
模块与包
模块
什么是模块?
模块就是一些列功能的集合体,通常一个py文件就是一个模块。
一个Python文件本身就是一个模块,文件名
m.py,模块名叫m
模块分为三大类
1. 内置的模块(python解释器自带的模块,直接使用)
2. 第三方的模块(python社区伙伴们开源提供的python模块,需要下载后使用)
3. 自定义的模块(定义模块指的是我们自己编写的脚本文件,文件名就是模块名,如get_sum.py,get_sum就是模块名)
模块分为四种形式
1. 使用Python编写的.py的文件
2. 已被编译为共享库或DLL的C或C++扩展
3. 把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件称之为包)
4. 使用C编写别链接到Python解释器的内置模块
为何要用模块
提高开发效率
内置与第三方的模块拿来就用,无需定义,这种拿来主义,可以极大地提升自己的开发效率
自定义的模块
可以将程序的各部分功能提取出来放到同一模块中为大家共享是使用
好处是减少了代码冗余,程序组织结构更加清晰,维护起来也更加方便
导入模块的几种方式
导入模块的方式
# 第一种 import ...
import os
import time
# 第二种 from ... import ...
from random import randrange
from lxml import html
# 第三种 from ... import * (这种不推荐)
from turtle import *
# 第四种 from from ... import ... as / import ... as ..
import pandas as pd
导入位置
文件头:文件头导入的模块属于全局作用域
函数内:函数内导入的模块属于局部的作用域
导入模块需要注意的事项
方式1:
使用方式1导入模块后,使用模块里面的名字,需要通过module_name.名字的方式使用内容。这种'指名道姓'的使用方式可以避免名字相同的冲突,但有时也很繁琐;
方式2:
方式2导入的名字可以直接使用,不用'指名道姓',但要注意命名冲突问题。
无需加前缀的好处是使得我们的代码更加简洁,坏处则是容易与当前名称空间中的名字冲突,如果当前名称空间存在相同的名字,则后定义的名字会覆盖之前定义的名字。
方式3:
方式3可以一次性导入模块下的所有名字。不常用,很容易产生命名冲突的问题。
只能在模块最顶层使用的方式导入,在函数内则非法。模块的编写者可以在自己的文件中定义__all__变量(一般是列表)用来自定义通过方式三导入时哪些名字能够被导入;还有,下划线开头的名字不会被*导入
方式4:
如果模块名很长,可以使用起别名的方式,简化模块使用的繁琐,还可以避免名字冲突问题。
方式3补充
# foo.py
__all__ = ["name", "say_hello", "Foo"]
name = "小满"
def say_hello():
print(f"{__name__}你好!我是小满")
def toys():
print("谁看到我的玩具了。。。")
class Foo:
def __int__(self):
pass
def func(self):
print("from func")
# 这样我们在另外一个文件中使用*导入时,就只能导入__all__定义的名字了
print(name)
say_hello()
foo = Foo()
foo.func()
toys() # 不在__all__列表里面,使用*导入会报错
# 执行结果
"""
NameError: name 'toys' is not defined
小满
db.foo你好!我是小满
from func
"""
导入模块规范
在文件顶部导入所有的模块
导入顺序:每类模块空一行,并且同类模块下模块名按字母先后顺序排列
1. python内置模块
2. 第三方模块
3. 自定义模块
模块的命名
参考变量命名规范,注意下划线开头的名字不会被
*导入自定义的模块名应该采用纯小写+下划线的风格
如何用模块
使用模块之前必须先导入,不管任何形式的模块使用前都需要先导入
导入模块后,使用模块里面的名字的使用就和普通py文件一样,只不过我们使用的名字都是模块所在名称空间的。
注意:
无论查看还是修改的都是模块本身,与调用位置无关。
补充:
模块也是python的一等公民,所以它和函数一样支持对象赋值,当参数,当容器类数据的元素等操作。(list, tuple, set, dict)
导入模块的本质
import foo
1. 执行foo.py
2. 产生foo.py的名称空间,将运行过程中产生的名字都丢到foo的名称空间中
3. 在当前文件中产生一个名字叫foo, 该名字指向2中产生的名称空间
之后的导入,都是直接引用首次导入产生的foo.py的名称空间,不会重复执行代码
补充:
导入方式:import ..,在当前执行文件的名称空间中放一个被导入模块的名字,通过这个名字引用模块中的名字。
导入方式:from .. import..,在当前执行文件的名称空间中直接放一个模块中的名字,不能访问模块的其他名字。
import module, 通过module.name的方式, 可以拿到module的所有名字;
from module import name,每次只能拿到name,其他名字需要单独引入。
相对导入只能用from module import symbol的形式,import ..versions语法是不对的,且symbol只能是一个明确的名字
再次被导入
因为程序没有结束,第一次导入的模块已经在内存中,导入产生的名称空间也在内存中;
所以模块或模块中的名字再次被导入时,不会再运行模块文件的程序代码,而是从内存中直接绑定引用。
强调
强调1:模块名.名字,是指名道姓的问某一个模块要名字对应的值,不会与当前名称空间的名字发生冲突
强调2:无论是查看还是修改操作的都是模块本身,与调用位置无关
print(foo.x)
print(foo.get)
print(foo.change)
# 建议的导入方式
import time
import foo
import m
# 不建议的导入方式
import time, foo, m
py文件的两种用途
1. 当脚本文件被执行
2. 当模块被导入执行
区别:
1. 脚本文件执行时,产生的名称空间在程序运行结束后失效回收
2. 导入运行的文件产生的名称空间在引用技术为零时回收
补充:
每个py文件
查找优先级
先后顺序
内存 ---> 内置 ---> sys.path路径
补充1:
import sys
sys.path是一个列表,里面存放各种文件夹的路径,当内存和内战中不存在需要导入的模块时,会在sys.path种找。
sys.path的第一个路径是当前文件所在文件夹的路径
补充2:
import sys
sys.moudles是一个字典,里面存放当前内存中已经有的模块,字典的键是模块名,对应的值是模块的路径。
例如:"'core.src": <module 'core.src' from 'E:\\core\\src.py'>
模块的循环导入
强调:这种循环导入方式是不对的,是垃圾的,程序开发过程中应该时刻注意避免之。
循环导入问题指的是在一个模块加载/导入的过程中导入另外一个模块,而在另外一个模块中又返回来导入第一个模块中的名字,由于第一个模块尚未加载完毕,所以引用失败、抛出异常。
究其根源就是在python中,同一个模块只会在第一次导入时执行其内部代码,再次导入该模块时,即便是该模块尚未完全加载完毕也不会去重复执行内部代码,只会在内存中找该模块,找不到就报错了。
解决方案:
只有某些函数时候导入模块时,将导入模块放到函数内.
包
什么是包
包就是一个包含有__init__.py文件的文件夹
模块(module)一般是一个文件,而包(package)是一个目录,一个包中可以包含很多个模块,可以说包是“模块打包”组成的。
Python中的包都必须默认包含一个__init__.py的文件。
__init__.py控制着包的导入行为。假如这个文件为空,那么我们仅仅导入包的话,就什么都做不了。
为何要有包
* 包的本质就是模块的一种形式, 包是用来被当做模块导入
* 暴露给使用者的还是一个包,不过作为模块的设计者更方便管理设计
1. 产生一个名称空间
2. 运行包下的`__init__py`文件, 将运行过程中产生的名字都丢到1的名称空间中
3. 在当前执行文件的名称空间中拿到一个mmm, mmm指向1的名称空间
import mmm
# mmm包下面有一个__init__.py
# __init__.py的代码是 print("运行了....")
"""
运行了....
"""
此时
__init__.py的代码如下
print("运行了....")
x = 1
def say():
print("hello")
主程序运行结果
import mmm
print(mmm.x)
mmm.say()
"""
运行了....
1
hello
"""
需要强调的是
1.在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2.创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
3.环境变量是以执行文件为准的,所有的被导入的模块或者说后续的其他文件引用的sys.path都是参照执行文件的sys.path
强调
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如`import` 顶级包.子包.子模块,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性).
2.包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间.
3.import导入文件时,产生名称空间中的名字来源于文件,import包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件.
例如
from a.b.c.d.e.f import xxx
import a.b.c.d.e.f
# 其中a b c d e 这几个都必须是包才可以
设置sys.path
import os
imoort sys
sys.path.append(os.path.dirname(__file__)) # __file__显示的是当前文件的绝对路径
# os.path.dirname() 获取当前文件所在的文件夹,也可以理解为去掉文件名返回目录
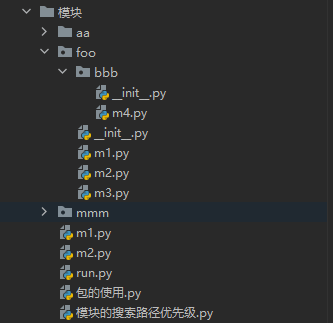
绝对导入
以包的文件夹作为起始来进行导入
sys.path的第一个文件夹是执行文件所在的文件夹
环境变量是以执行文件为准的,所有的被导入的模块或者说后续的其他文件引用的sys.path都是参照执行文件的sys.path
from foo.m1 import f1
from foo.m2 import f2
from foo.m3 import f3
from foo.bb.m4 import f4
相对导入
仅限于包内使用, 不能跨出包(包内模块之间的导入,推荐使用相对导入)
. 代表当前文件所在夹
.. 代表上一层文件夹
from .m1 import f1
from .m2 import f2
from .m3 import f3
from .bbb.m4 import f4
强调:相对导入不能跨出包,所以相对导入仅限于包内模块之间彼此闹着玩,只能在包内使用。
而绝对导入是没有任何限制的,所以绝对导入是一种通用的导入方式
解释main
在Python中,if __name__ == "__main__": 是一个常见的条件语句块,用于判断当前模块是否作为主程序直接运行,还是被其他模块导入并调用。
当一个Python脚本文件被直接运行时,Python解释器会将其指定为主程序,并将特殊变量__name__设置为__main__。而当一个模块被导入时,__name__的值将被设置为模块的名称。
因此,通过使用if __name__ == "__main__": 条件语句块,我们可以在脚本文件中指定一些只有在该脚本作为主程序运行时才会执行的代码。这样的代码通常包含一些测试、调试或初始化的逻辑。
def main():
# 主程序逻辑
print("这是主程序")
if __name__ == "__main__":
main()
在这个例子中,main()`函数包含了主程序的逻辑。通过使用 if __name__ == "__main__":条件语句,我们确保只有当该脚本作为主程序直接运行时,才会调用 main()函数。如果该脚本被其他模块导入,main()函数将不会自动执行。
注意
如果使用import 方法导入,那么使用导入对象的时候,需要一起带上
import mmm.foo.m4
mmm.foo.m4.f4 # 只能这样使用才可以
-
包内模块之间的导入,推荐使用相对导入
-
绝对导入参照的是
sys.path的路径 -
相对导入参照的是当前文件夹
软件开发目录规范
Foo/
│ requimrents.txt -----> 会使用到的包
| README / readme.txt -----> 项目说明书(使用的技术栈/框架/项目说明)
│
├─api
│ api.py
│
├─bin
│ start.py -----> 软件启动入口
│
├─conf ---> 配置文件
│ seeting.py -----> 此处存放固定的配置信息
│
├─core
│ core.py 或者 src.py ----> 此处存放核心业务逻辑代码
│
├─db (用于存放数据文件与操作数据的代码文件)
│ db_hander.py -----> 操作数据的代码(读写文件操作)
| - db_file. -----> db.txt ...
└─lib
│ - common.py:存放公共功能
│
└─log
log.txt / log.db -----> 存放日志的文件
- ATM # 项目名
|- README.md # 项目说明书(使用的技术栈/框架/项目说明)| |一
注意点
- 记录日志不属于核心逻辑,不应该放到core目录下的core文件
- 记录日志是属于共用的功能,需要放到common,存放公共功能
- 配置文件
seeting里面的文件,通常也是需要大写的,这个不是常量的意思,这个是一个规范 - 启动文件例如
start.py不要去导入它,即便能导入也不要去操作,这是违反规范的
编写模块规范
"The module is used to ..." # 模块的文档描述
import sys # 导入模块
x = 1 # 定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能
class Foo: # 定义类,并写好类的注释
"class Foo is used to ..."
pass
def test(): # 定义函数,并写好函数的注释
"Function test is used to ..."
pass
if __name__ == "__main__": # 主程序
test() # 在被当做脚本执行时,执行此处的代码
-
只有某些函数时候导入模块时,将导入模块放到函数内
-
文件都列出使用的模块
本文作者:小满三岁啦
本文链接:https://www.cnblogs.com/ccsvip/p/17900991.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



