python常用内置模块
建议掌握的模块
正则相关语法
普通字符
字母、数字、汉字、下划线、以及没有特殊定义的符号,都是"普通字符"。正则表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。
例如:表达式c,在匹配字符串abcde时,匹配结果是:成功;匹配到的内容是c;匹配到的位置开始于2,结束于3。(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)
元字符
正则表达式中使用了很多元字符,用来表示一些特殊的含义或功能。
| 表达式 | 匹配 |
|---|---|
. |
小数点可以匹配除了换行符\n以外的任意一个字符 |
| ` | ` |
[] |
匹配字符集中的一个字符 |
[^] |
对字符集求反,也就是上面的反操作。尖号必须在方括号里的最前面 |
- |
定义[]里的一个字符区间,例如[a-z] |
\ |
对紧跟其后的一个字符进行转义 |
() |
对表达式进行分组,将圆括号内的内容当做一个整体,并获得匹配的值 |
转义字符
一些无法书写或者具有特殊功能的字符,采用在前面加斜杠""进行转义的方法。例如下表所示:
| 表达式 | 匹配 |
|---|---|
\r, \n |
匹配回车和换行符 |
\t |
匹配制表符 |
\\ |
匹配斜杠\ |
\^ |
匹配^符号 |
\$ |
匹配$符号 |
\. |
匹配小数点. |
预定义匹配字符集
正则表达式中的一些表示方法,可以同时匹配某个预定义字符集中的任意一个字符。比如,表达式\d可以匹配任意一个数字。虽然可以匹配其中任意字符,但是只能是一个,不是多个。如下表所示,注意大小写:
| 表达式 | 匹配 |
|---|---|
\d |
任意一个数字,0~9 中的任意一个 等价于 [0-9]。 |
\w |
任意一个字母或数字或下划线,也就是 AZ,az,0~9,_ 中的任意一个 等价于[A-Za-z0-9_]。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\D |
\d的反集,也就是非数字的任意一个字符,等价于 [^0-9] |
\W |
\w的反集,也就是[^\w] 等价于 ‘[^A-Za-z0-9_]‘。 |
\S |
\s的反集,也就是[^\s] 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
重复匹配
| 表达式 | 匹配 |
|---|---|
{n} |
表达式重复n次,比如\d{2}相当于\d\d,a{3}相当于aaa |
{m,n} |
表达式至少重复m次,最多重复n次。比如ab{1,3}可以匹配ab或abb或abbb |
{m,} |
表达式至少重复m次,比如\w\d{2,}可以匹配a12,_1111,M123等等 |
? |
匹配表达式0次或者1次,相当于{0,1},比如a[cd]?可以匹配a,ac,ad |
+ |
表达式至少出现1次,相当于{1,},比如a+b可以匹配ab,aab,aaab等等 |
* |
表达式出现0次到任意次,相当于{0,},比如\^*b可以匹配b,^^^b等等 |
位置匹配
有时候,我们对匹配出现的位置有要求,比如开头、结尾、单词之间等等。
| 表达式 | 匹配 |
|---|---|
^ |
在字符串开始的地方匹配,符号本身不匹配任何字符 |
$ |
在字符串结束的地方匹配,符号本身不匹配任何字符 |
\b |
匹配一个单词边界,也就是单词和空格之间的位置,符号本身不匹配任何字符 |
\B |
匹配非单词边界,即左右两边都是\w范围或者左右两边都不是\w范围时的字符缝隙 |
re模块
re.search
re.search返回的是一个match对象可以通过
结果.group()或者结果.group(0)得到匹配的结果
In [29]: import re
In [30]: s = "foo123bar"
In [31]: re.search("123", s)
Out[31]: <re.Match object; span=(3, 6), match='123'>
In [32]: result = re.search("123", s)
In [33]: result
Out[33]: <re.Match object; span=(3, 6), match='123'>
In [35]: result.start() # 开始位置
Out[35]: 3
In [36]: result.end() # 结束位置
Out[36]: 6
In [37]: result.string # 匹配的字符串
Out[37]: 'foo123bar'
In [38]: result = re.search("1234", s)
In [39]: result
In [40]: result is None # 如果匹配不到返回的是None 或者说是空
Out[40]: True
In [53]: result = re.search("\d+", s)
In [57]: result.group() # 得到结果
Out[57]: '123'
. 号 匹配任意字符
In [41]: s = "foo.123.bar"
In [42]: re.search(".", s) # 不转义 匹配任意字符
Out[42]: <re.Match object; span=(0, 1), match='f'>
In [43]: re.search("\.", s) # 转义匹配到的结果
Out[43]: <re.Match object; span=(3, 4), match='.'>
^ 匹配开头
In [44]: re.search("^f", s) # ^ 匹配开头
Out[44]: <re.Match object; span=(0, 1), match='f'>
$ 匹配结尾
In [48]: s = "foo123oof"
In [49]: re.search("f", s)
Out[49]: <re.Match object; span=(0, 1), match='f'>
In [50]: re.search("f$", s)
Out[50]: <re.Match object; span=(8, 9), match='f'>
*号 匹配0次或更多次
In [48]: s = "foo123oof"
In [52]: re.search("fo*", s)
Out[52]: <re.Match object; span=(0, 3), match='foo'>
In [53]: s = "f123"
In [54]: re.search("fo*", s)
Out[54]: <re.Match object; span=(0, 1), match='f'>
+号匹配1次或更多次
In [56]: s = "foo123"
In [57]: re.search("fo+", s)
Out[57]: <re.Match object; span=(0, 3), match='foo'>
In [58]: s = "f123"
In [59]: re.search("fo+", s)
In [60]: # 没有匹配到任何结果,所以是空
{}匹配括号内的次数,第二个参数如果不写默认匹配更多次
注意:逗号之间不要添加空格,不然匹配不到任何数据
In [61]: s = "foo"
In [62]: re.search("o{1, 2}", s) # 因为添加了空格, 所以匹配不到任何数据
In [64]: re.search("o{1,2}", s)
Out[64]: <re.Match object; span=(1, 3), match='oo'>
In [65]: re.search("o{1}", s)
Out[65]: <re.Match object; span=(1, 2), match='o'>
In [66]: re.search("o{1,}", s)
Out[66]: <re.Match object; span=(1, 3), match='oo'>
\斜杠,转义符或者匹配字符集
In [68]: s = "foo123bar"
In [69]: re.search("\d+", s)
Out[69]: <re.Match object; span=(3, 6), match='123'>
In [70]: re.search("\D+", s)
Out[70]: <re.Match object; span=(0, 3), match='foo'>
In [72]: re.search("\w", s)
Out[72]: <re.Match object; span=(0, 1), match='f'>
In [73]: re.search("\w+", s)
Out[73]: <re.Match object; span=(0, 9), match='foo123bar'>
[ ] 括号内的次数匹配一次
In [75]: s = "foo123bar"
In [76]: re.search("[0-9]{3}", s)
Out[76]: <re.Match object; span=(3, 6), match='123'>
In [77]: re.search("[a-z]{3}", s)
Out[77]: <re.Match object; span=(0, 3), match='foo'>
In [78]: re.search("[a-z]*", s)
Out[78]: <re.Match object; span=(0, 3), match='foo'>
group分组
通过search或者match可以得到一个match对象,这个对象可以调用group方法
默认的分组就是group(0)
group(1)得到的是第一个括号的内容
group(2)得到是第二个括号的内容,以此类推
In [2]: import re
In [3]: s = "one,two,three"
In [4]: re.search("(\w+),(\w+)", s)
Out[4]: <re.Match object; span=(0, 7), match='one,two'>
In [5]: result = re.search("(\w+),(\w+)", s)
In [6]: result.group()
Out[6]: 'one,two'
In [7]: result.group(0)
Out[7]: 'one,two'
In [8]: type(result.group(0))
Out[8]: str
In [9]: result.group(1)
Out[9]: 'one'
In [10]: result.group(2)
Out[10]: 'two'
In [11]: result[1]
Out[11]: 'one'
In [12]: result[2]
Out[12]: 'two'
In [13]: result.groups()
Out[13]: ('one', 'two')
In [14]: type(result.groups())
Out[14]: tuplecls
给group起一个名字
?P<name> 比如 (?P<name1>\w+)
In [38]: s = "December 2023"
In [39]: result = re.search(r"(?P<month>[a-zA-Z]+)\s(?P<year>\d+)", s)
In [40]: result.groupdict()
Out[40]: {'month': 'December', 'year': '2023'}
In [41]: item = result.groupdict()
In [42]: month = item['month']
In [43]: year = item['year']
In [44]: month
Out[44]: 'December'
In [45]: year
Out[45]: '2023'
非捕获分组
有时候,我们并不需要捕获某个分组的内容,但是又想使用分组的特性。
这个时候就可以使用非捕获组
(?:表达式),从而不捕获数据,还能使用分组的功能。例如想要匹配两个字母组成的单词或者四个字母组成的单词就可以使用非捕获分组:
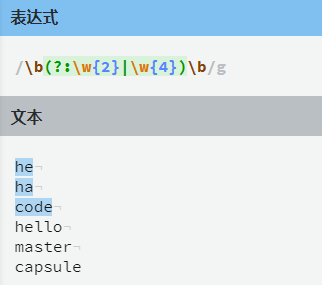
re.match
匹配开头
如果开头匹配不到,那么返回None
一般是用来检测字符串的合法性
场景:检测用户的邮箱之类是否合法,需要从开头匹配
In [47]: s = "foo123oof"
In [48]: re.match("\d+", s)
In [49]: result = re.match("\d+", s)
In [50]: result
In [51]: result is None
Out[51]: True
In [52]: re.search("\d+", s)
Out[52]: <re.Match object; span=(3, 6), match='123'>
In [53]: result = re.search("\d+", s)
In [54]: result
Out[54]: <re.Match object; span=(3, 6), match='123'>
In [57]: result.group()
Out[57]: '123'
re.fullmatch
整个字符串做匹配,整个字符串都满足正则规则就能匹配到,否则就是None
In [69]: import re
In [70]: s = "foo123oof"
In [71]: result = re.fullmatch("\d+", s) # 不满足条件,得到的结果就是None
In [72]: result
In [73]: result is None
Out[73]: True
In [74]:
In [74]: s = "1234"
In [76]: result = re.fullmatch("\d+", s) # 整个字符串满足条件,得到结果
In [77]: result[0]
Out[77]: '1234'
re.findall
匹配全部的结果,返回值是一个列表
In [79]: s = "123foo456bar"
In [80]: re.match("\d+", s)
Out[80]: <re.Match object; span=(0, 3), match='123'>
In [81]: re.search("\d+", s)
Out[81]: <re.Match object; span=(0, 3), match='123'>
In [82]: re.findall("\d+", s)
Out[82]: ['123', '456'] # 得到的结果是一个列表
In [83]: re.fullmatch("\d+", s) # None
In [84]:
In [85]: s = "foo,bar,baz,qux,quux,corge"
In [86]: re.findall(r"(\w+),(\w+)", s)
Out[86]: [('foo', 'bar'), ('baz', 'qux'), ('quux', 'corge')]
In [87]: fruits = "apple,orange,banana"
In [88]: re.findall(r"(\w+),(\w+)", fruits)
Out[88]: [('apple', 'orange')]
In [89]: re.findall(r"\w+", fruits)
Out[89]: ['apple', 'orange', 'banana']
re.finditer
得到一个迭代器
得到结果之后通过for循环或者next取值
如果数据量很大的话,可以使用此方法
In [100]: s = "foo,bar,baz,qux,quux,corge"
In [101]: result_iter = re.finditer("\w+", s)
In [102]: result_iter
Out[102]: <callable_iterator at 0x214f952b280>
In [103]: result_iter.__next__()[0]
Out[103]: 'foo'
In [104]: for result in result_iter:
...: print(result[0])
...:
bar
baz
qux
quux
corge
In [105]:
字符串的查找替换
re.sub
对结果进行替换,直接得到替换之后的结果
In [108]: s = "foo,000,baz,123,quux,corge"
In [109]: result = re.sub("\d+", "#", s) # 这个例子中将数字替换成#号
In [110]: result
Out[110]: 'foo,#,baz,#,quux,corge'
In [111]: type(result)
Out[111]: str
In [122]: s = "foo,000,baz,123,quux,corge" # 这个例子中把字母换成*号
In [123]: result = re.sub("[a-z]+", "*", s)
In [124]: result
Out[124]: '*,000,*,123,*,*'
sub结合group分组一起使用
In [134]: s = "123abc456"
In [135]: re.search("(\d+)[a-z]+(\d+)", s)
Out[135]: <re.Match object; span=(0, 9), match='123abc456'>
In [136]: re.sub("(\d+)[a-z]+(\d+)", r"\2abc\1", s) # 交换结果的位置
Out[136]: '456abc123'
需求:把第一个group匹配的结果换成*号,第二个group匹配的结果换成#号
语法
\g<group_number>\g的左边默认就是匹配到的第一个组,\g的右边可以写其他组的group_number
In [145]: s = "123abc456"
In [146]: re.sub("(\d+)[a-z]+(\d+)", r"*\g<2>%", s)
Out[146]: '*456%'
结合函数一起使用
需求:把字符串的英文字母从小写变成大写,把所有的数字乘以10
import re
def foo(match_object):
# 获取匹配的字符串
s = match_object.group(0)
if s.isdigit():
# 如果字符串只包含数字,则将其乘以10并转换为字符串
return str(int(s) * 10)
else:
# 如果字符串不只包含数字,则将其转换为大写形式
return s.upper()
# 使用 re.sub() 进行替换
# 此处的foo就是一个函数,接受一个match对象
r1 = re.sub(r"\w+", foo, "foo.10.bar.20.baz.30")
# 使用 re.subn() 进行替换,并返回替换的次数
r2 = re.subn(r"\w+", foo, "foo.10.bar.20.baz.30")
print(r1) # 输出替换后的字符串 FOO.100.BAR.200.BAZ.300
print(r2) # 输出替换后的字符串和替换的次数 ('FOO.100.BAR.200.BAZ.300', 6)
re.sub的count参数
控制替换次数
In [151]: s = "foo,000,baz,123,quux,corge"
In [152]: re.sub("\w+", "xxx", s, count=2) # 最多替换2次
Out[152]: 'xxx,xxx,baz,123,quux,corge'
re.subn
功能和re.sub一样,只是会额外返回替换的次数
In [129]: s = "foo,000,baz,123,quux,corge"
In [130]: result = re.subn("[a-z]+", "*", s) # 把字母替换成星号
In [131]: result
Out[131]: ('*,000,*,123,*,*', 4) # 这个数字4 就是替换的次数
In [132]: type(result)
Out[132]: tuple # 得到的结果是一个元组,元组的第0个索引是结果,第一个索引是次数
re.split
需求:将下面字符串的空格和逗号全部去除,保留去除后的结果列表
s = "foo, bar, baz, qux, quux, corge, orange, foobar"
# 使用字符串的split方法
In [155]: s = "foo, bar, baz, qux, quux, corge, orange, foobar"
In [156]: [index.strip() for index in s.split(",")]
Out[156]: ['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 'orange', 'foobar']
# 使用re.split方法
In [157]: s = "foo, bar, baz, qux, quux, corge, orange, foobar"
In [158]: re.split(r",\s*", s)
Out[158]: ['foo', 'bar', 'baz', 'qux', 'quux', 'corge', 'orange', 'foobar']
# 使用re.split 使用maxsplit控制最大分割次数
In [161]: s = "foo, bar, baz, qux, quux, corge, orange, foobar"
In [162]: re.split(r",\s*", s, maxsplit=4) # 最大分割次数4次 后面的还是保留原始字符串不做处理
Out[162]: ['foo', 'bar', 'baz', 'qux', 'quux, corge, orange, foobar']
re.comple
先把正则表达式compile成一个正则表达式对象,然后再去操作
一般情况下很少使用
In [197]: s = "foo123bar"
In [198]: re_obj = re.compile("\d+")
In [199]: re_obj.search(s).group(0) # 方式1 使用re_obj直接调用re方法
Out[199]: '123'
In [200]:
In [200]: re.search(re_obj, s)
Out[200]: <re.Match object; span=(3, 6), match='123'>
In [201]: re.search(re_obj, s).group() # 方式2 作为参数
Out[201]: '123'
flag匹配模式
Python的re模块提供了一些可选的标志修饰符来控制匹配的模式。可以同时指定多种模式,通过与符号|来设置多种模式共存。如re.I | re.M被设置成I和M模式。
| 匹配模式 | 描述 |
|---|---|
| re.A | ASCII字符模式 |
| re.I | 使匹配对大小写不敏感,也就是不区分大小写的模式 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 这个通配符能够匹配包括换行在内的所有字符,针对多行匹配 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
re.I对大小写不敏感,一起匹配全称
re.IGNORECASE
In [164]: re.search("a+", "aaaAAA")
Out[164]: <re.Match object; span=(0, 3), match='aaa'>
In [165]: re.search("A+", "aaaAAA")
Out[165]: <re.Match object; span=(3, 6), match='AAA'>
In [166]: re.search("a+", "aaaAAA", re.I) # 注意这里
Out[166]: <re.Match object; span=(0, 6), match='aaaAAA'>
re.M多行匹配 全称re.MULTILINE
In [168]: s = "foo\nbar\nbaz"
In [169]: re.search("^foo", s)
Out[169]: <re.Match object; span=(0, 3), match='foo'>
In [170]: re.search("^bar", s) # 无结果
In [171]: re.search("bar$", s) # 无结果
In [172]: re.search("baz$", s)
Out[172]: <re.Match object; span=(8, 11), match='baz'>
In [173]: re.search("^bar", s) # 无结果
In [174]: re.search("^bar", s, re.M)
Out[174]: <re.Match object; span=(4, 7), match='bar'>
.*和.*?有什么区别
在正则表达式中,.* 和.*? 都是用于匹配任意字符(除换行符外)的模式。它们之间的区别在于贪婪匹配和非贪婪匹配的行为。
首先来看.*
import re
content = "Hello, World! This is a test string. Hello, another string."
pattern = "Hello.*string."
result = re.search(pattern, content)
print(result.group())
# Hello, World! This is a test string. Hello, another string.
接着看.*?
import re
content = "Hello, World! This is a test string. Hello, another string."
pattern = "Hello.*?string."
result = re.search(pattern, content)
print(result.group())
# Hello, World! This is a test string.
总结:
.* 是贪婪匹配模式,它会尽可能匹配更多的字符。它会尝试匹配尽量长的字符串,直到遇到下一个模式或字符串的结束。
.*? 是非贪婪匹配模式,它会尽可能匹配更少的字符。它会尝试匹配尽量短的字符串,直到满足下一个模式或字符串的结束。
正则表达式提取技巧
不需要compile
使用re.compile()的时候,程序内部调用的是_compile()方法;当使用re.finall()的时候,在模块内部自动先调用了_compile()方法,再调用findall()方法。re.findall()自带re.compile()的功能,所以没有必要使用re.compile()。
预加载
import re
obj = re.compile(r"\d+")
items = obj.findall("我今天有100块,我买了1个蛋糕,3杯奶茶,一张电影票")
print(items) # ['100', '1', '3']
先抓大再抓小
一些无效内容和有效内容可能具有相同的规则。这种情况下很容易把有效内容和无效内容混在一起,如下面这段文字:
有效用户:
姓名: 张三
姓名: 李四
姓名: 王五
无效用户:
姓名: 不知名的小虾米
姓名: 隐身的张大侠
有效用户和无效用户的名字前面都以“姓名: ”开头,如果使用“姓名:(.*?)\n”来进行匹配,就会把有效信息和无效信息混在一起,难以区分。
import re
users = """
有效用户:
姓名: 张三
姓名: 李四
姓名: 王五
无效用户:
姓名: 不知名的小虾米
姓名: 隐身的张大侠
"""
pattern = "姓名:(.*)"
result = re.findall(pattern, users)
print(result)
# 结果如下
# [' 张三 ', ' 李四 ', ' 王五 ', ' 不知名的小虾米 ', ' 隐身的张大侠']
参考方法
import re
users = """
有效用户:
姓名: 张三
姓名: 李四
姓名: 王五
无效用户:
姓名: 不知名的小虾米
姓名: 隐身的张大侠
"""
user_big = r"有效用户(.*?)无效用户"
big_items = re.findall(user_big, users, re.S)
print(f"big_items的值为: {big_items}") # big_items的值为: [': \n\n姓名: 张三 \n\n姓名: 李四 \n\n姓名: 王五 \n\n']
use_ful = r"姓名:(.*?)\n"
result = re.findall(use_ful, big_items[0])
print(f"最终结果为: {result}") # 最终结果为: [' 张三 ', ' 李四 ', ' 王五 ']
在上面的例子中,括号和“.*?”都是一起使用的,因此可能会有读者认为括号内只能有这3种字符,不能有其他普通的字符。但实际上,括号内也可以有其他字符,对匹配结果的影响如下所示:
import re
html = """<div class="tail-info">客户端</div>
<div class="tail-info">2017-0101 13:45:00</div>
"""
result1 = re.findall('tail-info">(.*?)<', html)
result2 = re.findall('tail-info">2017(.*?)<', html)
result3 = re.findall('tail-info">(2017.*?)<', html)
print(f"括号里只有.*?时, 得到的结果: {result1}")
print(f"2017在括号外面时, 得到的结果: {result2}")
print(f"2017在括号里面时, 得到的结果是: {result3}")
结果如下:
括号里只有.*?时, 得到的结果: ['客户端', '2017-0101 13:45:00']
2017在括号外面时, 得到的结果: ['-0101 13:45:00']
2017在括号里面时, 得到的结果是: ['2017-0101 13:45:00']
如果括号里面有其他普通字符,那么这些普通字符就会出现在获取的结果里面。举一个例子,如果说“左手和右手之间”,一般指的是躯干这一部分。但如果说“左手和右手之间,包括左手和右手”,那么就是指的整个人。而把普通的字符放在括号里面,就表示结果中需要包含它们。
一些正则练手题目
注:题目来源 https://regexone.com/
正则学习网站:
Exercise 1: Matching Characters
| Task | Text |
|---|---|
| Match | abcdefg |
| Match | abcde |
| Match | abc |
abc
Exercise 1½: Matching Digits
| Task | Text |
|---|---|
| Match | abc123xyz |
| Match | define "123" |
| Match | var g = 123; |
123
Exercise 2: Matching With Wildcards
| Task | Text |
|---|---|
| Match | cat. |
| Match | 896. |
| Match | ?=+. |
| Skip | abc1 |
...\.
Exercise 3: Matching Characters
| Task | Text |
|---|---|
| Match | can |
| Match | man |
| Match | fan |
| Skip | dan |
| Skip | ran |
| Skip | pan |
[cmf]an
xercise 4: Excluding Characters
| Task | Text |
|---|---|
| Match | hog |
| Match | dog |
| Skip | bog |
[^b]og
Exercise 5: Matching Character Ranges
| Task | Text |
|---|---|
| Match | Ana |
| Match | Bob |
| Match | Cpc |
| Skip | aax |
| Skip | bby |
| Skip | ccz |
[A-C][n-p][a-c]
Exercise 6: Matching Repeated Characters
| Task | Text |
|---|---|
| Match | wazzzzzup |
| Match | wazzzup |
| Skip | wazup |
waz{3,5}up
Exercise 7: Matching Repeated Characters
| Task | Text |
|---|---|
| Match | aaaabcc |
| Match | aabbbbc |
| Match | aacc |
| Skip | a |
aa+b*c+
Exercise 8: Matching Optional Characters
| Task | Text |
|---|---|
| Match | 1 file found? |
| Match | 2 files found? |
| Match | 24 files found? |
| Skip | No files found. |
\d+\sfiles?\sfound\?
Exercise 9: Matching Whitespaces
| Task | Text |
|---|---|
| Match | 1. abc |
| Match | 2. abc |
| Match | 3. abc |
| Skip | 4.abc |
\d.\s+abc
Exercise 10: Matching Lines
| Task | Text |
|---|---|
| Match | Mission: successful |
| Skip | Last Mission: unsuccessful |
| Skip | Next Mission: successful upon capture of target |
^Mission:\ssuccessful$
Exercise 11: Matching Groups
| Task | Text | Capture Groups |
|---|---|---|
| Capture | file_record_transcript.pdf | file_record_transcript |
| Capture | file_07241999.pdf | file_07241999 |
| Skip | testfile_fake.pdf.tmp |
(^file_.+)\.pdf
Exercise 12: Matching Nested Groups
| Task | Text | Capture Groups |
|---|---|---|
| Capture | Jan 1987 | Jan 1987 1987 |
| Capture | May 1969 | May 1969 1969 |
| Capture | Aug 2011 | Aug 2011 2011 |
(\w+\s(\d+))
Exercise 13: Matching Nested Groups
| Task | Text | Capture Groups |
|---|---|---|
| Capture | 1280x720 | 1280 720 |
| Capture | 1920x1600 | 1920 1600 |
| Capture | 1024x768 | 1024 768 |
(\d+)x(\d+)
Exercise 14: Matching Conditional Text
| Task | Text |
|---|---|
| Match | I love cats |
| Match | I love dogs |
| Skip | I love logs |
| Skip | I love cogs |
I love (cats|dogs)
Exercise 15: Matching Other Special Characters
| Task | Text |
|---|---|
| Match | The quick brown fox jumps over the lazy dog. |
| Match | There were 614 instances of students getting 90.0% or above. |
| Match | The FCC had to censor the network for saying &$#*@!. |
.*
下面难度提升
Exercise 1: Matching Numbers
| Task | Text |
|---|---|
| Match | 3.14529 |
| Match | -255.34 |
| Match | 128 |
| Match | 1.9e10 |
| Match | 123,340.00 |
| Skip | 720p |
[^7].+\d$
Exercise 2: Matching Phone Numbers
| Task | Text |
|---|---|
| Capture | 415-555-1234 |
| Capture | 650-555-2345 |
| Capture | (416)555-3456 |
| Capture | 202 555 4567 |
| Capture | 4035555678 |
| Capture | 1 416 555 9292 |
(\d{3})
Exercise 3: Matching Emails
| Task | Text | Capture Groups |
|---|---|---|
| Capture | tom@hogwarts.com | tom |
| Capture | tom.riddle@hogwarts.com | tom.riddle |
| Capture | tom.riddle+regexone@hogwarts.com | tom.riddle |
| Capture | tom@hogwarts.eu.com | tom |
| Capture | potter@hogwarts.com | potter |
| Capture | harry@hogwarts.com | harry |
| Capture | hermione+regexone@hogwarts.com | hermione |
(^[\w\.]*)
Exercise 4: Capturing HTML Tags
| Task | Text | Capture Groups |
|---|---|---|
| Capture | <a>This is a link</a> |
a |
| Capture | <a href='https://regexone.com'>Link</a> |
a |
| Capture | <div class='test_style'>Test</div> |
div |
| Capture | <div>Hello <span>world</span></div> |
div |
<(\w+)
Exercise 5: Capturing Filename Data
| Task | Text | Capture Groups |
|---|---|---|
| Skip | .bash_profile | |
| Skip | workspace.doc | |
| Capture | img0912.jpg | img0912 jpg |
| Capture | updated_img0912.png | updated_img0912 png |
| Skip | documentation.html | |
| Capture | favicon.gif | favicon gif |
| Skip | img0912.jpg.tmp | |
| Skip | access.lock |
(\w+)\.(jpg|png|gif)$
Exercise 6: Matching Lines
| Task | Text | Capture Groups |
|---|---|---|
| Capture | The quick brown fox... | The quick brown fox... |
| Capture | jumps over the lazy dog. | jumps over the lazy dog. |
(\S.*)
Exercise 7: Extracting Data From Log Entries
| Task | Text | Capture Groups |
|---|---|---|
| Skip | W/dalvikvm( 1553): threadid=1: uncaught exception | |
| Skip | E/( 1553): FATAL EXCEPTION: main | |
| Skip | E/( 1553): java.lang.StringIndexOutOfBoundsException | |
| Capture | E/( 1553): at widget.List.makeView(ListView.java:1727) | makeView ListView.java 1727 |
| Capture | E/( 1553): at widget.List.fillDown(ListView.java:652) | fillDown ListView.java 652 |
| Capture | E/( 1553): at widget.List.fillFrom(ListView.java:709) | fillFrom ListView.java 709 |
(\w+)\(([\w\.]+):(\d+)\)
Exercise 8: Extracting Data From URLs
| Task | Text | Capture Groups |
|---|---|---|
| Capture | ftp://file_server.com:21/top_secret/life_changing_plans.pdf | ftp file_server.com 21 |
| Capture | https://regexone.com/lesson/introduction#section | https regexone.com |
| Capture | file://localhost:4040/zip_file | file localhost 4040 |
| Capture | https://s3cur3-server.com:9999/ | https s3cur3-server.com 9999 |
| Capture | market://search/angry%20birds | market search |
(\w+)://([\w\-\.]+)(:(\d+))?
random模块相关方法
需要掌握的,未提及的建议自行了解
import random
大于0且小于1之间的小数 (不含1)
random.random() # 0.38916016381720087
指定区间 指定start到end(包含start和end)之间的随机小数
random.uniform(0, 10) # 8.080921224222864
指定区间 指定start到end(含end)之间的随机整数
random.randint(1, 20) # 14
指定区间 指定start到end(不含end)之间的随机整数
random.randrange(1, 20) # 14
指定区间 指定start到end(不含end)之间的随机整数 第三个参数是步长 同python自带的range
random.randrange(1, 20, 5) # 6
随机取可迭代类型中的一个
nameList = ["小满", "大乔", "王昭君"]
random.choice(nameList) # 大乔
random.choice(tuple(nameList)) # 王昭君
random.choice("你是年少的欢喜") # 少
随机取可迭代类型中的多个(返回结果是列表)
nameList = ["小满", "大乔", "王昭君"]
random.sample(nameList, 2) # ['大乔', '王昭君']
random.sample("你是年少的欢喜", 3) # ['的', '少', '欢']
另外一种方法
nameList = ["小满", "大乔", "王昭君"]
heroList = random.choices(nameList, k=2)
print(heroList) # ['大乔', '小满']
洗牌,打乱原列表顺序(无返回值)
nameList = ["小满", "大乔", "王昭君"]
random.shuffle(nameList)
print(nameList) # ['王昭君', '大乔', '小满']
小练习
随机生成N个验证码
import string
import random
def symbol_code(number, length):
"""
number: 验证码个数
length: 验证码长度
return: 包含全部验证码的列表
"""
text = string.ascii_letters + string.digits
symbol_list = []
for line in range(length):
symbol = "".join(random.sample(text, number))
symbol_list.append(symbol)
return symbol_list
OS模块
OS模块使用方法
需要掌握,未提及的建议自行了解
获取当前脚本绝对路径
import os
file_path = os.path.abspath(__file__)
print(file_path)
获取当前文件的上级目录
import os
base_path = os.path.dirname(os.path.abspath(路径))
print(base_path)
路径拼接
import os
bese_path = "E:\小满"
new_path = os.path.join(bese_path, "document", "img", "三岁啦.jpg")
print(new_path)
E:\小满\document\img\三岁啦.jpg
判断路径是否纯在
存在返回True 不存在返回False
import os
path = "E:\小满\记录生活\二次元"
exists = os.path.exists(path)
print(exists)
False
创建文件夹(若存在同名文件则报错)
import os
# 创建单个文件夹
os.mkdir("琶洲漫展")
import os
path = "E:\小满\记录生活\二次元"
if not os.path.exists(path):
# 俺路径规律批量创建文件夹
os.makedirs(path)

是否为文件
import os
path = "E:\小满\记录生活\二次元\with_friends.jpg"
is_file = os.path.isfile(path)
print(is_file)
True
是否为文件夹
import os
path = "E:\小满\记录生活\二次元"
is_dir = os.path.isdir(path)
print(is_dir) # True
file_path = os.path.join(path, "with_friends.png")
is_dir = os.path.isdir(file_path) # False
print(is_dir)
切割路径
import os
path = "E:\小满\记录生活\二次元\with_friends.jpg"
file_tuple = os.path.split(path)
print(file_tuple)
('E:\\小满\\记录生活\\二次元', 'with_friends.jpg')
获取结尾文件/文件夹名称
import os
path = "E:\小满\记录生活\二次元"
print(os.path.basename(path)) # 二次元
path = "E:\小满\记录生活\二次元\with_friends.jpg"
print(os.path.basename(path)) # with_friends.jpg
删除文件
import os
os.remove("文件路径")
删除单个文件夹(如果文件夹里面有文件存在则报错)
import os
os.rmdir("琶洲漫展")
递归删除多级文件夹(如果文件夹里面有文件存在则报错)
import os
dir_path = "E:\小满\记录生活\二次元\琶洲漫展"
os.removedirs(dir_path)
OSError: [WinError 145] 目录不是空的。: 'E:\\小满\\记录生活\\二次元\\琶洲漫展'
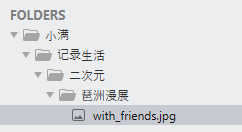
如果文件夹全部为空了,那么才可以递归去删除
import os
dir_path = "E:\小满\记录生活\二次元\琶洲漫展"
os.removedirs(dir_path) # 成功删除下面的所有文件夹
切换工作路径(相当于shell下cd)
import os
os.chdir(path)
重命名文件或者文件夹
import os
os.rename("旧名字", "新名字")
import os
dir_path = "E:\小满\记录生活\二次元\琶洲漫展"
os.chdir(dir_path)
os.rename("with_friends.jpg", "best_friends.jpg")
查看当前文件夹下的所有文件和文件夹
import os
dir_path = "E:\小满\记录生活\二次元\琶洲漫展"
os.chdir(dir_path)
os.mkdir("待整理")
elements = os.listdir(dir_path)
print(elements)
['best_friends.jpg', '待整理']
获取当前工作路径
import os
dir_path = "E:\小满\记录生活\二次元\琶洲漫展"
os.chdir(dir_path)
print(os.getcwd())
E:\小满\记录生活\二次元\琶洲漫展
运行shell命令
import os
os.system("shell命令")
import os
os.system("pip install -r requirements.txt")
将路径字符串转换为适合当前操作系统的标准化形式
注:window的是\,Linux和Mac平台是/
import os
path = "E:\小满\记录生活\二次元\琶洲漫展"
new_path = os.path.join(path, "待整理/王者荣耀区/被偷拍了.jpg")
print(new_path)
E:\小满\记录生活\二次元\琶洲漫展\待整理/王者荣耀区/被偷拍了.jpg
rel_path = os.path.normcase(new_path)
print(rel_path)
e:\小满\记录生活\二次元\琶洲漫展\待整理\王者荣耀区\被偷拍了.jpg
递归遍历指定目录以及下面的全部文件夹
import os
path = "E:\\小满"
for root, dirs, files in os.walk(path):
print(f"当前目录:{root}")
print(f"子目录:{dirs}")
print(f"文件列表:{files}")
print("------------------------------------")
当前目录:E:\小满
子目录:['记录生活']
文件列表:[]
------------------------------------
当前目录:E:\小满\记录生活
子目录:['二次元']
文件列表:[]
------------------------------------
当前目录:E:\小满\记录生活\二次元
子目录:['琶洲漫展']
文件列表:[]
------------------------------------
当前目录:E:\小满\记录生活\二次元\琶洲漫展
子目录:['待整理']
文件列表:['best_friends.jpg']
------------------------------------
当前目录:E:\小满\记录生活\二次元\琶洲漫展\待整理
子目录:[]
文件列表:[]
------------------------------------
shutil模块
shutil可以简单地理解为sh + util,shell工具的意思。shutil模块是对os模块的补充,主要针对文件的拷贝、删除、移动、压缩和解压操作。
无法拷贝文件的元数据
可以理解为鼠标右键查看文件详细信息的数据
shutil模块的主要方法
# 单独复制过去,不修改名称
shutil.copy('小满.txt', "..\")
# 复制过去,并且使用新名字
# 注意:如果对象路径有同名文件,会直接覆盖
shutil.copy('小满.txt', "..\我才是小满.txt")
# copy2同copy
# 不同的是copy2同时复制文件的内容以及文件的所有状态信息。
shutil.copy2('小满.txt', "我才是小满.txt")
# 递归地移动文件或者文件夹,移动过去的时候,目标路径一定要没有该文件夹,不然会报错。
# 需要注意的是,使用move方法无法跨磁盘移动数据,如果要跨磁盘操作,请使用copy方法
shutil.move('小满.txt', "王昭君.txt")
# 复制文件夹,以及包括它内部的文件夹以及文件,复制过去的时候,目标路径一定要没有改文件夹,不然会报错。
shutil.copytree("D:\\DB", "E:\\DB")
# 递归地删除目录及子目录内的文件。
# 注意!该方法不会询问yes或no,被删除的文件也不会出现在回收站里,请务必小心!
shutil.rmtree("DB")
# 删除文件使用os.remove("小满.txt") 就可以了
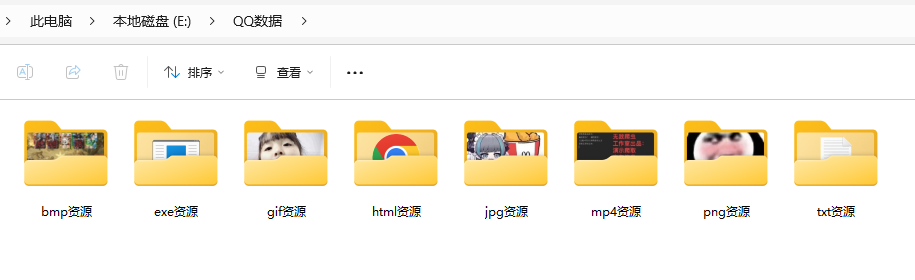
自己制作的指定文件复制小工具
功能,通过获取一个大的路径,拷贝分组文件到指定的文件夹里面,并根据后缀名分好组
欢迎复制使用,记得修改好路径哦 ~ _
import os
import time
import shutil
from functools import wraps
from pathlib import Path
def timer(func):
@wraps(func)
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
print(f"\n已完成!共耗时:{end_time - start_time}秒!")
return res
return inner
def main():
path_dict = {
"qq": {"file_path": r"C:\Users\小满\Documents\Tencent Files", "file_name": "QQ数据"},
"we_chat": {"file_path": r"C:\Users\小满\Documents\WeChat Files", "file_name": "微信数据"},
}
print("选择需要提取的数据".center(40, "-"))
user_input = input("【1】qq数据\n【2】微信数据\n >>>> ").strip()
choice = "qq" if user_input == "1" else "we_chat"
file_path = path_dict[choice]['file_path']
file_name = path_dict[choice]["file_name"]
move_file(file_path, file_name)
@timer
def move_file(base_path, file_name):
path = Path.cwd().parent / file_name
path.mkdir(exist_ok=True)
need_list = ['html', "jpg", "png", "gif", "bmp", "mp4", "md", "txt", "exe"]
for root, dirs, files in os.walk(base_path):
try:
for file in files:
fullpath = os.path.join(root, file)
path_obj = Path(fullpath)
name = path_obj.suffix.split(".")[-1] # 获取文件后缀名
if name in need_list:
rel_name = name + "资源"
dir_path = path / rel_name
if not dir_path.exists():
dir_path.mkdir(parents=True, exist_ok=True)
print(f"\r正在将文件【{file}】, 移动到【{dir_path}】", end="")
shutil.copy2(fullpath, dir_path)
except:
continue
if __name__ == '__main__':
main()
json模块
什么是序列化 & 反序列化
内存中的数据类型---->序列化---->特定的格式(json或者pickle格式)
内存中的格式<----反序列化<----特定的格式(json或者pickle格式)
土办法:
{"aaa":111}---->序列化str({"aaa":111})---->'{"aaa":111}'
{"aaa":111}<----反序列化eval('{"aaa":111}')<----'{"aaa":111}'
为何要序列化
序列化得到结果 ===> 特定的格式的内容有两种用途
1. 可以用于存储===>用于存档
2. 传输给其他平台使用===>跨平台数据交互
eg:
python dart
列表 特定的格式 数组
强调:
针对用途1的特定格式:可以是一种专用的格式===> pickle 只有python可以识别
针对用途2的特定格式:应该是一种通用,能够被所有语言识别的格式===>json
类型转换
将数据从Python转换到json格式,在数据类型上会有变化,如下表所示:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
反过来,从json格式转化为Python内置类型,见下表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
dumps方法
数据序列化
import json
data = [1, "2", '小满', True, False]
json_data = json.dumps(data)
print(json_data, type(json_data))
[1, "2", "\u5c0f\u6ee1", true, false] <class 'str'>
啊嘞?这些奇怪的符号是什么鬼!!!
在 Python 的 json 模块中,ensure_ascii 是一个可选参数,用于控制是否将非 ASCII 字符转义为 Unicode 转义序列。
当 ensure_ascii 设置为 True(默认值)时,json 模块会将所有非 ASCII 字符(例如特殊字符、Unicode 字符)转义为类似 \uXXXX 的 Unicode 转义序列。这样做是为了确保 JSON 字符串中只包含 ASCII 字符,因为在某些情况下,一些系统或应用程序可能只支持 ASCII 字符。
当 ensure_ascii 设置为 False 时,json 模块会保留非 ASCII 字符,不进行转义。这样可以在 JSON 字符串中包含非 ASCII 字符,以支持更广泛的字符集。
搞定啦!!
import json
data = [1, "2", '小满', True, False]
json_data = json.dumps(data, ensure_ascii=False) # 这里设置为False就好了
print(json_data)
[1, "2", "小满", true, false]
注意点:
1. 布尔类型会变成小写
2. 单引号会变成双引号
loads方法
反序列化
import json
data = [1, "2", '小满', True, False]
json_data = json.dumps(data, ensure_ascii=False)
ls = json.loads(json_data)
print(ls, type(ls))
[1, '2', '小满', True, False] <class 'list'>
dump方法
序列化到文件
import json
data = [1, "2", '小满', True, False]
with open("data.json", "w", encoding="utf-8") as file:
# data正常的数据
# file文件的句柄
# ensure_ascii=False 保留非 ASCII 字符,不进行转义
json.dump(data, file, ensure_ascii=False)
load方法
从文件反序列化
import json
with open("data.json", encoding="utf-8") as file:
data = json.load(file)
print(data) # [1, '2', '小满', True, False]
补充:
josn模块使用dump写入文件的时候,基本都是使用w模式,不会使用a模式。
json格式里面一般是双引号,不是单引号。
hashlib模块
注:hash算法不算加密算法
Hash,译做“散列”,也有直接音译为“哈希”的。把任意长度的输入,通过某种hash算法,变换成固定长度的输出,该输出就是散列值,也称摘要值。该算法就是哈希函数,也称摘要函数。
hash加密的特点
- 只要加密的内容是一样的,密文肯定一样。
- 不可逆,无法通过密文找到原始数据
- 长度固定,不论加密多长的数据,密文的长度是固定的
加密详解
一言以蔽之:加密逻辑完全一样
注意点:update()方法现在只接受bytes类型的数据,不接收str类型。
import hashlib
# sha1加密
def sha1_encryption(text):
sha1 = hashlib.sha1() # 创建sha1对象
bytes_text = text.encode("utf-8") # 加密数据 update里面必须是一个二进制数据
sha1.update(bytes_text)
return sha1.hexdigest() # 获取加密后的值
# sha1加密(加盐)
def sha1_encryption_with_salt(text, salt):
sha1 = hashlib.sha1()
content = text + salt
bytes_text = content.encode("utf-8")
sha1.update(bytes_text)
return sha1.hexdigest()
# sha224加密
def sha224_encryption(text):
sha224 = hashlib.sha224()
bytes_text = text.encode("utf-8")
sha224.update(bytes_text)
return sha224.hexdigest()
# sha224加密(加盐)
def sha224_encryption_with_salt(text, salt):
sha224 = hashlib.sha224()
content = text + salt
bytes_text = content.encode("utf-8")
sha224.update(bytes_text)
return sha224.hexdigest()
# sha256加密
def sha256_encryption(text):
sha256 = hashlib.sha256()
bytes_text = text.encode("utf-8")
sha256.update(bytes_text)
return sha256.hexdigest()
# sha256加密(加盐)
def sha256_encryption_with_salt(text, salt):
sha256 = hashlib.sha256()
content = text + salt
bytes_text = content.encode("utf-8")
sha256.update(bytes_text)
return sha256.hexdigest()
# sha384加密
def sha384_encryption(text):
sha384 = hashlib.sha384()
bytes_text = text.encode("utf-8")
sha384.update(bytes_text)
return sha384.hexdigest()
# sha384加密(加盐)
def sha384_encryption_with_salt(text, salt):
sha384 = hashlib.sha384()
content = text + salt
bytes_text = content.encode("utf-8")
sha384.update(bytes_text)
return sha384.hexdigest()
# sha512加密
def sha512_encryption(text):
sha512 = hashlib.sha512()
bytes_text = text.encode("utf-8")
sha512.update(bytes_text)
return sha512.hexdigest()
# sha512加密(加盐)
def sha512_encryption_with_salt(text, salt):
sha512 = hashlib.sha512()
content = text + salt
bytes_text = content.encode("utf-8")
sha512.update(bytes_text)
return sha512.hexdigest()
# md5加密
def md5_encryption(text):
md5 = hashlib.md5()
bytes_text = text.encode("utf-8")
md5.update(bytes_text)
return md5.hexdigest()
# md5加密(加盐)
def md5_encryption_with_salt(text, salt):
md5 = hashlib.md5()
content = text + salt
bytes_text = content.encode("utf-8")
md5.update(bytes_text)
return md5.hexdigest()
function_list = [
{"name": sha1_encryption, "params": {"text": "小满"}, "type": "sha1加密"},
{"name": sha1_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "sha1加密(加盐)"},
{"name": sha224_encryption, "params": {"text": "小满"}, "type": "sha224加密"},
{"name": sha224_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "sha224加密(加盐)"},
{"name": sha256_encryption, "params": {"text": "小满"}, "type": "sha256加密"},
{"name": sha256_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "sha256加密(加盐)"},
{"name": sha384_encryption, "params": {"text": "小满"}, "type": "sha384加密"},
{"name": sha384_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "sha384加密(加盐)"},
{"name": sha512_encryption, "params": {"text": "小满"}, "type": "sha512加密"},
{"name": sha512_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "sha512加密(加盐)"},
{"name": md5_encryption, "params": {"text": "小满"}, "type": "md5加密"},
{"name": md5_encryption_with_salt, "params": {"text": "小满", "salt": "最棒啦"}, "type": "md5加密(加盐)"},
]
for item in function_list:
func = item['name']
params = item['params']
encryption_type = item['type']
result = func(**params)
if index % 2 == 0:
print()
print(f"{encryption_type}的结果:{result} 长度为:{len(result)}")
sha1加密的结果:7fd75cfe6216a504ce08a251f3655d7a375b3df5 长度为:40
sha1加密(加盐)的结果:f63a49b6a7eee19b654e8875c5bdfeb4e272cab7 长度为:40
sha224加密的结果:1ff5288a95fc679636b47b11e5309f88c1a25969a3ab9b1471f3269b 长度为:56
sha224加密(加盐)的结果:1a78a70595912e5216f4527a21ff600a30fc580052710c9160245385 长度为:56
sha256加密的结果:a18e1d5053a25b6681786b6d32310423a20c1eb0854a855013ec0241dd6790be 长度为:64
sha256加密(加盐)的结果:9344e57ce2ba9e63752ce4be684bf5f0e5a35a31a615628a49d491948394e144 长度为:64
sha384加密的结果:a07af984d0cf8ae3ddf059260e3e1f017f0964118116b364f3bb9c234f9f72cc4c721c62ae3970091fa56438148ca7fa 长度为:96
sha384加密(加盐)的结果:567a74b8b717df273394cabf4fe9b4f9126f5d423c380aeb33ad3aa68d60efed94bdb60432fc43a1d602d2de8311e3eb 长度为:96
sha512加密的结果:b41e63b8b942985ea0a4fc9222ffc3af23ba4ea6e9a6a9b4f38ad9996673fbcf6af0f5433f4280b96ef9c7e9ec0601fc2511e73c2e3df35a7b4312f04c1b876b 长度为:128
sha512加密(加盐)的结果:dcd8d9575c30f5766a47c4627b333ce8ce6352bf6339abf43bf7514248b044e31ee906b9538773811dae3d6d8e384882efc13035b458e2aff4d3daa32fa2c80b 长度为:128
md5加密的结果:2cb8e740ec7ba006709eea6adbf8da23 长度为:32
md5加密(加盐)的结果:f080e64ad226718bbdde5a850aeef20e 长度为:32
Process finished with exit code 0
更简单的方法:
import hashlib
sha1 = hashlib.sha1("小满".encode("utf-8")).hexdigest()
sha224 = hashlib.sha224("小满".encode("utf-8")).hexdigest()
sha256 = hashlib.sha256("小满".encode("utf-8")).hexdigest()
sha384 = hashlib.sha384("小满".encode("utf-8")).hexdigest()
sha512 = hashlib.sha512("小满".encode("utf-8")).hexdigest()
md5 = hashlib.md5("小满".encode("utf-8")).hexdigest()
print(sha1, sha224, sha256, sha384, sha512, md5, sep="\n")
结果略。。。
import hashlib
def md5_encryption(text):
return hashlib.md5(text.encode("utf-8")).hexdigest()
print(md5_encryption("小满")) # 2cb8e740ec7ba006709eea6adbf8da23
一个通用的构造方法,name是某个算法的字符串名称,data是可选的bytes类型待摘要的数据。
import hashlib
md5_encryption = hashlib.new("md5", "小满".encode("utf-8")).hexdigest()
print(md5_encryption) # 2cb8e740ec7ba006709eea6adbf8da23
优化一下
import hashlib
def encryption(func_name, text="小满"):
return hashlib.new(func_name, text.encode("utf-8")).hexdigest()
func_name_list = ['sha1', "sha224", "sha256", "sha384", "sha512", "md5"]
for fun_name in func_name_list:
print(f"{fun_name} --> {encryption(fun_name)}")
结果略。。。
撞库
通俗一点讲,“撞库”就是黑客通过收集互联网上用户的账号和密码信息,生成对应的字典表,再尝试批量登录其他网站。以“撞运气”的形式“试”出可登录的用户名、密码。
尝试解决撞库的方案(加盐)
要在使用 Python 的 MD5 哈希函数时加盐,你可以将盐值与要哈希的数据连接在一起,然后再进行哈希运算。这样可以增加哈希的安全性,使其更难以破解。
import json
import random
import string
import hashlib
def run():
def hash_with_salt(text, salt):
content = text + salt
return hashlib.new("md5", content.encode("utf-8")).hexdigest()
def get_user_input():
username = input("输入账号:").strip()
password = input("输入密码:").strip()
return username, password
def save(data):
with open("user_pwd.json", "w", encoding="utf-8") as file:
json.dump(data, file, ensure_ascii=False)
# 随机生成4位验证码
def symbol_code(number=4):
text = string.ascii_letters + string.digits
symbol = "".join(random.sample(text, number))
return symbol
def register():
username, password = get_user_input()
symbol = symbol_code()
symbol_input = input(f"输入您看到的验证码 ->> {symbol} <<- :").strip()
if symbol_input.casefold() == symbol.casefold():
print(f"用户[{username}]已成功注册")
rel_password = hash_with_salt(username, symbol)
data = {username: {"username": username, "password": rel_password, "salt": symbol}}
save(data)
else:
print("验证码不对")
def login():
username, password = get_user_input()
with open("user_pwd.json", encoding="utf-8") as file:
user_data = json.load(file)
salt = user_data.get(username).get("salt")
rel_username = user_data.get(username).get("username")
rel_password = user_data.get(username).get("password")
new_password = hash_with_salt(username, salt)
if username == rel_username and new_password == rel_password:
print(f"用户[{username}]登录成功")
else:
print("登录失败")
register()
login()
if __name__ == "__main__":
run()
输入账号: 小满
输入密码: 3
输入您看到的验证码 ->> 4osh <<- : 4osh
用户[小满]已成功注册
输入账号: 小满
输入密码: 3
用户[小满]登录成功
本地json文件
{"小满": {"username": "小满", "password": "b338fc469557472904ba8ef75c681d7d", "salt": "4osh"}}
时间模块
time模块
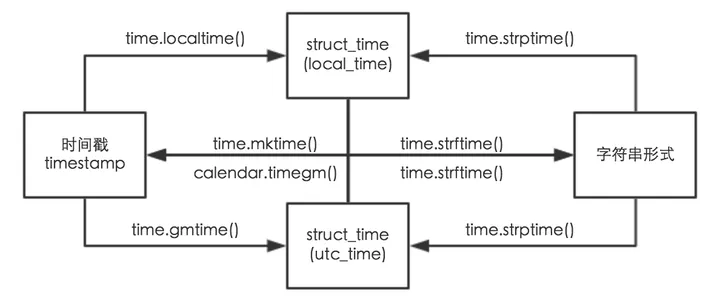
时间戳:从1970年到现在经过的秒数。作用:用于时间间隔的计算。
import time
time.time()
1702811565.8955057
格式化的时间字符串
import time
now = time.strftime("%Y年%m月%d日 %H时%M分%S秒")
print(now) # 2023年12月17日 19时13分44秒
now = time.strftime("%x %X")
print(now) # 12/17/23 19:14:04
lctime = time.localtime()
now = time.strftime("%x %X", lctime)
now # 12/17/23 19:14:16
结构化的时间
import time
lctime = time.localtime() # 本地时区的struct_time
print(lctime)
time.struct_time(tm_year=2023, tm_mon=12, tm_mday=17, tm_hour=19, tm_min=16, tm_sec=35, tm_wday=6, tm_yday=351, tm_isdst=0)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2023 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 61 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周日) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
import time
gmtime = time.gmtime() # UTC时区的struct_time UTC(协调世界时)是一种标准的时间参考,它与时区无关,表示全球统一的时间。
print(gmtime)
time.struct_time(tm_year=2023, tm_mon=12, tm_mday=17, tm_hour=11, tm_min=32, tm_sec=41, tm_wday=6, tm_yday=351, tm_isdst=0)
将格式化的字符串时间按照模板转化成结构化时间
语法:time.strptime(string, format)
string = "2023-12-7 19-42-09"
lctime = time.strptime(string, "%Y-%m-%d %H-%M-%S")
print(lctime)
time.struct_time(tm_year=2023, tm_mon=12, tm_mday=7, tm_hour=19, tm_min=42, tm_sec=9, tm_wday=3, tm_yday=341, tm_isdst=-1)
转换规律
字符串时间 ----> struct_time ----> 时间戳
string = "2023-12-7 19-42-09"
lctime = time.strptime(string, "%Y-%m-%d %H-%M-%S")
t = time.mktime(lctime)
print(t) # 1701949329.0
时间戳 ----> struct_time ----> 字符串时间
lctime = time.localtime(t)
now = time.strftime("%x %X", lctime)
print(now) # 12/17/23 19:50:50
奇怪的知识增加了
time.asctime() 同 time.ctime()
t1 = time.asctime() # Sun Dec 17 19:51:21 2023
t2 = time.ctime() # Sun Dec 17 19:51:21 2023
注:图片来源于知乎 友情链接
datetime模块
import time
import datetime
print(datetime.datetime.now())
2023-12-17 20:03:24.682513
print(datetime.datetime.utcnow())
2023-12-17 12:02:19.587722
t = time.time()
print(datetime.datetime.fromtimestamp(t))
2023-12-17 20:03:26.793521
now = datetime.datetime.now()
print(now)
2023-12-17 20:04:57.955645
print(now + datetime.timedelta(3)) # 当前时间+3天
2023-12-20 20:04:57.955645
print(now + datetime.timedelta(-3)) # 当前时间-3天
2023-12-14 20:04:57.955645
print(now + datetime.timedelta(days=-3)) # 当前时间-3天
2023-12-14 20:04:57.955645
print(now + datetime.timedelta(minutes=30)) # 当前时间+30分钟
2023-12-17 20:34:57.955645
print(now + datetime.timedelta(hours=2)) # 当前时间+2小时
2023-12-17 22:04:57.955645
subprocess模块
引入
subprocess模块主要用于创建子进程,并连接它们的输入、输出和错误管道,获取它们的返回状态。通俗地说就是通过这个模块,你可以在Python的代码里执行操作系统级别的命令,比如“ipconfig”、“du -sh”等等。subprocess模块替代了一些老的模块和函数,比如:
os.system()
subprocess过去版本中的call(),check_call()和check_output()已经被run()方法取代了。run()方法为3.5版本新增。
大多数情况下,推荐使用run()方法调用子进程,执行操作系统命令。
subprocess.run()
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False, encoding=None, errors=None)
args:表示要执行的命令。必须是一个字符串,字符串参数列表。
timeout:设置命令超时时间。如果命令执行时间超时,子进程将被杀死,并弹出TimeoutExpired异常。
check:如果该参数设置为True,并且进程退出状态码不是0,则弹出CalledProcessError异常。
- 注:0表示正常退出
encoding:如果指定了该参数,则stdin、stdout和stderr可以接收字符串数据,并以该编码方式编码。否则只接收bytes类型的数据。
shell:如果该参数为True,将通过操作系统的shell执行指定的命令。
- 在一般情况下Windows系统需要将shell设置为True
- args参数可以接收一个类似
'du -sh'的字符串,也可以传递一个类似['du', '-sh']的字符串分割列表。shell参数默认为False,设置为True的时候表示使用操作系统的shell执行命令。
一般如果args参数是一个字符串,需要指定shell=True,如果是一个列表则不需要。
import subprocess
subprocess.run("dir /w", shell=True) # 通过字符操作
subprocess.run(["dir"/ "/w"]) # 通过列表取操作
两种方法都可以,结合实际情况取使用就可以了
注意,run()方法返回的不是我们想要的执行结果或相关信息,而是一个CompletedProcess类型对象。
import subprocess
subprocess.run("dir /w", cwd="D:\\", shell=True) # cwd用于指定路径,如果不设置默认是程序执行的路径为准。

import subprocess
subprocess.run("dir /w", shell=True)
获取执行的结果
在默认的情况下,run()方法返回的是一个CompletedProcess类型对象,不能直接获取我们通常想要的结果。要获取命令执行的结果或者信息,在调用run()方法的时候,请指定stdout=subprocess.PIPE
subprocess.PIPE
管道,可传递给stdout、stdin和stderr参数。
stout,输出到屏幕
stdin,输入
stderr,输出错误到屏幕
import subprocess
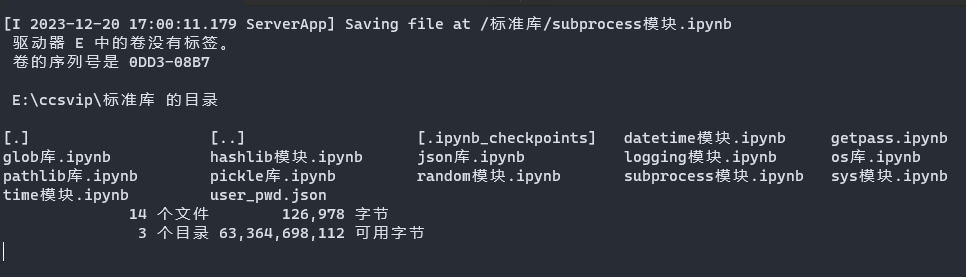
r = subprocess.run("dir /w", shell=True, stdout=subprocess.PIPE)
print(r.stdout) # 二进制数据
b' \xc7\xfd\xb6\xaf\xc6\xf7 E \xd6\xd0\xb5\xc4\xbe\xed\xc3\xbb\xd3\xd0\xb1\xea\xc7\xa9\xa1\xa3\r\n \xbe\xed\xb5\xc4\xd0\xf2\xc1\xd0\xba\xc5\xca\xc7 0DD3-08B7\r\n\r\n E:\\ccsvip\\\xb1\xea\xd7\xbc\xbf\xe2 \xb5\xc4\xc4\xbf\xc2\xbc\r\n\r\n[.] [..] [.ipynb_checkpoints]\r\ndatetime\xc4\xa3\xbf\xe9.ipynb getpass.ipynb glob\xbf\xe2.ipynb\r\nhashlib\xc4\xa3\xbf\xe9.ipynb json\xbf\xe2.ipynb logging\xc4\xa3\xbf\xe9.ipynb\r\nos\xbf\xe2.ipynb pathlib\xbf\xe2.ipynb pickle\xbf\xe2.ipynb\r\nrandom\xc4\xa3\xbf\xe9.ipynb subprocess\xc4\xa3\xbf\xe9.ipynb sys\xc4\xa3\xbf\xe9.ipynb\r\ntime\xc4\xa3\xbf\xe9.ipynb user_pwd.json \r\n 14 \xb8\xf6\xce\xc4\xbc\xfe 128,476 \xd7\xd6\xbd\xda\r\n 3 \xb8\xf6\xc4\xbf\xc2\xbc 63,364,169,728 \xbf\xc9\xd3\xc3\xd7\xd6\xbd\xda\r\n'
上面的结果是因为没有设置encoding,window的终端默认编码为gbk
import subprocess
r = subprocess.run("dir /w", shell=True, stdout=subprocess.PIPE, encoding="gbk")
print(r.stdout)
驱动器 E 中的卷没有标签。
卷的序列号是 0DD3-08B7
E:\ccsvip\标准库 的目录
[.] [..] [.ipynb_checkpoints]
datetime模块.ipynb getpass.ipynb glob库.ipynb
hashlib模块.ipynb json库.ipynb logging模块.ipynb
os库.ipynb pathlib库.ipynb pickle库.ipynb
random模块.ipynb subprocess模块.ipynb sys模块.ipynb
time模块.ipynb user_pwd.json
14 个文件 129,539 字节
3 个目录 63,364,169,728 可用字节
获取到stdout之后,也可以写入到文件
import subprocess
data = subprocess.run("pip list", shell=True, stdout=subprocess.PIPE, encoding="utf-8")
requriments = data.stdout
with open("requriements.txt", "w", encoding="utf-8") as file:
file.write(requriments)
或者直接使用shell命令写入文件
subprocess.run("pip freeze > requriments.txt", shell=True)
获取错误的演示
注:我的电脑没有F盘
data = subprocess.run("cd F:", shell=True, stderr=subprocess.PIPE, encoding="gbk")
print(data.stderr)
系统找不到指定的驱动器。
一样可以写入到文件里面
import subprocess
data = subprocess.run("cd F:", shell=True, stderr=subprocess.PIPE, encoding="gbk")
with open("错误原因.txt", "w", encoding="utf-8") as file:
file.write(data.stderr)
math模块
import math
math.ceil(4.1) # 向上取整
5
math.floor(4.8) # 向下取整
4
math.sqrt(36) # 取平方根
6.0
math.pi # 数字常数
3.141592653589793
math.e # 数字常数
2.718281828459045
math.fabs(-24) # 取绝对值
24.0
math.factorial(5) # 将 n 的阶乘作为整数返回。 如果 n 不是正数或为负值则会引发 ValueError 1*2*3*4*5
120
math.gcd(27, 18, 12) # 一个序列中的最大公约数
3
math.perm(4) # 和阶乘差不多
24
#计算输入的 iterable 中所有元素的积。 积的默认 start 值为 1。
# 当可迭代对象为空时,返回起始值。 此函数特别针对数字值使用,并会拒绝非数字类型。
numbers = [1, 2, 5, 10] # 1*2*5*10
math.prod(numbers)
100
math.pow(2, 3) # 返回 x 的 y 次幂
8.0
logging模块
日志级别(从低到高)
| 级别 | 级别数值 | 使用时机 |
|---|---|---|
| DEBUG | 10 | 调用详细信息(常用于调试) |
| INFO | 20 | 程序正常运行过程中产生的一些信息 |
| WARNING | 30 | 警告用户,提示风险(虽然程序还在正常工作,但有可能发生错误) |
| ERROR | 40 | 运行错误,部分异常(由于更严重的错误,程序已不能执行一些功能了) |
| CRITICAL | 50 | 严重错误,程序终止(程序已经无法正常运行) |
默认级别是WARNING,表示只有WARING和比WARNING更严重的事件才会被记录到日志内,低级别的信息会被忽略。因此,默认情况下,DEBUG和INFO会被忽略,WARING、ERROR和CRITICAL会被记录。
简单演示
在什么都不配置和设定的情况下,logging会简单地将日志打印在显示器上,如下例所示:
import logging
logging.warning('Watch out!') # 消息会被打印到控制台上
logging.info('I told you so') # 这行不会被打印,因为级别低于默认级别
操作流程(五个步骤)
- 创建记录器
getLogger - 添加格式化
Formatter - 创建处理器
- 设置级别
- 设置格式
- 添加处理器
addHandler
- 输出日志
logger.log
正常日志:打印到控制台
import logging
logger = logging.getLogger(__name__) # 创建一个logger实例,使用当前模块的名称作为logger的名称
# 添加格式化
formatter = logging.Formatter("%(asctime)s [%(levelname)s] %(message)s") # 设置日志的格式
stream_handler = logging.StreamHandler() # 创建一个流处理程序,将日志输出到控制台
stream_handler.setFormatter(formatter) # 设置流处理程序的格式化器为上面定义的格式化器
stream_handler.setLevel(logging.INFO) # 设置流处理程序的日志级别为INFO,只输出INFO级别及以上的日志
logger.addHandler(stream_handler) # 将流处理程序添加到logger实例中
logger.debug("这是一条简单的DEBUG日志") # 记录DEBUG级别的日志
logger.info("这是一条正常的INFO日志") # 记录INFO级别的日志
logger.warning("这是一条WARNING警告日志") # 记录WARNING级别的日志
logger.error("这是一条ERROR错误日志") # 记录ERROR级别的日志
logger.critical("这是一条严重错误的CRITICAL日志") # 记录CRITICAL级别的日志
正常日志(使用rich美化)
import logging
from rich.logging import RichHandler
logger = logging.getLogger(__name__) # 创建一个logger实例,使用当前模块的名称作为logger的名称
# 添加格式化
formatter = logging.Formatter("%(asctime)s [%(levelname)s] %(message)s") # 设置日志的格式
handler = RichHandler() # 创建一个RichHandler处理程序,用于丰富化日志的输出
handler.setFormatter(formatter) # 设置处理程序的格式化器为上面定义的格式化器
handler.setLevel(logging.INFO) # 设置处理程序的日志级别为INFO,只记录INFO级别及以上的日志
logger.addHandler(handler) # 将处理程序添加到logger实例中
logger.debug("这是一条简单的DEBUG日志") # 记录DEBUG级别的日志
logger.info("这是一条正常的INFO日志") # 记录INFO级别的日志
logger.warning("这是一条WARNING警告日志") # 记录WARNING级别的日志
logger.error("这是一条ERROR错误日志") # 记录ERROR级别的日志
logger.critical("这是一条严重错误的CRITICAL日志") # 记录CRITICAL级别的日志
正常日志:写入到文件里面
import logging
logger = logging.getLogger(__name__) # 创建一个logger实例,使用当前模块的名称作为logger的名称
# 添加格式化
formatter = logging.Formatter("%(asctime)s [%(levelname)s] %(message)s") # 设置日志的格式
file_handler = logging.FileHandler("test.log", "a", encoding="utf-8") # 创建一个文件处理程序,将日志写入test.log文件,以追加模式打开
file_handler.setFormatter(formatter) # 设置文件处理程序的格式化器为上面定义的格式化器
file_handler.setLevel(logging.INFO) # 设置文件处理程序的日志级别为INFO,只记录INFO级别及以上的日志
logger.addHandler(file_handler) # 将文件处理程序添加到logger实例中
logger.debug("这是一条简单的DEBUG日志") # 记录DEBUG级别的日志
logger.info("这是一条正常的INFO日志") # 记录INFO级别的日志
logger.warning("这是一条WARNING警告日志") # 记录WARNING级别的日志
logger.error("这是一条ERROR错误日志") # 记录ERROR级别的日志
logger.critical("这是一条严重错误的CRITICAL日志") # 记录CRITICAL级别的日志
自用打印语法
import logging
logging.basicConfig(format="【%(levelname)s】%(asctime)s 系统警告:%(message)s", datefmt="%x %X %p", encoding="utf-8")
try:
password = input("请输入密码:")
assert password.isdigit() and len(password) == 6, "密码只能是6位纯数字!"
except Exception as e:
logging.warning(e)
else:
print("登录成功")
禁止日志输出到屏幕
# 禁用默认的日志处理器,以防止日志消息打印到屏幕上
logger.propagate = False
防止日志重复记录
# 添加下面一句,在记录日志之后移除句柄,防止日志重复记录
file_logger.removeHandler(file_handler)
sys模块
sys模块主要是针对与Python解释器相关的变量和方法,不是主机操作系统。
| 属性及方法 | 使用说明 |
|---|---|
| sys.argv | 获取命令行参数列表,第一个元素是程序本身 |
| sys.exit(n) | 退出Python程序,exit(0)表示正常退出。当参数非0时,会引发一个SystemExit异常,可以在程序中捕获该异常 |
| sys.version | 获取Python解释程器的版本信息 |
| sys.maxsize | 最大的Int值,64位平台是2**63 - 1 |
| sys.path | 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 |
| sys.platform | 返回操作系统平台名称 |
| sys.stdin | 输入相关 |
| sys.stdout | 输出相关 |
| sys.stderr | 错误相关 |
| sys.exc_info() | 返回异常信息三元元组 |
| sys.getdefaultencoding() | 获取系统当前编码,默认为utf-8 |
| sys.setdefaultencoding() | 设置系统的默认编码 |
| sys.getfilesystemencoding() | 获取文件系统使用编码方式,默认是utf-8 |
| sys.modules | 以字典的形式返回所有当前Python环境中已经导入的模块 |
| sys.builtin_module_names | 返回一个列表,包含所有已经编译到Python解释器里的模块的名字 |
| sys.copyright | 当前Python的版权信息 |
| sys.flags | 命令行标识状态信息列表。只读。 |
| sys.getrefcount(object) | 返回对象的引用数量 |
| sys.getrecursionlimit() | 返回Python最大递归深度,默认1000 |
| sys.getsizeof(object[, default]) | 返回对象的大小 |
| sys.getswitchinterval() | 返回线程切换时间间隔,默认0.005秒 |
| sys.setswitchinterval(interval) | 设置线程切换的时间间隔,单位秒 |
| sys.getwindowsversion() | 返回当前windwos系统的版本信息 |
| sys.hash_info | 返回Python默认的哈希方法的参数 |
| sys.implementation | 当前正在运行的Python解释器的具体实现,比如CPython |
| sys.thread_info | 当前线程信息 |
sys.argv
sys.argv是一个脚本执行参数列表,列表的第一个元素是脚本名称,从第二个元素开始才是真正的参数。
demo.py
import sys
for index, arg in enumerate(sys.argv):
print(f"第 {index} 个参数是 {arg}")
在终端运行 py demo.py的 结果
py .\demo.py 小满 小乔 大乔
第 0 个参数是 .\demo.py
第 1 个参数是 小满
第 2 个参数是 小乔
第 3 个参数是 大乔
sys.getrefcount(object)
我们都知道Python有自动的垃圾回收机制,让我们不用费力去进行内存管理。那么Python怎么知道一个对象可以被当做垃圾回收呢?Python使用‘引用计数’的方式,追踪每个对象 的引用次数,每对这个对象的一次引用,这个计数就加一,每删除一个该对象的引用,这个计数就减一。当引用为0的时候,就表示没有任何变量指向这个对象,那么就可以回收这个对象,腾出它所占用的内存空间。
sys.getrefcount(object)这个方法可以返回一个对象被引用的次数。注意,这个次数默认从1开始,因为你在使用sys.getrefcount(object)方法的时候就已经引用了它一次(该引用是临时性的,调用结束后,自动解除引用。)。如果不好理解,可以简单地认为它自带被动光环:引用+1。
In [2]: import sys
In [3]: a = "我是小满"
In [4]: sys.getrefcount(a)
Out[4]: 2
In [5]: b = a
In [6]: sys.getrefcount(a)
Out[6]: 3
In [7]: c = a
In [8]: sys.getrefcount(a)
Out[8]: 4
In [9]: del c
In [10]: sys.getrefcount(a)
Out[10]: 3
In [11]: del b
In [12]: sys.getrefcount(a)
Out[12]: 2
sys.modules
sys.modules是一个Python内置的模块,它是一个字典,用于存储已经导入的模块。每当导入一个模块时,该模块的信息将被添加到sys.modules字典中,以便在后续的导入操作中可以快速地访问和重用。
以下是sys.modules的一些常见用途和特性:
- 访问已导入的模块: 通过
sys.modules字典,你可以访问已经导入的模块。例如,可以使用sys.modules['os']来访问已导入的os模块。 - 避免重复导入:
sys.modules字典可以帮助避免重复导入模块。在导入模块之前,Python会检查sys.modules字典中是否已经存在该模块的记录。如果存在,Python将直接使用已经导入的模块,而不会再次导入。 - 查看已导入的模块: 你可以使用
sys.modules.keys()方法来查看当前已导入的模块名称列表。 - 删除已导入的模块: 通过删除
sys.modules字典中的模块条目,可以从已导入的模块列表中删除模块。这可以在某些情况下用于重新加载模块或清除缓存。
需要注意的是,sys.modules字典是一个全局字典,它存储在Python解释器的内存中,并且在整个程序的执行期间都是可用的。
In [16]: sys.modules
Out[16]:
{'sys': <module 'sys' (built-in)>,
'builtins': <module 'builtins' (built-in)>,
'_frozen_importlib': <module '_frozen_importlib' (frozen)>,
'_imp': <module '_imp' (built-in)>,
'_thread': <module '_thread' (built-in)>,
'_warnings': <module '_warnings' (built-in)>
# ... 截取部分
In [20]: sys.modules.keys()
Out[20]: dict_keys(['sys', 'builtins', '_frozen_importlib', '_imp', '_thread', '_warnings', '_weakref', '_io', 'marshal', 'nt', 'winreg', '_frozen_importlib_external', 'time', 'zipimport', '_codecs', 'codecs', 'encodings.aliases', 'encodings', 'encodings.utf_8', '_codecs_cn', '_multibytecodec', 'encodings.gbk', '_signal', '_abc', 'abc', 'io', '_stat', 'stat', '_collections_abc', 'genericpath', '_winapi', 'ntpath', 'os.path', 'os', '_sitebuiltins', '_distutils_hack', 'pywin32_system32', 'pywin32_bootstrap', 'site', 'importlib._bootstrap', 'importlib._bootstrap_external', 'warnings', 'importlib', 'importlib.machinery', 'importlib._abc'
# ... 截取部分
In [22]: sys.modules.values()
Out[22]: dict_values([<module 'sys' (built-in)>, <module 'builtins' (built-in)>, <module '_frozen_importlib' (frozen)>, <module '_imp' (built-in)>, <module '_thread' (built-in)>, <module '_warnings' (built-in)>, <module '_weakref' (built-in)>, <module '_io' (built-in)>, <module 'marshal' (built-in)>, <module 'nt' (built-in)>, <module 'winreg' (built-in)>, <module '_frozen_importlib_external' (frozen)>, <module 'time' (built-in)>, <module 'zipimport' (frozen)>, <module '_codecs' (built-in)>, <module 'codecs' from 'C:\\Users\\chuxu\\AppData\\Local\\Programs\\Python\\Python310\\lib\\codecs.py'>, <module 'encodings.aliases'
# ... 截取部分
sys.builtin_module_names
sys.builtin_module_names是一个字符串元组,包含了所有已经编译在Python解释器内的模块名称。
import sys
def find_modules(module=None):
if module in sys.builtin_module_names:
print(f"{module}模块内置于 __builtin__ ")
else:
print(f"{module}模块位于 {__import__(module).__file__}")
find_modules("os")
find_modules("lxml")
find_modules("time")
os模块位于 C:\xxxx\Python310\lib\os.py
lxml模块位于 C:\xxxx\Python310\lib\site-packages\lxml\__init__.py
time模块内置于 __builtin__
sys.path
path是一个目录列表,供Python从中查找模块。在Python启动时,sys.path根据内建规则和PYTHONPATH变量进行初始化。sys.path的第一个元素通常是个空字符串,表示当前目录。
支持增删改查,不过一般是往里面添加需要操作的路径,删除请谨慎
添加方法
import sys
from pathlib import Path
pathList = sys.path
new_path = Path.cwd() / "IMG/小满/漫展"
Path.mkdir(new_path, parents=True, exist_ok=True) # 递归创建文件夹
sys.path.insert(0, new_path.__str__())
print(sys.path)
['E:\\初窥门径\\IMG\\小满\\漫展', "其他路径已省略..."]
sys.platform
获取当前执行环境的平台名称,不同的平台返回值如下表所示:
| 操作系统 | 返回值 |
|---|---|
| Linux | 'linux' |
| Windows | 'win32' |
| Windows/Cygwin | 'cygwin' |
| Mac OS X | 'darwin' |
sys.stdin、sys.stdout、sys.stderr
sys.stdin、sys.stdout和sys.stderr是sys模块中的标准输入、标准输出和标准错误流对象。
-
sys.stdin:sys.stdin是一个类文件对象,表示程序的标准输入流。它通常用于从用户或其他程序读取输入。你可以使用sys.stdin.readline()方法读取一行输入,或者使用迭代器的方式逐行读取输入。 -
sys.stdout:sys.stdout是一个类文件对象,表示程序的标准输出流。它通常用于向屏幕或其他输出设备打印输出。你可以使用print()函数将内容打印到sys.stdout,或者使用sys.stdout.write()方法直接写入文本。 -
sys.stderr:sys.stderr是一个类文件对象,表示程序的标准错误流。与sys.stdout类似,它通常用于向屏幕或其他输出设备打印错误消息和异常信息。Python的异常信息通常会被打印到sys.stderr中。
这些对象在Python的命令行交互式环境中默认与控制台相关联。在脚本中,它们通常与终端或其他IO流进行重定向,以便将输入、输出和错误信息发送到指定的位置。
以下是一个简单的示例,展示了如何使用sys.stdin、sys.stdout和sys.stderr:
import sys
# 从标准输入读取用户输入
input_data = sys.stdin.readline()
print("输入的内容是:", input_data)
# 将输出打印到标准输出
sys.stdout.write("这是标准输出\n")
# 将错误消息打印到标准错误
sys.stderr.write("这是标准错误\n")
可以结合logging、subprocess等模块打印数据到屏幕的时候也可以使用到这几个方法。
仅做了解的模块
fileinput模块
fileinput模块用于对标准输入或多个文件进行逐行遍历。这个模块的使用非常简单,相比open()方法批量处理文件,fileinput模块可以对文件、行号进行一定的控制。
两个.txt文件的内容分别如下
千变万化,归于一心
稍微认真一点
一味趋吉避凶,心又何处安放?
武道没有定式,人生亦是如此
变则万物恒通,通则武道长存,小满独家
别羡慕,我可是凭本事摸鱼的
生于小满,小满即安
对自己严苛的人,怎么可能对他人宽容
故乡的梅花开了吗?
凛冬已至。
身躯已然冰封,灵魂仍旧火热。
白梅落下之日,归去故里之。
时美貌是种罪孽,暴雪也无法掩埋。
故乡的梅花开了吗? 替你们消消火。
寒流,无处不在。
from glob import glob
import fileinput
for line in fileinput.input(files=glob("*.txt"), encoding="utf-8"):
print(f"{line.strip()}")
千变万化,归于一心
稍微认真一点
一味趋吉避凶,心又何处安放?
武道没有定式,人生亦是如此
变则万物恒通,通则武道长存,小满独家
别羡慕,我可是凭本事摸鱼的
生于小满,小满即安
对自己严苛的人,怎么可能对他人宽容
故乡的梅花开了吗?
凛冬已至。
身躯已然冰封,灵魂仍旧火热。
白梅落下之日,归去故里之。
时美貌是种罪孽,暴雪也无法掩埋。
故乡的梅花开了吗? 替你们消消火。
寒流,无处不在。
主要属性
fileinput.filename()
返回当前正在处理的文件名(也就是包含了当前正在处理的文本行的文件)
fileinput.fileno()
返回当前文件的总行数。
fileinput.lineno()
返回当前的行数,这个行数是累计的。多个文件的行数会累加起来。
fileinput.filelineno()
返回当前正在处理的文件的当前行数。每次处理完一个文件并开始处理下一个文件时,该值会重置为1,重新开始计数。
fileinput.isfirstline()
当前行是当前文件的第一行时返回True,否则False
fileinput.isstdin()**
当前操作对象为`sys.stdin`时返回True否则False。
**fileinput.nextfile()
关闭当前的文件,跳到下一个文件,跳过的行不计数。
fileinput.close()
关闭整个文件链,结束迭代。
需求:为每一行添加一个行号并打印结果,文件也需要同步替换成行号
from glob import glob
import fileinput
for line in fileinput.input(files=glob("*.txt"), encoding="utf-8", inplace=True):
print(f"[{fileinput.lineno()}]{line.strip()}")
两个.txt最新的内容如下
[1]千变万化,归于一心
[2]稍微认真一点
[3]一味趋吉避凶,心又何处安放?
[4]武道没有定式,人生亦是如此
[5]变则万物恒通,通则武道长存,小满独家
[6]别羡慕,我可是凭本事摸鱼的
[7]生于小满,小满即安
[8]对自己严苛的人,怎么可能对他人宽容
[9]故乡的梅花开了吗?
[10]凛冬已至。
[11]身躯已然冰封,灵魂仍旧火热。
[12]白梅落下之日,归去故里之。
[13]时美貌是种罪孽,暴雪也无法掩埋。
[14]故乡的梅花开了吗? 替你们消消火。
[15]寒流,无处不在。
多文件操作案例
全部内置函数.txt的内容如下
abs()
aiter()
all()
any()
anext()
ascii()
bin()
bool()
breakpoint()
bytearray()
bytes()
callable()
chr()
classmethod()
compile()
complex()
delattr()
dict()
dir()
divmod()
enumerate()
eval()
exec()
filter()
float()
format()
frozenset()
getattr()
globals()
hasattr()
hash()
help()
hex()
id()
input()
int()
isinstance()
issubclass()
iter()
len()
list()
locals()
map()
max()
memoryview()
min()
next()
object()
oct()
open()
ord()
pow()
print()
property()
range()
repr()
reversed()
round()
set()
setattr()
slice()
sorted()
staticmethod()
str()
sum()
super()
tuple()
type()
vars()
zip()
待处理.txt的内容如下
数字的绝对值
异步迭代器
是否全为 True
是否有 True 值
异步迭代下一项
转为 ASCII 字符
转为二进制字符串
返回布尔值
设置断点
生成字节数组
生成字节序列
对象是否可调用
Unicode 字符串
方法封装成类方法
编译为代码对象
创建复数
删除对象属性
创建字典
对象的所有属性和方法
计算商和余数
添加元素索引
执行字符串表达式
执行复杂代码
元素过滤
构造浮点数对象
格式化
构建不可变集合
获取对象属性
全局变量
检测对象属性
对象的哈希值
内置帮助
16进制字符串
对象标识值
获取输入字符串
构造整数
实例类型检测
子类检测
生成迭代器
对象长度
创建列表
当前本地符号表的字典
对序列元素应用函数处理
最大元素
创建内存视图
最小元素
迭代下一项
空对象
转为八进制字符串
打开文件
Unicode 码位编号
求n次幂
打印对象内容
修饰方法
等差数列对象
打印形式字符串
序列反向迭代器
小数舍入
创建集合对象
设置对象属性
切片对象
返回已排序列表
方法转换为静态方法
对象的字符形式
求和
调用超类方法
构建元组
对象的类型
对象属性字典
同位元素对象组合
需求:将两个数据读取出来重新拼接到一起,然后写入到一个markdown文件里面
解决方案
import fileinput
files = ["全部内置函数.txt", "待处理.txt"]
input1, input2 = files
f = open("结果.md", "w", encoding="utf-8")
for f1, f2 in zip(fileinput.input(input1, encoding="utf-8"), fileinput.input(input2, encoding="utf-8")):
data = f"{f1.strip()}{f2.strip()}"
f.write("{}\n".format(data))
f.write("```python\n\n")
f.write("```\n")
f.close()
本地结果如下

成功解决问题!😎

zipfile
import zipfile
from pathlib import Path
path = Path.cwd()
zippath = "ATM.zip"
# 创建一个ZipFile对象
zip_file = zipfile.ZipFile(zippath)
# 返回ZIP文件中包含的所有文件和文件夹的字符串的列表
names = zip_file.namelist()
# 将压缩文件中的内容解压到具体的路径
zip_file.extractall(path)
print("zip finish!")
如果遇到压缩无法解压一般是有两种情况,要么是文件损害,要么是压缩文件有密码
将文件/夹压缩成zip文件并移动到指定的目录
import os
import zipfile
import shutil
new_zip = zipfile.ZipFile("小满的照片.zip", "w")
for root, dirs, files in os.walk("E:\\小满"): # 遍历需要被压缩的目录
for filename in files:
fullpath = os.path.join(root, filename)
new_zip.write(fullpath, compress_type=zipfile.ZIP_DEFLATED)
# compress_type=zipfile.ZIP_DEFLATED
# 指定压缩模式,如果不指定,则只是打包行为,并不会对数据进行压缩
new_zip.close()
shutil.move("小满的照片.zip", r"C:\Users\小满\Desktop")
getpass模块
就是输入的时候把字符转成 . 号,一般很少用到
如果是在控制台输入,会看不到密码
import getpass
username = input("输入姓名:").strip()
password = getpass.getpass("输入密码:").strip()
print(type(password))
if username.casefold() == "eva" and password == "11223344":
print("登录成功!")
else:
print("登录失败")
输入姓名: eva
输入密码: ········
<class 'str'>
登录成功!
pickle模块
pickle模块是Python专用的持久化模块,可以持久化包括自定义类在内的各种数据,比较适合Python本身复杂数据的存贮。pickle与json的操作基本一样,但是不同的是,它持久化后的字串是不可认读的,不如json的来得直观,并且只能用于Python环境,不能用作与其它语言进行数据交换,不通用。
主要方法
与json模块一模一样的方法名。但是在pickle中dumps()和loads()操作的是bytes类型,而不是json中的str类型;在使用dump()和load()读写文件时,要使用rb或wb模式,也就是只接收bytes类型的数据。
| 方法 | 功能 |
|---|---|
| pickle.dump(obj, file) | 将Python数据转换并保存到pickle格式的文件内 |
| pickle.dumps(obj) | 将Python数据转换为pickle格式的bytes字串 |
| pickle.load(file) | 从pickle格式的文件中读取数据并转换为python的类型 |
| pickle.loads(bytes_object) | 将pickle格式的bytes字串转换为python的类型 |
import pickle
hero_dict = {"name": "小满", "hobby": "摸鱼"}
pickle_data = pickle.dumps(hero_dict)
print(type(pickle_data)) # 二进制
print(pickle_data)
<class 'bytes'>
b'\x80\x04\x95&\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x06\xe5\xb0\x8f\xe6\xbb\xa1\x94\x8c\x05hobby\x94\x8c\x06\xe6\x91\xb8\xe9\xb1\xbc\x94u.'
import pickle
hero_dict = {"name": "小满", "hobby": "摸鱼"}
pickle_data = pickle.dumps(hero_dict)
foo = pickle.loads(pickle_data)
print(foo)
print(type(foo))
{'name': '小满', 'hobby': '摸鱼'}
<class 'dict'>
写入文件
import pickle
hero_dict = {"name": "小满", "hobby": "摸鱼"}
with open("hero.pickle", "wb") as file:
pickle.dump(hero_dict, file)
with open("hero.pickle", "rb") as f:
data = pickle.load(f)
print(data) # {'name': '小满', 'hobby': '摸鱼'}
[^ \f\n\r\t\v]:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号