策略迭代 (Policy Iteration)
转载自知乎
https://zhuanlan.zhihu.com/p/34006925
假设我们有一个3 x 3的棋盘:
- 有一个单元格是超级玛丽,每回合可以往上、下、左、右四个方向移动
- 有一个单元格是宝藏,超级玛丽找到宝藏则游戏结束,目标是让超级玛丽以最快的速度找到宝藏
- 假设游戏开始时,宝藏的位置一定是(1, 2)
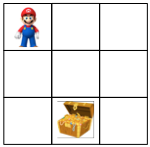
这个一个标准的马尔科夫决策过程(MDP):
- 状态空间State:超级玛丽当前的坐标
- 决策空间Action: 上、下、左、右四个动作
- Action对State的影响和回报 P(State', Reward | State, Action):本文认为该关系是已知的
- 超级玛丽每移动一步,reward = -1
- 超级玛丽得到宝箱,reward = 0并且游戏结束
利用策略迭代 (Policy Iteration) 求解马尔科夫决策过程
上一篇我们介绍了如何使用价值迭代 (Value Iteration) 来求解MDP,这篇介绍另外一种方法:策略迭代 (Policy Iteration)。
关于策略迭代,需要知道下面几点:
- 什么叫策略?策略就是根据当前状态决定该采取什么Action,
P(Action | State)
- 以本文超级玛丽寻找宝箱为例,超级玛丽需要不断朝着宝箱的方向前进
- 当前状态在宝箱左侧,策略应该是朝右走
- 当前状态在宝箱上方,策略应该是超下走
- 如何衡量策略的好坏 —— 策略评估 (Policy Evaluation)
- 还记得上一节定义的价值函数 (Value Function) 吗?给定一个策略,我们可以计算出每个状态的期望价值 V(s)
- 如何找到更好的策略 —— 策略迭代 (Policy Iteration)
- 初始化:随机选择一个策略作为初始值,比如说不管什么状态,一律朝下走,即P(Action = 朝下走 | State) = 1,P(Action = 其他Action | State) = 0
- 第一步 策略评估 (Policy Evaluation):根据当前的策略计算V(s)
- 第二步 策略提升 (Policy Improvement):计算当前状态的最好Action,更新策略,
- 不停的重复策略评估和策略提升,直到策略不再变化为止

下面以寻找宝藏为例,说明策略迭代过程:
- 初始化:无论超级玛丽在哪个位置,策略默认为向下走
- 策略评估:计算V(s)
- 如果宝藏恰好在正下方,则期望价值等于到达宝藏的距离(-2或者-1)
- 如果宝藏不在正下方,则永远也不可能找到宝藏,期望价值为负无穷
- 策略提升:根据V(s)找到更好的策略
- 如果宝藏恰好在正下方,则策略已经最优,保持不变
- 如果宝藏不在正下方,根据
可以得出最优策略为横向移动一步
- 第一轮迭代:通过上一轮的策略提升,这一轮的策略变成了横向移动或者向下移动(如图所示)
- 策略评估:计算V(s)
- 如果宝藏恰好在正下方,则期望价值等于到达宝藏的距离(-2或者-1)
- 如果宝藏不在正下方,当前策略会选择横向移动,期望价值为-3, -2, -1
- 策略提升:根据V(s)找到更好的策略
- 如果宝藏恰好在正下方,则策略已经最优,保持不变
- 如果宝藏不在正下方,根据
可以得出当前策略已经最优,保持不变
源码实现
下面的代码实现了一个Agent,价值迭代在optimize函数中实现,完整可运行jupyter notebook欢迎访问我的Github: whitepaper/RL-Zoo
class Agent:
def __init__(self, env):
self.env = env
def policy_evaluation(self, policy):
V = np.zeros(self.env.nS)
THETA = 0.0001
delta = float("inf")
while delta > THETA:
delta = 0
for s in range(self.env.nS):
expected_value = 0
for action, action_prob in enumerate(policy[s]):
for prob, next_state, reward, done in self.env.P[s][action]:
expected_value += action_prob * prob * (reward + DISCOUNT_FACTOR * V[next_state])
delta = max(delta, np.abs(V[s] - expected_value))
V[s] = expected_value
return V
def next_best_action(self, s, V):
action_values = np.zeros(env.nA)
for a in range(env.nA):
for prob, next_state, reward, done in self.env.P[s][a]:
action_values[a] += prob * (reward + DISCOUNT_FACTOR * V[next_state])
return np.argmax(action_values), np.max(action_values)
def optimize(self):
policy = np.tile(np.eye(self.env.nA)[1], (self.env.nS, 1