
02-APIView和序列化类 serializers
常规通过CBV的写法
# models.py
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
publish = models.CharField(max_length=64)
class Meta:
db_table = "book"
# urls.py
from django.urls import path
from .views import BookView, BookDetailView
urlpatterns = [
# 查询全部图书以及新增图书
path("books/", BookView.as_view()),
# 修改一本图书,删除一本图书,查询1本图书
path("books/<int:pk>/", BookDetailView.as_view())
]
import json
from urllib.request import unquote
from django.shortcuts import render
from .models import Book
from django.http import JsonResponse
from django.views import View
from django.forms.models import model_to_dict
# 127.0.0.1:8000/app01/books/
class BookView(View):
# 查询全部书籍
def get(self, request):
book_obj = Book.objects.all()
data_list = []
for obj in book_obj:
# data_list.append({"name": obj.name, "price": obj.price, "publish": obj.publish})
# 推荐下面的写法
data_list.append(model_to_dict(obj))
return JsonResponse({"code": 100, "msg": "查询成功!", "results": data_list})
# 新增一本书籍
def post(self, request):
data = request.POST.dict()
Book.objects.create(**data)
return JsonResponse({"code": 100, "msg": "新增成功!"})
# 127.0.0.1:8000:app01/books/pk/
class BookDetailView(View):
# 修改单本书籍
def put(self, request, pk):
# 这里获取到通过二进制的字符串 b'%..'
body = request.body
# print("进来的数据是json格式的") 即前端是通过json发送请求的
data_dict = json.loads(body)
Book.objects.filter(pk=pk).update(**data_dict)
# 因为通过PUT方法发送的请求并不会在POST里面,所以只能在request.body里面取数据
# 但是这个数据是 b'%..'的形式,所以我们需要通过unquote去转码成正常的数据,然后再去操作数据库
data = unquote(body) # name=挪威的森林&price=88&publish=上海出版社
data_dict = {k: v for k, v in (line.split("=") for line in data.split("&"))}
# 更新数据到数据库里面
Book.objects.filter(pk=pk).update(**data_dict)
return JsonResponse({"code": 100, "msg": "修改成功!"})
# 删除单本书籍
def delete(self, request, pk):
Book.objects.filter(pk=pk).delete()
return JsonResponse({"code": 100, "msg": "删除成功!"})
# 查询单本书籍
def get(self, request, pk):
book_obj = Book.objects.filter(pk=pk).first()
# data = {"name": book_obj.name, "price": book_obj.price, "publish": book_obj.publish}
# 推荐下面的写法
data = model_to_dict(book_obj)
return JsonResponse({"code": 100, "msg": "查询成功!", "result": data})
通过传统视图写有什么问题
- 取数据不友好,数据有时候能从request.POST取出来,又时候又只能从request.body里面取出来数据,而且是同一个接口,所以会加大后端代码的冗余。
- 发送POST请求会遇到403Forbidden ,需要每一次都解决csrf的问题
- 有没有一个方案即能从某个指定的地方拿到数据不需要转格式,又能帮我们解决csrf_token的问题呢?
- 可以使用APIView
request.content_type
可以用来获取前端的请求头编码类型,参考下表:
| 请求编码类型 | request.content_type打印结果 |
|---|---|
| form-data | multipart/form-data; boundary=--------------------------109480859847807332950202 |
| urlencoded | application/x-www-form-urlencoded |
| json | application/json |
通过content_type,获取到编码类型之后,在APIView中去判断就更方便处理了。
基于APIView编写五个接口
返回要使用drf自带的Response,这个Response 不仅仅可以有JsonResponse的功能,也可以返回字符串
# 继承APIView
from rest_framework.views import APIView
from rest_framework.response import Response
# 基于上面的问题以及restful规范,新开一个路径v1 然后使用APIView的方式重写一遍,解决上面的问题
# views.py
# =-------------------- 下面是基于 APIView 写的五个方法
from rest_framework.views import APIView
from rest_framework.response import Response
# 127.0.0.1:8000/app01/v1/books/
class BookViewV1(APIView):
# 查询全部书籍
def get(self, request):
book_obj = Book.objects.all()
data_list = []
for obj in book_obj:
data_list.append(model_to_dict(obj))
return Response({"code": 100, "msg": "查询成功!", "results": data_list})
# 新增一本书籍
def post(self, request):
items = request.data
if request.content_type == 'application/json':
# 这里可以通过request.content_type 去判断前端的编码类型 目前这个缩进是json的结果,能直接拿到数据
# 如果前端是通过json方式传过来的数据,那么拿到的就直接是一个字典
data = items
else:
# 否则 得到的就是 QueryDict 需要通过.get取值
# data = {"name": items.get("name"), "price": items.get("price"), "publish": items.get("publish")}
# 建议通过QueryDict.dict() 方法
Book.objects.create(**items.dict())
return Response({"code": 100, "msg": "新增成功!"})
class BookDetailViewV1(APIView):
# 修改单本书籍
def put(self, request, pk):
data = request.data if request.content_type == 'application/json' else request.data.dict()
Book.objects.filter(pk=pk).update(**data)
return JsonResponse({"code": 100, "msg": "修改成功!"})
# 删除单本书籍
def delete(self, request, pk):
Book.objects.filter(pk=pk).delete()
return JsonResponse({"code": 100, "msg": "删除成功!"})
# 查询单本书籍
def get(self, request, pk):
book_obj = Book.objects.filter(pk=pk).first()
data = model_to_dict(book_obj)
return JsonResponse({"code": 100, "msg": "查询成功!", "result": data})
# urls.py
from django.urls import path
from .views import BookViewV1, BookDetailViewV1
urlpatterns = [
# ---------- 下面是基于 APIView 去写的 -----------------
path("v1/books/",BookViewV1.as_view()),
path("v1/books/<int:pk>/", BookDetailViewV1.as_view())
]
# modes.py 不变
APIView的执行流程(难)重要
# 1 APIView继承了 Django的View---》 class APIView(View)
# 2 请求来了,路由匹配成功后---》执行流程
2.1 路由配置 path('books/', BookView.as_view()),
2.2 BookView.as_view()(request)-->BookView中没有as_view--》找父类APIView的as_view
BookView-->APIView-->View
2.3 APIView的as_view
@classmethod # 绑定给类的方法,类来调用
def as_view(cls, **initkwargs):
# super代指父类--》父类是View--》之前读过--》self.dispatch()
# 这个view 还是原来View的as_view的执行结果--》as_view中有个view内部函数
view = super().as_view(**initkwargs)
# 只要继承了APIView,不需要处理csrf
'''
@csrf_exempt
def index(request):
pass
等同于 index=csrf_exempt(index)
以后调用index,其实调用的 是csrf_exempt(index)()
'''
return csrf_exempt(view)
2.4 请求来了,真正执行的是:csrf_exempt(view)(request)-->去除了csrf的view(request)--》self.dispatch()
2.5 请求来了,真正执行的是 self.dispatch(request)--->self 是 视图类的对象
BookView的对象--》自己没有--》APIView中
2.6 现在要看 APIView的dispatch
def dispatch(self, request, *args, **kwargs):
# 1 包装了新的request对象---》现在这个requets对象,已经不是原来django的request对象了
request = self.initialize_request(request, *args, **kwargs)
try:
# 2 APIView的initial--》三件事:三大认证:认证,频率,权限
self.initial(request, *args, **kwargs)
# 3 就是执行跟请求方式同名的方法
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
# 4 如果在三大认证或视图类的方法中出了异常,会被统一捕获处理
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
# 执行流程总结
1 只要继承了APIView,就没有csrf限制了
2 只要继承了APIView,request就是新的request了,它有data
3 在执行跟请求方式同名的方法之前,执行了三大认证:认证,频率,权限
4 只要在三大认证或者视图类的方法中出了一场,都会被捕获,统一处理
Request对象
#1 APIView执行流程---》request对象---》变成了新的
-多了 request.data
#2 新的Request具体是哪个类的对象
rest_framework.request.Request 类的对象
#3 老的request是哪个类的对象
django.core.handlers.wsgi.WSGIRequest
# 4 老的request可以
-request.method
-request.path
-request.META.get('REMOTE_ADDR')
-request.FILES.get()
...
# 5 新的request支持之前所有老request的操作
-1 之前如何用,还是如何用
-2 request.data-->请求体的数据--》方法包装成了数据属性
@property
def data(self):
if not _hasattr(self, '_full_data'):
self._load_data_and_files()
return self._full_data
-3 request.query_params--->原来的request.GET--》贴合restful规范-》
@property
def query_params(self):
return self._request.GET
-4 request._request 就是老的request
# 6 源码分析---》为什么:之前如何用,还是如何用?没有继承关系
from rest_framework.request import Request
-__getattr__: .拦截方法,对象.属性,如果属性不存在,就会触发__getattr__执行
-requst.method -->新的request没有--》会触发新的Request类中的 __getattr__
def __getattr__(self, attr):
try:
# 根据字符串 _request 获取self中的属性
# _request 就是原来老的request
_request = self.__getattribute__("_request")
# 通过反射,去老的request中,获取属性
return getattr(_request, attr)
except AttributeError:
return self.__getattribute__(attr)
# 总结:记住的 新的request
-1 之前如何用,还是如何用
-2 request.data-->请求体的数据--》方法包装成了数据属性
-3 request.query_params--->原来的request.GET--》贴合restful规范-》
-4 request._request 就是老的request
-5 魔法方法之 __getattr__
APIView到底新增了哪些方法?
| 方法 | 说明 |
|---|---|
| request.data | 如果是json方式直接拿到数据字典,如果是from-data或者urlencoded需要自己再次处理 |
| request.query_params | 还是原来的request.GET--》贴合restful规范-》 推荐后续GET方法使用 |
| request._request | 就是原来的request |
魔法方法之 __getattr__
# 以__开头 __结尾的都是魔法方法,魔法方法并不是我们主动调用的,而是某种情况下,自动去触发的。
# __getattr__ 为拦截方法,如果对象.属性 不存在 就会触发该方法的运行。
class Hero:
def __getattr__(self, name):
print(f"根据 {name} 去取值")
return "我是默认值 3"
hero = Hero()
hero.name = "小满" # 如果属性存在 正常打印, 如果属性不存在正常情况下会报错,不过定义了__getattr__ 方法会自动触发
print(hero.age) # 根据这里的属性
# 根据 age 去取值
# 我是默认值 3
序列化类 serializer
伪代码
# BookSerializer.py
from rest_framework import serializers #
class BookSerializer(serializers.Serializer):
# 下面写字段
...
# views
from .serializer import BookSerializer # 自己定义的类
from rest_framework.response import Response
from rest_framework.views import APIView # 不继承APIView也可以 怎么方便怎么来
class 类名(APIView):
# 序列化多个对象
obj_list = 模型层的类.objects.all()
# 序列化多个类 加上many=True
serializer = BookSerializer(instance=obj_list, many=True)
# ---- 下面是序列化单个
obj = 模型层的类.objects.filter(pk=pk).first()
serializer = BookSerializer(instance=obj)
# 注意,返回的时候,我们也不使用JsonResponse了,使用def的Response
return Response({"code": 100, "msg": "ok"})
引入
# 上面,我们已经通过APIView 优化了5个接口,不过还是有许多问题:
- 做序列化的时候,手动去做,方法很笨。
- 拓展性差,后续如果要序列化某个、或少序列化某个字段,会比较麻烦
# 优化 借助 drf 提供的序列化类,有下面的优点:
- 1. 可以帮助我们快速的完成序列化
- 2. 数据校验,帮助我们反序列化之前校验数据的准确性
- 3. 可以帮助我们做反序列化
# 如何使用?
- 1. 新建一个py文件,名称随意,在里面新建一个类,然后继承Serialier
- 2. 在类中写字段,字段就是要序列化的字段
- 3. 在视图函数中,序列化类,实例化得到对象,传入该传的参数
- 单条
- 多条
- 4. 调用序列化类对象的 serializer.data 方法完成序列化
序列化案例 查询相关
# serializer.py 自己创建的Py文件
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 注意注意, 这里指定字段类型需要通过 serializers
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.CharField()
# 重开一个路径v2 使用serializers 做进一步优化
# 128.0.0.0:8000/app01/v2/books/
# views.py
# ------------------------------ 下面是基于 serializrs 序列化
from .serializer import BookSerializer
from rest_framework.response import Response
# 127.0.0.1:8000/app01/v2/books/
class BookViewV2(APIView):
def get(self, request):
obj_list = Book.objects.all()
# 要序列化的qs对象,但是如果是很多条数据,必须加上 many=True 默认的情况下 instance=None data=empty
serailizer = BookSerializer(instance=obj_list, many=True)
# 需要注意的是,这里不用使用JsonResponse了,而是使用drf的Response去返回
# from rest_framework.response import Response
return Response({"code": 100, "msg": "成功!", "results": serailizer.data})
# 127.0.0.1:8000/app01/v2/books/pk/
class BookDetailViewV2(APIView):
def get(self, request, pk):
obj = Book.objects.filter(pk=pk).filter().first()
# 因为这里是查询单本书的接口,所以不需要传入many参数,如果一定要传 传入many=False即可,默认也是many=False
serializer = BookSerializer(instance=obj, many=False)
return Response({"code": 100, "msg": "查询成功!", "result": serializer.data})
数据校验案例 post (校验前端传入的数据和forms很像)
- 主要功能是校验前端传入的数据
- 数据校验和反序列化的时候,不能传入instance,而要传入data
- 在 Django REST Framework 中,每个字段对应的验证方法可以通过
validate_<field_name>的方式来定义,其中<field_name>是字段的名称。
# serializer.py
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
class BookSerializer(serializers.Serializer):
# 注意注意, 这里指定字段类型需要通过 serializers
name = serializers.CharField(max_length=10, min_length=3) # 注意注意! 这里的length指的是字符的长度 ,不是编码!!
price = serializers.IntegerField(max_value=200, min_value=20) # 最大值和最小值
publish = serializers.CharField()
# 局部钩子,可以给某一个字段指定条件
# name
# name中不能包含sb开头活着结尾
def validate_name(self, name):
if "sb" in name:
# 不合法,抛出异常
raise ValidationError("书名不合法!")
# 书名如果合法,需要返回出去
return name
# 全局钩子, 多个字段校验
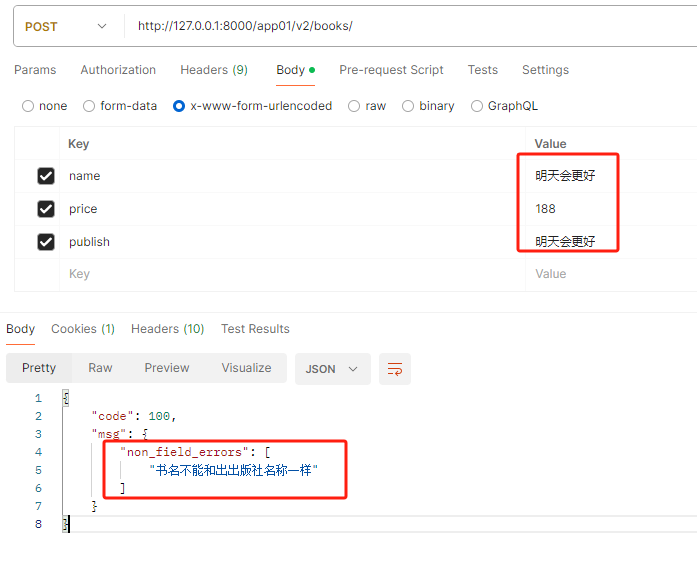
# 要求,书名不能和出版社名称相同
def validate(self, attrs):
# attrs [字典]
# 这个attrs 是什么,这个attrs 就是通过自己校验,以及通过局部钩子校验通过之后的数据,然后才走到全局钩子
if attrs.get("name") == attrs.get("publish"):
raise ValidationError("书名不能和出出版社名称一样")
# 不要忘记返回
return attrs
# views.py
from .serializer import BookSerializer
from rest_framework.response import Response
# 127.0.0.1:8000/app01/v2/books/
class BookViewV2(APIView):
def post(self, request):
# data获取数据
# 1 校验前端传入的数据
# 2 数据校验和反序列化 ---> 这里不能传入instance 而要传入data
serializer = BookSerializer(data=request.data)
# 3 进行数据的校验
if serializer.is_valid():
# 校验通过,保存
return Response({"code": 100, "msg": "保存成功!骗你的 略~"})
else:
# 数据校验不通过,主动抛出异常,使用serializer.errors
return JsonResponse({"code": 100, "msg": serializer.errors})
数据校验通过保存数据
视图层:save()
自定义序列化类:
- 如果是put,方式进来,即修改数据,重写update方法
- 如果是post,方式进来,即新增数据,重新create方法
# 自定义序列化类.py
from rest_framework import serializers
from .models import Book
from rest_framework.exceptions import ValidationError
class BookSerializer(serializers.Serializer):
# ...
# 删除的部分同之前一样
# validated_data 固定写法
# 一般post重写此方法
def create(self, validated_data):
# validated_data 这个是前端通过校验的数据
book = Book.objects.create(**validated_data)
# 别忘记返回出去
return book # 这个book其实就是下面的 validated_data
# 一般put请求重写此方法
# 这个 validated_data 起始就是上面的book
def update(self, instance, validated_data):
# instance 要修改的对象
# validated_data 数据
# 笨办法 待优化
# instance.name = validated_data.get("name")
# instance.price = validated_data.get("price")
# instance.publish = validated_data.get("publish")
# 优化后的方法,通过反射
for k, v in validated_data.items():
setattr(instance, k, v)
# 别忘记save()
instance.save()
# 保存之后,记得返回给前端
return instance
# 127.0.0.1:8000/app01/v2/books/
class BookViewV2(APIView):
def post(self, request):
# data获取数据
# 1 校验前端传入的数据
# 2 数据校验和反序列化 ---> 这里不能传入instance 而要传入data
serializer = BookSerializer(data=request.data)
# 3 进行数据的校验
if serializer.is_valid():
# 校验通过,保存
serializer.save() # 序列化类要重写create方法
return Response({"code": 100, "msg": "保存成功!骗你的 略~"})
else:
# 数据校验不通过,主动抛出异常,使用serializer.errors
return JsonResponse({"code": 100, "msg": serializer.errors})
# 127.0.0.1:8000/app01/v2/books/pk/
class BookDetailViewV2(APIView):
# 修改数据
def put(self, request, pk):
obj = Book.objects.filter(pk=pk).first()
items = request.data
if request.content_type == 'application/json':
data = items
else:
data = {"name": items.get("name"), "price": items.get("price"), "publish": items.get("publish")}
# 注意!!! 改对象必须传instance和data
serializer = BookSerializer(instance=obj, data=request.data)
if serializer.is_valid():
serializer.save() # 记得自定义序列化类里面要重写update方法
return Response({"code": 100, "msg": "更新成功!"})
else:
return Response({"code": 100, "msg": serializer.errors})
异常和设置中文返回异常
主动抛出异常 serializer.errors (一般写在视图中)
{
"code": 100,
"msg": {
"name": [
"Ensure this field has at least 3 characters."
]
}
}
异常类基类 ValidationError (一般写在自定义的序列化类中)
from rest_framework.exceptions import ValidationError
raise ValidationError("数据错误!")
如果想要异常修改为中文,需要在settings中去设置下面的操作
# 注册app, app的名称 rest_framework
INSTALLED_APPS = [
"rest_framework", # 这个
]
LANGUAGE_CODE = "zh-hans"
TIME_ZONE = "Asia/Shanghai"
USE_TZ = False
# 然后就可以显示中文的结果了
{
"code": 100,
"msg": {
"name": [
"请确保这个字段至少包含 3 个字符。"
]
}
}
如果包含了多个错误,那么结果也会是多个错误
{
"code": 100,
"msg": {
"name": [
"请确保这个字段至少包含 3 个字符。"
],
"price": [
"请确保该值小于或者等于 200。"
]
}
}
回顾反射的相关知识
更详细的可以看看这篇文章:https://hiyongz.github.io/posts/python-notes-for-reflection/
hasattr
返回布尔值,有返回值
class Hero:
def __init__(self, name, age):
self.name = name
self.age = age
xm = Hero(name="小满", age=3)
print(hasattr(xm, "hobby")) # False
print(hasattr(xm, "name")) # True
getattr
参考字典的get即可,有返回值
class Hero:
def __init__(self, name, age):
self.name = name
self.age = age
xm = Hero(name="小满", age=3)
print(getattr(xm, "name", "None")) # 小满
print(getattr(xm, "hobby", "None")) # None
setattr
动态设置属性,无返回值
class Hero:
def __init__(self, name, age):
self.name = name
self.age = age
xm = Hero(name="小满", age=3)
setattr(xm, "hobby", "摸鱼")
setattr(xm, "name", "大乔")
print(xm.__dict__)
# {'name': '大乔', 'age': 3, 'hobby': '摸鱼'}
delattr
有则删除,无则报错,无返回值
class Hero:
def __init__(self, name, age):
self.name = name
self.age = age
xm = Hero(name="小满", age=3)
delattr(xm, "name")
# delattr(xm, "hobby") # AttributeError: hobby
print(xm.__dict__) # {'age': 3}
自己写装饰器实现request.data
# ------------------ 下面是自己的装饰器 链接来了都会转成字典 ------------------
import re
import json
from dataclasses import dataclass
from django.views.decorators.csrf import csrf_exempt
@dataclass
class ToDict:
f: callable
def __call__(self, request, *args, **kwargs):
base_dict = {}
# 获取body
body = request.body
# 检查请求的内容类型
if request.content_type == "application/json":
# 如果是json直接反序列化
data = json.loads(body)
base_dict.update(data)
elif request.content_type == 'application/x-www-form-urlencoded':
# 解析表单数据
items = unquote(request.body)
data = {k: v for k, v in (item.split("=") for item in items.split("&"))}
base_dict.update(data)
else:
# 使用正则表达式解析其他类型的数据
items = ''.join(unquote(request.body).split())
string = re.findall(r'.*?name="(.*?)"(.*?)-.*?', items, re.S | re.I)
for line in string:
k, v = line
base_dict[k] = v
# 打印解析的数据
print(base_dict)
# 调用原始函数并返回结果
return self.f(request)
@ToDict
@csrf_exempt
def book_view_v3(request):
return JsonResponse({"code": 100, "msg": "成功!"})
本文作者:小满三岁啦
本文链接:https://www.cnblogs.com/ccsvip/p/18130173
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



