随笔分类 - 算法笔记
ccr的算法笔记
摘要:## AC_Automaton=Trie+KMP! ~~废话~~ ### [KMP](https://www.cnblogs.com/ccr-note/p/KMP.html "KMP") ### [Trie](https://www.cnblogs.com/ccr-note/p/trie.html
阅读全文
摘要: # KMP KMP是一种非常有用的算法,可以将字符串匹配的复杂度由 $O(nm)$ 降到 $O(n+m)$ ## 朴素算法 学过语言就会朴素算法,这里只给出伪代码: ``` for(i=0->n-1){ for(j=i>m-i){ if(s[i]!=s[j])goto fg; } cout usin
阅读全文
# KMP KMP是一种非常有用的算法,可以将字符串匹配的复杂度由 $O(nm)$ 降到 $O(n+m)$ ## 朴素算法 学过语言就会朴素算法,这里只给出伪代码: ``` for(i=0->n-1){ for(j=i>m-i){ if(s[i]!=s[j])goto fg; } cout usin
阅读全文
# KMP KMP是一种非常有用的算法,可以将字符串匹配的复杂度由 $O(nm)$ 降到 $O(n+m)$ ## 朴素算法 学过语言就会朴素算法,这里只给出伪代码: ``` for(i=0->n-1){ for(j=i>m-i){ if(s[i]!=s[j])goto fg; } cout usin
阅读全文
摘要:# 字典树 ## 字典树(Trie)简介 > 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效
阅读全文
摘要:## 并查集的定义 >并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题。常常在使用中以森林来表示。 ——百度百科 并查集,顾名思义,支持以下两种操作操作: - 并(Union):把两个不相交的集合合并为一个集合。 - 查(Find):查询两个元素是否在
阅读全文
摘要: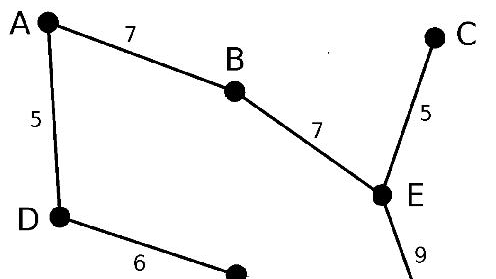 ## Prim算法 prim算法基本思想:基于点的解决方式 1. 先随便选择一个点s作为起点,把其他所有点设为未添加节点,再设一dis数组,代表每个 节点到最小生成树最近点的距离,易得一开始只有dis[s]=0,其他均为∞。 1. 每轮找到dis值最小且未添加过的节点加入生成树中,且使用这个节点的邻
阅读全文
## Prim算法 prim算法基本思想:基于点的解决方式 1. 先随便选择一个点s作为起点,把其他所有点设为未添加节点,再设一dis数组,代表每个 节点到最小生成树最近点的距离,易得一开始只有dis[s]=0,其他均为∞。 1. 每轮找到dis值最小且未添加过的节点加入生成树中,且使用这个节点的邻
阅读全文
## Prim算法 prim算法基本思想:基于点的解决方式 1. 先随便选择一个点s作为起点,把其他所有点设为未添加节点,再设一dis数组,代表每个 节点到最小生成树最近点的距离,易得一开始只有dis[s]=0,其他均为∞。 1. 每轮找到dis值最小且未添加过的节点加入生成树中,且使用这个节点的邻
阅读全文
摘要:## 思想 拓扑,一看就是从图的开始开始开拓,并按被开拓到的顺序排序 拓扑排序的思想如下: > 将入度为 $0$ 的点删除,并记录它被删除的顺序,直到没有点则结束程序 ## 图解  Tarjan Tarjan算法是图论中非常常用的算法之一,能解决强连通分量,双连通分量,割点和桥,求最近公共祖先(LCA)等问题。 Tarjan 算法是基于深度优先搜索的算法,用于求解图的连通性问题。 割点 如果从图中删除节点 \(x\) 以及所有与 \(x\) 关联的边之后,图将被分成两个或两个以
阅读全文
Tarjan Tarjan算法是图论中非常常用的算法之一,能解决强连通分量,双连通分量,割点和桥,求最近公共祖先(LCA)等问题。 Tarjan 算法是基于深度优先搜索的算法,用于求解图的连通性问题。 割点 如果从图中删除节点 \(x\) 以及所有与 \(x\) 关联的边之后,图将被分成两个或两个以
阅读全文
Tarjan Tarjan算法是图论中非常常用的算法之一,能解决强连通分量,双连通分量,割点和桥,求最近公共祖先(LCA)等问题。 Tarjan 算法是基于深度优先搜索的算法,用于求解图的连通性问题。 割点 如果从图中删除节点 \(x\) 以及所有与 \(x\) 关联的边之后,图将被分成两个或两个以
阅读全文
 图论打砸会
图论打砸会
摘要:什么是STL STL(Standard Template Library),即标准模板库,是一个高效的C++程序库 被容纳于C++标准程序库(C++ Standard Library)中,是ANSI/ISO C++标准中最新的也是极具革命性的一部分。包含了诸多在计算机科学领域里常用的基本数据结构和基
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号