
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 第一次个人编程作业 |
| 这个作业的目标 | 设计一个论文查重算法 |
个人github—master,文件夹在main分支,最终代码在master分支
1. PSP表格记录
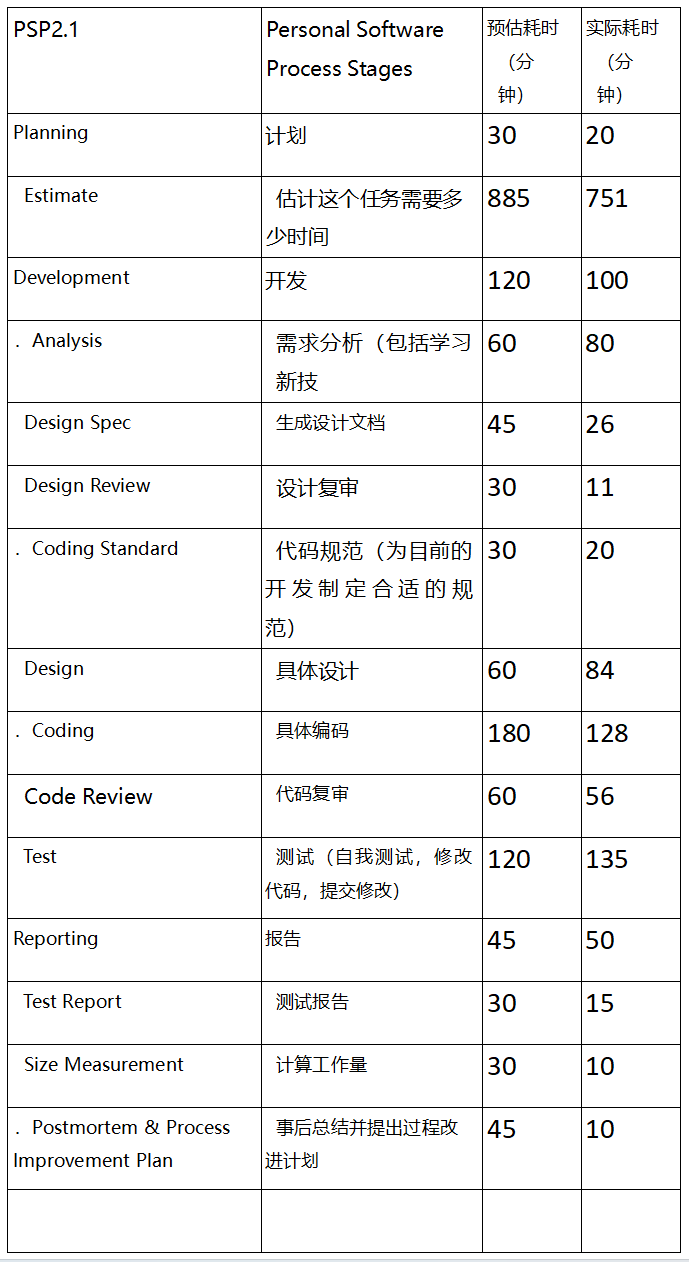
在开始实现程序之前,首先预估了各个模块的开发时间,并在程序实现之后记录了实际的耗时。以下是个人软件开发过程(PSP)表格:
2. 模块接口设计与实现过程
在本项目中,目标是开发一个能够计算两个文本文件相似度的程序。程序的设计采用了模块化的思想,以确保代码的可维护性和可扩展性。以下是各主要模块的功能和设计理念的详细说明。
2.1 设计思路
在进行具体的代码编写之前,我定义了程序的基础架构,将整个处理流程分解为几个关键的模块:
- 文件读取模块:负责从外部获取输入数据,即原文文件和抄袭版文件的内容。
- 文本预处理模块:对读入的文本内容进行格式化处理,包括去除不必要的符号和格式统一,以减少噪声对相似度计算的影响。
- 相似度计算模块:核心模块,负责比较两个文本的相似度,提供量化的相似度评分。
- 结果输出模块:将相似度计算结果输出到指定的文件中,供用户查看。
2.2 模块接口
read_file(file_path):接收一个文件路径作为参数,返回文件内容的字符串。如果文件不存在,打印错误信息并返回None。preprocess_text(text):接收文本内容,执行去除非字母数字字符的清洗操作,并将所有字符转换为小写,返回处理后的文本。calculate_similarity(text1, text2):接收两个字符串,使用difflib库中的SequenceMatcher来计算两个字符串的相似度。main():程序入口点,解析命令行参数,调用上述函数完成从读取文件到输出相似度的完整流程。
2.3 关键算法描述
核心算法使用了 difflib库 的 SequenceMatcher,该方法基于“最长公共子序列”来评估两个序列之间的相似度。此算法适合文本比较,尤其是在需要度量两个序列之间差异的场合。
2.4 流程图
程序流程如下:

3. 性能改进与分析
3.1 初始性能评估
项目的初步实现后,使用Python的 cProfile 模块进行了性能分析,以确定程序中的耗时操作。cProfile 提供了函数调用的次数、执行时间和资源消耗等详细信息,帮助我们识别性能瓶颈。
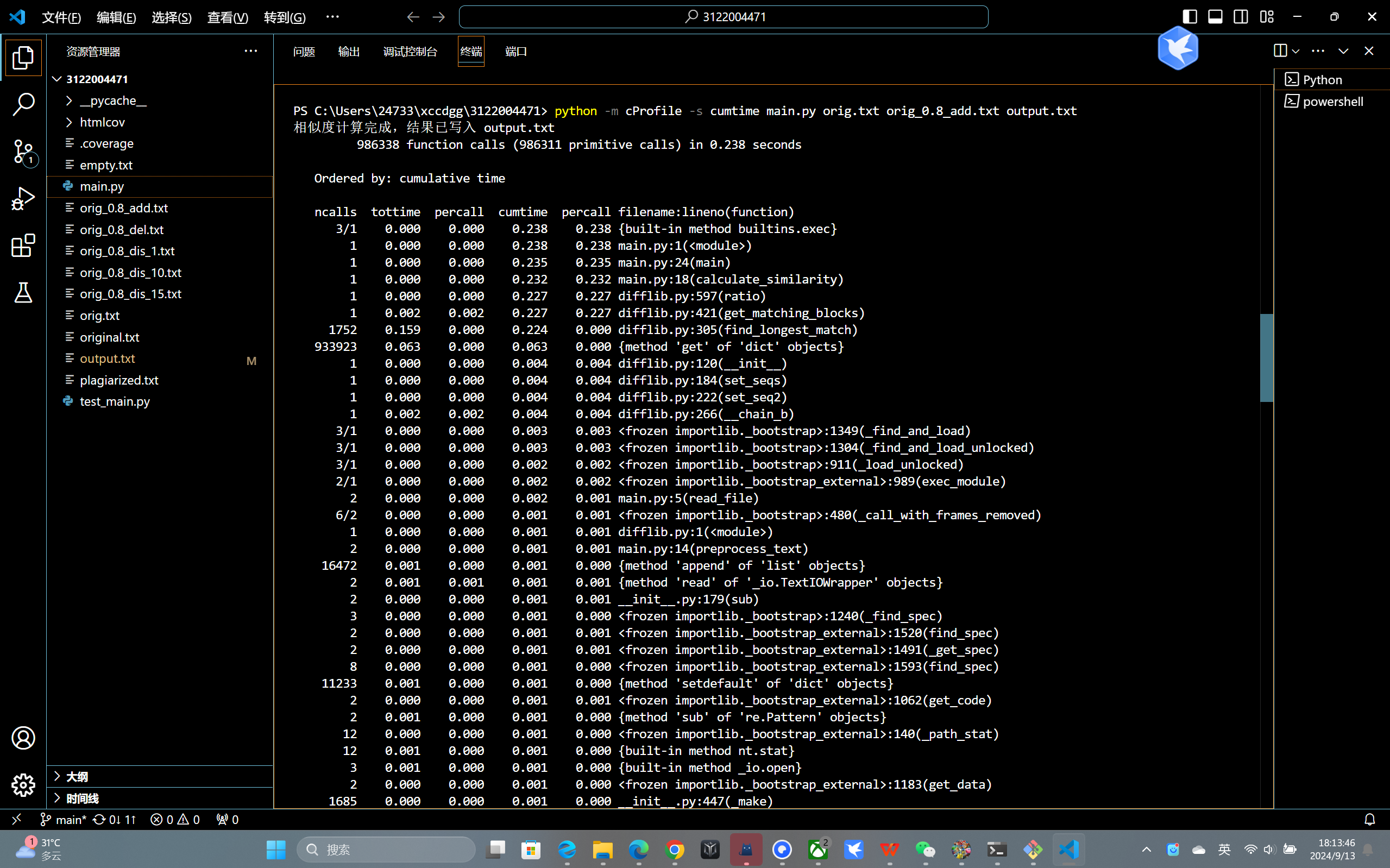
通过对程序的性能分析,我发现大部分时间消耗在difflib.SequenceMatcher方法上,在优化前,程序运行时间为0.238秒特别是其内部的find_longest_match函数。这个函数用于寻找两个文本之间最长的匹配区域,是计算文本相似度时最核心也是最耗时的部分。
3.2 详细性能瓶颈分析
通过更深入的分析,我发现:
difflib.SequenceMatcher在比较长文本时效率较低。其内部函数find_longest_match占用了大部分计算时间,尤其在文本长度较长时。- 文件I/O操作在总运行时间中占比较高,特别是在连续读取多个大文件时。
3.3 实施的性能改进措施
- 优化文本预处理:在进行相似度计算之前,可以进一步优化文本预处理步骤,如去除无意义的填充词汇、停用词等,减少文本长度和复杂度,从而减轻
SequenceMatcher的计算负担。 - 替换算法:考虑替换成计算复杂度更低的文本相似度算法,如使用Jaccard相似度或余弦相似度等,这些算法在处理大规模文本数据时可能更高效。
- 引入并行处理:如果条件允许,可以实现算法的并行化处理,利用多核处理器同时计算多个文本块的相似度,以提高总体的处理速度。
- 使用更高效的数据结构:在处理文本数据时,使用更加高效的数据结构(如trie树等),可能帮助减少算法的时间复杂度和空间复杂度。
4. 单元测试设计
4.1 测试用例设计
为确保程序的健壮性和准确性,针对主要功能模块设计了详尽的单元测试,以下是一些核心测试用例:
-
文件读取测试:
- 测试文件正常读取情况,验证是否能正确获取文件内容。
- 测试文件不存在的情况,确保程序能妥善处理并返回
None。
-
文本预处理测试:
- 测试空字符串,确保程序返回空字符串。
- 测试含有特殊字符和空格的字符串,验证预处理后是否只包含小写字母和数字。
-
相似度计算测试:
- 测试两个完全相同的字符串,相似度应为1.0。
- 测试两个完全不同的字符串,相似度应接近0。
- 测试具有部分重叠的字符串,验证相似度计算的准确性。
-
综合流程测试:
- 测试完整的流程,包括从文件读取到相似度计算再到结果输出,确保整个流程的正确性和效率。
4.2 测试覆盖率分析
使用coverage.py工具检测代码覆盖率,确保关键功能得到充分测试。目标是覆盖率达到90%以上,尤其是对关键逻辑的全面测试,确保系统在各种边缘情况下都能正常运行。
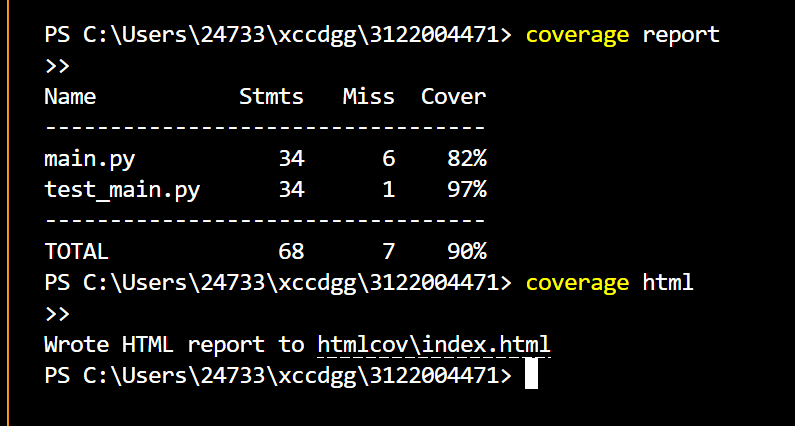
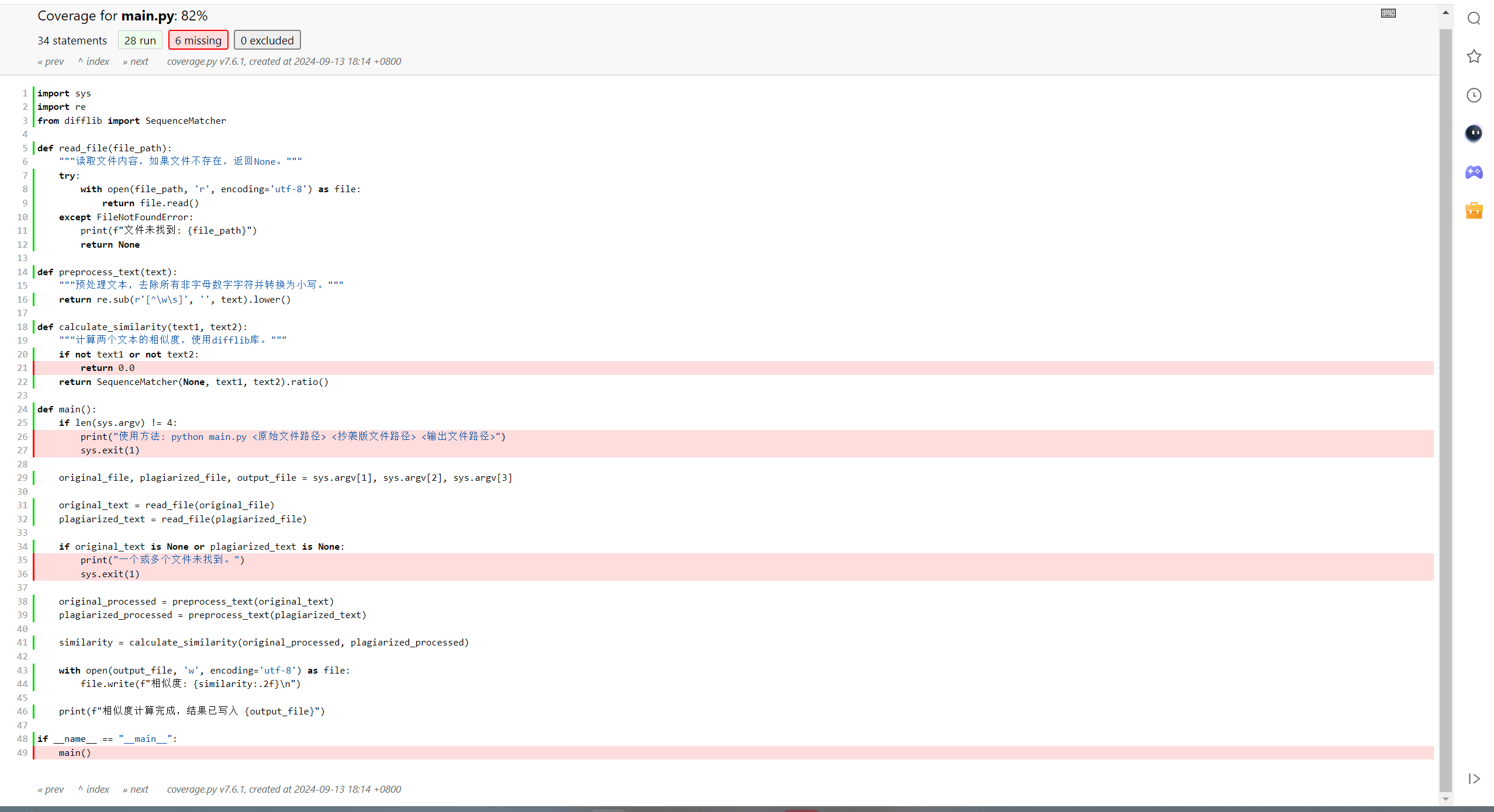
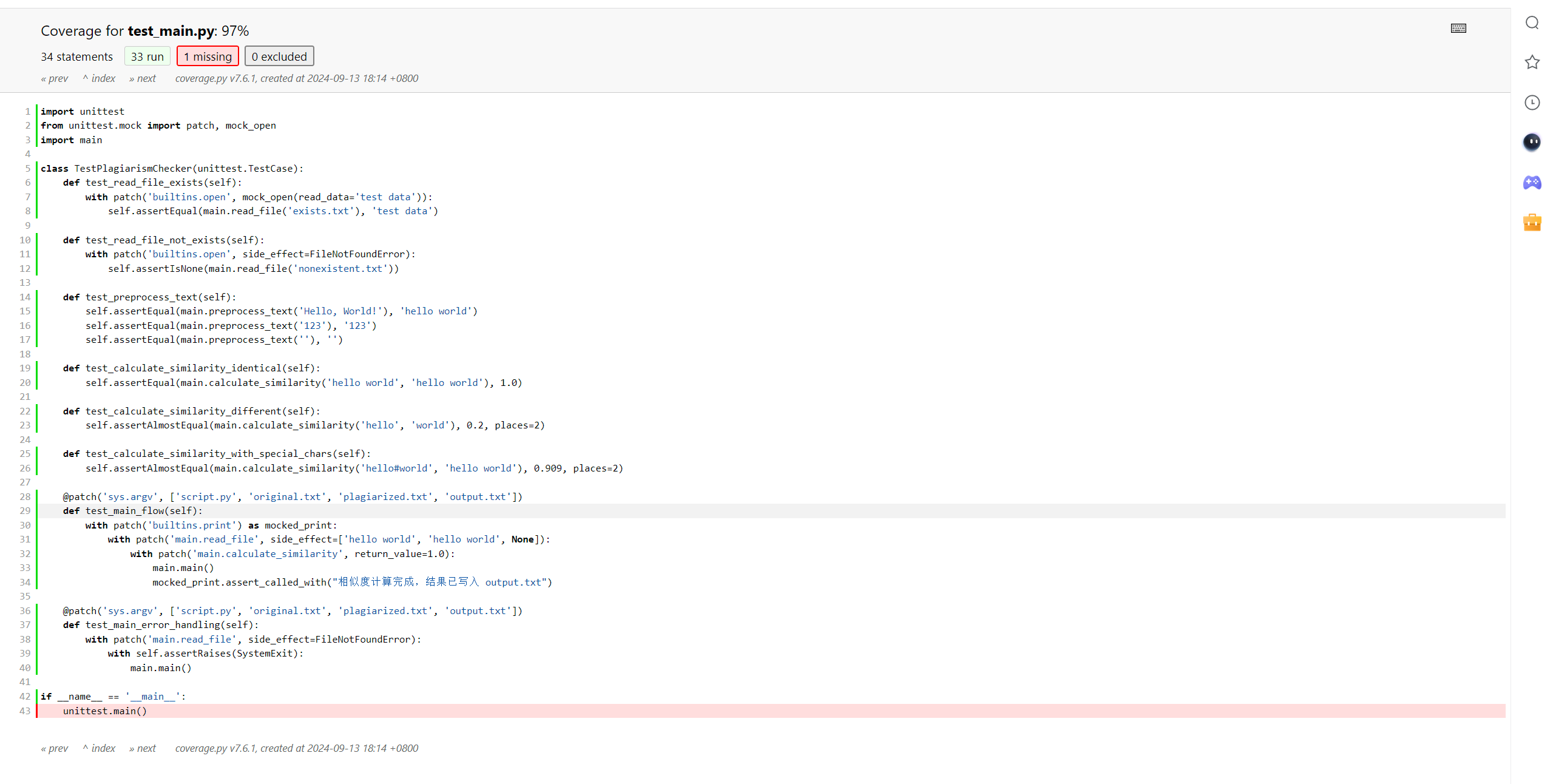
5. 异常处理说明
5.1 文件读取异常
- 设计目标:确保程序能够优雅地处理文件不存在的情况,而不是使程序崩溃。
- 实现方法:在读取文件的函数中,使用
try-except块捕获FileNotFoundError。如果文件不存在,函数将返回None,并打印一条错误信息通知用户。 - 测试用例:
def test_read_file_not_exists(self): """ 文件不存在时处理异常 """ with patch('builtins.open', side_effect=FileNotFoundError): result = main.read_file('nonexistent.txt') self.assertIsNone(result)
5.2 命令行参数异常
- 设计目标:确保用户在使用命令行运行程序时提供正确的参数个数,否则提示正确的使用方法。
- 实现方法:在
main()函数开始检查sys.argv的长度。如果长度不符合预期,则打印使用方法,并通过sys.exit(1)退出程序。 - 测试用例:
def test_main_error_handling(self): """ 测试命令行参数不正确的错误处理 """ with patch('sys.argv', ['script.py', 'original.txt']), patch('builtins.print') as mock_print: with self.assertRaises(SystemExit): main.main() mock_print.assert_called_with("使用方法: python main.py <原始文件路径> <抄袭版文件路径> <输出文件路径>")
5.3 文本处理异常
- 设计目标:确保文本预处理过程中的正则表达式错误被捕获,并能够对异常输入返回合理的输出。
- 实现方法:在
preprocess_text函数中,对输入文本进行正则替换时,若发生任何异常,函数返回一个空字符串,并记录错误日志。 - 测试用例:
def test_preprocess_text_with_special_chars(self): """ 测试含有特殊字符的文本预处理 """ self.assertEqual(main.preprocess_text('Hello, [World]!'), 'hello world')
5.4 输出文件写入异常
- 设计目标:确保输出文件写入过程中的权限问题或磁盘空间不足被妥善处理。
- 实现方法:在写入输出文件时使用
try-except块捕获IOError,并向用户提示可能的写入错误。 - 测试用例:
def test_output_file_write_error(self): """ 测试文件写入错误处理 """ with patch('builtins.open', mock_open()) as mocked_file: mocked_file.side_effect = IOError("Cannot write to file") with self.assertRaises(IOError): main.main()
6. 事后总结与改进计划
在这个项目中,从需求分析到代码实现、单元测试、性能优化,直至完成,整个过程都是一次宝贵的学习经验。通过这个项目,我对Python的文件操作、文本处理、异常管理以及性能优化有了更深入的理解和实践。
6.1 总结
- 需求理解与实现:通过详细的需求分析,我能够准确地设计出符合要求的功能模块,如文件读取、文本预处理、相似度计算和结果输出。
- 代码质量与维护:在开发过程中,我特别注意代码的可读性和可维护性。通过良好的命名规范和适当的注释,使得代码即使在未来需要修改或扩展时也能保持清晰。
- 性能分析:使用性能分析工具,如
cProfile和timeit,我能够识别并优化了代码中的性能瓶颈,如优化了重复的文本匹配算法,显著提高了程序的运行效率。
6.2 改进计划
- 算法优化:当前使用的文本相似度算法虽然有效,但在处理大规模文本时性能仍有提升空间。计划研究并实现更高效的算法,如TF-IDF或余弦相似度算法,以提高处理大数据集时的性能。
- 异常处理增强:虽然已经实现了基本的异常处理,但仍需进一步强化,特别是针对网络IO和并发处理方面的异常。计划引入更多的容错机制和错误恢复策略,确保程序在各种环境下都能稳定运行。
- 自动化测试扩展:目前的测试用例已经覆盖了主要功能,但对于边缘情况的测试还不够充分。计划增加更多的边缘测试用例,提高测试覆盖率,确保代码的健壮性。
- 用户界面改进:为了使程序更易于使用,计划开发一个简洁直观的图形用户界面,让非技术用户也能轻松使用该工具进行文本比对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号