The encrypted message comes from reading the message in row-major order from the rotated table, omitting any asterisks.
For example, given the original message ‘iloveyouJack’, the message length is L = 12. Thus the padded message is ‘iloveyouJack****’, with length M = 16. Below are the two tables before and after rotation.
![]() Then we read the secret message as ‘Jeiaylcookuv’.
Then we read the secret message as ‘Jeiaylcookuv’.
For example, given the original message ‘iloveyouJack’, the message length is L = 12. Thus the padded message is ‘iloveyouJack****’, with length M = 16. Below are the two tables before and after rotation.

输入
The first line of input is the number of original messages, 1 ≤ N ≤ 100. The following N lines each have a message to encrypt. Each message contains only characters a–z (lower and upper case), and has length 1 ≤ L ≤ 10 000.
输出
For each original message, output the secret message.
样例输入 Copy
2
iloveyoutooJill
TheContestisOver
样例输出 Copy
iteiloylloooJuv OsoTvtnheiterseC
就是模拟,没啥好说的
#include<iostream> #include<cstring> using namespace std; const int N=5000; char c[N][N]; int f; int pfs(int n) { for(int i=1;;i++) { if(i==n/i) { f=i; return 1; } if(i*i>n) break; } return 0; } int main(){ int n; cin>>n; while(n--) { int len,b; char ch[20000],str[20000]; cin>>ch; len=strlen(ch); for(int i=len;;i++) { if(pfs(i)) { b=f; break; } } //cout<<b<<endl; int k=0; for(int i=1;i<=b;i++) { for(int j=1;j<=b;j++) { c[i][j]=ch[k]; k++; if(k>len) c[i][j]='*'; } } k=0; for(int j=1;j<=b;j++) { for(int i=b;i>=1;i--) { str[k]=c[i][j]; k++; } } for(int i=0;i<k;i++) { if(str[i]=='*') continue; else cout<<str[i]; } cout<<endl; } return 0; }
问题 E: 优美的数
题目描述
在BLUESKY007眼中,如果一个数包含7或这个数是7的倍数,这个数就是优美的。
BLUESKY007在纸上写下了所有大于0的优美的数,她想考考你,第k个数是多少?
BLUESKY007在纸上写下了所有大于0的优美的数,她想考考你,第k个数是多少?
输入
第一行一个整数t,表示数据组数。
接下来的t行,每行一个整数k。
接下来的t行,每行一个整数k。
输出
一共t行,第i行输出第i组数据的答案。
样例输入 Copy
11
1
2
3
4
5
6
7
8
9
10
2021
样例输出 Copy
7
14
17
21
27
28
35
37
42
47
5477
提示
对于40%的数据,1≤t,k≤10。
对于75%的数据,1≤t,k≤100。
对于100%的数据,1≤t,k≤2021
对于75%的数据,1≤t,k≤100。
对于100%的数据,1≤t,k≤2021
数据范围也不大,直接算出每个数,然后输出就可以了
#include<iostream> using namespace std; const int N=3000; int a[N]; int chaifen(int n) { while(n) { if(n%10==7) return 1; n/=10; } return 0; } int main(){ int n; cin>>n; int k=1; for(int i=7;;i++) { if(i%7==0||chaifen(i)) { a[k]=i; k++; } if(k>2021) break; } while(n--) { int x; cin>>x; cout<<a[x]<<endl; } return 0; }
问题 A: 优秀的拆分
题目描述
一般来说,一个正整数可以拆分成若干个正整数的和。例如,1=1,10=1+2+3+4等。
对于正整数n的一种特定拆分,我们称它为“优秀的”,当且仅当在这种拆分下,n被分解为了若干个不同的2的正整数次幂。注意,一个数x能被表示成2的正整数次幂,当且仅当x能通过正整数个2相乘在一起得到。
例如,10=8+2=23+21是一个优秀的拆分。但是,7=4+2+1=22+21+20就不是一个优秀的拆分,因为1不是2的正整数次幂。
现在,给定正整数n,你需要判断这个数的所有拆分中,是否存在优秀的拆分。若存在,请你给出具体的拆分方案。
对于正整数n的一种特定拆分,我们称它为“优秀的”,当且仅当在这种拆分下,n被分解为了若干个不同的2的正整数次幂。注意,一个数x能被表示成2的正整数次幂,当且仅当x能通过正整数个2相乘在一起得到。
例如,10=8+2=23+21是一个优秀的拆分。但是,7=4+2+1=22+21+20就不是一个优秀的拆分,因为1不是2的正整数次幂。
现在,给定正整数n,你需要判断这个数的所有拆分中,是否存在优秀的拆分。若存在,请你给出具体的拆分方案。
输入
输入只有一行,一个正整数n,代表需要判断的数。
输出
如果这个数的所有拆分中,存在优秀的拆分。那么,你需要从大到小输出这个拆分中的每一个数,相邻两个数之间用一个空格隔开。可以证明,在规定了拆分数字的顺序后,该拆分方案是唯一的。
若不存在优秀的拆分,输出“-1”(不包含双引号)。
若不存在优秀的拆分,输出“-1”(不包含双引号)。
样例输入 Copy
【样例1】
6
【样例2】
7
样例输出 Copy
【样例1】
4 2
【样例2】
-1
提示
样例1解释
6=4+2=22+21是一个优秀的拆分。注意,6=2+2+2不是一个优秀的拆分,因为拆分成的3个数不满足每个数互不相同。
对于20%的数据,n≤10。
对于另外20%的数据,保证n为奇数。
对于另外20%的数据,保证n为2的正整数次幂。
对于80%的数据,n≤1024。
对于100%的数据,1≤n≤1×107。
6=4+2=22+21是一个优秀的拆分。注意,6=2+2+2不是一个优秀的拆分,因为拆分成的3个数不满足每个数互不相同。
对于20%的数据,n≤10。
对于另外20%的数据,保证n为奇数。
对于另外20%的数据,保证n为2的正整数次幂。
对于80%的数据,n≤1024。
对于100%的数据,1≤n≤1×107。
这个循环细节卡了好久...不知道为什么
怪怪的
#include <iostream> #include <cmath> using namespace std; int main(){ int n; cin>>n; if(n%2!=0) { cout<<"-1"<<endl; return 0; } while(1) { if(n<=0) break; int k=1; while(1) { if(pow(2,k+1)>n) break; k++; } int x=pow(2,k); n-=x; printf("%d ",(int)x); } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号