【Kaggle】Titanic: Machine Learning from Disaster
注:记录自己的第一次 Kaggle
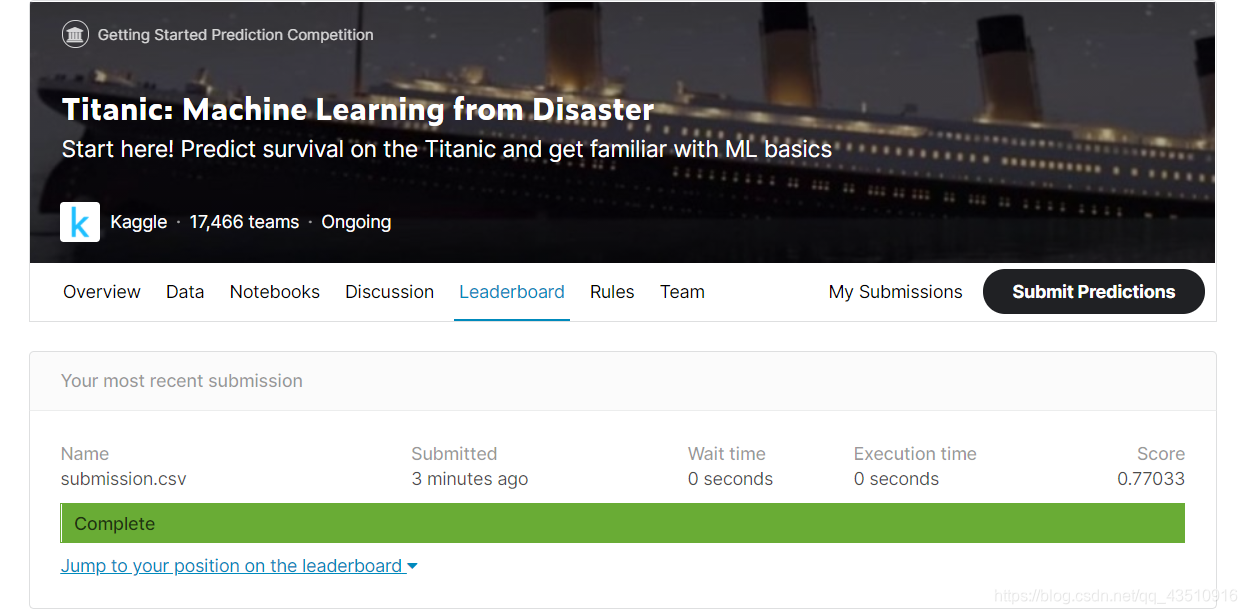
Result
Code
数据预览
数据导入
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
data=pd.read_csv('/kaggle/input/titanic/train.csv')
test=pd.read_csv('/kaggle/input/titanic/test.csv')
warnings.filterwarnings("ignore")
数据查看
data.head()
test.head()
数据清洗
删除多余特征
删除id、票号、船舱类型特征
data_drop=data.drop(['PassengerId', 'Ticket', 'Cabin'], axis=1)
test_drop=test.drop(['PassengerId', 'Ticket', 'Cabin'], axis=1)
test_drop.head()
data_drop.isnull().sum().nlargest(10)
Age 177
Embarked 2
Survived 0
Pclass 0
Name 0
Sex 0
SibSp 0
Parch 0
Fare 0
dtype: int64
test_drop.isnull().sum().nlargest(10)
Age 86
Fare 1
Pclass 0
Name 0
Sex 0
SibSp 0
Parch 0
Embarked 0
dtype: int64
缺失值填充
data_drop['Age'].fillna(data_drop['Age'].median(), inplace=True)# 中位数填充
test_drop['Age'].fillna(data_drop['Age'].median(), inplace=True)# 中位数填充
data_drop['Embarked'].fillna(data_drop['Embarked'].mode()[0], inplace=True)# 众数填充
test_drop['Fare'].fillna(data_drop['Fare'].mode()[0], inplace=True)# 众数填充
test_drop.isnull().sum().nlargest(10)
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
data_drop.isnull().sum().nlargest(10)
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
数据挖掘
家庭总人数
data_drop['FamilySize']=data_drop['SibSp']+data_drop['Parch']+1# 家庭总人数
test_drop['FamilySize']=test_drop['SibSp']+test_drop['Parch']+1# 家庭总人数
身份标识
每个人的姓名前面都会有一个类似于Mr,Mrs的标识,我们把这个也作为其中一个特征:
data_drop['Title'] = data_drop['Name'].str.split(
", ", expand=True)[1].str.split(".", expand=True)[0]
test_drop['Title'] = test_drop['Name'].str.split(
", ", expand=True)[1].str.split(".", expand=True)[0]
less_data=data_drop['Title'].value_counts()<10
data_drop['Title']=data_drop['Title'].apply(lambda x: 'Misc' if less_data.loc[x]==True else x)
data_drop['Title'].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Misc 27
Name: Title, dtype: int64
less_test=test_drop['Title'].value_counts()<10
test_drop['Title']=test_drop['Title'].apply(lambda x: 'Misc' if less_test.loc[x]==True else x)
test_drop['Title'].value_counts()
Mr 240
Miss 78
Mrs 72
Master 21
Misc 7
Name: Title, dtype: int64
年龄分级
我们把年龄分为等差的五级作为其中一个特征:
data_drop['AgeBin']=pd.cut(data_drop['Age'].astype(int), 5)
data_drop['AgeBin'].value_counts()
(16.0, 32.0] 525
(32.0, 48.0] 186
(-0.08, 16.0] 100
(48.0, 64.0] 69
(64.0, 80.0] 11
Name: AgeBin, dtype: int64
test_drop['AgeBin']=pd.cut(test_drop['Age'].astype(int), 5)
test_drop['AgeBin'].value_counts()
(15.2, 30.4] 254
(30.4, 45.6] 80
(45.6, 60.8] 42
(-0.076, 15.2] 32
(60.8, 76.0] 10
Name: AgeBin, dtype: int64
票价分级
我们把票价按照购买人数分为的五级作为其中一个特征:
data_drop['FareBin']=pd.qcut(data_drop['Fare'], 4)
data_drop['FareBin'].value_counts()
(7.91, 14.454] 224
(-0.001, 7.91] 223
(31.0, 512.329] 222
(14.454, 31.0] 222
Name: FareBin, dtype: int64
test_drop['FareBin']=pd.qcut(test_drop['Fare'], 4)
test_drop['FareBin'].value_counts()
(-0.001, 7.896] 114
(31.472, 512.329] 105
(14.454, 31.472] 102
(7.896, 14.454] 97
Name: FareBin, dtype: int64
数据准备
数据编码
from sklearn.preprocessing import LabelEncoder
label=LabelEncoder()
data_drop['Sex_Code']=label.fit_transform(data_drop['Sex'])
data_drop['Embarked_Code']=label.fit_transform(data_drop['Embarked'])
data_drop['Title_Code']=label.fit_transform(data_drop['Title'])
data_drop['AgeBin_Code']=label.fit_transform(data_drop['AgeBin'])
data_drop['FareBin_Code']=label.fit_transform(data_drop['FareBin'])
test_drop['Sex_Code']=label.fit_transform(test_drop['Sex'])
test_drop['Embarked_Code']=label.fit_transform(test_drop['Embarked'])
test_drop['Title_Code']=label.fit_transform(test_drop['Title'])
test_drop['AgeBin_Code']=label.fit_transform(test_drop['AgeBin'])
test_drop['FareBin_Code']=label.fit_transform(test_drop['FareBin'])
训练特征选择
feature_cols=['Pclass', 'FamilySize','Sex_Code', 'Embarked_Code', 'Title_Code', 'AgeBin_Code', 'FareBin_Code']
target='Survived'
训练集
data_X=data_drop[feature_cols]
data_y=data_drop[target]
测试集
test_X=test_drop[feature_cols]
模型训练
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=100)
model.fit(data_X, data_y)
预测
y_pred=model.predict(test_X)
output=pd.read_csv("/kaggle/input/titanic/gender_submission.csv")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号