初始python请求库
写在前面
爬虫:远离个人信息、灰黑产,本文仅供技术讨论,请自觉遵守robots协议。
反爬虫的常见手段
爬虫项目最复杂的不是页面信息的信息与提取,而是爬虫与反爬虫,反反爬虫之间的互相博弈。
User-Agent
浏览器的标志信息,会通过请求头传递给服务器,用以说明访问数据的浏览器信息。
反爬虫:先检查是否有UA,或者UA是否合法
代理IP
验证码访问
动态加载网页
数据加密
...
常见HTPP状态码
1xx: 信息类
2xx: 请求成功
3xx: 跳转
4xx: 客户端错误
5xx: 服务器错误
详细可以参考:https://ahrefs.com/blog/zh/http-status-codes/
Urllib
urllib在python中分为urllib和urllib2,在python3中为urllib
构造简单的请求
# 导入模块
import urllib.request
import urllib.parse
# 发送请求
response = urllib.request.urlopen('http://xx.xx')
# 获取响应状态码
print(response.getcode()) # 200
# 获取请求的url地址
print(response.geturl()) # http://xx.xx
# 获取请求头
print(response.getheaders())
# 获取请求返回的数据
# response.read() 获取结果的二进制 需要自行decode()
content = response.read().decode()
# 下载,需要导入
urllib.request.urlretrieve("图片或者视频的url", filename='文件名称.后缀')
# 编码 urllib.parse.quote()
text = urllib.parse.quote('栗山千明')
print(text) # %E6%A0%97%E5%B1%B1%E5%8D%83%E6%98%8E
# 解码
text = urllib.parse.unquote('%E6%A0%97%E5%B1%B1%E5%8D%83%E6%98%8E')
print(text) # 栗山千明
模拟浏览器携带params参数/get请求
# 导入模块
import urllib.request
import urllib.parse
from fake_useragent import UserAgent
# 设置基础 URL 和请求头部信息
base_url = "https://www.xx.com/s?"
headers = {
"User-Agent": UserAgent().random
}
# 构建查询参数
kw = {
"wd": "栗山千明"
}
# 将查询参数编码并拼接到 URL 中
url = base_url + urllib.parse.urlencode(kw)
print(url) # 输出拼接后的 URL:https://www.xx.com/s?wd=%E6%A0%97%E5%B1%B1%E5%8D%83%E6%98%8E
# 创建请求对象并添加请求头部信息
request = urllib.request.Request(url=url, headers=headers)
# 发起请求并获取响应
response = urllib.request.urlopen(request)
print(response.read().decode()) # 打印响应内容
# 保存数据
with open('lsqm.html', 'wt', encoding='utf-8') as file:
file.write(response.read().decode())
发送post请求
# 导入模块
import json
import urllib.request
import urllib.parse
from fake_useragent import UserAgent
# 设置基础 URL 和请求头部信息
base_url = "https://fanyi.xx.com/sug"
headers = {
"User-Agent": UserAgent().random
}
# 构建表单数据
form_data = {
"kw": "cancer"
}
# 对表单数据进行 URL 编码并转换为 bytes 类型
data = urllib.parse.urlencode(form_data).encode('utf-8')
# 创建请求对象并添加请求头部信息和数据
request = urllib.request.Request(url=base_url, data=data, headers=headers)
# 发起请求并获取响应
response = urllib.request.urlopen(request)
# 打印响应状态码
print(response.getcode()) # 输出响应状态码:200
# 解析响应内容并打印
print(json.loads(response.read().decode())) # 输出解析后的 JSON 响应内容
"""
{'errno': 0,
'data': [
{'k': 'cancer', 'v': 'n. 癌症,恶性肿瘤; 弊病,社会恶习; 迅速蔓延的恶劣的或危险的事物; [天]巨蟹座,巨蟹宫'},
{'k': 'Cancer', 'v': 'n. 巨蟹座; [天]巨蟹宫; [人名] 坎瑟'},
{'k': 'CANCER', 'v': 'abbr. computer analysis of nonlinear circuit exclu'},
{'k': 'cancers', 'v': 'n. 癌( cancer的名词复数 ); 迅速蔓延的恶劣的或危险的事物'},
{'k': 'Cancers', 'v': 'n. 巨蟹座( Cancer的名词复数 )'}],
'logid': 2138524268}
"""
异常捕获
import urllib.error
import urllib.request
url = 'http://www.xx.comm'
try:
urllib.request.urlopen(url=url)
# URLError 为异常基类 捕获这个即可
except urllib.error.URLError as e:
print(e) # HTTP Error 503: Service Unavailable
使用代理
import urllib.request
# 创建一个代理处理器,指定代理服务器的地址和端口
handler = urllib.request.ProxyHandler({"http": "http://58.246.58.150:9002",})
# 使用代理处理器创建一个自定义的URL打开器
opener = urllib.request.build_opener(handler)
# 要访问的URL
url = 'http://xx.xx/ip'
# 使用自定义的打开器打开指定的URL,发送请求并获取响应
response = opener.open(url)
# 读取响应内容并解码为字符串,然后打印输出
print(response.read().decode())
简单总结
- urllib.request中实现了构造请求和发送请求的方法
- urllib.request.Request(url, headers, data)能构造请求
- urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应
- response.read()能够实现获取响应中的bytes字符串
- urllib.parse的unquote和quote可以实现解码和编码
- urllib.request.urlretrieve支持下载数据
urllib3
默认会进行三次链接,三次重定向检查,requests是1次。
PoolManager 是 urllib3 中用于管理连接池的类,可以通过设置不同的参数来调整连接池的行为。以下是一些常用的参数及其说明:
num_pools:表示连接池的数量,即同时可以维护的连接数。
maxsize:表示每个连接池的最大连接数,控制连接池中连接的数量。
block:表示当连接池达到最大连接数时,是否阻塞等待新连接可用。设置为 True 表示阻塞,设置为 False 表示不阻塞。
timeout:表示获取连接的超时时间,即在超时后会抛出异常。
cert_reqs:表示对服务器证书的要求级别,可设置为 CERT_NONE、CERT_OPTIONAL 或 CERT_REQUIRED。
ca_certs:表示用于验证服务器证书的受信任 CA 证书文件的路径。
cert_file:表示客户端证书文件的路径,用于与服务器进行双向证书验证。
key_file:表示客户端私钥文件的路径,用于双向证书验证时提供私钥。
retries:表示在请求失败时的重试次数。
构造简单的请求
import urllib3
from fake_useragent import UserAgent
# 创建一个 PoolManager 对象,设置超时时间为 3 秒
http = urllib3.PoolManager(timeout=3)
# 要请求的 URL
url = 'https://xx.cn/api.php'
# 发送 GET 请求
response = http.request('GET', url)
# 输出 HTTP 响应状态码
print(response.status) # 200
# 输出请求的 URL
print(response.url)
# 输出实际发送请求的 URL 地址,可能会因重定向而不同于初始请求的 URL
print(response._request_url)
# 输出响应的 HTTP 头部信息
print(response.headers)
# 输出 HTTP 响应状态码的原因短语,描述状态码的含义。一般成功代表 OK
print(response.reason)
# 将响应内容写入文件 'girl.jpg' 中
# response.data 就是获取网页返回的数据,这个数据是二进制的,所以这里可以直接写入
content = response.data
with open('girl.jpg', 'wb') as file:
file.write(content)
携带参数
import urllib3
from fake_useragent import UserAgent
# 创建一个 PoolManager 对象
http = urllib3.PoolManager()
# 要请求的 URL 注意注意 这里不能带 ? 问号
url = "https://www.xx.com/s"
# 设置请求头中的 User-Agent 为随机生成的 User-Agent
headers = {
"User-Agent": UserAgent().random
}
# 设置请求的参数
params = {"wd": '小满'}
# 发送带有请求头和参数的 GET 请求
# requests中是params,这里是fields
response = http.request("GET", url, headers=headers, fields=params)
# 检查响应状态码的原因短语是否为 "OK"
if response.reason == "OK":
# 响应的数据默认是二进制,这里需要解码为字符串
print(response.data.decode())
发送POST
import json
import urllib3
from fake_useragent import UserAgent
# 创建一个 PoolManager 对象
http = urllib3.PoolManager()
# 要请求的 URL
url = "https://fanyi.xx.com/sug"
# 设置请求头中的 User-Agent 为随机生成的 User-Agent
headers = {
"User-Agent": UserAgent().random
}
# 设置要发送的数据
data = {"kw": 'cancer'}
# 发送带有请求头和数据的 POST 请求
response = http.request("POST", url, headers=headers, fields=data)
# 检查响应状态码的原因短语是否为 "OK"
if response.reason == "OK":
# 解码响应内容
content = response.data.decode()
# 将响应内容解析为 JSON 格式并输出
print(json.loads(content))
设置代理
import urllib3
from fake_useragent import UserAgent
# 创建 ProxyManager 对象并使用代理地址
try:
# ProxyManager继承自urllib3.PoolManager,所以PoolManager 中的方法它也可以使用
proxy_http = urllib3.ProxyManager(proxy_url="http://58.246.58.150:9002")
url = "http://xx.xx/get"
response = proxy_http.request("GET", url, headers={'User-Agent': UserAgent().random})
except urllib3.exceptions.HTTPError as e:
print(e)
else:
print(response.data.decode())
捕获异常 基类为HTTPError
import urllib3
from fake_useragent import UserAgent
# 创建一个 PoolManager 对象
http = urllib3.PoolManager()
# 要访问的 URL
url = "http://3.comm"
try:
# 发送带有自定义 User-Agent 的 GET 请求
response = http.request("GET", url=url, headers={'User-Agent': UserAgent().random})
except urllib3.exceptions.HTTPError as e:
# 捕获 HTTPError 异常并打印异常信息
print(e)
requests
这里只是列出一部分的功能,更多功能建议查阅官方资料
referer
上一次访问的地址,一般防的时候盗链需要加上
cookies
为了能够通过爬虫获取到登录后的页面,或者是解决通过cookie的反扒,需要使用request来处理cookie的请求
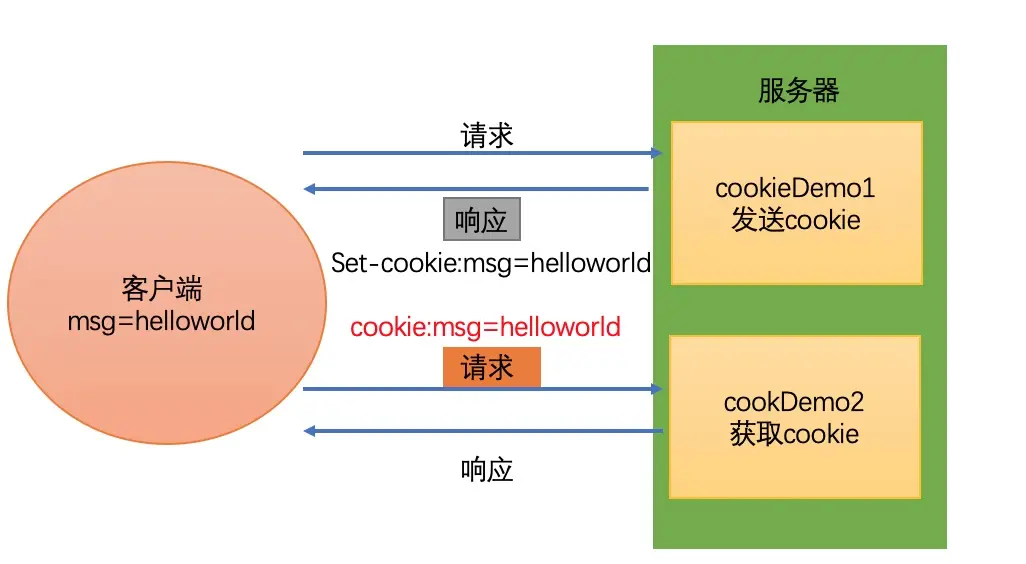
爬虫中使用cookie的利弊
带上cookie的好处
- 能够访问登录后的页面
- 能够实现部分反反爬
带上cookie的坏处
- 一套cookie往往对应的是一个用户的信息,请求太频繁有更大的可能性被对方识别为爬虫
- 那么上面的问题如何解决?使用多个账号。
requests处理cookie的方法
使用requests处理cookie有三种方法:
- 把cookie字符串放在headers中
- headers中的cookie:
- 使用分号(;)隔开
- 分号列表的类似a=b形式的表示一条cookie
- a=b中,a表示键(name),b表示值(value)
- headers中仅仅使用了cookie的name和value
- 把cookie字典传给请求方法的cookies参数接收
- 使用requests提供的session模块
*注意:
cookie有过期时间,所以直接复制浏览器中的cookie可能意味着下一次程序运行的时候需要替换代码中的cookie,对应的我们也可以通过一个程序专门来获取cookie供其他程序使用;当然也有很多网站的cookie过期时间很长,这种情况下,直接复制cookie来使用更加简单。
cookies传递的3种方式
# 1. 直接带在请求参数中
import requests
from typing import Dict
def fetch_cookis() -> Dict:
cookies = "填写自己的cookie"
cookies_dict = dict()
for item in cookies.replace(' ', '').replace('\n', '').split(';'):
k, v = item.split('=', 1)
cookies_dict.setdefault(k, v)
return cookies_dict
def get_request(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers, cookies=fetch_cookis())
content = response.text
with open('jd.html', 'w', encoding='utf-8') as f:
f.write(content)
def main():
url = "https://item.xx.com/100081954750.html?bbtf=1"
get_request(url)
if __name__ == '__main__':
main()
# 方案2 推荐 直接代带进去字典种,就不用写cookies这个参数了
import requests
def get_request(url):
cookies = "填写自己的cookie"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
'Cookies': cookies
}
response = requests.get(url=url, headers=headers)
content = response.text
with open('jd.html', 'w', encoding='utf-8') as f:
f.write(content)
def main():
url = "https://item.xx.com/100081954750.html?bbtf=1"
get_request(url)
if __name__ == '__main__':
main()
使用requests.session处理cookie
前面使用手动的方式使用cookie,那么有没有更好的方法在requests中处理cookie呢?
requests提供了一个叫做session的类,来实现客户端和服务端的会话保持
会话保持有两个函数:
- 保存cookie,下一次请求会带上前一次的cookie
- 实现和服务端的长连接,加快请求速度
使用方法:
session = requests.session()
response = session.get(url, headers)
session示例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方的时候,会带上前一次的cookie
session请求案例
import os
import requests
from fake_useragent import UserAgent
# 初始化一个requests会话
session = requests.session()
# 定义自定义User-Agent头部信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
# 基础URL和相对URL
base_url = '某网站'
rel_url = '某网站下面的json地址'
# 发送一个GET请求到基础URL
# 第一次请求的目的是为了拿到服务器返回的cookie方便下次请求
res1 = session.get(url=base_url, headers=headers)
# 发送一个GET请求到相对URL
# 这次请求会自动携带cookie
res = session.get(url=rel_url, headers=headers)
# 打印第二个URL的JSON响应
print(res.json())
使用requests.cookies获取cookies
# 登录成功后,可以通过这个方法拿到cookies
cookies = request.cookies
get请求的查询字符串传递 params

import requests
from urllib.parse import unquote
def get_request(url, keyword):
params = {'q': keyword}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers, params=params)
content = response.text
with open(f'{keyword}.html', 'w', encoding='utf-8') as f:
f.write(content)
def main():
url = "https://cn.xx.com/search?"
get_request(url, '栗山千明')
if __name__ == '__main__':
main()
将URL中的百分号编码的字符解码成原始字符 unquote
from urllib.parse import unquote
name = '%E6%A0%97%E5%B1%B1%E5%8D%83%E6%98%8E'
rel_name = unquote(name)
print(rel_name) # 栗山千明
post参数传递 data
data = {'kw': keyword}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"
}
response = requests.get(url=url, headers=headers, data=data)
session对象
http请求,每一次都是一个新的-->cookie需要自己处理携带
session可以自动处理cookies
import requests
# session 会自动保存登录状态,下次直接使用session发送请求,就不用再处理cookie了
session = requests.session()
response = session.post(url='url')
session的小案例
import requests
from base64 import b64decode, b64encode
from fake_useragent import UserAgent
class Spider:
base_url = b'aHR0cHM6Ly94dWVxaXUuY29tLw=='
data_url = b'aHR0cHM6Ly9zdG9jay54dWVxaXUuY29tL3Y1L3N0b2NrL2JhdGNoL3F1b3RlLmpzb24/c3ltYm9sPVNIMDAwMDAxLFNaMzk5MDAxLFNaMzk5MDA2LFNIMDAwNjg4LFNIMDAwMDE2LFNIMDAwMzAwLEJKODk5MDUwLEhLSFNJLEhLSFNDRUksSEtIU1RFQ0gsLkRKSSwuSVhJQywuSU5Y'
headers={'User-Agent': UserAgent().random}
def encryption(self, url):
return b64decode(url).decode()
# 不携带cookies去访问
def first_conn(self, url=None):
url = self.data_url if url is None else self.base_url
response = requests.get(url=self.encryption(url), headers=self.headers)
print(response.text) # 拿不到数据
return response.cookies
# 携带cookies去访问
def with_cookies_conn(self):
cookies = self.first_conn(url=self.base_url)
response = requests.get(url=self.encryption(self.data_url), headers=self.headers, cookies=cookies)
print('携带cookies去访问', response.text) # 能拿到数据
# 通过session保持通话,持续访问
def session_conn(self):
session = requests.session()
session.get(url=self.encryption(self.base_url), headers=self.headers)
response = session.get(url=self.encryption(self.data_url), headers=self.headers)
print('通过session访问', response.text) # 能拿到数据 并且简化了操作
spider = Spider()
# 没有携带cookies直接访问
spider.first_conn()
# 携带cookies去访问
spider.with_cookies_conn()
# 通过session去访问
spider.session_conn()
post请求的json和data区别
参考请求体中:Accept 参数
如果是json 那么请求体就类似 application/json, text/plain, */* 这样的请求需要使用json
如果是 */* 或者含有urlencode 那么就使用data即可
两种解码方式
import requests
response = requests.get('https://xx.xx')
# 方式1 直接通过response.text 如果乱码需要自行解码
content = response.text
# 方式2 通过获取resonse.content 然后自行解码decode()
# 一般情况下推荐使用这种,不论是字节流还是字符都可用操作
content = response.content.decode()
获取 HTTP 响应内容的编码格式 response.apparent_encoding
response.apparent_encoding是 Python 中 requests 库中的一个属性,用于获取 HTTP 响应内容的编码格式。当服务器没有在 HTTP 响应头中指定编码格式时,apparent_encoding会尝试根据内容来猜测编码格式,然后返回一个推测的编码格式。这个属性在处理网页内容时特别有用,因为有些网页可能没有正确声明编码格式,或者声明的编码格式不准确,所以需要推测正确的编码格式以正确地解析内容。
# 自用写法 大部分网站都🆗
response.encoding = 'utf-8' if response.encoding == 'utf-8' else response.apparent_encoding
超时设置 timeout
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错
注意:这个方法还能够拿来检测代理ip的质量,如果一个代理p在很长时间没有响应,那么添加超时之后也会报错,对的这个ip就可以从代理ip池中删除。
# timeout=超时时间 单位秒
# 也可以是一个元组 里面是数字类型
# 通过添加timeout参数,能够保证在3秒钟内返回响应,否则会报错
response = requests.get(url=url, headers=headers, timeout=3)
response的常见属性
import requests
response = requests.get('https://xx.xx/api.php')
print(response.ok) # 打印状态码 200-299之间都成功
print(response.content) # 响应体 ---> 二进制格式
print(response.status_code) # 响应状态码
print(response.headers) # 响应头
print(response.cookies) # 响应的cookies
print(response.cookies.get_dict()) # cookiejar对象 --> 转成字典格式 也可以dict(response.cookies)
print(response.cookies.items()) # cookie的value值
print(response.url) # 最后一次请求的地址,如果重定向了也会拿到
print(response.request.url) # 第一次发起请求的地址,最初请求的url
print(response.history) # 访问历史 ——> 重定向才会有
print(response.encoding) # 编码格式 可以通过前端head标签的charset查看
response.iter_content() # 图片,视频 --> 迭代着把数据保存到本地
response.ok() # 如果status_code小于200,response.ok返回True
# 如果status_code大于200,response.ok返回False
import requests
response = requests.get('https://xx.xx/api.php')
with open('小姐姐.jpg', 'wb') as file:
# 这里可以指定字节参数 如果一个文件(图片或者视频)很大 可以使用这个去下载 提速
for line in response.iter_content(chunk_size=1024):
file.write(line)
SSL认证
# http 和 https
http: 超文本传输协议
https: 安全的超文本传输协议
https = http + ssl/tls
https加了一个ssl证书,必须有整数才能互相通信,更加安全。
如果遇到xxxz提示证书不安全,解决方案一般有2个
1. 不携带整数
2. 自己写一个整数
如何不携带证书 verify=False
只会出现在HTTPS请求的页面
import requests
# 比如提示一个证书不安全的网页,页面有一个继续访问,那么这个verify=False 就相当于这个操作
# 提示不安全的附近有一个自己添加证书,就相当于 cert
requests.get('xx.html', verify=False, cert=('/path/server/crt', 'path/ley'))
异常处理 RequestException
import requests
try:
response = requests.get('https://3.xx', timeout=2)
# RequestException 最大的异常处理 捕获这个处理一次就可以了
except requests.exceptions.RequestException as e:
print(e)
else:
print(response.text)
主动抛出异常 response.raise_for_status()
import re
import requests
from fake_useragent import UserAgent
def get_request():
url = 'https://xx.xx/get'
try:
# 尝试3次
requests.adapters.DEFAULT_RETRIES = 3
response = requests.get(url=url, headers={'User-Agent': UserAgent().random})
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(e)
if __name__ == '__main__':
msg = get_request()
print(msg)
文件上传 files
import requests
files = {"file": open('小姐姐.jpg', "rb")}
response = requests.post("https://xx.xx/post", files=files)
print(response)
代理
为什么要使用代理服务器
1.让服务器以为不是同一个客户端在请求
2.防止我们的真实地址被泄露,防止被追究
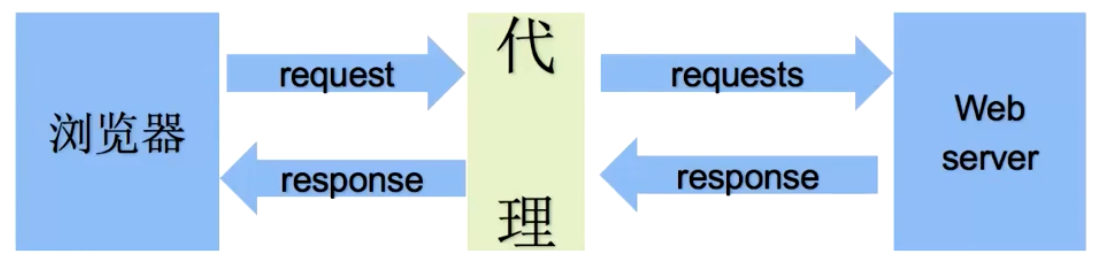
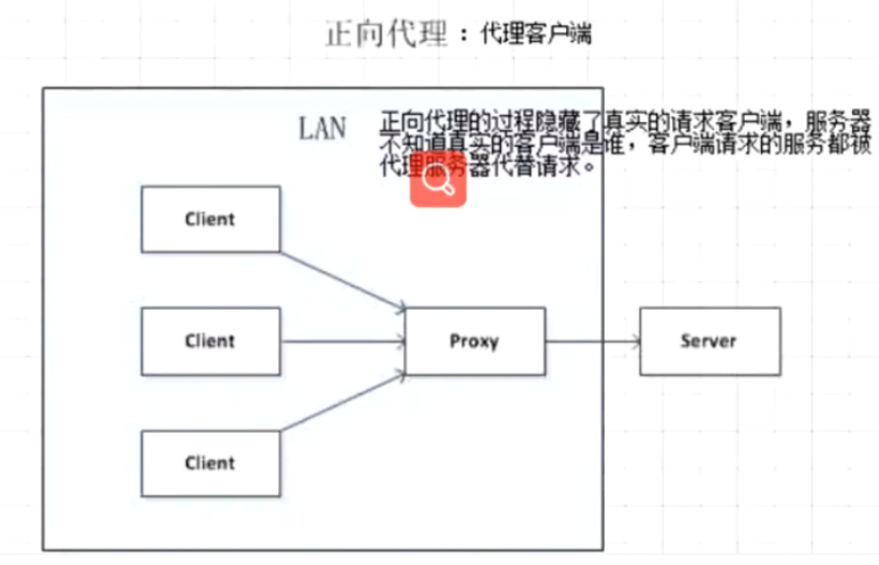
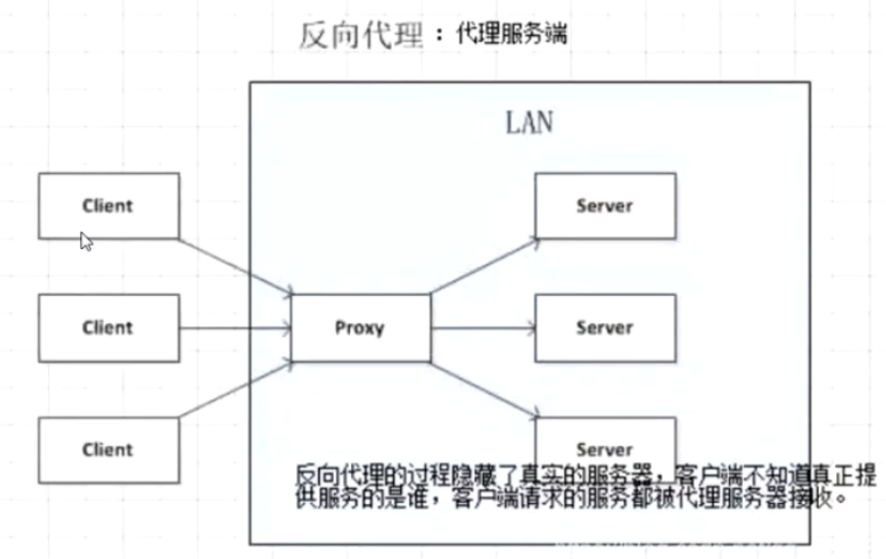
正向代理和反向代理
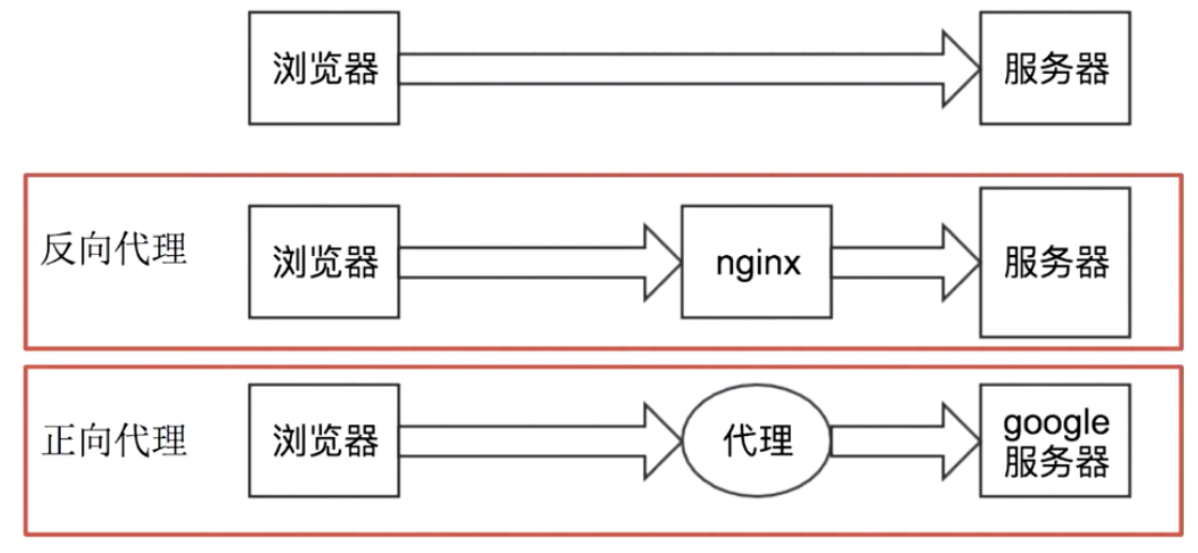
从上图可以看出:
- 正向代理:对于浏览器知道服务器的真实地址,例如VPN
- 反向代理:浏览器不知道服务器的真实地址,录入nginx
正向代理:
客户端与正向代理客户端再同一局域网,客户端发出请求,正向代理代替客户端向服务器发出请求,服务器不知道谁是真正的客户端,正向代理隐藏了真实的请求客户端。
反向代理:
服务器与反向代理在同一个局域网,客户端发出请求,反向代理接收请求,反向代理服务器会把我们的请求转发到真实提供服务的各台服务器,Nginx就是性能非常好的反向代理服务器,用来做负载均衡。
代理IP的分类
根据代理IP的匿名程度,代理IP可以分为下面三类:
透明代理(Transparent Proxy):透明代理的意思是客户端根本不需要知道有代理服务器的存在,但是它传送的仍然是真实的IP。使用透明代理时,对方服务器是可以知道你使用了代理的,并且他们也知道你的真实IP。你想要隐藏的话,不要用这个。
- 透明代理为什么无法隐藏身份呢?
- 因为他们将你的真实IP地址发送给了对方的服务器,所以无法达到保护真实信息。
匿名代理(Anonymous Proxy):匿名代理隐藏了您的真实IP,但是访问对象是可以检测到你使用了代理服务器访问他们的。会改变我们的请求信息,服务器端有可能会认为我们使用了代理。不过使用此种代理时,虽然被访问的网站不能知道你的IP地址,但仍然可以知道你在使用代理,当然某些能够侦测IP的网页也是可以查到你的IP的。
高匿代理(Elite proxy 或 High Anonymity Proxy):高匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户端浏览器在访问它,这时客户的真实IP是隐藏的,完全用代理服务器的信息替代了您的所有信息,就像您就是完全使用那台代理服务器直接访问对象,同时服务端不会认为我们使用了代理。IPDIEA覆盖全球240+国家地区IP高匿名代理不必担心被追踪。
。
在使用的时候,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
- http代理
- https代理
- socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择

代理IP使用的注意点
1. 反反爬
使用代理ip是非常必要的一种反反爬的方式
但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
- 一段时间内,检测IP访问的频率,访问太多、太频繁会屏蔽
- 检查Cookie,User-Agent,Refer等header参数,如果没有则屏蔽
- 服务方购买所有代理提供商,加入到反爬虫数据库里,如果检测是代理则屏蔽
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,必要每次都用一个ip
2. 代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没有办法使用,这时候就需要通过程序去检测哪些可用,把不能用的删除掉。
3. 代理服务器平台的使用
^_ ^ 自行查询 ^_^
如何使用
import requests
from fake_useragent import UserAgent
proxies = {
# 字典的value请求方式写不写都一样
"http": "http://58.246.58.150:9002",
"https": "socks5://219.243.212.118:8443"
}
# proxies = {
# 字典的value请求方式写不写都一样
# "http": "58.246.58.150:9002",
# "https": "219.243.212.118:8443"
#}
}
url = 'https://myip.xx.net/'
# proxies={} 这个就是使用代理
response = requests.get(url=url, headers={'User-Agent': UserAgent().random}, proxies=proxies)
# 也支持全局带 即session()
session = requests.session()
session.get(url=url, headers={'User-Agent': UserAgent().random}, proxies=proxies)
# 如果要随机使用代理,可以把全部代理放进去一个列表里面,然后通过random.choice()实现
import random
proxies_list = [{}, {}, {}...]
proxies = random.choice(proxies_list)
# 测试代理的可用性,先不通过代理请求获取结果,然后再通过代理请求,拿到的结果不一样就是使用成功了。
https://httpbin.org/ip
代理报错参考文章:
设置重连次数
import requests
try:
# 尝试3次
requests.adapters.DEFAULT_RETRIES = 3
...
except requests.exceptions.RequestException as e:
print(e)
接口请求认证
import requests
from requests.auth import HTTPBasicAuth
reponese=requests.get('https://xx.com/user', auth=HTTPBasicAuth('user', 'pass'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号