重新认识python
 人生就像一盒巧克力,你永远不知道会尝到哪种滋味。
人生就像一盒巧克力,你永远不知道会尝到哪种滋味。
写在前面
Beautiful is better than ugly.
Simple is better than complex.
什么是NB的代码,新手小白都能很直观看懂的代码(建议)
学习建议
- 建议先学基础(任何语言),先入门
- 再去学高级阶段(项目阶段)
- 注重面试能力(口头表达能力、文档书写能力)
- 遇到问题如何解决?
- 1-5分钟之内的问题自己解决(笔记、视频回放等)
- 5-20分钟借助一些搜索引擎(百度、谷歌等)
- 20分钟还没解决,就要问老师等
怎样算学好
学一门编程语言,要学到怎样才算是熟练了呢?就是当你看到一个东西,想到一个需求,无论什么需求,就能在脑海将其怎么实现这个需求的大概思路整理出来,做到这一步,就差不多了
编程思维
分解:把一个复杂的大问题,拆解成更可执行、更好理解的小步骤。
模式识别:找出相似模式,高效解决细分问题。
抽象:聚焦最重要的信息,忽视无用细节。
算法:设计一步一步的解决路径,解决整个问题。
关于中括号[]
计算机行业,描述语法格式时,使用中括号
[]表示可选,非必选。
反斜杠\连接
content = "你懂的越多" \
"你就越像这个世界的孤儿"
print(content) # 你懂的越多你就越像这个世界的孤儿
下划线分组
在书写很大的数时,可使用下划线将其中的位分组,使其更清晰易读:
当你打印这种使用下划线定义的数字时,Python 不会打印其中的下划线,这种表示法既适用于整数,也适用于浮点数。
In [1]: universe_age = 14_000_000_000
In [2]: print(universe_age)
14000000000
终端打印彩色文本
print("\033[indexm内容\033[0m")
# 把index换成对应效果的数字就可以了

color_list = [9, 21, 30, 31, 32, 33, 34, 35, 36, 37, 40, 41, 42, 43, 44, 45, 46, 47, 51, 60, 91, 92, 93, 94, 95, 96, 97]
for index, item in enumerate(color_list, 1):
print(f"\033[{item}m欢迎来到小满的博客\033[0m", end='\t')
if index % 5 == 0:
print()

打印文件要以运行的文件开始算,导入模块要以当前的模块开始算
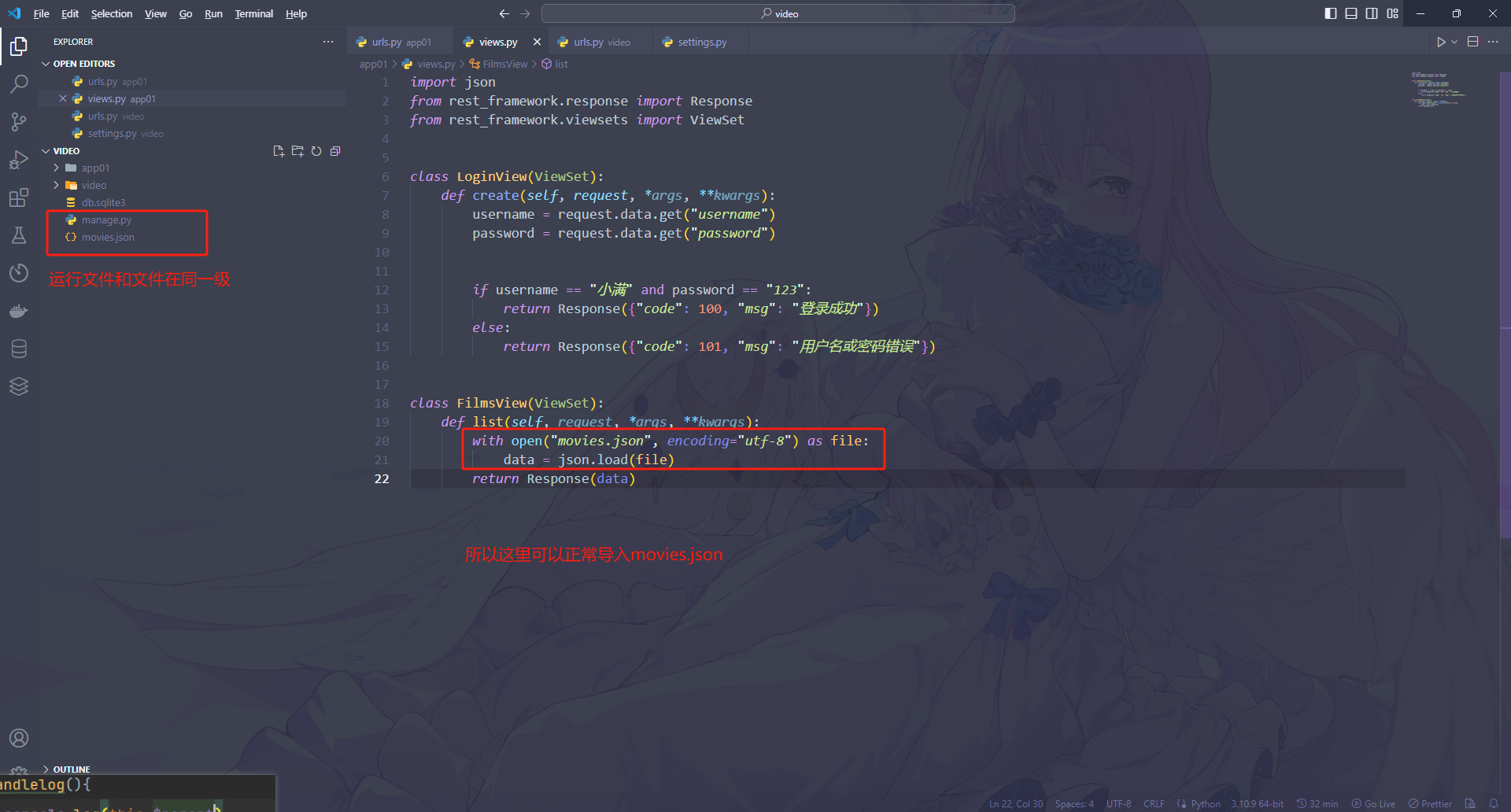
对象
标识id 类型type 值value
变量放在栈区里面,对象位于堆里面
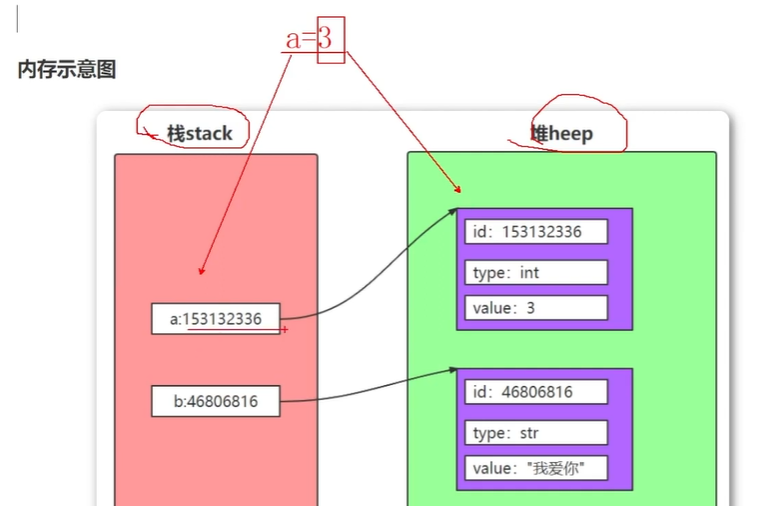
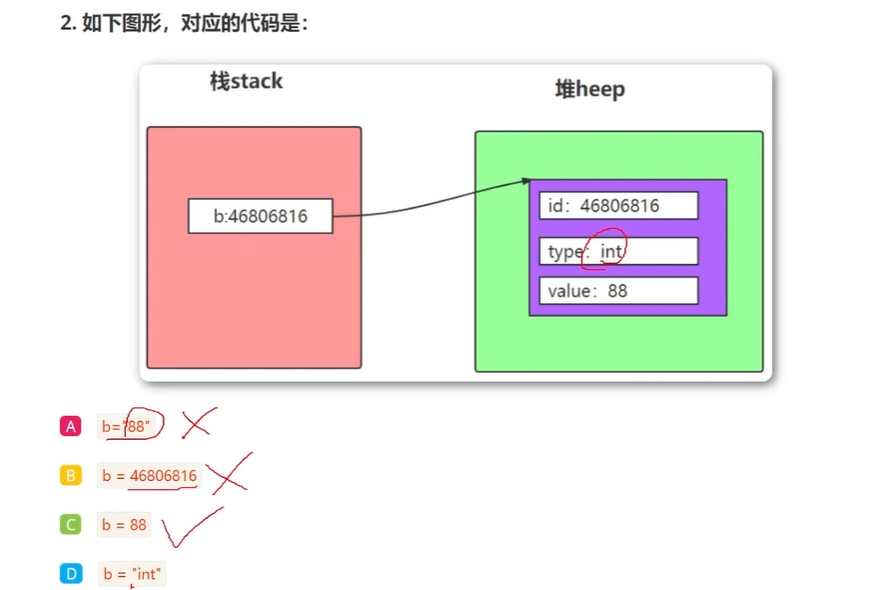
引用
在python中一切皆对象
变量也称为对象的引用,存储的是对象的地址,变量通过地址引用了对象。
python是动态类型的语言,变量不需要显式声明类型, 根据变量引用对象,python解释器会自动确定数据类型。
变量没有类型,对象有类型
垃圾回收机制
比如去饭店吃饭,饭店里面有四个桌子,如果一个桌子已经吃完了,服务员就会清理吃掉的垃圾,然后剩下的客人才可以继续用餐。
函数执行时间 timeit
# 导入必要的模块
from timeit import timeit
items = []
def foo():
for index in range(100_000_000):
items.append(index)
# 测量 foo 函数执行时间
execution_time = timeit(foo, number=1) # number=1 表示执行一次 foo 函数
print("执行 foo 函数所花费的时间:", execution_time, "秒")
短板补齐 zip_longest
我们知道,如果传入的多个可迭代对的长度不相等,则取最短的进行对应,这类似于木桶效应的短板现象,如果想按最长的处理,不足的用 None 补足补齐,可以使用 itertools 中的 zip_longest 方法:
from itertools import zip_longest
# 两个可迭代对象
a = [1, 2, 3, 4]
b = ['a', 'b', 'c']
# 使用 zip_longest 打包成元组
result = list(zip_longest(a, b))
print(result)
# 输出:[(1, 'a'), (2, 'b'), (3, 'c'), (4, None)]
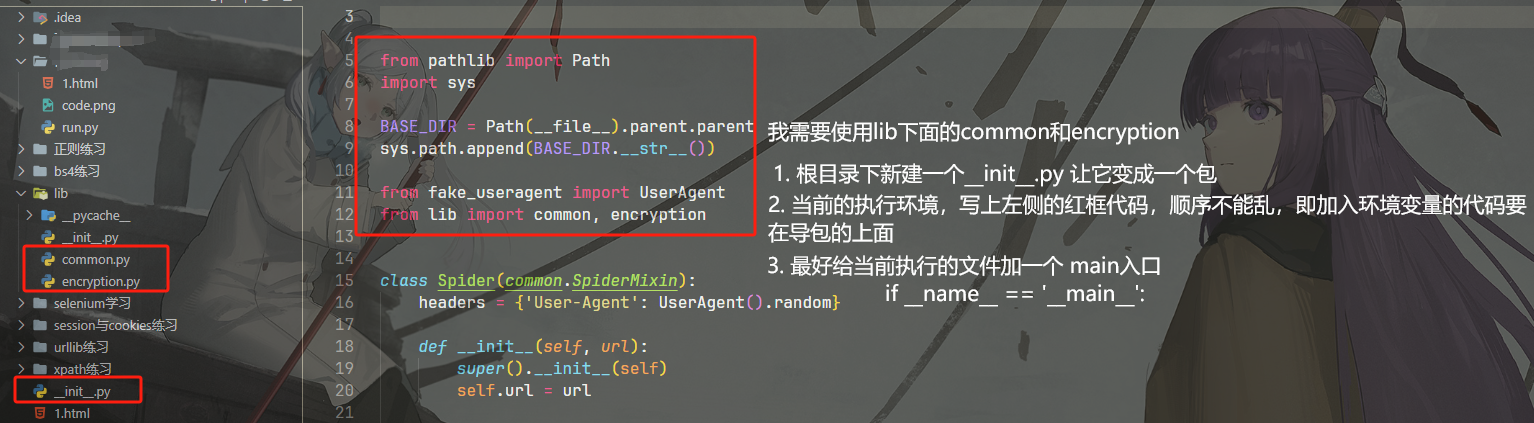
关于导包
前景:在使用pycharm的时候,能够正确识别到是哪一个包,可以正常导入,但是使用vscode的时候,无法识别到包
exit()
exit()函数用于退出Python程序的执行。当调用exit()时,程序会立即终止执行,并返回到程序的调用者,可以将其视为强制终止程序执行的命令。在上述代码中,当index等于3时,程序会立即退出,因此后续的循环不会被执行。
# 循环遍历范围在0到9之间的数字
for index in range(10):
# 如果当前数字等于3
if index == 3:
# 使用exit()函数退出程序
exit()
# 打印当前数字
print(index)
小心+=和=陷进
# +=不会重新定义变量,而=会重新定义变量。 也就是说,+=是对变量进行追加,而=是重新定义变量。
def foo(a_list):
a_list += [4, 5] #⚠️ 改变了传入的参数,不是局部变量。
def bar(a_list):
a_list = a_list + [4, 5] #⚠️ 重新定义了传入的参数,是局部变量。
my_list = [1, 2, 3]
print(f'foo函数执行前: my_list = {my_list}')
foo(my_list)
print(f'foo函数执行后: my_list = {my_list}')
my_list = [1, 2, 3]
print(f'bar函数执行前: my_list = {my_list}')
bar(my_list)
print(f'bar函数执行后: my_list = {my_list}')
"""
foo函数执行前: my_list = [1, 2, 3]
foo函数执行后: my_list = [1, 2, 3, 4, 5]
bar函数执行前: my_list = [1, 2, 3]
bar函数执行后: my_list = [1, 2, 3]
"""
python内置的服务器开启
python -m http.server port
# port指的是端口 默认是8000 开启服务器后局域网可以共享
# 即通过0.0.0.0:port 访问
python -m http.server 8000
# 可以通过127.0.0.1:8000 访问
# 可以通过localhost:8000 访问
# 在同一个局域网的另外一台电脑可以通过 0.0.0.0:8000 访问
eval(慎用)
eval会将字符串当做表达式来执行,会有安全隐患。
In [10]: a = 10
In [11]: b = 20
In [12]: dict1 = dict(a=100, b=200)
In [13]: eval("a+b")
Out[13]: 30
In [14]: eval("a+b", dict1)
Out[14]: 300
__getattr__ 定义一个类,继承字典,实现通过 . 取值
当 实例 . 取值的时候获取不到,就会进入到
__getattr__
class MyDict(dict):
def __getattr__(self, item):
return self.get(item)
my_dict = MyDict(name="小满", age=3, hobby="摸鱼")
print(my_dict.name) # 小满
print(my_dict.hobby) # 摸鱼
print(my_dict.gender) # None 不存在的key
__getitem__ 定义一个类,不继承字典,实现通过 [ ] 和 . 取值
当实例 [ ] 取值的时候,取不到,就会进入到
__getitem__
class MyDict:
def __init__(self, data):
self.data = data
def __getattr__(self, item):
return self.data.get(item, None)
def __getitem__(self, item):
return self.data.get(item, None)
my_dict = MyDict(dict(name="小满", age=3, hobby="摸鱼"))
print(my_dict.name) # 小满
print(my_dict.age) # 3
print(my_dict['hobby']) # 摸鱼
print(my_dict['gender']) # None 不会报错 因为在 __getitem__ 中处理了
变量命名
1. 描述性强
# 描述性弱的名字:看不懂在做什么
value = process(s.strip())
# 描述性强的名字:尝试从用户输入里解析出一个用户名
username = extract_username(input_string.strip())
2. 遵循PEP8原则
3. 尽量简短
4. 要匹配类型
布尔值(bool)是一种很简单的类型,它只有两个可能的值:“是(True)”或“不是(False)”。因此,给布尔值变量起名有一个原则:一定要让读到变量的人觉得它只会有“肯定”和“否定”两种可能。举例来说,is、has 这些非黑即白的词就很适合用来修饰这类名字。
下面的表内有一些更详细的例子:
| 变量名 | 含义 | 说明 |
|---|---|---|
is_superuser |
是否是超级用户 | 是 / 不是 |
has_errors |
有没有错误 | 有 / 没有 |
allow_empty |
是否允许空值 | 允许 / 不允许 |
nullable |
是否可以为 null | 可以 / 不可以 |
匹配 int/float 类型的名字
当人们看到和数字有关的名字时,自然就会认定它们是 int 或 float 类型。这些名字可被简单分为以下几种常见类型:
- 释义为数字的所有单词,比如:
port(端口号)、age(年龄)、radius(半径)等 - 使用
_id结尾的单词,比如:user_id、host_id - 使用
length/count开头或者结尾的单词,比如:length_of_username、max_length、users_count
最好别拿一个名词的复数形式来作为
int类型的变量名,比如apples、trips等。因为这类名字,会和那些装着Apple和Trip的普通容器对象(List[Apple]、List[Trip])相混淆。为了避免混淆,我建议用number_of_apples或trips_count这种复合词来作为int类型的名字。
5. 超短命名
在众多变量名里,有一类名字非常特别,那就是只有一两个字母的短名字。这些短名字一般可分为两类,第一类是那些大家约定俗成的短名字,比如:
- 数组索引三剑客
i、j、k - 某个整数
n - 某个字符串
s - 某个异常
e - 文件对象
fp
我并不反对使用这类短名字,自己也经常用,因为它们写起来的确很方便。但如果条件允许,我还是建议尽量用更精确的名字替代它们。比如,在表示用户输入的字符串时,用 input_str 替代 s 总是会更明确一些。
另一类短名字,则是对一些其他常用名的缩写。比如,在使用 Django 框架做国际化内容翻译时,常常会用到 gettext 方法。为了方便,我们常会把 gettext 缩写成 _ 来使用:
from django.utils.translation import gettext as _
print(_('待翻译文字'))
如果你在项目中发现有一些长名字会重复出现,那你也可以效仿上面的方式,为这些长名字设置一些短名字作为别名。这样可以让代码变得更紧凑,更好读。但同一个项目内的超短缩写不宜太多,否则效果就会适得其反。
命名其它技巧
- 在同一段代码内,不要出现多个相似的变量名,比如同时使用
users、users1、users3这种序列 - 你可以尝试用换词来简化复合变量名,比如用
is_special来代替is_not_normal - 如果你苦思冥想都想不出一个合适的名字,请打开
GitHub,到其他人的开源项目里找找灵感吧。
定义临时变量提升可读性
随着业务逻辑变得复杂,我们的代码里也会经常出现一些复杂的表达式,就像下面这样:
# 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
if user.is_active and (user.sex == 'female' or user.level > 3):
user.add_coins(10000)
return
看见 if 后面那一长串了吗?有点难读对不对?但这也没办法,毕竟产品经理就是明明白白这么跟我说的——业务逻辑如此。
但逻辑虽然如此,不代表我们就得把代码直白地写成这样。如果把后面的复杂表达式赋值为一个临时变量,代码可以变得更好读:
# 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
user_is_eligible = user.is_active and (user.sex == 'female' or user.level > 3):
if user_is_eligible:
user.add_coins(10000)
return
在新代码里,“计算用户合规的表达式”和“判断合规发送金币的条件分支”这两段代码不再直接被杂糅在了一起,而是有了一个可读性强的变量 user_is_elegible 作为缓冲。不论是代码的可读性还是可维护性,都因为这个变量而变得更好了。
不要使用 locals()
locals() 是 Python 的一个内置函数,调用它会返回当前作用域中的所有局部变量。
def foo():
name = 'piglei'
bar = 1
print(locals())
# 调用 foo() 将输出:
{'name': 'piglei', 'bar': 1}
使用“德摩根定律”
在做分支判断时,我们有时候会写成这样的代码:
# 如果用户没有登录或者用户没有使用 chrome,拒绝提供服务
if not user.has_logged_in or not user.is_from_chrome:
return "our service is only available for chrome logged in user"
第一眼看到代码时,是不是需要思考一会才能理解它想干嘛?这是因为上面的逻辑表达式里面出现了 2 个 not 和 1 个 or。而我们人类恰好不擅长处理过多的“否定”以及“或”这种逻辑关系。
这个时候,就该 德摩根定律 出场了。通俗的说,德摩根定律就是 not A or not B 等价于 not (A and B)。通过这样的转换,上面的代码可以改写成这样:
if not (user.has_logged_in and user.is_from_chrome):
return "our service is only available for chrome logged in user"
怎么样,代码是不是易读了很多?记住德摩根定律,很多时候它对于简化条件分支里的代码逻辑非常有用。
同时赋值给多个变量
同时给多个变量赋值可在一行代码中给多个变量赋值,这有助于缩短程序并提高其可读性。这种做法最常用于将一系列数赋给一组变量。例如,下面演示了如何将变量 x、y 和 z 都初始化为零:
x, y, z = 0, 0, 0
# 或者
x = y = z = 0
# 注意,此方法不建议可变数据类型,比如列表
x = y = z = [] # 这样是不推荐的
变量解包
“变量解包(unpacking)”是 Python 里的一种特殊赋值操作。它允许你把一个可迭代对象(比如列表)的所有成员,一次性赋值给多个变量:
>>> usernames = ['piglei', 'raymond']
# 注意:左侧变量个数必须和待展开的列表长度相等,否则会报错
>>> author, reader = usernames
>>> author
'piglei'
假如在赋值语句左侧添加小括号 (…),你甚至可以一次展开多层嵌套数据:
>>> attrs = [1, ['piglei', 100]]
>>> user_id, (username, score) = attrs
>>> user_id
1
>>> username
'piglei'
除了上面的普通解包外,Python 还支持更灵活的动态解包语法。只要用星号表达式(*variables)作为变量名,它便会贪婪地捕获多个值对象,并将捕获到的内容作为列表赋值给 variables。
比如,下面 data 列表里的数据就分为三段:头为用户,尾为分数,中间的都是水果名称。通过把 *fruits 设置为中间的解包变量,我们就能一次性解包所有变量——fruits 会捕获 data 去头去尾后的所有成员:
>>> data = ['piglei', 'apple', 'orange', 'banana', 100]
>>> username, *fruits, score = data
>>> username
'piglei'
>>> fruits
['apple', 'orange', 'banana']
>>> score
100
和常规的切片赋值语句比起来,动态解包语法要直观许多:
# 1. 动态解包
>>> username, *fruits, score = data
# 2. 切片赋值
>>> username, fruits, score = data[0], data[1:-1], data[-1]
# 两种变量赋值方式完全等价
面的变量解包操作,也可以在任何循环语句里使用:
>>> for username, score in (['piglei', 100], ['raymond', 60]):
... print(username)
...
piglei
raymond
在人们常用的诸多变量名中,单下划线 _ 是比较特殊的一个。它常作为一个无意义的占位符出现在赋值语句中。_ 这个名字本身没啥特别之处,这么用算是大家的一种约定俗成。
举个例子,假如你想在解包赋值时忽略某些变量,你就可以使用 _ 作为变量名:
# 忽略展开时的第二个变量
>>> author, _ = usernames
# 忽略第一个和最后一个变量之间的所有变量
>>> username, *_, score = data
科学计数法
3.14e2 代表3.14 * 10的2次方
314e-2 代表314 * 10的-2次方
e的大小写均可
整数
python中的整数是无穷大的
In [13]: pow(9, 1000)
Out[13]: 1747871251722651609659974619164660570529062487435188517811888011810686266227275489291486469864681111075608950696145276588771368435875508647514414202093638481872912380089977179381529628478320523519319142681504424059410890214500500647813935818925701905402605484098137956979368551025825239411318643997916523677044769662628646406540335627975329619264245079750470862462474091105444437355302146151475348090755330153269067933091699479889089824650841795567478606396975664557143737657027080403239977757865296846740093712377915770536094223688049108023244139183027962484411078464439516845227961935221269814753416782576455507316073751985374046064592546796043150737808314501684679758056905948759246368644416151863138085276603595816410945157599742077617618911601185155602080771746785959359879490191933389965271275403127925432247963269675912646103156343954375442792688936047041533537523137941310690833949767764290081333900380310406154723157882112449991673819054110440001
时间戳
1970年1月1日
00:00:00秒开始到现在的时间,1毫秒等于1/1000秒,也就是1000毫秒等于1秒
import time
now = time.time()
now = int(now)
now_minute = now // 60
now_day = now_minute // (24 * 60)
now_year = now_day // 365
print(now_minute, now_day, now_year)
# 28475254 19774 54
短路运算
下面的结果不会报错,会打印
False
print(10 > 20 and 3 / 0) # False
同一运算符
is和==,==的本质就是调用了__eq__()的这个方法,is比较的是内存地址是否一样,==比较的值是否一样
整数的缓存机制
在命令行模式下,python仅仅对比较小的整数进行缓存,缓存范围是
[-5到256]在文件模式下,所有的数字都会被缓存,缓存到缓存到链表中,不会被连续缓存,用到去缓存链表去先去查找
# 命令行模式下
In [17]: a = 256
In [18]: b = 256
In [19]: a is b
Out[19]: True
In [20]: a = 257
In [21]: b = 257
In [22]: a is b
Out[22]: False
# 文件模式下,即通过IDE运行
a = 256
b = 256
print(a is b) # True
a = 257
b = 257
print(a is b) # True
字符串的编码和解码
如果在 Python 中调用 encode() 和 decode() 方法时不指定参数,默认使用的编码格式是 UTF-8
关于字符串的切片
如果指定了开始位置和结束位置,没有指定步长,步长值大于字符串长度,也不会发生报错,而是从步长开始一直到字符串结束
In [23]: content = "你是年少的欢喜"
In [24]: content[2:100]
Out[24]: '年少的欢喜'
字符串的startswith和endswith
你可能已经使用过
startswith和endswith方法来搜索字符串中的前缀或者后缀。 但是你不一定知道他们可以使用多个条件。
string1 = 'abc.xls'
# method 1
if string1.endswith('.xls') or string1.endswith('.xlsx'):
print('Yes')
# method 2
if string1.endswith(('.xls','.xlsx')):
print('Yes')
字符串新增removeprefix和removesuffix方法
In [8]: content = "你是年少的欢喜"
In [9]: content.removeprefix("你")
Out[9]: '是年少的欢喜'
In [10]: content
Out[10]: '你是年少的欢喜'
In [11]: content.removesuffix("的欢喜")
Out[11]: '你是年少'
In [12]: content
Out[12]: '你是年少的欢喜'
字符串+的效率问题
当使用字符串
+时候,会生成新的对象,效率会明显比字符串的join方法慢很多,join函数仅新建一次对象。如果有能用join方法的场景,尽量使用join总结:
循环的时候一定要使用join
import time
from functools import wraps
def timer(func):
@wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} 运行时间:{end_time - start_time} 秒")
return result
return wrapper
@timer
def func1():
text = ""
for index in range(100_0000):
text += "小满"
@timer
def func2():
name_list = ["小满" for _ in range(100_0000)]
text = "".join(name_list)
if __name__ == "__main__":
func1()
func2()
# func1 运行时间:0.6730570793151855 秒
# func2 运行时间:0.06065797805786133 秒
字符串的滞留机制
只保留一份
# 中文情况下
In [25]: t1 = "你是年少的欢喜"
In [26]: t2 = "你是年少的欢喜"
In [27]: t1 is t2
Out[27]: False
In [28]: t1 == t2
Out[28]: True
# 英文情况下
In [29]: t3 = "aabbcc"
In [30]: t4 = "aabbcc"
In [31]: t3 is t4
Out[31]: True
In [32]: t3 == t4
Out[32]: True
可变字符串,通过io模块
- 在python中,字符串属于不可变对象,不支持原地修改,如果要修改其中的值,只能创建新的字符串对象
- 确定需要原地修改字符串,可以使用
io.StringIO对象或array模块
如果直接修改会报错
text = "你是年少的欢喜"
text[0] = "他"
print(text) # TypeError: 'str' object does not support item assignment
通过io模块去修改
import io
text = "你是年少的欢喜"
f = io.StringIO(text) # 这个f就是可变字符串
f.seek(0) # 指针位置移动
f.write("他") # 替换的新值
new_text = f.getvalue() # 得到值
print(new_text) # 他是年少的欢喜
序列
序列是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个连续值的连续的内存空间。
- 列表
- 元组
- 字典
- 集合
- 字符串
基本上写python,每一天都会碰到序列,离不开序列。
列表添加元素的5种方式
append()
extend()
insert()上面这几种都不会生成新的对象
+尾部添加生成新列表
*乘法扩展,生成新列表这两种方法会生成新的对象
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个热点涉及列表元素的大量移动,效率较低。
除非必要,我们一般只在列表尾部添加元素或删除元素,这会大大提高列表的操作效率
列表的删除remove问题
只会删除第一个,不会删除全部
name_list = ['大乔', '小满', '大乔', '小满', '小乔', '阿珂', '小满', '海月']
name_list.remove('小满')
print(name_list)
# ['大乔', '大乔', '小满', '小乔', '阿珂', '小满', '海月']
如果要全部删除列表中的指定元素,可以遍历去删除
name_list = ['大乔', '小满', '大乔', '小满', '小乔', '阿珂', '小满', '海月']
name_list.remove('小满')
for name in name_list:
if name == '小满':
name_list.remove(name)
else:
print(name_list)
# ['大乔', '大乔', '小乔', '阿珂', '海月']
reversed得到的是一个迭代器
In [1]: nameList = ['小满', '大乔', '庄周', '阿珂']
In [2]: new_name_list = reversed(nameList)
In [3]: new_name_list
Out[3]: <list_reverseiterator at 0x23efb335d50>
In [4]: for index in new_name_list:
...: print(index)
...:
阿珂
庄周
大乔
小满
快速生成一个数字列表
In [3]: numbers = list(map(int, input().split()))
23 2 -23 11 89 102
In [4]: numbers
Out[4]: [23, 2, -23, 11, 89, 102]
生成器生成式只能遍历一次
注意,这个不是元组生成式
In [9]: num_iter = (x*3 for x in range(5))
In [10]: num_iter
Out[10]: <generator object <genexpr> at 0x0000023EFC5ECC10>
In [11]: for item in num_iter:
...: print(item)
...:
0
3
6
9
12
In [12]: for item in num_iter:
...: print(item)
...:
In [13]:
当要变量多个列表的时候
尝试使用索引去取值,而不是使用拉锁函数zip,因为实际的情况可能会更多。
In [14]: name_list
Out[14]: ['孙红梅', '蔡佳', '孔凤英', '韩凤兰', '李帅', '唐阳', '梁雪', '许玲', '詹凤兰', '杨桂香']
In [15]: age_list
Out[15]: [19, 22, 19, 33, 24, 25, 17, 25, 18, 30]
In [17]: score_list
Out[17]: [119, 112, 120, 122, 92, 97, 116, 108, 89, 107]
In [18]: join_list
Out[18]:
['40128人参与',
'51320人参与',
'51164人参与',
'47759人参与',
'41777人参与',
'45215人参与',
'52318人参与',
'58778人参与',
'61914人参与',
'38455人参与']
In [19]: for name, age, score, join in zip(name_list, age_list, score_list, join_list):
...: print(name, age, score, join)
...:
孙红梅 19 119 40128人参与
蔡佳 22 112 51320人参与
孔凤英 19 120 51164人参与
韩凤兰 33 122 47759人参与
李帅 24 92 41777人参与
唐阳 25 97 45215人参与
梁雪 17 116 52318人参与
许玲 25 108 58778人参与
詹凤兰 18 89 61914人参与
杨桂香 30 107 38455人参与
In [20]: for index in range(len(name_list)):
...: name = name_list[index]
...: age = age_list[index]
...: score = score_list[index]
...: join = join_list[index]
...: print(name, age, score, join)
...:
孙红梅 19 119 40128人参与
蔡佳 22 112 51320人参与
孔凤英 19 120 51164人参与
韩凤兰 33 122 47759人参与
李帅 24 92 41777人参与
唐阳 25 97 45215人参与
梁雪 17 116 52318人参与
许玲 25 108 58778人参与
詹凤兰 18 89 61914人参与
杨桂香 30 107 38455人参与
文件写入的时候,多用.join()方法
user_dict = {'username': 'eva', 'password': '22', 'balance': '1000'}
data = "|".join(user_dict.values())
print(data) # eva|22|1000
批量递归移动文件glob
recursive=True是glob.glob()方法的一个参数,用于指定是否递归地搜索子目录。当设置为True时,glob.glob()将会搜索指定目录及其所有子目录中匹配模式的文件。
import os
import shutil
import glob
import time
BASE_DIR = r'E:头像下载\头像结果'
to_dirs = r"E:头像下载\全部头像"
os.chdir(BASE_DIR)
t1 = time.time()
all_img_files = glob.glob("*/*.*", recursive=True)
for img in all_img_files:
path = os.path.join(BASE_DIR, img)
shutil.move(img, to_dirs)
else:
t2 = time.time()
print(f'全部文件移动完毕,耗时:{t1-t1:.2f}秒')
线程池的简单使用
if __name__ == '__main__':
# 使用线程池执行HTTP请求
with ThreadPoolExecutor(max_workers=10) as t:
futures = [t.submit(get_request, url) for url in url_list]
# 处理每个页面的响应内容
for future in futures:
future.add_done_callback(fetch_content)
线程池加锁
import concurrent.futures
import threading
# 定义共享资源
shared_resource = 0
# 创建互斥锁
lock = threading.Lock()
# 定义一个任务函数,用来更新共享资源
def update_shared_resource():
global shared_resource
# 在访问共享资源之前加锁
with lock:
shared_resource += 1
print(f"Updated shared resource: {shared_resource}")
# 在访问完成后解锁
# 初始化线程池
with concurrent.futures.ThreadPoolExecutor() as executor:
# 提交多个任务到线程池中
tasks = [executor.submit(update_shared_resource) for _ in range(10)]
# 等待所有任务完成
for task in concurrent.futures.as_completed(tasks):
task.result()
关于字典解包
In [22]: name_dict = dict(name="小满", age=3, hobby="摸鱼")
In [23]: name, age, hobby = name_dict
In [24]: name
Out[24]: 'name'
In [25]: age
Out[25]: 'age'
In [26]: hobby
Out[26]: 'hobby'
In [27]: name, age, hobby = name_dict.values()
In [28]: name
Out[28]: '小满'
In [29]: age
Out[29]: 3
In [30]: hobby
Out[30]: '摸鱼'
In [14]: items = {'真人女头ins清冷破碎感 很精致的女头大全': 'https://www.qqtn.com//article/article_340926_1.html'}
In [15]: k, v = next(iter(items.items()))
In [16]: k
Out[16]: '真人女头ins清冷破碎感 很精致的女头大全'
In [17]: v
Out[17]: 'https://www.qqtn.com//article/article_340926_1.html'
合并字典
d1 = {'name': '小满', 'age': 3}
d2 = {"hobby": ['摸鱼', '抢人头']}
d3 = {'teacher': '老夫子'}
d4 = {**d1, **d2, **d3}
print(d4) # {'name': '小满', 'age': 3, 'hobby': ['摸鱼', '抢人头'], 'teacher': '老夫子'}
用字典统计次数
numList = [1, 2, 2, 3, 3]
num_dict = {}
for num in numList:
num_dict[num] = num_dict.get(num, 0) + 1
print(num_dict)
"""
{1: 1}
{1: 1, 2: 1}
{1: 1, 2: 2}
{1: 1, 2: 2, 3: 1}
{1: 1, 2: 2, 3: 2}
"""
列表字典嵌套
In [36]: name1 = {"name": '小满', 'age': 3, 'hobby': '摸鱼'}
In [37]: name2 = {'name': '大乔', 'age': 4, 'hobby': '抢人头'}
In [38]: name3 = {'name': '阿珂', 'age': 4, 'hobby': '刀人'}
In [39]: name_list = [name1, name2, name3]
In [40]: for name in name_list:
...: print("姓名:{name}, 年龄:{age},爱好:{hobby}".format(**name))
...:
姓名:小满, 年龄:3,爱好:摸鱼
姓名:大乔, 年龄:4,爱好:抢人头
姓名:阿珂, 年龄:4,爱好:刀人
使用函数快速生成一个字典
def func(**kwargs):
user_dict = kwargs
print(user_dict)
username = input("输入姓名:")
password = input("输入密码:")
func(username=username, password=password, balance="1000")
"""
输入姓名:小满
输入密码:123
{'username': '小满', 'password': '123', 'balance': '1000'}
"""
def foo(**kwargs):
print(kwargs)
print(locals())
print(vars())
foo(name='eva', age=30, hobby=['python', 'java'])
"""
{'name': 'eva', 'age': 30, 'hobby': ['python', 'java']}
{'kwargs': {'name': 'eva', 'age': 30, 'hobby': ['python', 'java']}}
{'kwargs': {'name': 'eva', 'age': 30, 'hobby': ['python', 'java']}}
"""
关于format_map以及双大括号赋值的问题
变量名被双大括号
{}包围,这样 Python 解释器就不会将其解释为变量名了。
tags = """
{{ value: {PostmanRuntime}, name: 'PostmanRuntime'}},
{{ value: {Python Requests}, name: 'Python Requests'}},
{{ value: {Chrome}, name: 'Chrome'}}
""".format_map(browser_dict)
print(tags)
"""
{ value: 44, name: 'PostmanRuntime'},
{ value: 51, name: 'Python Requests'},
{ value: 6, name: 'Chrome'}
"""
字典生成式的应用
In [5]: data = 'name=挪威的森林&price=88&publish=上海出版社'
In [6]: data_dict = {k: v for k, v in (line.split("=") for line in data.split("&"))}
In [7]: data_dict
Out[7]: {'name': '挪威的森林', 'price': '88', 'publish': '上海出版社'}
三元运算符在字典中的使用
a = 10
b = 20
print({True: a, False: b}[a < b]) # 10 方括号是条件,根据这个结果去字典里面判断
字典核心底层原理
字典 对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组)。数组的每个单元叫做
bucket。每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。由于所有
bucket结构大小一致,我们可以通过偏移量来读取指定的bucket。
详细可以参考这篇友链:点我打开
用法总结
- 字典在内存中开销巨大,典型的空间换时间。
- 键查询速度很快
- 网字典里面添加新键值对可能导致扩容,导致散列表中键的次序变化。因此,
不要在遍历字典的同时进行字典的修改- 键必须可散列
- 数字、字符串、元组都是可散列的
- 自定义的对象需要支持下面三点:
- 支持
hash()函数- 支持通过
__eq__()方法检测相等性- 若
a==b为真,则hash(a)==hash(b)也为真- 可变类型不支持
hash,不可变类型才支持hash
In [45]: name = '小满'
In [46]: new_name = '小满'
In [47]: name == new_name
Out[47]: True
In [48]: name is new_name
Out[48]: False
In [49]: hash(name) == hash(new_name)
Out[49]: True
In [50]: hash(['小满'])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[50], line 1
----> 1 hash(['小满'])
TypeError: unhashable type: 'list'
In [51]:
while循环小技巧
当控制的数为1的时候,while条件写成<=或者>=
num = 1
while num <= 5:
print("人生苦短 我用Python")
num += 1
当控制的数为0的时候,while条件写成<或者>
num = 0
while num < 5:
print("人生苦短 我用Python")
num += 1
接口注释
def resize_image(image, size):
"""做了什么
一言以蔽之
:param 参数名: 参数名解释
:param size: 包含宽高的元组:(width, height)
:return: 返回了什么
"""
def resize_image(image, size):
"""将图片缩放为指定尺寸,并返回新的图片。
注意:当文件超过 5MB 时,请使用 resize_big_image()
:param image: 图片文件对象
:param size: 包含宽高的元组:(width, height)
:return: 新图片对象
"""
条件表达式中不能有赋值操作符,不过可以有海象运算符
In [52]: age = 3
In [53]: if (name = '小满'):
...: print(age)
Cell In[53], line 1
if (name = '小满'):
^
SyntaxError: invalid syntax. Maybe you meant '==' or ':=' instead of '='?
In [54]: if name := "小满":
...: print(age)
...:
3
In [55]: name
Out[55]: '小满'
海象运算符
python3.8引入walrus 操作符允许我们在条件判断中同时进行赋值操作。这样可以简化代码,将赋值和比较结合在一起,提高代码的可读性和简洁性。
with open('data.txt', 'wt', encoding="utf-8") as file:
file.write('小满\n3\n摸鱼')
with open('data.txt', encoding='utf-8') as file:
while data := file.readline():
print(data.strip())
if name := '小满':
print('小满,欢迎回家!')
else:
print('你不是小满~')
# 小满
# 3
# 摸鱼
# 小满,欢迎回家!
关于条件判断内的变量
如果在条件判断内定义的变量,需要有
else分支,才可以正常在条件判断内引用到这个变量,否则会报错
# 正确的演示
path = "reset"
if path == '/register':
data = '注册'
elif path == '/login':
data = '登录'
else:
data = '404 page not found'
print(data) # 404 page not found
# 错误的演示
path = "reset"
if path == '/register':
data = '注册'
elif path == '/login':
data = '登录'
print(data) # NameError: name 'data' is not defined
递归
递归函数,指的是自己调用自己的函数,在函数体内部直接或间接的自己调用自己。每个递归函数必须包含两个部分:
- 终止条件
- 表示递归什么时候结束。一般用于返回值,不再调用自己。
- 递归步骤
- 把第n步的值和第n-1步的值相关联。
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
如果递归次数超过30层,就不要使用递归了。
# 计算5的阶乘
def f(n):
if n == 1:
return 1
else:
return n * f(n-1)
f(5) # 120
yield和yield from
lst = [1, [[[[3, 3], 5]]], [[[[[[[[[[[[[6]]]]], 8]]], "aaa"]]]], 250]]
def func(ls):
for item in ls:
if isinstance(item, list):
yield from func(item)
else:
yield item
for line in func(lst):
print(line, end=" ") # 1 3 3 5 6 8 aaa 250
修改递归最大次数(很少用到)
import sys
current_recursion_limit = sys.getrecursionlimit()
print(current_recursion_limit) # 3000
set_limit = sys.setrecursionlimit(5000)
print(set_limit) # 5000
嵌套函数
一般在什么情况下使用嵌套函数
- 封装-数据隐藏
- 外部无法访问“嵌套函数”。
- 贯彻 DRY(Don't Repeat Yourself) 原则嵌套函数,可以让我们在函数内部避免重复代码
- 闭包
# 未使用内嵌函数
def printChineseName(name, familyName):
print(f'{familyName} {name}')
def printEnglishName(name, familyName):
print(f'{name} {familyName}')
printChineseName('满', '小')
printEnglishName('eva', 'j')
"""
小 满
eva j
"""
# 使用内嵌函数后
def printName(isChineseName, name, familyName):
def showName(a, b):
print(f'{a} {b}')
if isChineseName:
showName(familyName, name)
else:
showName(name, familyName)
printName(True, '满', '小')
printName(False, 'eva', 'j')
"""
小 满
eva j
"""
LEGB规则
python在查找名称时候,是按照LEGB规则查找的
Local 指的就是函数或者类的方法内部
Enclosed 指的是嵌套函数(一个函数包裹另一个函数,闭包)
Global 指的是模块中的全局变量
Built in 指的是python未自己保留的特殊名称
格式化时间
import datetime
now = datetime.datetime.now()
time_now = now.strftime("%x %X")
print(time_now) # 02/26/24 19:29:56
import time
now = time.strftime("%x %X")
print(now) # 02/26/24 19:30:24
import time
now = time.strftime("%Y年%m月%d日 %H:%M:%S秒")
print(now) # 2024年02月26日 19:31:01秒
import time
from datetime import datetime
t = int(time.time())
now = datetime.fromtimestamp(t)
print(now) # 2024-02-26 19:31:35
获取时间
import time
timer = time.time
def foo():
return [pow(index, 3) for index in range(200000)]
t1 = timer()
foo()
t2 = timer()
print(t2 - t1)
批量卸载/安装包
# 先导出包到一个位置,比如桌面
pip list freeze > package.txt
# 批量卸载包
pip uninstall -r package.txt -y
# 批量安装包
pip install -r package.txt
# 批量安装包另外一种方法,使用空格隔开包
pip install requests lxml ...
# pip指定镜像(临时使用一下)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
使用pandas快速写入excel
from pandas as pd
import common
contents = ['排名', '名称', '评价人数', '评分', '推荐理由', '演员整容']
df = pd.DataFrame(common.data_list, columns=contents)
df.to_excel(rf'{path_file}/豆瓣电影top250 py pandas.xlsx', index=False)
找模块的顺序
- 从内存找
- sys.path
sys.path的第一个文件夹是执行文件所在的文件夹
环境变量是以执行文件为准的,所有的被导入的模块或者说后续的其他文件引用的sys.path都是参照执行文件的sys.path
开启多进程/多线程的目的
解决IO阻塞 就是耗时间 可以用time.sleep() 模拟
没有join方法的时候,处于并行状态,缺点:先将主进程启动起来,但是没有按照顺序拿到子进程的结果
start就启动的就是子进程
在启动后里面加上join方法 ---> c串行的状态
关于self
self是在类实例化时才存在的,在静态方法中无法访问实例变量。
静态方法可以访问类变量
静态方法不依赖于类的实例,并且不会访问或修改实例变量。它们在逻辑上与类关联,但与具体的实例无关。
关于super
# super()继承的时候可以这样写
class Mixin:
def __init__(self, name, age):
self.name = name
self.age = age
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs):
self.hobby = hobby
调用方法的几种方式
class Hero:
def say(self):
print("你好!我是小满")
Hero.say(Hero()) # 你好!我是小满
Hero().say() # 你好!我是小满
xm = Hero()
Hero.say(xm) # 你好!我是小满
getattr(Hero(), 'say')() # 你好!我是小满
使用pathlib创建多级文件夹
# 需求:使用 pathlib 创建多级文件夹。
pathlib.Path('./data').mkdir(parents=True, exist_ok=True)
# parents = True: 创建中间级父目录
# exist_ok= True: 目标目录存在时不报错
使用pathlib获取根目录
from pathlib import Path
# parent父级的意思,根据实际情况去控制即可
BASE_DIR = Path(__file__).resolve().parent.parent
pathlib两个绝对路径区别
path.absolute()返回路径的绝对路径,将当前工作目录与路径拼接得到完整路径。
path.resolve()返回路径的规范化绝对路径,处理符号链接和特殊路径符号,得到最终的绝对路径。
os.walk(遍历目录,递归遍历)
import os
base_path = r"E:\小满写真"
for root, dirs, files in os.walk(base_path):
for dir_path in dirs:
# 查看全部目录的绝对路径
print(f"➨ {os.path.join(root, dir_path)}")
for name in files:
# 查看所有文件的绝对路径
print(f"⇨ {os.path.join(root, name)}")
关于爬虫编码
如果网页源代码中的
charset设置的是gb2312,那么requests.encoding设置成GBK或者gbk就可以了。
xpath中*号表示通配符
items = tree.xpath("//div/*/li/a/@href")
reduce
from functools import reduce
def func(x, y):
return x + y
result = reduce(func, range(1, 11))
print(result) # 55
print(reduce(lambda x, y: x + y, range(1, 11))) # 55

 浙公网安备 33010602011771号
浙公网安备 33010602011771号