14-Django之聚合、分组、F与Q查询
聚合查询
需要借助关键字:aggregate
使用环境:聚合查询通常情况下都是配合分组一起使用的
查询结果:使用聚合函数,从每一个组中获取结果:字典
注意点:
聚合函数必须在分组之后才能使用
没有分组,即默认整体就是一组
查询结果为,普通字典
# 使用聚合查询,需要导入相关模块
from django.db.models import Max, Min, Sum, Count, Avg
# 聚合查询通常情况下都是配合分组一起使用的
# 只要是跟数据库相关的模块
# 基本上都在 django.db.models 里面
# 上述没有那么应该在 django.db里面
from django.db.models import Avg, Sum, Count, Max, Min
# 查询单个
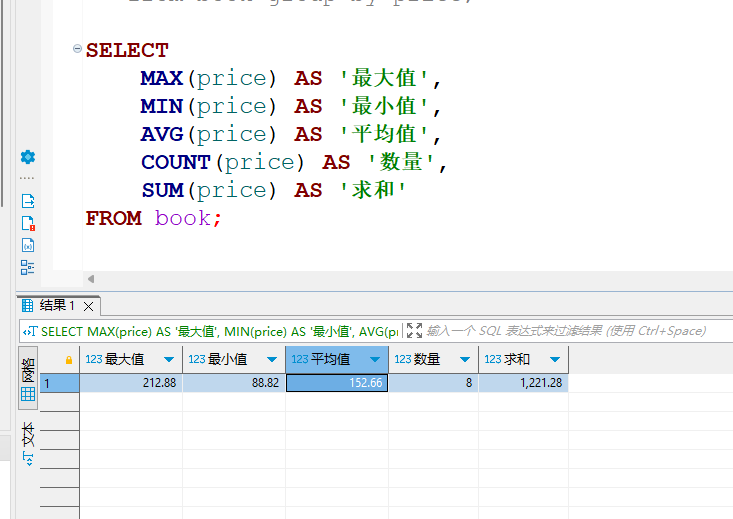
res = models.Book.objects.aggregate(Sum('price'))
print(res) # {'price__sum': Decimal('1221.28')}
# 查询全部
items = models.Book.objects.aggregate(Max('price'), Min('price'), Avg('price'), Count('price'), Sum('price'))
print(items, type(items))
# {'price__max': Decimal('212.88'), 'price__min': Decimal('88.82'), 'price__avg': Decimal('152.660000'),
# 'price__count': 8, 'price__sum': Decimal('1221.28')} <class 'dict'>
for k, v in items.items():
print(k, v, sep='\t')
# price__max 212.88
# price__min 88.82
# price__avg 152.660000
# price__count 8
# price__sum 1221.28
分组查询
关键字:annotate
MySQL分组查询特点
- 分组之后默认只能获取到分组的依据
- 组内其他字段都无法直接获取了
- 严格模式: ONLY_FULL_GROUP_BY
from django.db.models import Avg, Sum, Count, Max, Min
# 1. 统计每一本书的作者个数
res = models.Book.objects.annotate() # models后面点什么,就是按什么分组
res1 = models.Book.objects.annotate(author_num=Count('authors')).values('title', 'author_num')
res2 = models.Book.objects.annotate(author_num=Count('authors__nid')).values('title', 'author_num')
print(res, res1, res2)
# author_num 这是自己定义的字段 用来存储统计出来的每本书对应的作者个数,理解为变量名就可以了
# 2. 统计每个出版社卖的最贵的书的价格
res = models.Publish.objects.annotate(max_price=Max('book__price')).values('name', 'max_price')
print(res)
# <QuerySet [{'name': '上海出版社', 'max_price': Decimal('212.88')}, {'name': '湖南出版社', 'max_price': Decimal('88.99')}]>
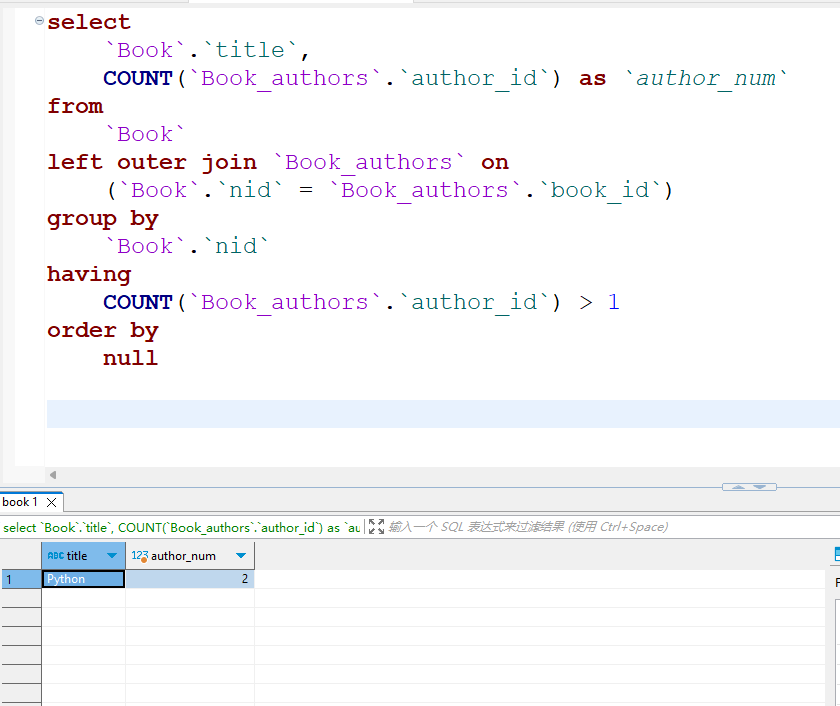
# 3. 统计不止一个作者的图书
# 先按照图书分组 求每一本书对应的作者个数
# 过滤出不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title', 'author_num')
print(res) # <QuerySet [{'title': 'Python', 'author_num': 2}]>
# 4. 查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res)
# 5. 统计 price 大于150元 的书籍的作者个数
res = models.Book.objects.filter(price__gt=150).annotate(num_authors=Count('authors')).values('title', 'num_authors')
print(res)
演示案例3
F与Q查询
使用前记得先导入
from django.db.models import F, Q
# F查询
"""
能够帮助你直接获取到表中某个字段对应的数据
"""
from django.db.models import F, Q
# 1. 将所有的书籍价格提升 20 块
models.Book.objects.update(price=F('price') + 20)
# 2. 在 Python 书的名称后面加上 '爬虫从入门到放弃' 字样
"""
在操作字符串类型的数据的时候 F不能够直接做到字符串的拼接
需要使用 Concat 同MySQL中的concat一样的用法
"""
from django.db.models.functions import Concat
from django.db.models import Value
# Concat(F('title'), Value('爬虫从入门到放弃')) 表示将原标题与字符串 '爬虫从入门到放弃' 进行连接。
models.Book.objects.filter(title='Python').update(title=Concat(F('title'), Value('爬虫从入门到放弃')))
点我查看MySQL数据
mysql> select * from book;
+-----+------------+----------------------------+--------+------------+
| nid | title | pub_date | price | publish_id |
+-----+------------+----------------------------+--------+------------+
| 1 | JavaScript | 2023-03-24 16:00:00.000000 | 212.88 | 1 |
| 2 | Typescript | 2024-03-04 16:00:00.000000 | 112.58 | NULL |
| 3 | Python | 2022-12-11 16:00:00.000000 | 88.82 | 3 |
| 4 | Dart | 2023-11-03 16:00:00.000000 | 150.00 | 1 |
| 5 | Golang | 2024-01-10 16:00:00.000000 | 200.12 | 1 |
| 6 | Julia | 2024-02-20 16:00:00.000000 | 178.90 | 1 |
| 7 | Ruby | 2006-06-05 16:00:00.000000 | 188.99 | 1 |
| 8 | C++ | 1999-09-11 16:00:00.000000 | 88.99 | 3 |
+-----+------------+----------------------------+--------+------------+
8 rows in set (0.03 sec)
mysql> select * from book;
+-----+------------+----------------------------+--------+------------+
| nid | title | pub_date | price | publish_id |
+-----+------------+----------------------------+--------+------------+
| 1 | JavaScript | 2023-03-24 16:00:00.000000 | 232.88 | 1 |
| 2 | Typescript | 2024-03-04 16:00:00.000000 | 132.58 | NULL |
| 3 | Python | 2022-12-11 16:00:00.000000 | 108.82 | 3 |
| 4 | Dart | 2023-11-03 16:00:00.000000 | 170.00 | 1 |
| 5 | Golang | 2024-01-10 16:00:00.000000 | 220.12 | 1 |
| 6 | Julia | 2024-02-20 16:00:00.000000 | 198.90 | 1 |
| 7 | Ruby | 2006-06-05 16:00:00.000000 | 208.99 | 1 |
| 8 | C++ | 1999-09-11 16:00:00.000000 | 108.99 | 3 |
+-----+------------+----------------------------+--------+------------+
8 rows in set (0.00 sec)
mysql> select * from book;
+-----+--------------------------------+----------------------------+--------+------------+
| nid | title | pub_date | price | publish_id |
+-----+--------------------------------+----------------------------+--------+------------+
| 1 | JavaScript | 2023-03-24 16:00:00.000000 | 252.88 | 1 |
| 2 | Typescript | 2024-03-04 16:00:00.000000 | 152.58 | NULL |
| 3 | Python爬虫从入门到放弃 | 2022-12-11 16:00:00.000000 | 128.82 | 3 |
| 4 | Dart | 2023-11-03 16:00:00.000000 | 190.00 | 1 |
| 5 | Golang | 2024-01-10 16:00:00.000000 | 240.12 | 1 |
| 6 | Julia | 2024-02-20 16:00:00.000000 | 218.90 | 1 |
| 7 | Ruby | 2006-06-05 16:00:00.000000 | 228.99 | 1 |
| 8 | C++ | 1999-09-11 16:00:00.000000 | 128.99 | 3 |
+-----+--------------------------------+----------------------------+--------+------------+
8 rows in set (0.00 sec)
# Q查询
"""
filter括号内多个参数是and关系
"""
from django.db.models import Q
# Q包裹逗号分割 还是and关系
# 筛选出价格在 100 到 200 之间的书籍记录。
res1 = models.Book.objects.filter(Q(price__lt=200), Q(price__gt=100))
print(res1)
# | or关系
# 筛选出发布日期在 '2024-01-01' 之前或价格大于等于 150 的书籍记录。
res2 = models.Book.objects.filter(Q(pub_date__lt='2024-01-01') | Q(price__gte=150))
print(res2)
# ~not关系
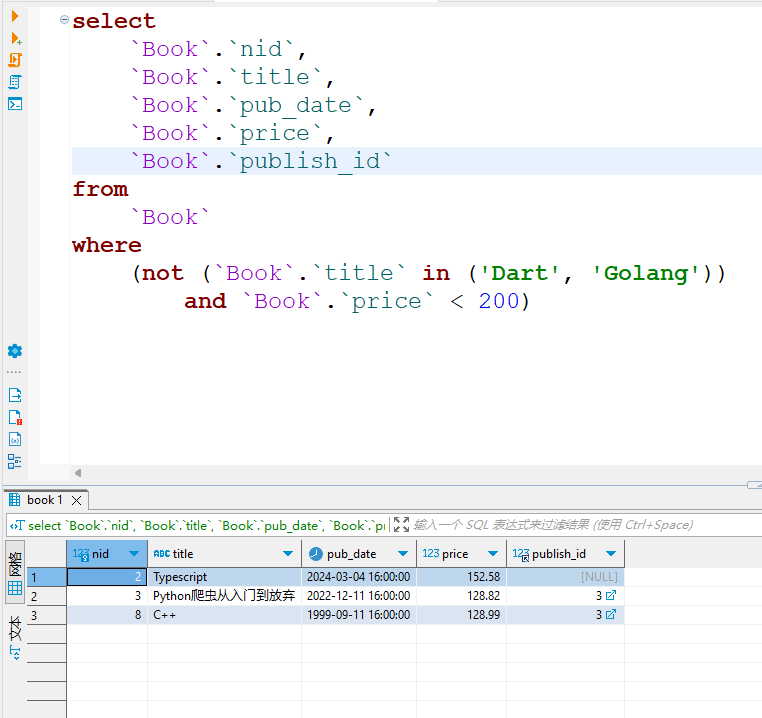
# 筛选出标题不是 'Dart' 或 'Golang' 且价格小于 200 的书籍记录。
res3 = models.Book.objects.filter(~Q(title__in=['Dart', 'Golang']) , Q(price__lt=200))
print(res3)
# Q的高阶用法 能够将查询条件左边也变成字符串的形式
# 提前生成 Q 对象 并使用 append 添加条件
# 筛选出价格大于 200 或者发布日期在 '2000-01-01' 之后的书籍记录。
q = Q()
q.connector = 'or'
q.children.append(['price__gt', 200])
q.children.append(['pub_date__gt', '2000-01-01'])
res = models.Book.objects.filter(q) # 默认是and关系
print(res)
特殊参数choices
- 定义字段时,指定
choiceschoices的值为元组套元组或列表套元组,(事先定义好,一般在该表类中定义该字段之前定义)- 每一个元组存放两个元素,形成一种对应关系
- 往数据库中存值时,该字段的值为元组第一个元素即可
- 通过
对象.get_字段名_display()获取对应的元组的第二个元素值,当没有对应关系时,返回的是它本身
# 数据准备
class SimpleTest(models.Model):
name = models.CharField(max_length=32, verbose_name='姓名')
gender_choice = [
(1, '男'),
(2, '女'),
(3, '保密')
]
# 迁移数据库
python manage.py makemigrations
python manage.py migrate
# 录入数据并测试结果
models.SimpleTest.objects.create(name='小满', gender=2)
models.SimpleTest.objects.create(name='兰陵王', gender=1)
models.SimpleTest.objects.create(name='大乔', gender=2)
models.SimpleTest.objects.create(name='小乔', gender=3)
models.SimpleTest.objects.create(name='老夫子', gender=4)
for user_obj in models.SimpleTest.objects.all():
print(user_obj.gender, end='\t')
print(user_obj.get_gender_display())
"""
2 女
1 男
2 女
3 保密
4 4
"""
mysql> select * from book_simpletest;
+----+-----------+--------+
| id | name | gender |
+----+-----------+--------+
| 1 | 小满 | 2 |
| 2 | 兰陵王 | 1 |
| 3 | 大乔 | 2 |
| 4 | 小乔 | 3 |
| 5 | 老夫子 | 4 |
+----+-----------+--------+
5 rows in set (0.01 sec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号