7-Django的路由系统
版本语法
Django1.x版本语法
from django.conf.urls import url
urlpatterns = [
url(正则表达式, views视图函数,参数,别名)
]
Django2.x+版本语法
from django.urls import path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail)
]
# 要从 URL 中取值,使用尖括号。
# 捕获的值可以选择性地包含转换器类型。比如,使用 <int:name> 来捕获整型参数。如果不包含转换器,则会匹配除了 / 外的任何字符。
# 这里不需要添加反斜杠,因为每个 URL 都有。比如,应该是 articles 而不是 /articles 。
参数说明
from django.conf.urls import url
urlpatterns = [
path(路径名, views视图函数,参数,别名),
]
# 路径名:在浏览器端口后请求的路径名
# views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
# 参数:可选的要传递给视图函数的默认参数(字典形式)
# 别名:一个可选的name参数
使用正则表达式(了解)
# 如果要在Django3.x 以上的版本使用老版本的正则语法,需要先引入
from django.urls import re_path
# 在 Python 正则表达式中,命名正则表达式组的语法是 (?P<name>pattern) ,其中 name`是组名,pattern`是要匹配的模式。
# 这里是先前 URLconf 的一些例子,现在用正则表达式重写一下:
from django.urls import path, re_path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<slug>[\w-]+)/$', views.article_detail),
]
这实现了与前面示例大致相同的功能,除了:
将要匹配的 URLs 将稍受限制。比如,10000 年将不在匹配,因为 year 被限制长度为4。
无论正则表达式进行哪种匹配,每个捕获的参数都作为字符串发送到视图。
当从使用path()切换到re_path()(反之亦然),要特别注意,视图参数类型可能发生变化,你可能需要调整你的视图。
无名分组
分组就是将某段正则表达式用
()括起来
# 无名分组 无名分组就是将括号内正则表达式匹配到的内容当做位置参数传给后面的视图函数
re_path(r'^text/(\d+)/', views.test),
def test(request,data):
print(data)
return HttpResponse('test')
有名分组
# 有名分组 可以给正则表达式起一个别名
# 有名分组就是将括号内正则表达式匹配到的内容当做关键字参数传给后面的视图函数
re_path(r'^testadd/(?P<year>\d+)', views.testadd),
def testadd(request, year):
print(year)
return HttpResponse("testadd")
无名有名混用
# 无名有名混合使用
# 结论:无名分组和有名分组不能混用
re_path(r'^index/(\d+)/(?P<year>\d+)/', views.index),
# 访问路由获取不到 (\d+) 的内容
# 但是同一个分组可以使用多次
re_path(r'^test/(\d+)/(\d+)/',views.test),
re_path(r'^test/(?P<xxx>\d+)/(?P<year>\d+)/',views(r'^test/(?P<xxx>\d+)/(?P<year>\d+)/',viewsre_path.test),
def index(request,args,year):
return HttpResponse("index")
反向解析
通过一些方法得到一个结果,该结果可以直接访问对应的url触发对应的试图函数,即定义name=一个别名,可以通过这个别名去获取
127.0.0.1:8000/profile/settings/中的profile/settings/
# 在需要解析URL的地方,对于不同层级,Django提供了不同的工具用于URL反查:
# 在模板语言中:使用url模板标签。(也就是写前端网页时)
# 在Python代码中:使用reverse()函数。(也就是写视图函数等情况时)
# 在更高层的与处理Django模型实例相关的代码中:使用get_absolute_url()方法。(也就是在模型model中,参考前面的章节)
# 所有上面三种方式,都依赖于首先在path种为url添加name属性
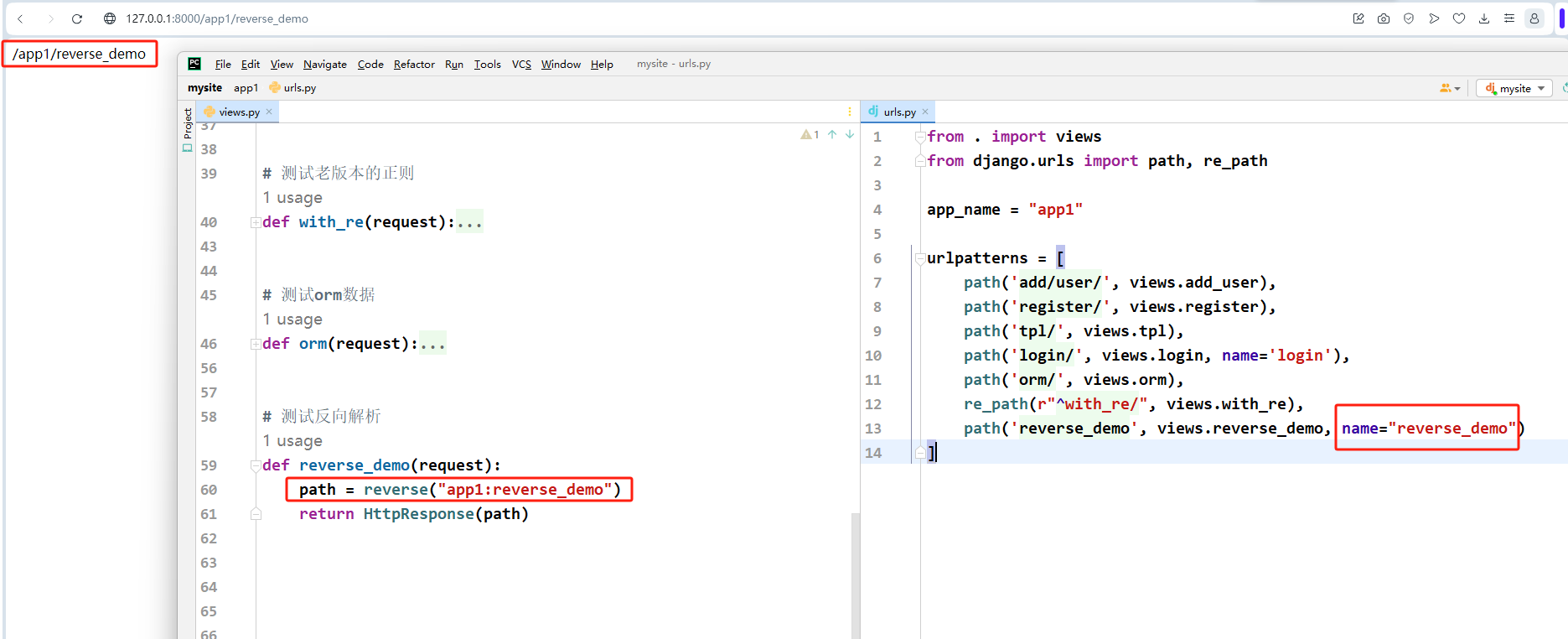
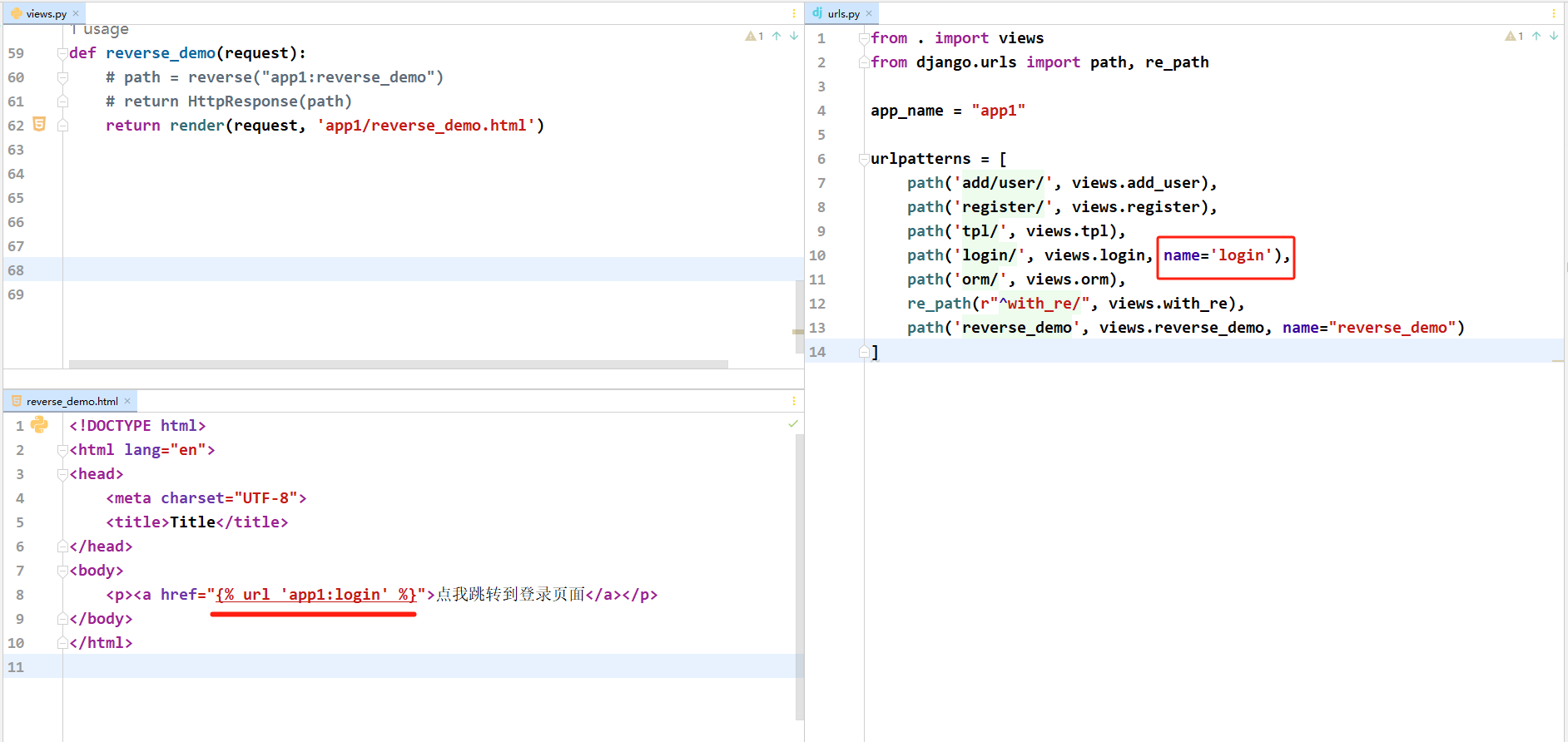
# urls.py
path('login/', views.login, name='login')
# views.py
from django.urls import reverse
def with_re(request):
name = reverse('login')
return HttpResponse(name)
# 浏览器得到结果 /login/
路由分发
Django 的路由分发就像是地图上的指示牌,帮助用户找到正确的目的地(视图函数)。它帮助确定用户在浏览器中输入的 URL 应该导向哪个页面。这样,开发人员可以更好地组织和管理网站的不同页面,让用户能够顺利访问他们想要的内容。
- 方便管理,把路由分发到各自的APP内部进行维护
- 总的路由会更加方便维护,解耦合,代码也不会冗余
- 每一个项目下的APP都应该包括以下几个项目(templates,static,urls,views)
路由分发的场景
1、Django的每一个应用都可以有自己的templates文件夹,urls.py、static文件夹,正是基于这个特点,Django能够非常好的做到分组开发(每个人只写自己的app),公司中组长只需要将下属写的app全部拷贝到一个新的Django项目中,然后在配置文里面注册所以的app再利用路由分发的特点将所以app整合起来
2、当一个Django项目中url特别多的时候,总路由urls.py代码非常冗余不好维护,这个时候也可以利用路由分发来减轻总路由的压力
利用路由分发之后,总路由不再干路由与视图函数的直接对应关系,而是做一个分发处理,识别当前url是属于那个应用下的,直接分发给对应的应用去处理
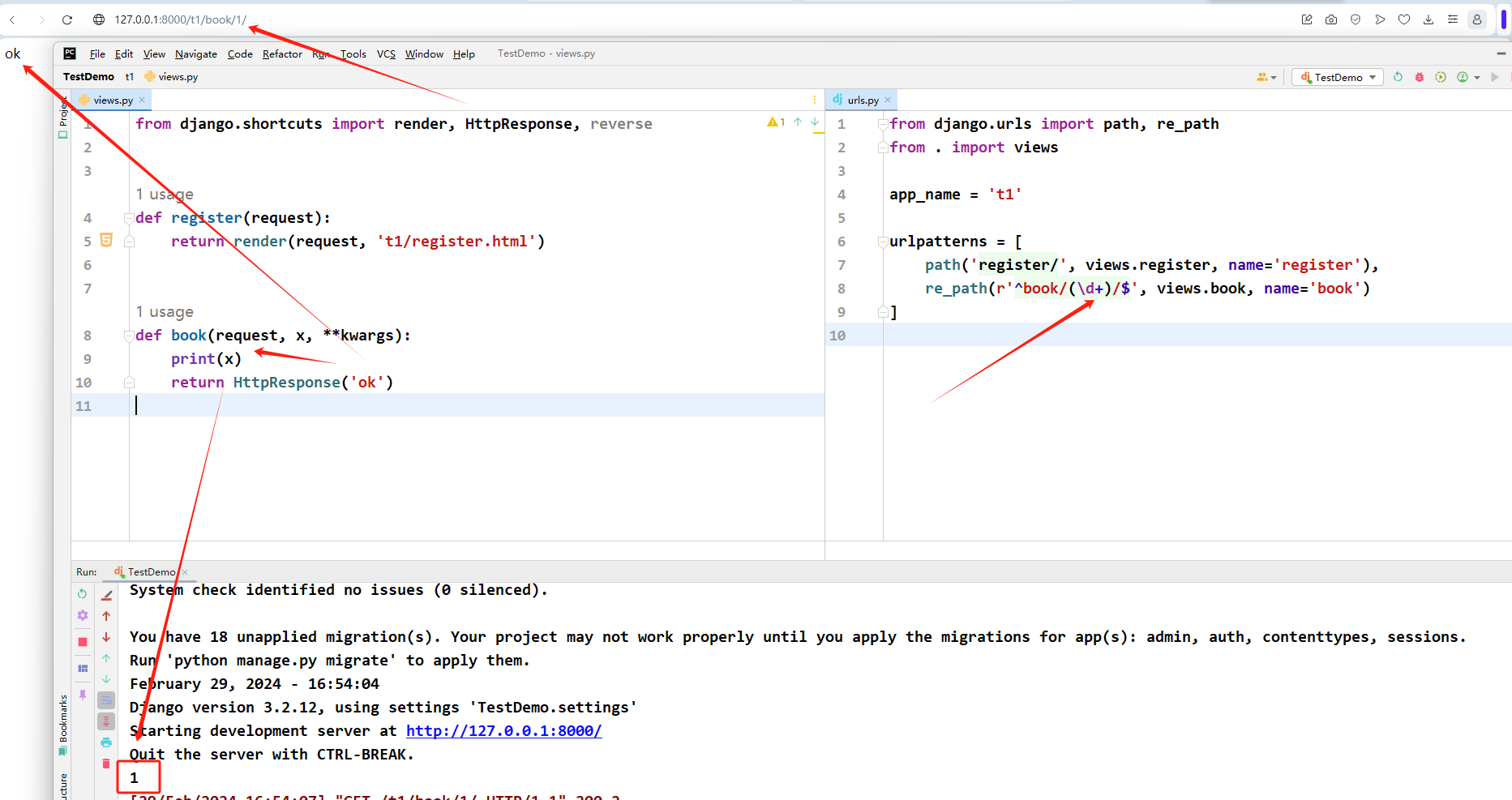
# 路由分发其实很简单
# 1.在主路由下面导入模块include
# 2.在项目下的APP内新建一个urls.py
# 3.在APP/urls.py里面导入path,然后导入视图层views,也起一个变量名为urlpatterns的列表,格式参考主路由写就可以了
# 主urls.py
from django.urls import path, include
# 由一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
path('app1/', include('app1.urls',)),
]
# app1.py
from . import views
from django.urls import path
urlpatterns = [
path('tpl/', views.tpl)
]
名称空间namespace
我么只需要在app自己本身的urls.py文件内,添加一行
app_name = 'your_app_name'即可。注意不是在根路由文件中。一般就和自己的app同命即可,因为项目里面不会有2个同样名字的app。使用的方式很简单:
# 视图中
reverse('your_app_name:index',args=(...))
# 模板中
{% url 'your_app_name:index' ... %}
伪静态
静态网页:自己和自己玩,不会和服务器交互,就算静态网页
动态网页:和服务器有数据交互
伪静态:将一个动态网页伪装成静态网页
搜索引擎本质上就是一个巨大的爬虫程序
伪装的目的在于增大本网站的seo查询力度,并且增加搜索引擎收藏本网页的概率。
Django版本的区别
路由匹配规则
Django1.x路由层使用的是url方法
在Django2.x版本以后在路由层使用的是path方法
url() 第一个参数支持正则
path() 第一个参数不支持正则,写什么就匹配到什么
正则匹配规则
在Django2.x以后也可以使用正则表单式,但是使用的方法是re_path
- path与re_path或者1.0中的url的不同之处是,传给path的第一个参数不再是正则表达式,而是一个完全匹配的路径。相同之处是第一个参数中的匹配字符均无需加前导斜杠。
- 使用尖括号(<>)从url中捕获值,相当于有名分组。
- <>中可以包含一个转化器类型(converter type),比如使用 int:name 使用了转换器int若果没有转化器,将匹配任何字符串,当然也包括了 / 字符。
from django.urls import path, re_path
re_path(r'^fuc/(?P<year>\d+)', views.func)
# 等价于
url(r'^fuc/(?P<year>\d+)', views.func)
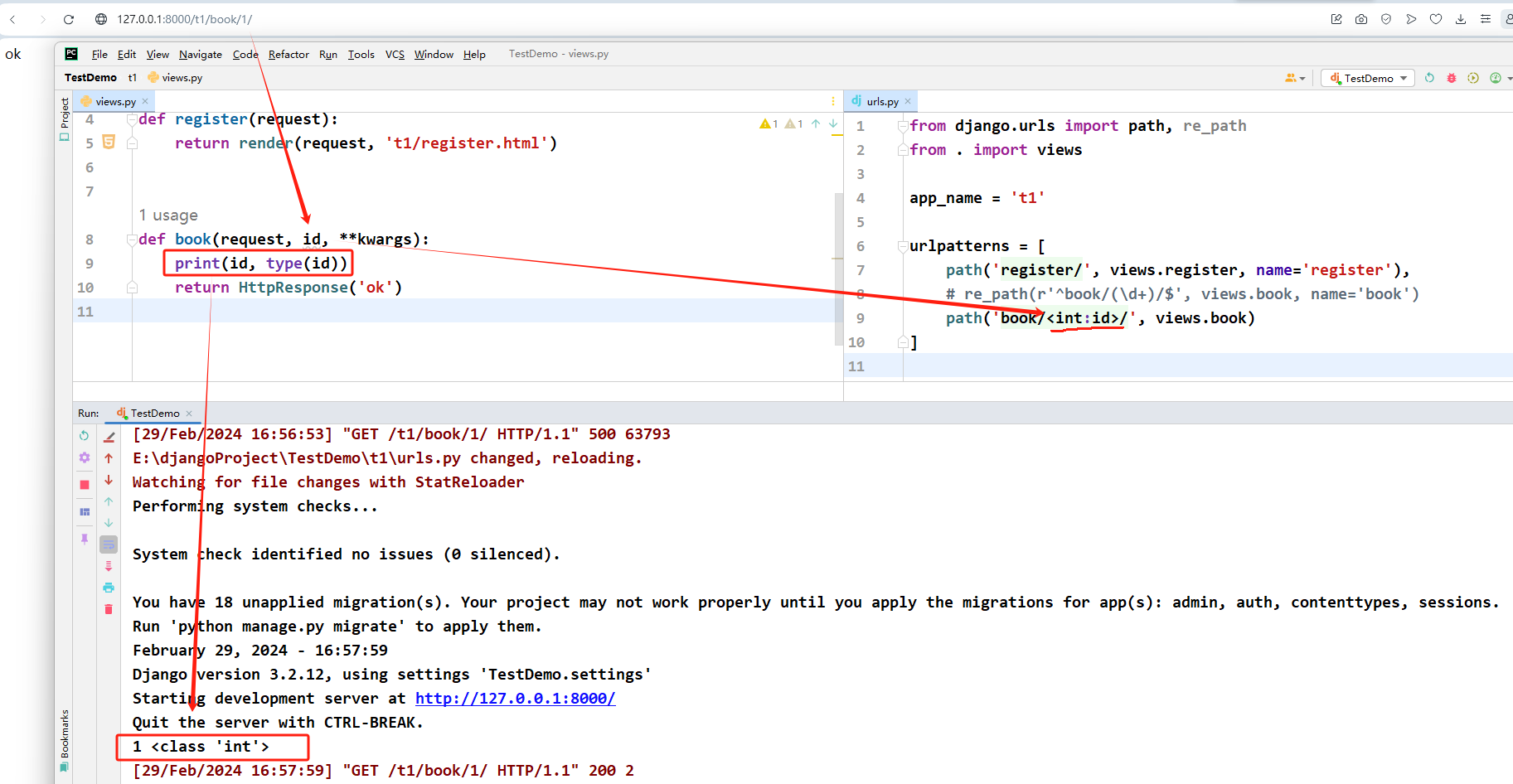
路径转换器
虽然path不支持正则,但是其内部支持五种转换器
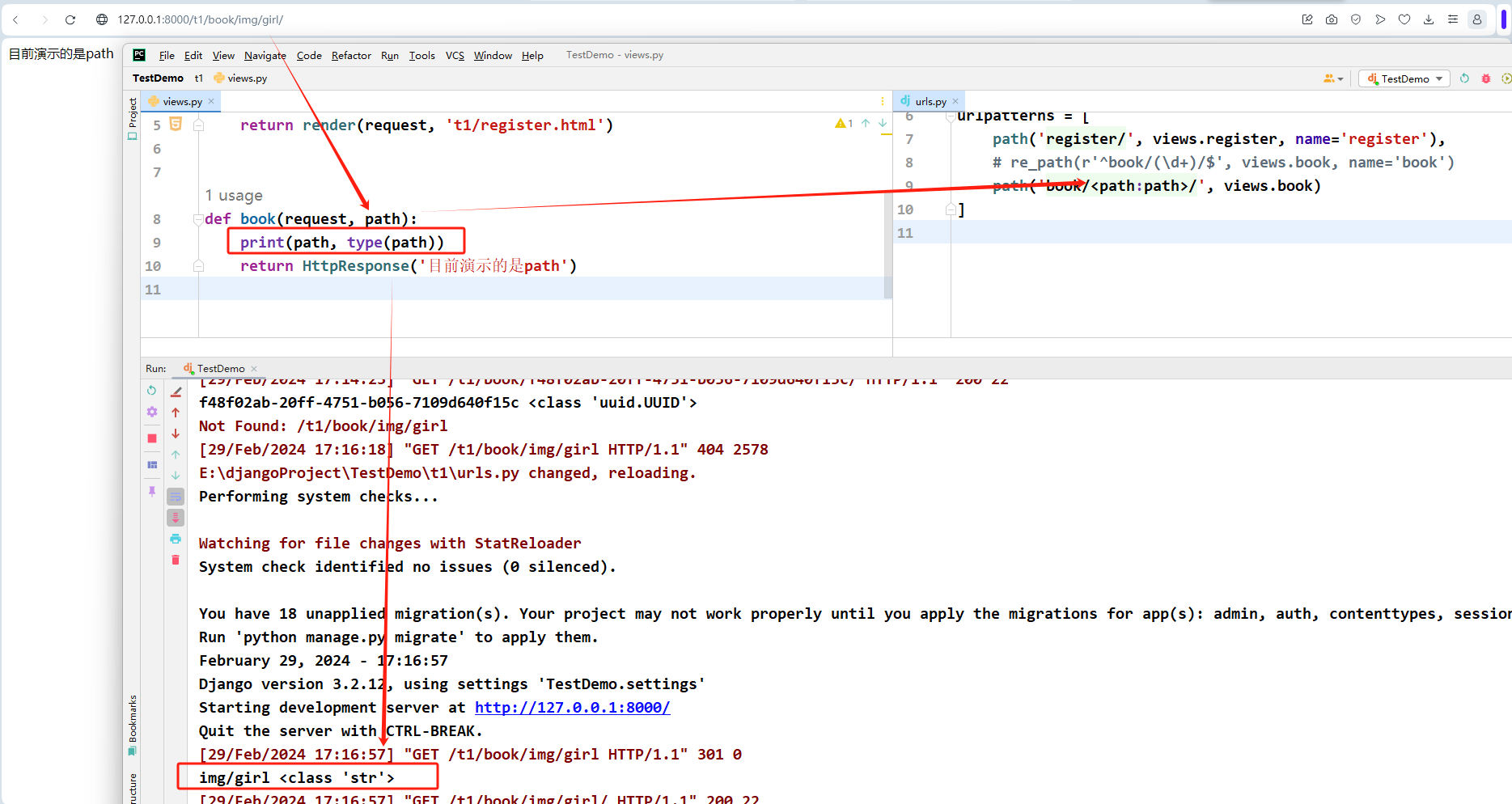
path('book/<int:id>/',views.book)
# 将第二个路由里面的内容先转成整型,然后以关键字的形式传递给后面的视图函数
五种转换器
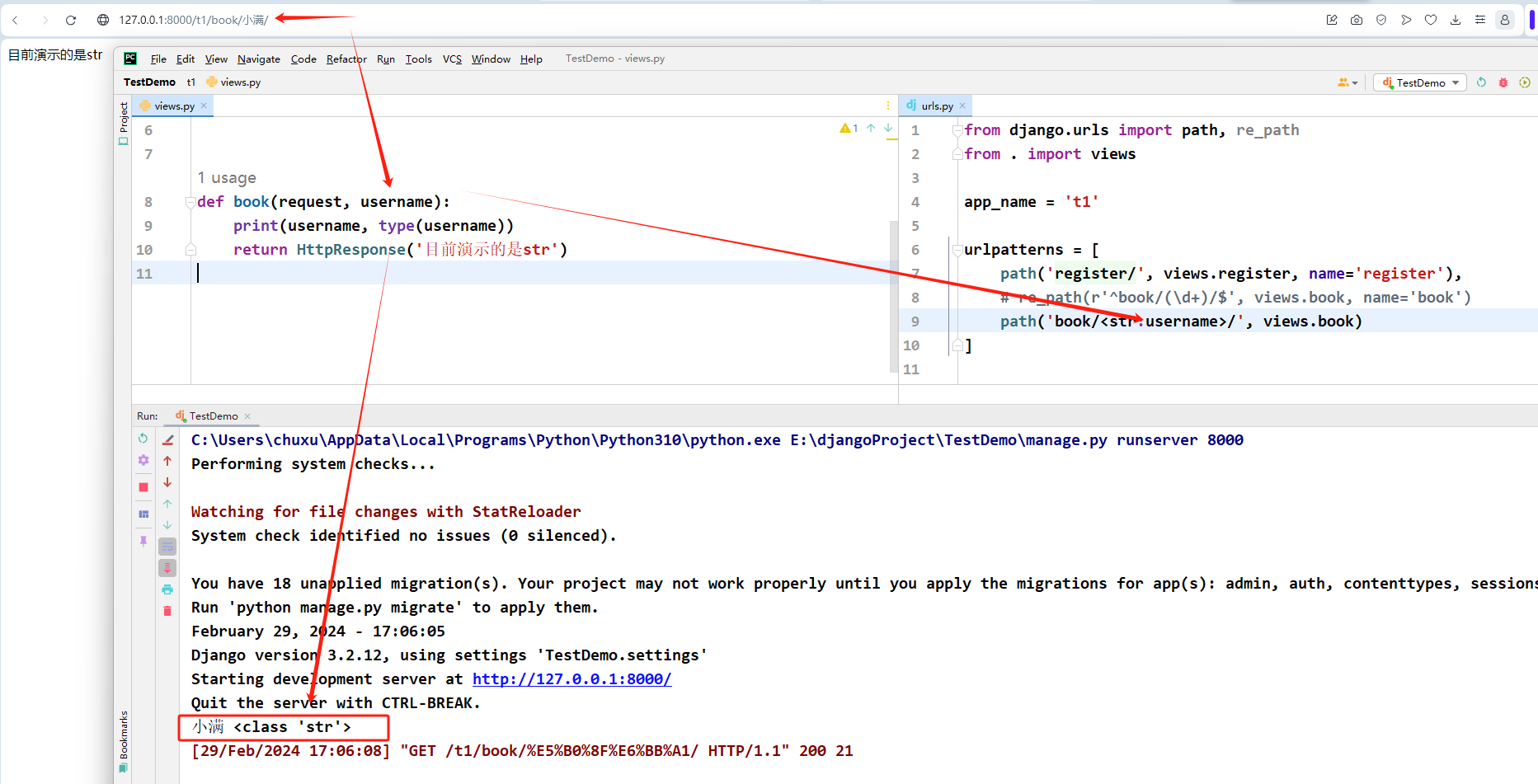
str
匹配除了 '/' 之外的非空字符串,如果表达式内不包含转换器,则会默认匹配字符串。
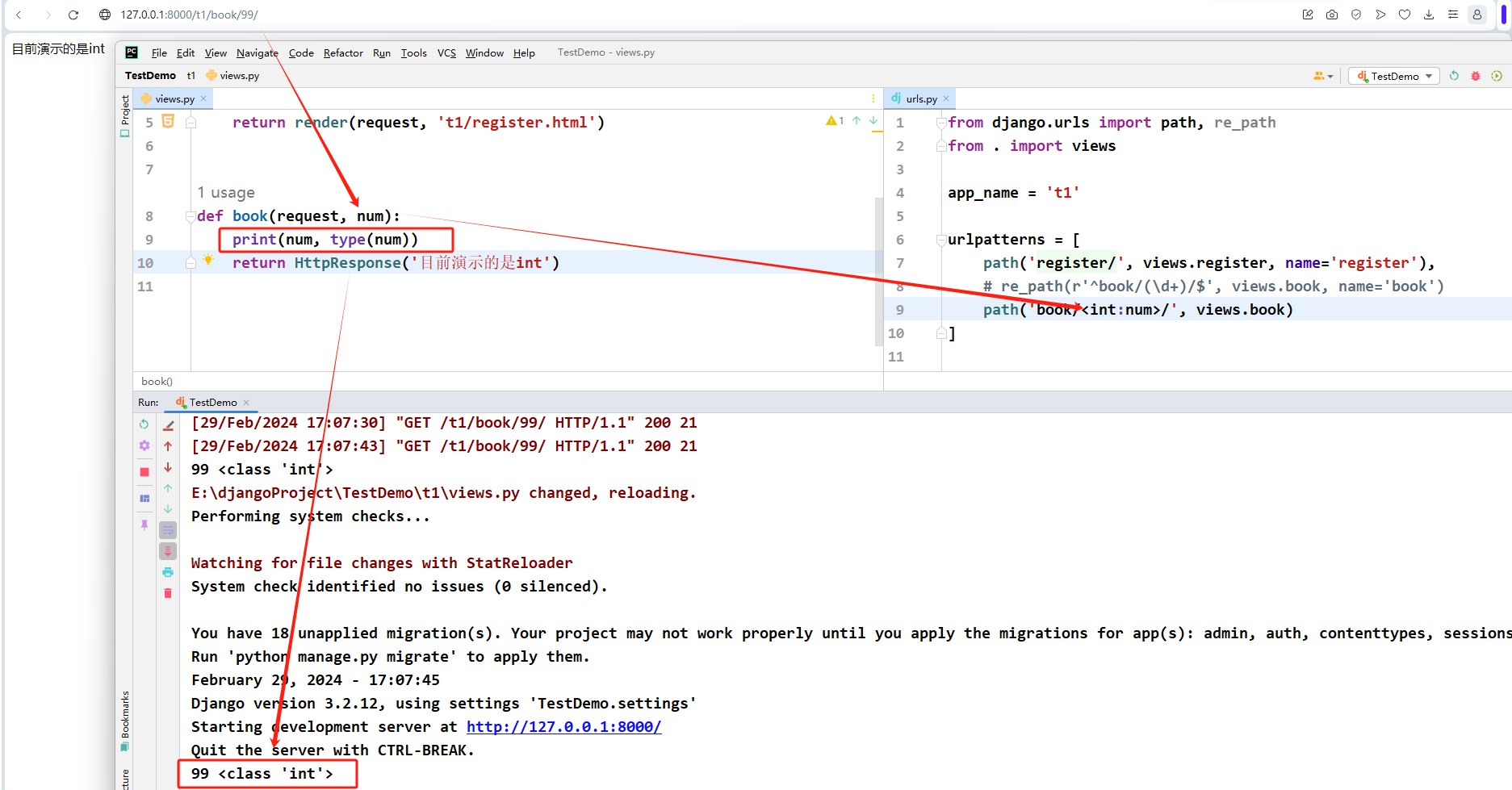
int
匹配 0 或任何正整数。返回一个 int 。
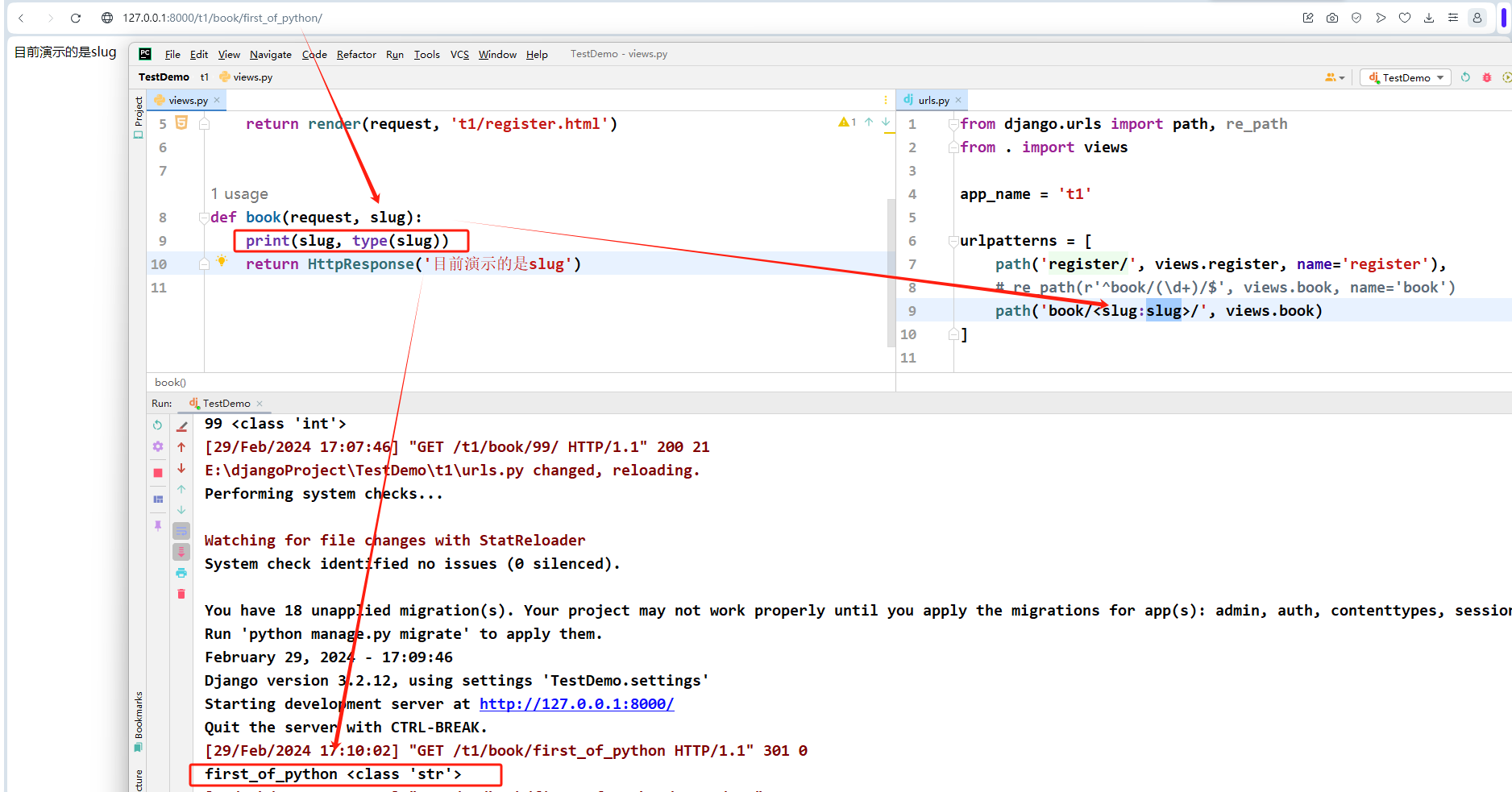
slug
匹配任意由 ASCII 字母或数字以及连字符和下划线组成的短标签。比如,building-your-1st-django-site 。
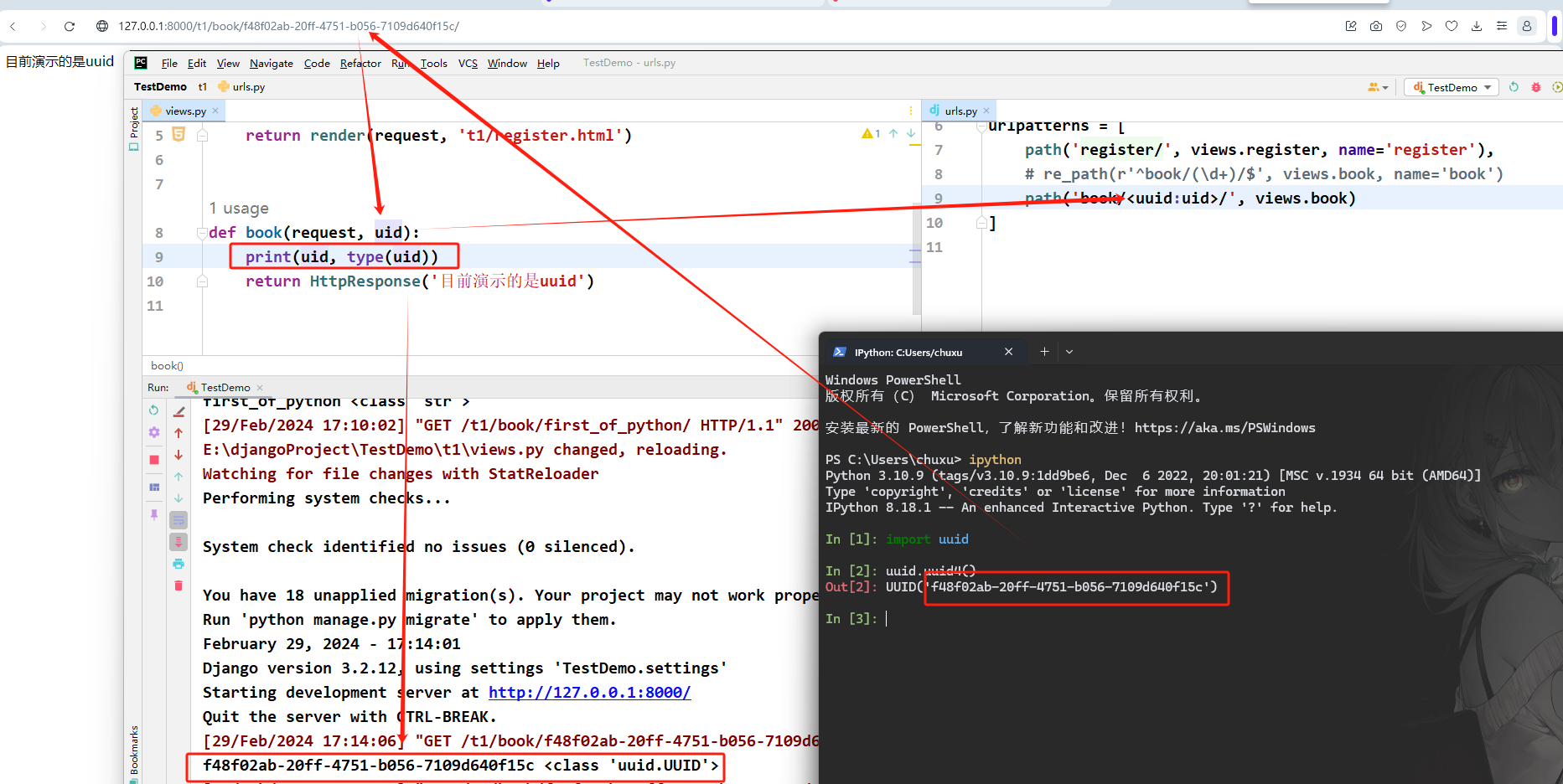
uuid
匹配一个格式化的 UUID 。为了防止多个 URL 映射到同一个页面,必须包含破折号并且字符都为小写。
比如,075194d3-6885-417e-a8a8-6c931e272f00。返回一个 UUID 实例。
path
匹配非空字段,包括路径分隔符 '/' 。它允许你匹配完整的 URL 路径而不是像 str 那样匹配 URL 的一部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号